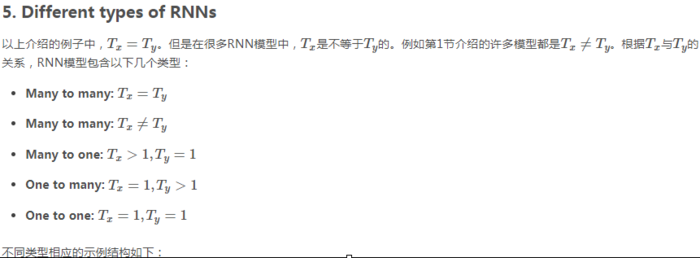
1.1 为什么选择序列模型
序列模型的应用
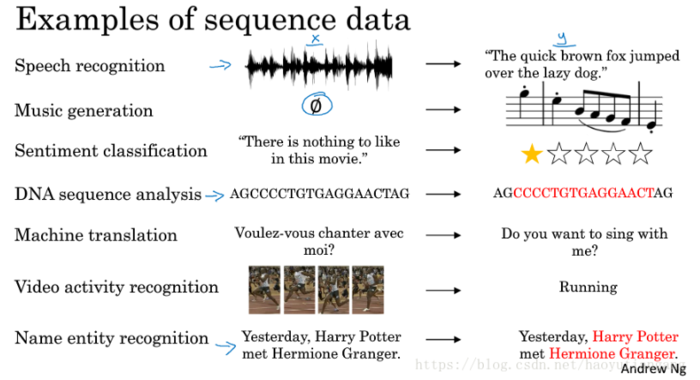
语音识别:将输入的语音信号直接输出相应的语音文本信息。无论是语音信号还是文本信息均是序列数据。
音乐生成:生成音乐乐谱。只有输出的音乐乐谱是序列数据,输入可以是空或者一个整数。
情感分类:将输入的评论句子转换为相应的等级或评分。输入是一个序列,输出则是一个单独的类别。
DNA序列分析:找到输入的DNA序列的蛋白质表达的子序列。
机器翻译:两种不同语言之间的想换转换。输入和输出均为序列数据。
视频行为识别:识别输入的视频帧序列中的人物行为。
命名实体识别:从输入的句子中识别实体的名字。

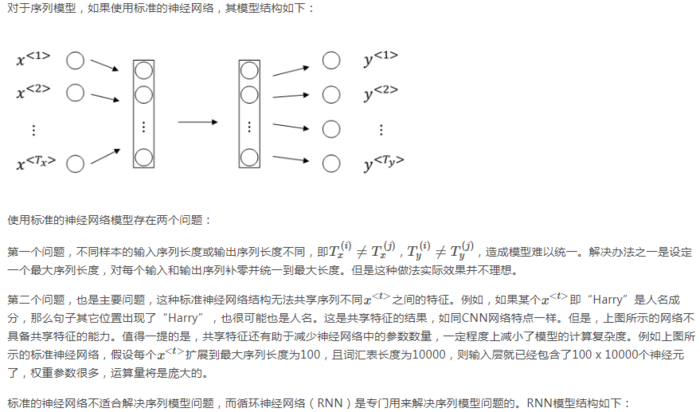
这些序列模型基本都属于监督式学习,输入x和输出y不一定都是序列模型。如果都是序列模型的话,模型长度不一定完全一致。
1.2 数学符号
符号含义

字典编码
利用一个字(词)典向量,通常有3-5万个字(词)。
可以利用one-hot编码,指出输入的序列中每个单词的向量
与字典向量大小一致
是单词的索引位置1,其他位置0

从上图可以看出字典里一共有10000个单词,从a开始,到zulu为止,这10000个单词排列成为一个1*10000的列向量。对于Harry这个单词,其对应的向量X(1)如上图,因为Harry这个词位于词典中的第4075个位置,所以X(1)就是第4075个元素为1,其余全为零的1*10000的列向量。
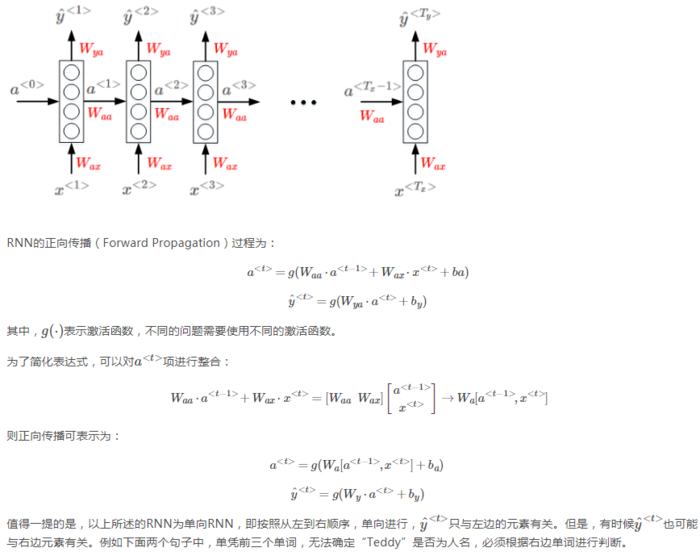
1.3 循环神经网络模型
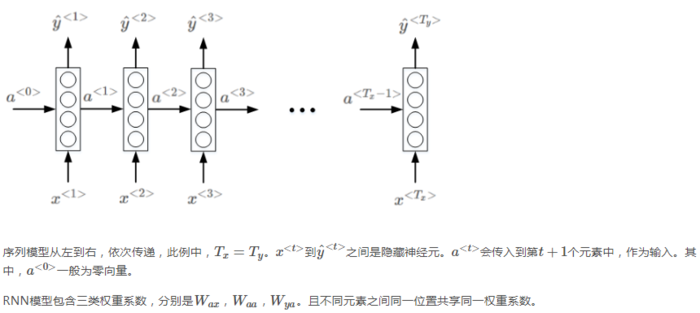
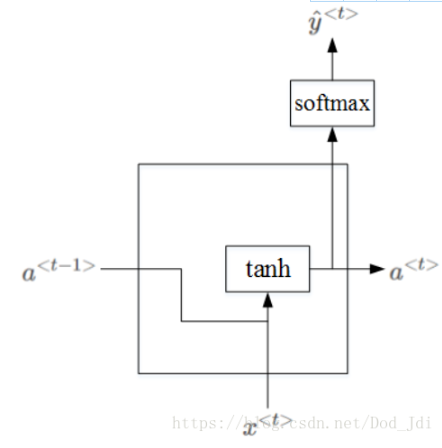
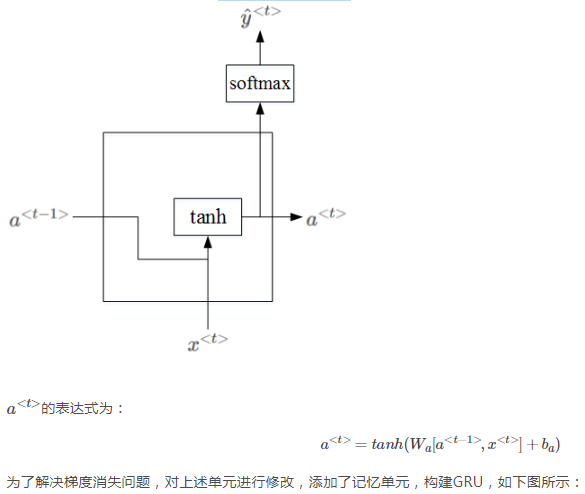
网络内部结构(激活函数是tanh):

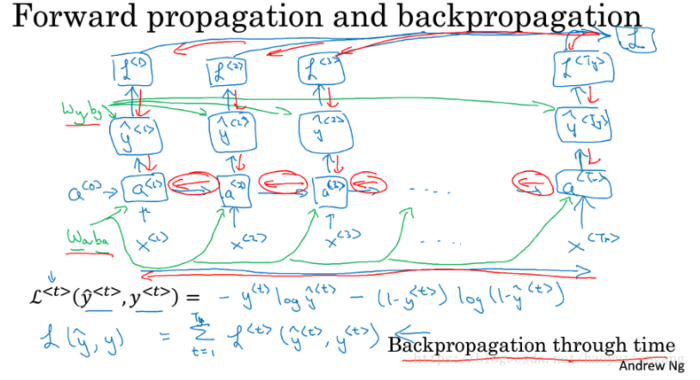
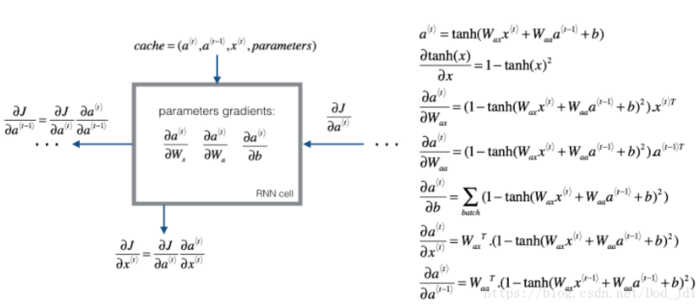
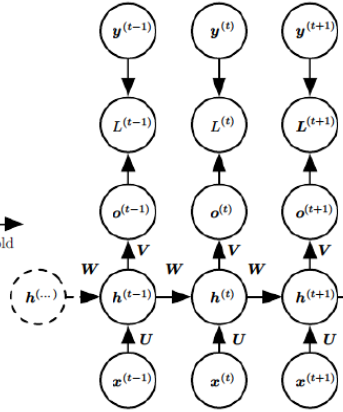
简单说一下反向传播的过程,假设上图是一个完整的RNN,h(···)就是a0。L=L(t-1)+L(t)+L(t+1)。上图有三个W,从左到右命名为W123,最终的dw=1/3*(dw1+dw2+dw3)。上图中的h就是之前的a。下面是参数w的反向传播计算过程:
dw3=L(t+1)对w3的偏导=L(t+1)对h(t+1)的偏导* h(t+1) 对w3的偏导=dh(t+1)* h(t+1) 对w3的偏导
dw2=L(t)对w2的偏导+L(t+1)对w2的偏导=L(t)对h(t)的偏导*h(t) 对w2的偏导+L(t+1)对h(t)的偏导*h(t) 对w2的偏导=(L(t)对h(t)的偏导 +L(t+1)对h(t)的偏导)*h(t) 对w2的偏导=dh(t)*h(t) 对w2的偏导=(L(t)对h(t)的偏导 +L(t+1)对h(t+1)的偏导*h(t+1)对h(t)的偏导)*h(t) 对w2的偏导=(L(t)对h(t)的偏导 +dh(t+1)*h(t+1)对h(t)的偏导)*h(t) 对w2的偏导
同理可求 dw1=dh(t-1)*h(t-1) 对w1的偏导=(L(t-1)对h(t-1)的偏导 +dh(t)*h(t)对h(t-1)的偏导)*h(t-1) 对w1的偏导
反向传播的核心就是多元函数求导法则:
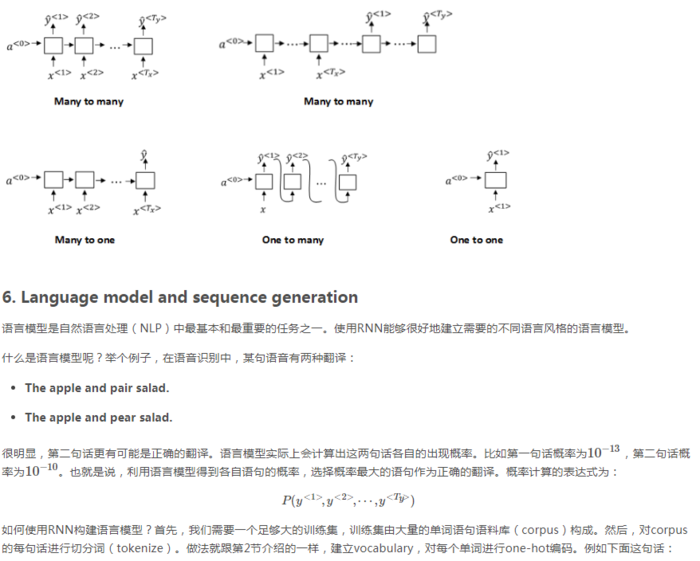
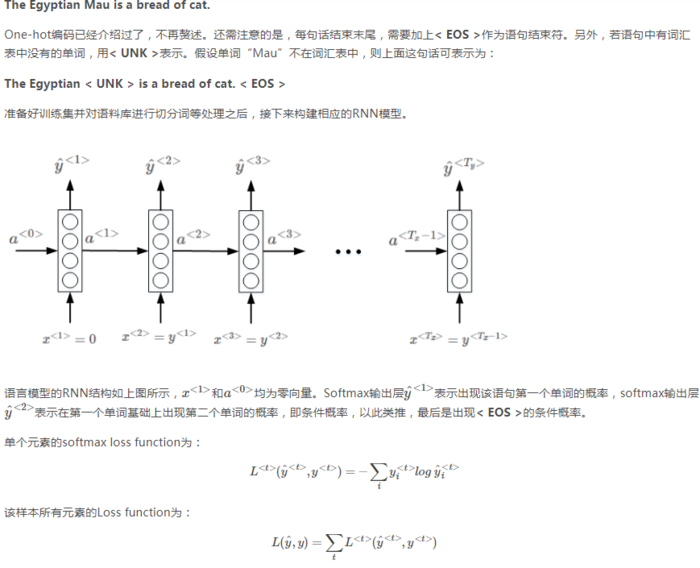

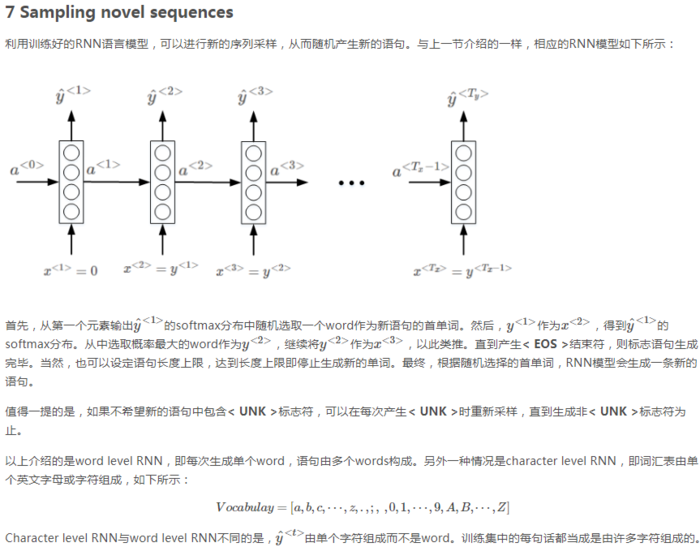
以 Cat eat fish. 这句为例,演示一下计算这句话的概率过程:
这句话的概率P=第一个单词是cat的概率*第一个单词是cat时第二个词是eat的概率*第一个单词是cat第二个词是eat时第三个词是fish的概率*第一个单词是cat第二个词是eat第三个词是fish时第四个词是.(EOS)的概率 最后这个概率可有可无,因为有时不把EOS放在词典里。
1.先从y1帽里找到第一个词是cat的概率P1
2.令x2=y1即令x2=cat对应的列向量。 这个列向量就是之前说的one-hot,然后从y2帽里找到第二个词是eat的概率P2
3.令x3=y2即令x3=eat对应的列向量。 然后从y3帽里找到第三个词是fish的概率P3
4.令x4=y3即令x4=fish对应的列向量。 然后从y3帽里找到第四个词是.(EOS)的概率P4
最后的概率P=P1*P2*P3*P4
上述是求概率的问题,那么如果生成一个有三个单词的句子,过程是怎样的?
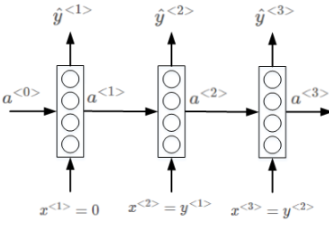
流程图与上图类似,只不过y1和y2不是提前知道的了。首先从y1帽里找出来最高概率的词A,y1就是该词对应的O向量,即对应位置为1,其它全为零。然后再从y2帽里找出来最高概率的词B,y2就是该词对应的O向量,即对应位置为1,其它全为零。然后得到y3帽,从y3帽里找出最高概率的词C。A B C就是生成的含三个单词的句子。

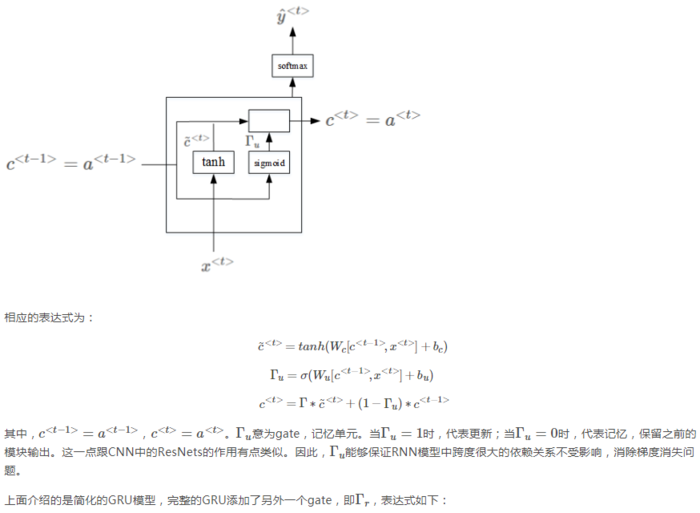 左图中的第三次式子的第一个伽马漏了下标u
左图中的第三次式子的第一个伽马漏了下标u
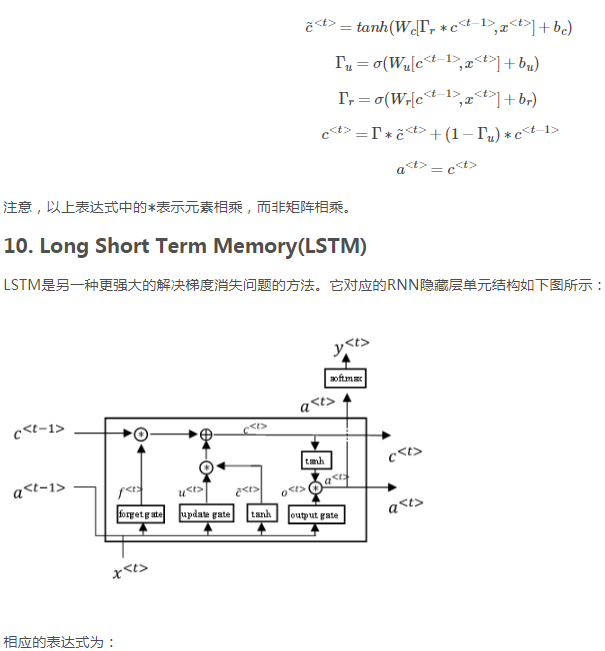

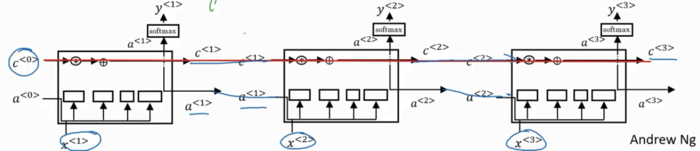
上图是三个单元连接在一起的LSTM的简图。下边这条线是a,上边这条是c。只要合理设置遗忘门和更新门,LSTM就能把C0的值一直向右传递,传递给C3。
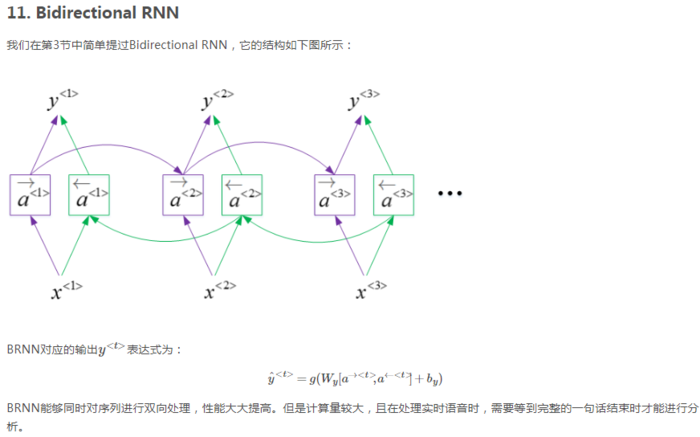
双向RNN的工作过程:首先进行正向计算:依次算出a1→、a2→、a3→,然后进行反向计算:依次算出a3←、a2←、a1←。然后再由a1→和a1←算出y1,由a2→和a2←算出y2,以此类推。
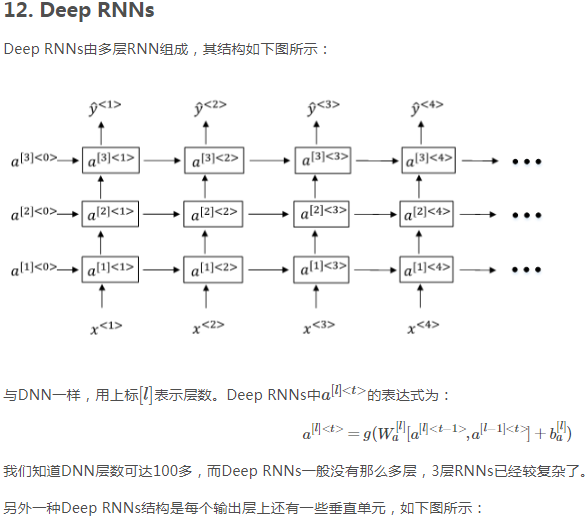
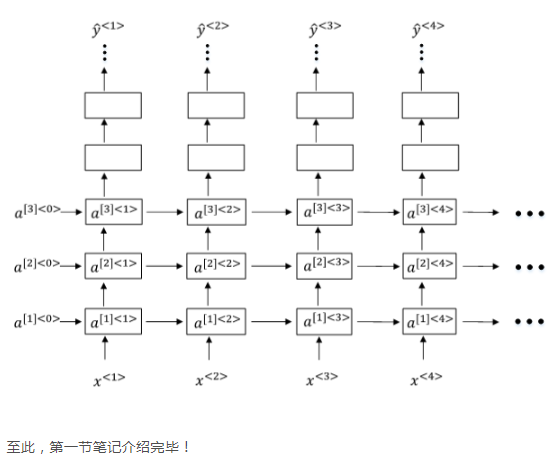
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:【69】循环神经网络 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 