前言
本文给大家分享的是如何通过利用Python实现鲁迅名言查询系统,废话不多直接开整~
开发工具
Python版本: 3.6
相关模块:
PyQt5模块
fuzzywuzzy模块
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
文中实战教程,评论留言获取。
代码实现
简单的GUI
class GUI(QWidget):
def __init__(self, parent=None):
super().__init__()
self.setWindowTitle('鲁迅名言查询-公众号:Python工程狮')
self.setWindowIcon(QIcon('data/icon.png'))
self.label1 = QLabel('句子:')
self.line_edit = QLineEdit()
self.label2 = QLabel('查询结果:')
self.text = QTextEdit()
self.button = QPushButton()
self.button.setText('查询')
self.cmb = QComboBox()
self.cmb.setStyle(QStyleFactory.create('Fusion'))
self.cmb.addItem('匹配度: 100%')
self.cmb.addItem('匹配度: 90%')
self.cmb.addItem('匹配度: 80%')
self.cmb.addItem('匹配度: 70%')
self.grid = QGridLayout()
self.grid.setSpacing(12)
self.grid.addWidget(self.label1, 1, 0)
self.grid.addWidget(self.line_edit, 1, 1, 1, 38)
self.grid.addWidget(self.button, 1, 39)
self.grid.addWidget(self.label2, 2, 0)
self.grid.addWidget(self.text, 2, 1, 1, 40)
self.grid.addWidget(self.cmb, 1, 40)
self.setLayout(self.grid)
self.resize(600, 400)
self.button.clicked.connect(self.inquiry)
self.paragraphs = self.loadData('data/book.txt')
查询
def inquiry(self):
sentence = self.line_edit.text()
matched = []
score_thresh = self.getScoreThresh()
if not sentence:
QMessageBox.warning(self, "Warning", '请先输入需要查询的鲁迅名言')
else:
for p in self.paragraphs:
score = fuzz.partial_ratio(p, sentence)
if score >= score_thresh and len(sentence) <= len(p):
matched.append([score, p])
infos = []
for match in matched:
infos.append('[匹配度]: %d\n[内容]: %s\n' % (match[0], match[1]))
if not infos:
infos.append('未匹配到任何相似度大于%d的句子.\n' % score_thresh)
self.text.setText('\n\n\n'.join(infos)[:-1])
根据下拉框选项获取匹配度
def getScoreThresh(self):
if self.cmb.currentIndex() == 0:
return 100
elif self.cmb.currentIndex() == 1:
return 90
elif self.cmb.currentIndex() == 2:
return 80
elif self.cmb.currentIndex() == 3:
return 70
数据导入
def loadData(self, data_path):
paragraphs = []
with open(data_path, 'r', encoding='utf-8') as f:
for line in f.readlines():
if line.strip():
paragraphs.append(line.strip('\n'))
return paragraphs
运行
if __name__ == '__main__':
app = QApplication(sys.argv)
gui = GUI()
gui.show()
sys.exit(app.exec_())
结果展示
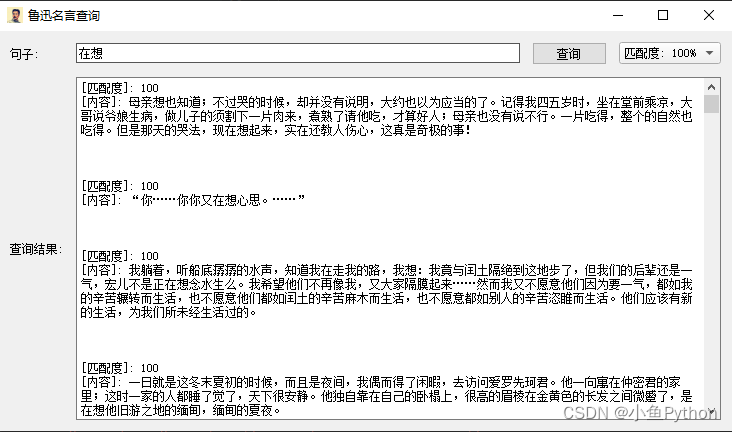

最后
今天的分享到这里就结束了 ,感兴趣的朋友也可以去试试哈
对文章有问题的,或者有其他关于python的问题,可以在评论区留言或者私信我哦
觉得我分享的文章不错的话,可以关注一下我,或者给文章点赞(/≧▽≦)/
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:【脚本项目源码】Python实现鲁迅名言查询系统 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 