一、爬虫的基本原理
网络爬虫的价值其实就是数据的价值,在互联网社会中,数据是无价之宝,一切皆为数据,谁拥有了大量有用的数据,谁就拥有了决策的主动权。
爬虫聚合站点
https://qbt4.mobduos.com/promote/pc/?code=339115928&utm=339115928
http://www.hrdatayun.com
https://tophub.today/c/tech
https://www.vlogxz.com/
1.0 爬虫定义
简单来讲,爬虫就是一个探测机器,它的基本操作就是模拟人的行为去各个网站溜达,点点按钮,查查数据,或者把看到的信息背回来。就像一只虫子在一幢楼里不知疲倦地爬来爬去。
1.1 爬虫薪资
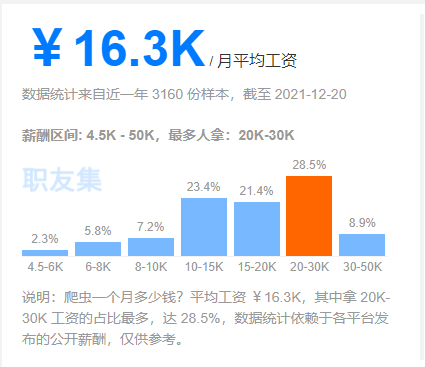

1.2 爬虫前景
每个职业都是有一个横向和纵向的发展,也就是所谓的广度和深度的意思。第一、如果专研得够深,你的爬虫功能很强大,性能很高,扩展性很好等等,那么还是很有前途的。第二、爬虫作为数据的来源,后面还有很多方向可以发展,比如可以往大数据分析、数据展示、机器学习等方面发展,前途不可限量,现在作为大数据时代,你占据在数据的的入口,还怕找不到发展方向吗?

1.3 爬虫创业
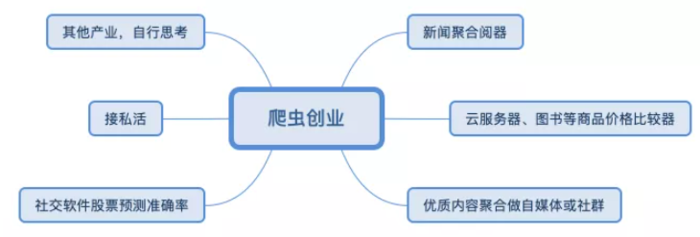
案列:
1.1.1 获取网页
爬虫首先要做的工作就是获取网页,这里就是获取网页的源代码。源代码里包含了网页的部分有用信息,所以只要把源代码获取下来,就可以从中提取想要的信息了。
- 使用socket下载一个页面
#!/usr/bin/python
# -*- coding: UTF-8 -*-
"""
@author:chenshifeng
@file:00.py
@time:2022/10/14
"""
import socket
# 不需要安装
# 访问网站
url = 'www.baidu.com'
# 端口
port = 80
def blocking():
sock = socket.socket() # 建立对象
sock.connect((url, port)) # 连接网站 ,发出一个HTTP请求
request_url = 'GET / HTTP/1.0\r\nHost: www.baidu.com\r\n\r\n'
sock.send(request_url.encode()) # 根据请求头来发送请求信息
response = b'' # 建立一个二进制对象用来存储我们得到的数据
chunk = sock.recv(1024) # 每次获得的数据不超过1024字节
while chunk: # 循环接收数据,因为一次接收不完整
response += chunk
chunk = sock.recv(1024)
header, html = response.split(b'\r\n\r\n', 1)
f = open('index.html', 'wb')
f.write(html)
f.close()
if __name__ == '__main__':
blocking()
1.1.2 提取信息
获取网页源代码后,接下来就是分析网页源代码,从中提取我们想要的数据。首先,最通用的方法便是采用正则表达式提取,这是一个万能的方法,但是在构造正则表达式时比较复杂且容易出错。
另外,由于网页的结构有一定的规则,所以还有一些根据网页节点属性、CSS 选择器或 XPath 来提取网页信息的库,如 Beautiful Soup、pyquery、lxml 等。使用这些库,我们可以高效快速地从中提取网页信息,如节点的属性、文本值等。
提取信息是爬虫非常重要的部分,它可以使杂乱的数据变得条理清晰,以便我们后续处理和分析数据。
1.1.3 保存数据
提取信息后,我们一般会将提取到的数据保存到某处以便后续使用。这里保存形式有多种多样,如可以简单保存为 TXT 文本或 JSON 文本,也可以保存到数据库,如 MySQL 和 MongoDB 等,也可保存至远程服务器,如借助 SFTP 进行操作等。
1.1.4 自动化程序
说到自动化程序,意思是说爬虫可以代替人来完成这些操作。首先,我们手工当然可以提取这些信息,但是当量特别大或者想快速获取大量数据的话,肯定还是要借助程序。爬虫就是代替我们来完成这份爬取工作的自动化程序,它可以在抓取过程中进行各种异常处理、错误重试等操作,确保爬取持续高效地运行。
二、HTTP基本原理
2.1.1 URI 和 URL
这里我们先了解一下 URI 和 URL,URI 的全称为 Uniform Resource Identifier,即统一资源标志符,URL 的全称为 Universal Resource Locator,即统一资源定位符。
什么是URL?
Uniform Resource Locator或者简称URL— 顾名思义 — 就是对于某种web资源的引用,并且包含了如何获取该资源的方式。 最常见到的场景就是指一个网站的地址,也就是你在浏览器地址栏见到的那个东西。

一个URL由如下几个部分构成:
https://img.vm.laomishuo.com/image/2019/10/F9A91867-194B-4F18-90CF-65CE2A8BFDDA.jpeg
- 协议: 通常是https或者http。表示通过何种方式获取该资源。你可能还见过其他协议类型,比如ftp或者file,协议后面跟着://
-
主机名: 可以是一个已经在DNS服务器注册过的域名 —— 或者是一个IP地址 —— 域名就表示背后的IP地址。一组主要由数字组成的用于标识接入网络的设备的字符串。
主机名后面可以指定端口,端口是可选的,如果不指定则使用默认端口,端口和主机名之间通过冒号隔开。 -
资源路径: 用于表示资源在主机上的文件系统路径。
可以在这之后通过问号连接可选的查询参数,如果有多个查询参数,通过&符连接
最后一项,如果需要的话可以添加#作为需要跳转的页面上的矛点名称。
一个URL的组成部分可以参考下面的图示:
什么是URI?
接下来我们来了解一下究竟什么是URI。与URL相似的部分是,Uniform Resource Identifier同样定义了资源的标识。但不同点在于URI通常不会包含获取资源的方式。
ISBN作为书目的资源定义就是一种URI,但不是URL。它清楚地为每一种出版的书目定义了唯一的数字编号,但没有包含任何如何获取这种资源的方法。
URI代表着统一资源标识符(UniformResourceIdentifier),用于标识某一互联网资源名称。 该种标识允许用户对任何包括本地和互联网的资源通过特定的协议进行交互操作。比如上面URL中的F9A91867-194B-4F18-90CF-65CE2A8BFDDA.jpeg。
URL 和 URI 的区别:
(1)URL:Uniform Resource Locator统一资源定位符;
(2)URI: Uniform Resource Identifier统一资源标识符;
因此我们可以这样总结:URI是URL的超集,URL是URI的子集。每一个URL都必定也是一个URI。
其实一直有个误解,很多人以为URI是URL的子集,其实应该反过来。URL是URI的子集才对。简单解释下。
假设"小白"(URI)是一种资源,而"在迪丽亦巴的怀里"表明了一个位置。如果你想要找到(locate)小白,那么你可以到"在迪丽亦巴怀里"找到小白,而"在迪丽亦巴怀里的/小白"才是我们常说的URL。而"在迪丽亦巴怀里的/小白"(URL)显然是"小白"(URI)的子集,毕竟,"小白"还可能是"在牛亦菲怀里的/小白"(其他URL)。
所以实际上URL就是一种特定的URI,这种URI还含有如何获取资源的信息。如果一定需要一句话来总结本文的主要内容,那么RFC3986中的这句定义一定是最合适的:
The term “Uniform Resource Locator” (URL) refers to the subset of URIs that, in addition to identifying a resource, provide a means of locating the resource by describing its primary access mechanism.
2.1.2 超文本
其英文名称叫作 hypertext,我们在浏览器里看到的网页就是超文本解析而成的,其网页源代码是一系列 HTML 代码,里面包含了一系列标签,比如 img 显示图片,p 指定显示段落等。浏览器解析这些标签后,便形成了我们平常看到的网页,而网页的源代码 HTML 就可以称作超文本。
2.1.3 HTTP 和 HTTPS
在百度的首页 https://www.baidu.com/ 中,URL 的开头会有 http 或 https,这个就是访问资源需要的协议类型,有时我们还会看到 ftp、sftp、smb 开头的 URL,那么这里的 ftp、sftp、smb 都是指的协议类型。在爬虫中,我们抓取的页面通常就是 http 或 https 协议的,我们在这里首先来了解一下这两个协议的含义。
- HTTP 的全称是 Hyper Text Transfer Protocol,中文名叫做超文本传输协议
- HTTPS 的全称是 Hyper Text Transfer Protocol over Secure Socket Layer,是以安全为目标的 HTTP 通道,简单讲是 HTTP 的安全版,即 HTTP 下加入 SSL 层,简称为 HTTPS。
参考:https://baike.baidu.com/item/HTTPS/285356?fr=aladdin
2.1.4 HTTP 请求过程
我们在浏览器中输入一个 URL,回车之后便会在浏览器中观察到页面内容。实际上,这个过程是浏览器向网站所在的服务器发送了一个请求,网站服务器接收到这个请求后进行处理和解析,然后返回对应的响应,接着传回给浏览器。响应里包含了页面的源代码等内容,浏览器再对其进行解析,便将网页呈现了出来,模型如图 所示。
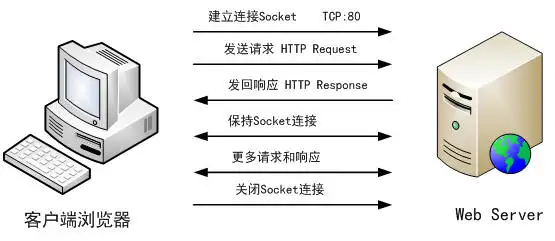
2.1.5 请求
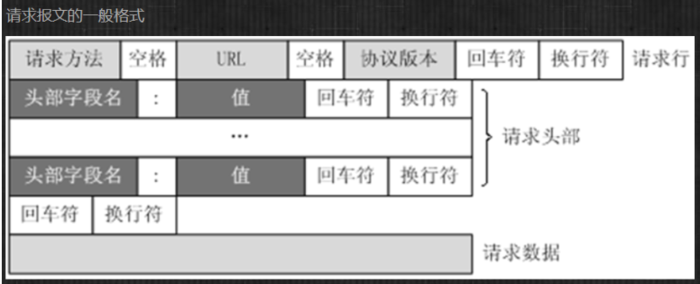
请求,由客户端向服务端发出,可以分为 4 部分内容:请求方法(Request Method)、请求的网址(Request URL)、请求头(Request Headers)、请求体(Request Body)。
面板组成
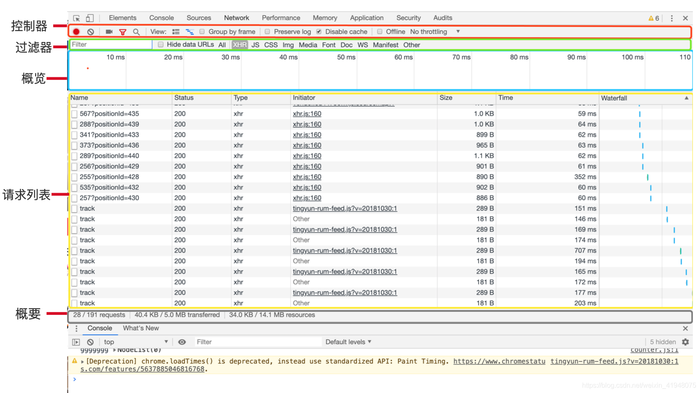
-
请求方法
表 1-1 其他请求方法
方 法 描 述 GET 请求页面,并返回页面内容 HEAD 类似于 GET 请求,只不过返回的响应中没有具体的内容,用于获取报头 POST 大多用于提交表单或上传文件,数据包含在请求体中 PUT 从客户端向服务器传送的数据取代指定文档中的内容 DELETE 请求服务器删除指定的页面 CONNECT 把服务器当作跳板,让服务器代替客户端访问其他网页 OPTIONS 允许客户端查看服务器的性能 TRACE 回显服务器收到的请求,主要用于测试或诊断
本表参考:http://www.runoob.com/http/http-methods.html。
-
请求的网址
请求的网址,即统一资源定位符 URL,它可以唯一确定我们想请求的资源。
-
请求头
参考:https://byvoid.com/zhs/blog/http-keep-alive-header/
- Accept
- Accept-Language
- Accept-Encoding
- Host 主机
- Cookie 会话信息 身份
- Referer 记录来源
- User-Agent 浏览器得指纹信息
- Content-Type 类型
-
请求体
请求体一般承载的内容是 POST 请求中的表单数据,而对于 GET 请求,请求体则为空。
2.1.6 响应
响应,由服务端返回给客户端,可以分为三部分:响应状态码(Response Status Code)、响应头(Response Headers)和响应体(Response Body)。
- 响应状态码
响应状态码表示服务器的响应状态,如 200 代表服务器正常响应,404 代表页面未找到,500 代表服务器内部发生错误。在爬虫中,我们可以根据状态码来判断服务器响应状态,如状态码为 200,则证明成功返回数据,再进行进一步的处理,否则直接忽略。表 2-3 列出了常见的错误代码及错误原因。
1.1常见的错误代码及错误原因
| 状态码 | 说 明 | 详 情 |
|---|---|---|
| 100 | 继续 | 请求者应当继续提出请求。服务器已收到请求的一部分,正在等待其余部分 |
| 101 | 切换协议 | 请求者已要求服务器切换协议,服务器已确认并准备切换 |
| 200 | 成功 | 服务器已成功处理了请求 |
| 201 | 已创建 | 请求成功并且服务器创建了新的资源 |
| 202 | 已接受 | 服务器已接受请求,但尚未处理 |
| 203 | 非授权信息 | 服务器已成功处理了请求,但返回的信息可能来自另一个源 |
| 204 | 无内容 | 服务器成功处理了请求,但没有返回任何内容 |
| 205 | 重置内容 | 服务器成功处理了请求,内容被重置 |
| 206 | 部分内容 | 服务器成功处理了部分请求 |
| 300 | 多种选择 | 针对请求,服务器可执行多种操作 |
| 301 | 永久移动 | 请求的网页已永久移动到新位置,即永久重定向 |
| 302 | 临时移动 | 请求的网页暂时跳转到其他页面,即暂时重定向 |
| 303 | 查看其他位置 | 如果原来的请求是 POST,重定向目标文档应该通过 GET 提取 |
| 304 | 未修改 | 此次请求返回的网页未修改,继续使用上次的资源 |
| 305 | 使用代理 | 请求者应该使用代理访问该网页 |
| 307 | 临时重定向 | 请求的资源临时从其他位置响应 |
| 400 | 错误请求 | 服务器无法解析该请求 |
| 401 | 未授权 | 请求没有进行身份验证或验证未通过 |
| 403 | 禁止访问 | 服务器拒绝此请求 |
| 404 | 未找到 | 服务器找不到请求的网页 |
| 405 | 方法禁用 | 服务器禁用了请求中指定的方法 |
| 406 | 不接受 | 无法使用请求的内容响应请求的网页 |
| 407 | 需要代理授权 | 请求者需要使用代理授权 |
| 408 | 请求超时 | 服务器请求超时 |
| 409 | 冲突 | 服务器在完成请求时发生冲突 |
| 410 | 已删除 | 请求的资源已永久删除 |
| 411 | 需要有效长度 | 服务器不接受不含有效内容长度标头字段的请求 |
| 412 | 未满足前提条件 | 服务器未满足请求者在请求中设置的其中一个前提条件 |
| 413 | 请求实体过大 | 请求实体过大,超出服务器的处理能力 |
| 414 | 请求 URI 过长 | 请求网址过长,服务器无法处理 |
| 415 | 不支持类型 | 请求格式不被请求页面支持 |
| 416 | 请求范围不符 | 页面无法提供请求的范围 |
| 417 | 未满足期望值 | 服务器未满足期望请求标头字段的要求 |
| 500 | 服务器内部错误 | 服务器遇到错误,无法完成请求 |
| 501 | 未实现 | 服务器不具备完成请求的功能 |
| 502 | 错误网关 | 服务器作为网关或代理,从上游服务器收到无效响应 |
| 503 | 服务不可用 | 服务器目前无法使用 |
| 504 | 网关超时 | 服务器作为网关或代理,但是没有及时从上游服务器收到请求 |
| 505 | HTTP 版本不支持 | 服务器不支持请求中所用的 HTTP 协议版本 |
- 响应头
响应头包含了服务器对请求的应答信息,如 Content-Type、Server、Set-Cookie 等。下面简要说明一些常用的头信息。
- Date:标识响应产生的时间。
- Last-Modified:指定资源的最后修改时间。
- Content-Encoding:指定响应内容的编码。
- Server:包含服务器的信息,比如名称、版本号等。
- Content-Type:文档类型,指定返回的数据类型是什么,如 text/html 代表返回 HTML 文档,application/x-javascript 则代表返回 JavaScript 文件,image/jpeg 则代表返回图片。
- Set-Cookie:设置 Cookies。响应头中的 Set-Cookie 告诉浏览器需要将此内容放在 Cookies 中,下次请求携带 Cookies 请求。
- Expires:指定响应的过期时间,可以使代理服务器或浏览器将加载的内容更新到缓存中。如果再次访问时,就可以直接从缓存中加载,降低服务器负载,缩短加载时间。
- 响应体
最重要的当属响应体的内容了。响应的正文数据都在响应体中,比如请求网页时,它的响应体就是网页的 HTML 代码;请求一张图片时,它的响应体就是图片的二进制数据。我们做爬虫请求网页后,要解析的内容就是响应体,如图 2-8 所示。
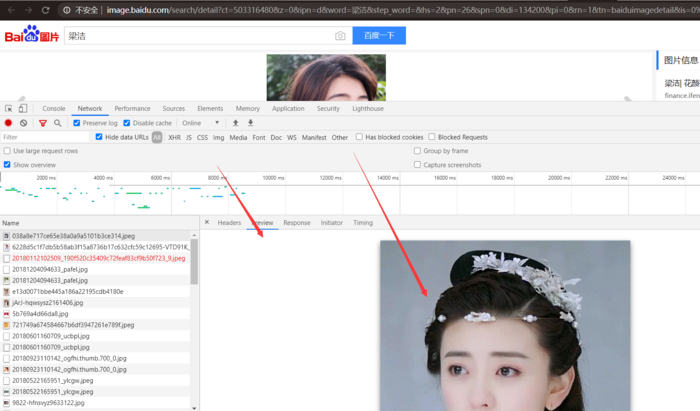
在浏览器开发者工具中点击 Preview,就可以看到网页的源代码,也就是响应体的内容,它是解析的目标。
在做爬虫时,我们主要通过响应体得到网页的源代码、JSON 数据等,然后从中做相应内容的提取。
三、web网页基础
3.1 网页的组成
网页可以分为三大部分 —— HTML、CSS 和 JavaScript。如果把网页比作一个人的话,HTML 相当于骨架,JavaScript 相当于肌肉,CSS 相当于皮肤,三者结合起来才能形成一个完善的网页。下面我们分别来介绍一下这三部分的功能。
3.1.1 html
HTML 是用来描述网页的一种语言。
- HTML 指的是超文本标记语言 (Hyper Text Markup Language)
- HTML 不是一种编程语言,而是一种标记语言 (markup language)
- 标记语言是一套标记标签 (markup tag)
- HTML 使用标记标签来描述网页
HTML 标签
- HTML 标记标签通常被称为 HTML 标签 (HTML tag)。
- HTML 标签是由尖括号包围的关键词,比如
- HTML 标签通常是成对出现的,比如 和
- 标签对中的第一个标签是开始标签,第二个标签是结束标签
- 开始和结束标签也被称为开放标签和闭合标签
HTML 文档 = 网页
- HTML 文档描述网页
- HTML 文档包含 HTML 标签和纯文本
- HTML 文档也被称为网页
Web 浏览器的作用是读取 HTML 文档,并以网页的形式显示出它们。浏览器不会显示 HTML 标签,而是使用标签来解释页面的内容:
<html>
<body>
<h1>我的第一个标题</h1>
<p>我的第一个段落。</p>
</body>
</html>
3.1.2 css
什么是 CSS?
- CSS 指层叠样式表 (Cascading Style Sheets)
- 样式定义如何显示 HTML 元素
- 样式通常存储在样式表中
- 把样式添加到 HTML 4.0 中,是为了解决内容与表现分离的问题
- 外部样式表可以极大提高工作效率
- 外部样式表通常存储在 CSS 文件中
- 多个样式定义可层叠为一个
body {
background-color:#d0e4fe;
}
h1 {
color:orange;
text-align:center;
}
p {
font-family:"Times New Roman";
font-size:20px;
}
3.1.3 JavaScript
JavaScript 是属于 HTML 和 Web 的编程语言。
编程令计算机完成您需要它们做的工作。
JavaScript 是 web 开发人员必须学习的 3 门语言中的一门:
- HTML 定义了网页的内容
- CSS 描述了网页的布局
- JavaScript 控制了网页的行为
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<!-- 编写css文件 需要使用 style -->
<style>
h1{
color: red;
text-align: center;
}
</style>
<body>
<!-- 编写文本 需要使用 h5 标签 -->
<h1 id="text">大家好,我是尘世风</h1>
<p>
</p>
<div>
<img src="https://t9.baidu.com/it/u=2219788502,4244472931&fm=218&app=137&size=f242,150&n=0&f=JPEG&fmt=auto?s=F9231F703F227A15696CD9CD0300A0B3&sec=1658595600&t=4967a0d0d262421dd9926f00a598186e" alt="">
</div>
<button id="xl">
点击我切换数据
</button>
<!-- 编写JS文件 需要使用 script标签 -->
<script>
document.getElementById('xl').onclick = function () {
document.getElementById("text").innerText = '大家好,我是隔壁老王'
}
</script>
</body>
</html>
四、会话和Cookies
在浏览网站的过程中,我们经常会遇到需要登录的情况,有些页面只有登录之后才可以访问,而且登录之后可以连续访问很多次网站,但是有时候过一段时间就需要重新登录。还有一些网站,在打开浏览器时就自动登录了,而且很长时间都不会失效,这种情况又是为什么?其实这里面涉及会话(Session)和 Cookies 的相关知识,本节就来揭开它们的神秘面纱。
4.1.1 无状态 HTTP
在了解会话和 Cookies 之前,我们还需要了解 HTTP 的一个特点,叫作无状态。
-
会话
会话,其本来的含义是指有始有终的一系列动作 / 消息。比如,打电话时,从拿起电话拨号到挂断电话这中间的一系列过程可以称为一个会话。
-
Cookies
Cookies 指某些网站为了辨别用户身份、进行会话跟踪而存储在用户本地终端上的数据。
-
Cookies 列表
- Name,即该 Cookie 的名称。Cookie 一旦创建,名称便不可更改
- Value,即该 Cookie 的值。如果值为 Unicode 字符,需要为字符编码。如果值为二进制数据,则需要使用 BASE64 编码。
- Max Age,即该 Cookie 失效的时间,单位秒,也常和 Expires 一起使用,通过它可以计算出其有效时间。Max Age 如果为正数,则该 Cookie 在 Max Age 秒之后失效。如果为负数,则关闭浏览器时 Cookie 即失效,浏览器也不会以任何形式保存该 Cookie。
- Path,即该 Cookie 的使用路径。如果设置为 /path/,则只有路径为 /path/ 的页面可以访问该 Cookie。如果设置为 /,则本域名下的所有页面都可以访问该 Cookie。
- Domain,即可以访问该 Cookie 的域名。例如如果设置为 .zhihu.com,则所有以 zhihu.com,结尾的域名都可以访问该 Cookie。
- Size 字段,即此 Cookie 的大小。
- Http 字段,即 Cookie 的 httponly 属性。若此属性为 true,则只有在 HTTP Headers 中会带有此 Cookie 的信息,而不能通过 document.cookie 来访问此 Cookie。
- Secure,即该 Cookie 是否仅被使用安全协议传输。安全协议。安全协议有 HTTPS,SSL 等,在网络上传输数据之前先将数据加密。默认为 false
五、socket介绍
参考:http://c.biancheng.net/socket/
什么是 Socket?
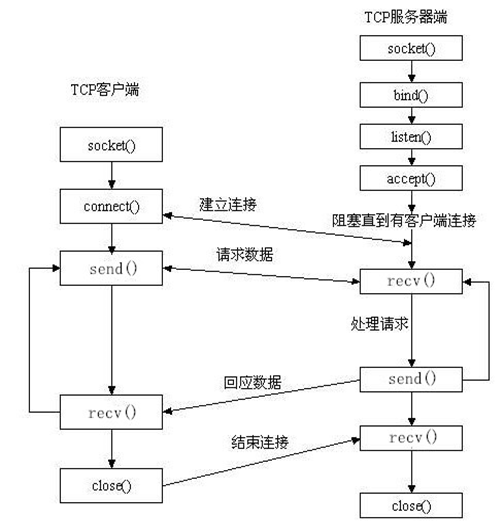
在计算机通信领域,socket 被翻译为“套接字”,它是计算机之间进行通信的一种约定或一种方式。通过 socket 这种约定,一台计算机可以接收其他计算机的数据,也可以向其他计算机发送数据
应该是应用层与传输层间的一个抽象层
参考:https://www.jianshu.com/p/066d99da7cbd
流程图
请求报文格式
套接字对象服务端方法

综合案例---使用socket下载图片
url = 'https://img1.baidu.com/it/u=3028486691,1206269421&fm=253&fmt=auto&app=138&f=JPEG?w=499&h=323'
import socket # socket模块是python自带的内置模块,不需要我们去下载
# 创建套接字客户端
client = socket.socket()
# 访问网站
url = 'img1.baidu.com'
# 端口
port = 80
# 连接,通过(ip,端口)来进行连接
client.connect((url,port))
resq = "GET /it/u=3028486691,1206269421&fm=253&fmt=auto&app=138&f=JPEG?w=499&h=323 HTTP/1.0\r\nHost: img1.baidu.com\r\n\r\n"
# 根据请求头来发送请求信息
client.send(resq.encode())
# 建立一个二进制对象用来存储我们得到的数据
result = b''
data = client.recv(1024)
# 循环接收响应数据 添加到bytes类型
while data:
result+=data
data = client.recv(1024)
import re
# re.S 匹配包括换行在内的所有字符 ,去掉响应头
images = re.findall(b'\r\n\r\n(.*)',result, re.S)
# 打开一个文件,将我们读取到的数据存入进去,即下载到本地我们获取到的图片
with open("可爱的小姐姐.jpg","wb") as f:
f.write(images[0])
六、httpx模块
httpx是Python新一代的网络请求库,它包含以下特点
- 基于Python3的功能齐全的http请求模块
- 既能发送同步请求,也能发送异步请求
- 支持HTTP/1.1和HTTP/2
- 能够直接向WSGI应用程序或者ASGI应用程序发送请求
环境安装
pip install httpx
测试
headers = {'user-agent': 'my-app/1.0.0'}
params = {'key1': 'value1', 'key2': 'value2'}
url = 'https://httpbin.org/get'
r = httpx.get(url, headers=headers, params=params)
爬虫请求案例
# encoding: utf-8
"""
@author:chenshifeng
@file: 爬虫案例.py
@time:2022/10/14
"""
import httpx
import os
class S_wm(object):
def __init__(self):
self.headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36'
}
def get_url_list(self):
url_list = ['https://img1.baidu.com/it/u=1875739781,4152007440&fm=253&fmt=auto&app=120&f=JPEG?w=1024&h=576',
'https://img1.baidu.com/it/u=3980896846,3728494487&fm=253&fmt=auto&app=138&f=JPEG?w=333&h=499',
'https://img1.baidu.com/it/u=467548803,2897629727&fm=253&fmt=auto&app=138&f=JPEG?w=800&h=500',
]
return url_list
def save_image(self,filename,img):
with open(filename, 'wb') as f:
f.write(img.content)
print('图片提取成功')
def run(self):
url_list = self.get_url_list()
for index,u in enumerate(url_list):
file_name = './image/{}.jpg'.format(index)
data = httpx.request('get', u, headers=self.headers)
self.save_image(file_name,data)
if __name__ == '__main__':
url = 'https://www.vmgirls.com/13344.html'
s = S_wm()
if os.path.exists("./image") is False:
os.mkdir('./image')
s.run()
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:爬虫的基本原理 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 