当前,前端对二进制数据有许多的API可以使用,这丰富了前端对文件数据的处理能力,有了这些能力,就能够对图片等文件的数据进行各种处理。
本文将着重介绍一些前端二进制数据处理相关的API知识,如Blob、File、FileReader、ArrayBuffer、TypeArray、DataView等等。
字节
在介绍各种API之前,我们需要先了解下和字节有关的知识。
我们知道,计算机是二进制的世界,而字节(byte)是计算机技术中关于二进制数据的一种基本单位,1字节有8个二进制位,即8比特(bit)。
比特又叫位,一位二进制数据要么是0、要么是1,只有两种状态,所以1比特有2种状态。
1字节有8比特,即8个二进制位,那就能表示 2**8 = 256 种状态,取值从 00000000 到 11111111。
字节作为基本单位,在很多地方都被使用,如字符编码知识,见前文前端需要了解的编码知识。
二进制数据在存储的时候,以字节为单位,这里还涉及到一个关于字节序的知识。
字节序
字节序描述的是计算机如何存储字节。
因为我们知道,内存存储都有索引地址,每个字节对应一个索引地址。一个字节存储8位二进制,即0到255之间,但需要存储大于255的数值的时候,就需要多个字节,多个字节就涉及到排序问题。
所以字节序就是:当需要多个字节表示一个值的时候,这多个字节使用什么样的排序方式在内存中进行存储。
而排序方式主要是两种:大端存储(big-endian)和小端存储(little-endian)。
大端存储和小端存储
大端存储又称大字节序、高字节序,方式是低位字节排在内存中的高地址端,高字节位排放在内存中的低地址端。图片文件 png、jpg都是这种方式。
小端存储又称为小字节序、低字节序,方式是低位字节排在内存中的低地址端,高位字节排在内存中的高地址端。图片文件gif是小端序。
示例
当我们使用不同的字节序存储数字 0x12345678 (这里是16进制表示,对应的十进制:305419896。进制相关知识可见前文Javascript中的进制和进制转换:
大端存储在内存中的存储地址:

小端存储在内存中的存储地址:
这里数字字节的高-低位是从左到右,最高位是 12,最低位是 78;而内存中存储时从左到右是低地址——高地址。
所以在大端序中高位字节的 12 在内存最左边的低地址位,而低字节位 78 则在内存最右边的高地址位;而小端序则正好相反。
从视觉习惯上,大端存储似乎更顺眼,但无论哪种方式,计算的结果都是一样的,只是在计算的时候需要处理这个排序方式,下文会涉及到。
Blob
Blob,即 Binary large Object,本质上是一个二进制对象,该对象表示的是一个不可变、原始数据的类文件对象。
它的不可变,代表它是只读的,不可被改变。
Blob对象的构造函数语法:new Blob(array, options)。
参数array:是一个数据数组,可以是多种对象的数据,包含 ArrayBuffer、Blob、String 等等。
参数options:可选对象,指定两个属性:
type表示Blob对象数据的MIME类型;endings指定包含行结束符\n的字符串如何写入。
我们可以使用构造函数直接创建一个新的 Blob 对象:
const blob = new Blob(['123456789'], {type : 'text/plain'});
新创建的对象实例,结构如下:
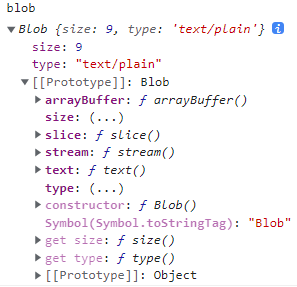
从以上示例,我们就可以看到Blob对象的方法和属性:
- 实例属性
- size:Blob对象中数据的字节大小
- type:字符串,表示Blob对象数据的MIME类型
- 示例方法
- arrayBuffer():返回包含Blob所有内容的二进制格式的ArrayBuffer的一个promise对象
- stream():返回能读取Blob的ReadableStream对象
- text():返回包含Blob所有内容的字符串(UTF-8编码)的一个promise对象
- slice([start [, end [, contentType]]]):
- 该方法有三个可选参数,可用于分割Blob数据
- 它根据指定的起始和结束位置,返回原Blob在该范围的数据,得到一个新的Blob对象
- 第三个参数
contentType可以为新Blob对象指定自己的MIME类型
可以针对上面的 blob 实例进行操作:
blob.slice(0, 3).text().then(res => {
console.log(res)
})
// 结果:123
以上代码,使用slice()方法获取原blob的前三位的数据,生成新的Blob实例后,通过text()方法打印出文本内容。
下面可以看看Blob在接口请求中的应用,Fetch API中的 Response 对象,拥有一个blob方法,能够得到Blob对象。
const imgRequst = new Request('11.jpg')
fetch(imgRequst).then((response) => {
return response.blob()
}).then((mBlob) => {
console.log(mBlob)
})
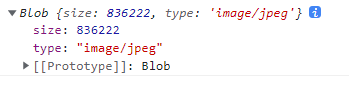
通过以上代码,请求一个jpg图片文件,响应对象通过 blob() 方法转为Blob对象:
File
File对象继承了Blob对象,是一种特殊类型的Blob,它扩展了对系统文件的支持能力。
File提供文件信息,并能够在javascript中进行访问,一般在使用 <input> 标签选择文件时返回,因为 <input> 标签允许选择多个文件,这里返回的是文件列表 files。
除了 <input> 标签以外,还有两种方式返回File对象:
- 自由拖放操作生成的
DataTransfer对象。 - 文件系统访问API中的
FileSystemFileHandle对象的getFile()方法。
File的构造函数:new File(bits, name[, options])。
有三个参数:
- bits:是一个数据数组,可以是多种对象的数据,与Blob对象类似
- name:文件名称
- options:可选属性对象,包含两个选项
- type:MIME类型字符串
- lastModified:时间戳,表示文件的最后修改时间
下面代码,通过 <input> 标签读取文件:
<input id="input-file" type="file" accept="image/*" />
document.getElementById('input-file').onchange = (e) => {
const file = e.target.files[0]
console.log(file)
// ...
}
这是一个简单的图片上传,获取到的file实例,控制台打印出来:
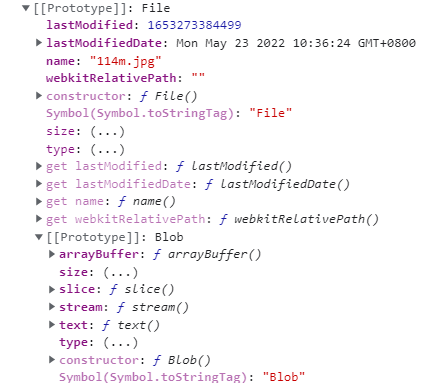
通过上图(chrome浏览器下),可以看到File继承了Blob的素有属性和方法:
- 属性除了size和type以外,File还有自己的几个属性
- lastModified:只读,时间戳,文件最后修改时间
- name:只读,文件名
lastModifiedDate:只读,文件最后修改时间的 Date 对象,该对象已废弃 - webkitRelativePath:非标准属性,返回path或URL
- File没有自己的实例方法,都继承自Blob
对Blob和File的读取
File继承自Blob,都是只读对象,除了使用slice分片以外,并没有其他操作能力,所以如果对它们进行处理需要借助其他的API。
主要用于操作Blob的API有:FileReader、URL.createObjectURL()、createImageBitmap()和XMLHttpRequest.send()。下面将介绍这几种方式。
Blob和File都是
WebAPI,是由浏览器环境提供的,而上面提到这四种对象也同样是WebAPI。
FileReader
FileReader是用于异步读取文件类型(或原始数据缓冲区)的内容,指定Blob或File对象为需要读取的文件数据。
FileReader 不能在文件系统中用路径名的方式读取文件。
构造函数:new FileReader()。
如果对文件处理功能开发较多,对FileReader对象应该较熟,我们先看一个示例:
document.getElementById('input-file').onchange = (e) => {
const file = e.target.files[0]
const reader = new FileReader()
reader.onload = async (event) => {
const img = new Image()
img.src = event.target.result
}
reader.readAsDataURL(file)
}
以上代码,就是很常用的,使用FileReader读取一个图片文件的Base64数据,然后使用图片对象加载。Base64知识,可参考前文深入理解Base64编码字符串。
这段代码也涉及到FileReader对像的属性、事件、方法。
FileReader的属性事件和方法
- 属性(皆只读)
- error:在读取文件时发生的错误
- readyState:表示当前读取状态
常量名 值 状态描述 EMPTY 0 没有加载 LOADING 1 正在加载 DONE 2 已完成全部读取 - result:文件内容,读取状态完成时才有效
- 方法
- abort():中止读取操作。在返回时,readyState属性为DONE
- readAsArrayBuffer():以ArrayBuffer类型读取Blob中的内容
- readAsBinaryString():以原始二进制数据类型读取Blob中的内容
- readAsDataURL():以Base64字符串类型读取Blob中的内容
- readAsText():以文本字符串类型读取Blob中的内容
- 事件
- onabort:读取操作被中断时触发
- onerror:读取操作发生错误时触发
- onload:读取操作完成时触发
- onloadstart:读取操作开始时触发
- onloadend:读取操作结束时触发
- onprogress:读取Blob时触发
URL.createObjectURL()
URL是浏览器环境提供的,用于处理url链接的一个接口对象。可以通过它,解析、构造、规范和编码各种url链接。
而URL提供的一个静态方法 createObjectURL(),可以用来处理Blob和File文件对象。
先看一个例子:
document.getElementById('input-file').onchange = (e) => {
const file = e.target.files[0]
const url = URL.createObjectURL(file)
const img = new Image()
img.onload = () => {
document.body.append(img)
}
img.src = url
}
页面展示:

这段代码就实现了上传图片,通过 URL.createObjectURL 读取后生成一个本地映射的url,再使用Image对象加载图片。
通过查看页面元素,可以看到新添加的图片元素,它的src是一个类似链接的字符串:blob:http://localhost:8088/29c8f4a5-9b47-436f-8983-03643c917f1c,通过这个字符串,图片就能加载显示出来。
再来看 createObjectURL(),它返回一个包含给定的Blob或File对象的url,就可以当做文件资源被加载。而这个url的生命周期和它的窗口同步,窗口关闭这个url就自动释放了。
这个url就是被称为伪协议的Objct URL。
Object URL
Object URL 又被称为Blob URL,一般使用Blob或File对象生成,通过 URL.createObjectURL() 方法创建一个唯一的URL。
Object URL的格式为:blob:origin/唯一标识(uuid)。
上面生成的URL字符串就符合这个格式:blob:http://localhost:8088/29c8f4a5-9b47-436f-8983-03643c917f1c。
- origin 对应的
http://localhost:8088/,如果直接打开本地html文件,则origin为null。 - uuid 对应
29c8f4a5-9b47-436f-8983-03643c917f1c。
浏览器内部会为生成Object URL保持一个 URL 到 Blob 的映射,Blob是留存在内存中,浏览器只有在卸载当前窗口文档时才会释放。
如果要手动释放,则需要URL的另外一个静态方法:URL.revokeObjectURL(),它用于销毁之前创建的URL实例,在合适的时机调用即可销毁Object URL。
URL.revokeObjectURL(url)
XMLHttpRequest.send()
XMLHttpRequest.send(body):用于在XHR的HTTP请求中,发送数据体。
这里的body参数,可以是多种数据类型,包括Blob对象。
const xhr = new XMLHttpRequest()
xhr.send(new Blob())
createImageBitmap()
createImageBitmap(): 主要处理图片资源,接受不同的图片资源对象为参数,并生成一个ImageBitmap对象。
这些参数就就可以是Blob和File对象。
ImageBitmap表示可以绘制在canvas上的位图图像。
createImageBitmap(file).then(imageBitmap => {
const canvas = document.createElement('canvas')
canvas.width = imageBitmap.width
canvas.height = imageBitmap.height
const ctx = canvas.getContext('2d')
ctx.drawImage(imageBitmap, 0, 0)
document.body.append(canvas)
})
如上代码,即可读取图片文件,使用canvas绘制。
ArrayBuffer
ArrayBuffer 对象表示通用的、固定长度的原始二进制缓冲区,它是一个字节数组,但不能直接操作它的内容,而需要通过其他方式(如TypeArray或DataView等)进行处理。
构造函数:new ArrayBuffer(length),返回一个指定大小的ArrayBuffer对象。
参数length:要创建的 ArrayBuffer 的字节大小。大于Number.MAX_SAFE_INTEGER(>= 2 ** 53)或为负数,则抛出一个RangeError异常。
下面我们先使用前面介绍的 FileReader 读取一个文件的ArrayBuffer内容:
document.getElementById('input-file').onchange = (e) => {
const file = e.target.files[0]
const reader = new FileReader()
reader.onload = async (event) => {
console.log(event.target.result)
}
reader.readAsArrayBuffer(file)
}
控制台日志打印输出:
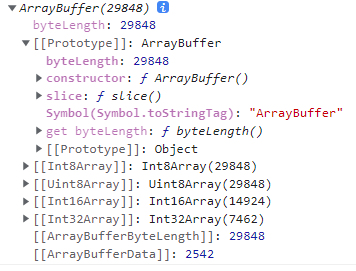
从上图,可以看到ArrayBuffer的实例属性和方法:
- byteLength:表示字节大小,不可改变
- slice(begin[, end]):根据指定位置范围返回一个新的ArrayBuffer,可以分割ArrayBuffer。
ArrayBuffer还有静态属性和方法:
- ArrayBuffer.length:构造函数的length属性,值为1
- ArrayBuffer.isView(arg):如果参数是ArrayBuffer的视图实例则返回true。
由于我们无法直接操作ArrayBuffer,所以需要使用其他对象来处理,下面将介绍其中两种。
TypeArray
TypeArray,即类型化数组,它描述了二进制数据缓冲区的一个类数组。TypeArray本身不是一个可用的对象,只是一个辅助的数据类型,作为所有类型数组的构造原型,真正可用的类型数组包含了多种,如Int8Array、Uint8Array等。
常用的类型数组如下表所示:
| 对象 | 元素所占字节数 | 取值范围 | 描述 |
|---|---|---|---|
| Int8Array | 1 | -128 - 127 | 8 位有符号整型数组 |
| Uint8Array | 1 | 0 - 255 | 8 位无符号整型数组 |
| Uint8ClampedArray | 1 | 0 - 255 | 8 位无符号整型固定数组 |
| Int16Array | 2 | -32768 - 32767 | 16 位有符号整型数组 |
| Uint16Array | 2 | 0 - 65535 | 16 位无符号整型数组 |
| Int32Array | 4 | -2147483648 - 2147483647 | 32 位有符号整型数组 |
| Uint32Array | 4 | 0 - 4294967295 | 32 位无符号整型数组 |
| Float32Array | 4 | 1.2×10**-38 to 3.4×10**38 |
32 位浮点数型数组 |
| Float64Array | 8 | 5.0×10**-324 to 1.8×10**308 |
64 位浮点数型数组 |
| BigInt64Array | 8 | -2**63 to 2**63-1 |
64 位有符号数型数组 |
| BigUint64Array | 8 | 0 to 2**64-1 |
64 位无符号整型数组 |
类型化数组与普通数据也较相似,同样拥有一系列的方法和属性,但不支持 push、pop、shift、unshift、splice 等可以改变原数组的增删改方法。
类型化数组由于定义了数据类型,则各元素必须是同类型的数据,不能像普通数据那样元素可以是不同类型;当元素数据类型固定统一时,处理效率更优。
各类型数组在构造函数、属性、方法等语法上相同,下面就以 Uint8Array 为例。
语法
Uint8Array构造函数:
new Uint8Array()
new Uint8Array(length)
new Uint8Array(typedArray)
new Uint8Array(object)
new Uint8Array(buffer [, byteOffset [, length]])
length 参数的最大取值
8 位类数组是 2145386496
16 位类数组是 1072693248
32 位类数组是 536346624
32 位类数组是 268173312
静态属性和方法
- BYTES_PER_ELEMENT:返回数组元素所占字节数,Uint8Array中的值是1,Uint32Array中的值是4,见上表
- length:固定长度,Uint8Array中的值是1,Uint32Array中的值是3,基本没用
- name:类型数组返回自己的构造名,Uint8Array类型返回
Uint8Array,Uint32Array类型返回Uint32Array等等 - from(source[, mapFn[, thisArg]]):从源类型数组中返回一个新的数组
- of(element0[, element1[, ...[, elementN]]]):创建一个具有可变数量参数的新类型数组
实例属性和方法
介绍完静态属性和方法,下面通过一个示例,来查看下Uint8Array的实例属性和方法,代码如下。
const reader = new FileReader()
reader.onload = async (event) => {
const aBuffer = event.target.result
const uint8Array = new Uint8Array(aBuffer)
console.log(uint8Array)
}
reader.readAsArrayBuffer(file)
以上代码,直接读取文件的ArrayBuffer数据,然后通过 Uint8Array 构造函数,得到Uint8Array实例,控制台查看:

通过加载一张png图片,得到它的Uint8Array数组数据,可以看到类型数组大部分的属性和方法都和普通数组类似,除了前文提到的增删改数组的方法以外。因此,对类型数组使用下标、循环等等方式进行读取,和普通函数没什么两样。
而类型数组也自己的特殊属性(都只读)和方法,如下:
- buffer:返回类型数组引用的ArrayBuffer
- byteLength:字节数长度
- byteOffset:相对源ArrayBuffer的偏移字节数
- length:数组长度
- set(array[, offset]):从给定数组中读取元素值,并存储在类型数组中
- subarray(begin, end):给定开始和结尾索引,返回一个新的类型数组
类型数组间的关系
要了解常见类型数组间的关系,我们先看下面这张图:
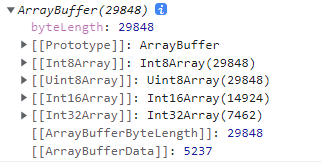
图上所示,是一张png图片的ArrayBuffer数据,可以看到,ArrayBuffer的字节长度属性默认取8位整型数组的长度,即与Int8Array和Uint8Array的长度一致。
而Int8Array的长度29848,正好是Int16Array的长度14924的两倍,是Int32Array的长度7462的四倍,可知,这里就是对字节的合并计算:
- Int8Array(Uint8Array) 转 Int16Array(Uint16Array),需要依序合并两个字节后计算数值。
- Int8Array(Uint8Array) 转 Int32Array(Uint32Array),需要依序合并四个字节后计算数值。
- Int16Array(Uint16Array) 转 Int32Array(Uint32Array),需要依序合并两个字节后计算数值。
读取GIF文件示例
类型数组通过数组的方式对ArrayBuffer的内容进行读取操作,可以方便我们处理文件的二进制数据。
但使用类型数组的时候,碰到多字节的数据时,需要考虑字节序的问题。
下面,我们以读取小端存储的GIF图片为例。
GIF图片的Uint8Array数组数据中,宽高数据的存储就是使用了两个字节,第7-8位存储图片的宽度,9-10位存储图片的高度。
我们加载的GIF图片宽高皆为600,需要处理字节序,代码如下:
const uint8Array = new Uint8Array(aBuffer)
let bufferIndex = 6
// 获取GIF宽度的两个字节的值
const width1 = uint8Array[bufferIndex]
// width1 结果:88
const width2 = uint8Array[bufferIndex + 1]
// width2 结果:2
// 得到各自的16进制数据
const width1hex = width1.toString(16)
const width2hex = width2.toString(16)
// 转换成实际的宽度大小,注意这里把两个字节的顺序做了调整,符合小端序
const width = parseInt(width2hex + width1hex, 16)
// width 结果:600
使用小端序处理后,宽度结果等于600,符合图片实际宽度。
自己手动处理字节序会稍显麻烦,如果不想手动去处理字节序的问题,可以使用另外一个对象:DataView。
DataView
DataView 是一个从 ArrayBuffer 中读取多种类型数值并且不用考虑字节序的接口对象。它的使用简单方便,拥有一系列的 get- 和 set- 实例方法操作数据。
DataView的构造函数:new DataView(buffer [, byteOffset [, byteLength]])。
参数:
- buffer:源ArrayBuffer
- byteOffset:buffer中的字节偏移量
- byteLength:字节长度
DataView不用考虑字节序,同样是读取GIF的宽度时,代码可简化:
const fileDataView = new DataView(arrBuffer)
let bufferIndex = 6
const width = fileDataView.getUint16(bufferIndex, true)
// 结果:600
bufferIndex += 2
const height = fileDataView.getUint16(bufferIndex, true)
// 结果:600
以上代码,很方便就得到GIF图片的宽高数据(600),因为使用了 DataView 和它的 getUint16 方法,不需要手动处理字节序。getUint16 方法有两个参数:第一个参数代表字节索引;第二参数表示字节序,默认大端序,为true则是小端序,GIF是小端,所以上面代码为true。
除了getUint16以外,DataView 还有十多个类似的实例方法。
DataView的get和set系列方法
get系列方法通过字节偏移索引获取对应的数值,其中多字节的数据,需要两个参数:
- byteOffset:读取时的字节偏移量
- littleEndian:字节序,默认大端,设为true则是小端
| 名称 | 参数 | 描述 |
|---|---|---|
| getInt8 | (byteOffset) | 有符号 8-bit 整数(1个字节) |
| getUint8 | (byteOffset) | 无符号 8-bit 整数(1个字节) |
| getInt16 | (byteOffset [, littleEndian]) | 16-bit数(短整型,2个字节) |
| getUint16 | (byteOffset [, littleEndian]) | 16-bit数(无符号短整型,2个字节) |
| getInt32 | (byteOffset [, littleEndian]) | 32-bit数(长整型,4个字节) |
| getUint32 | (byteOffset [, littleEndian]) | 32-bit数(无符号长整型,4个字节) |
| getFloat32 | (byteOffset [, littleEndian]) | 32-bit浮点数(单精度浮点数,4个字节) |
| getFloat64 | (byteOffset [, littleEndian]) | 64-bit数(双精度浮点型,8个字节) |
| getBigInt64 | (byteOffset [, littleEndian]) | 带符号的64位整数(long long类型)值 |
| getBigUint64 | (byteOffset [, littleEndian]) | 无符号的64位整数(unsigned long long类型)值 |
set系列方法是和get方法对应的,处理相应字节偏移索引位置的数值,参数如下:
- byteOffset:读取时的字节偏移量
- value:设置相应类型的数值
- littleEndian:字节序,默认大端,设为true则是小端
| 名称 | 参数 | 描述 |
|---|---|---|
| setInt8 | (byteOffset, value) | 8-bit数(一个字节) |
| setUint8 | (byteOffset, value) | 8-bit数(无符号字节) |
| setInt16 | (byteOffset, value [, littleEndian]) | 16-bit数(短整型) |
| setUint16 | (byteOffset, value [, littleEndian]) | 16-bit数(无符号短整型) |
| setInt32 | (byteOffset, value [, littleEndian]) | 32-bit数(长整型) |
| setUint32 | (byteOffset, value [, littleEndian]) | 32-bit数(无符号长整型) |
| setFloat32 | (byteOffset, value [, littleEndian]) | 32-bit数(浮点型) |
| setFloat64 | (byteOffset, value [, littleEndian]) | 64-bit数(双精度浮点型) |
| setBigInt64 | (byteOffset, value [, littleEndian]) | 带符号的64位整数(long long类型)值 |
| setBigUint64 | (byteOffset, value [, littleEndian]) | 无符号的64位整数(unsigned long long类型)值 |
Blob和ArrayBuffer
对于Blob和ArrayBuffer两个对象,我们可以稍做总结:
- Blob是Web API,浏览器环境提供,读取它可以使用FileReader、URL.createObjectURL等WebAPI;ArrayBuffer是JS语言内置对象,处理它则需要使用TypeArray、DataView等JS-API。
- Blob表示不可变的类文件数据;ArrayBuffer则表示原始数据缓冲区。
- Blob用于读取类文件数据,不对应内存;ArrayBuffer用于读取内存数据。
- Blob和ArrayBuffer都需要通过其他对象才能操作数据。
- Blob和ArrayBuffer可以使用不同方式进行相互之间的转换。
- 要操作字节二进制数据,得依赖ArrayBuffer和辅助它的操作对象。
Blob和ArrayBuffer之间的转换:
- 使用Blob构造函数可以读取ArrayBuffer,生成一个新的Blob。
- 通过Blob实例的arrayBuffer()方法,可以获取到对应的ArrayBuffer。
- 通过FileReader对象的readAsArrayBuffer()方法,将Blob读取为ArrayBuffer。
如下代码:
const aBuffer = new ArrayBuffer(4)
// 使用Blob构造函数
const blob = new Blob([aBuffer])
// Blob的arrayBuffer()方法(promise)
blob.arrayBuffer()
// FileReader
const reader = new FileReader()
reader.readAsArrayBuffer(blob)
原文链接:https://www.cnblogs.com/jimojianghu/p/17292186.html
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:深入理解前端字节二进制知识以及相关API - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 