完整代码及其数据,请移步小编的GitHub地址
传送门:请点击我
如果点击有误:https://github.com/LeBron-Jian/DeepLearningNote
本节主要学习Keras的应用模块 Application提供的带有预训练权重的模型,这些模型可以用来进行预测,特征提取和 finetune,上一篇文章我们使用了VGG16进行特征提取和微调,下面尝试一下其他的模型。
模型的预训练权重将下载到 ~/.keras/models/ 并在载入模型时自动载入,当然我们也可以下载到自己的目录下,但是需要去源码修改路径。
模型的官方下载路径:https://github.com/fchollet/deep-learning-models/releases
TensorFlow VGG-16预训练模型:https://github.com/ry/tensorflow-vgg16
ImageNet上的预训练模型参考文献:https://www.jianshu.com/p/7e13a498bd63
1,预训练模型的定义
1.1 机器学习为什么要训练模型?
在机器学习中大概有如下步骤:确定模型,训练模型,使用模型。
模型简单来说可以理解为函数,确定模型时说自己认为这些数据的特征符合哪个函数。训练模型就是使用已有的数据,通过一些方法(最优化或者其他方法)确定函数的参数,参数确定后的函数就是训练的结果,使用模型就是将新的数据代入函数求值。
一个模型中,有很多参数,有些参数,可以通过训练获得,比如logistic模型中的权重。但是有些参数,通过训练无法获得,被称为“超参数”,比如学习率等。这需要靠经验,过着gird search的方法去寻找。
1.2 预训练模型的由来
预训练模型是深度学习架构,已经过训练以执行大量数据上的特定任务(例如,识别图片上的分类问题)。这种训练不容易执行,并且需要大量的资源,超出许多可用于深度学习模型的人可用的资源。在谈论预训练模型的时候,通常指的时在ImageNet(http://image-net.org/)上训练的CNN(用于视觉相关任务的架构)。ImageNet数据包含超过1400万个图像,其中120万个图像分为1000个类别(大约100万个图像含边界框和注释)。
1.3 预训练模型的定义
预训练模型是在训练结束时结果比较好的一组权重值,研究人员分享出来供其他人使用。我们可以在GitHub上找到许多具有权重的库,但是在获取预训练模型的最简单的方法可能是直接来自你选择的深度学习库。
上面是预训练模型的规范定义,你还可以找到预训练的模型来执行其他任务,例如物体检测或姿势估计。
此外,最近研究人员已开始突破预训练模型的界限。在自然语言处理(使用文本的模型)的上下文中,我们已经有一段时间使用嵌入层。Word嵌入是一组数字的表示,其中的想法是类似的单词将以某种有用的方式表达。例如,我们可能希望\'鹰派\',\'鹰\',\'蓝杰伊\'的表现形式有一些相似之处,并且在其他方面也有所不同。用矢量表示单词的开创性论文是word2vec,这篇嵌入层的论文是我最喜欢的论文之一,最早源于80年代,Geoffrey Hinton 的论文。
尽管通过对大型数据集进行训练获得的单词的表示非常有用(并且以与预训练模型类似的方式共享),但是将单词嵌入作为预训练模型会有点拉伸。然而,通过杰里米霍华德和塞巴斯蒂安鲁德的工作,真正的预训练模型已经到达NLP世界。它们往往非常强大,围绕着首先训练语言模型(在某种意义上理解某种语言中的文本而不仅仅是单词之间的相似性)的概念,并将其作为更高级任务的基础。有一种非常好的方法可以在大量数据上训练语言模型,而不需要对数据集进行人工注释。这意味着我们可以在尽可能多的数据上训练语言模型,比如整个维基百科!然后我们可以为特定任务(例如,情感分析)构建分类器并对模型进行微调,其中获取数据的成本更高。要了解有关这项非常有趣的工作的更多信息,请参阅论文虽然我建议先看看随附的网站,了解全局。
1.4 为什么要使用预训练模型呢?
目前在深度学习神经网络中,训练过程是基于梯度下降法来进行参数调优的。通过一步步的迭代,来求得最小的损失函数和最优的模型权重。进行梯度下降时给每一个参数赋一个初始值。一般我们希望数据和参数的均值都为0,输入和输出的方法一致。在实际应用中,参数服从高斯分布或者均匀分布都是比较有效的初始化方法。
模型的作者已经给出了基准模型,这样我们可以使用预训练模型,而无需从头开始构建模型来解决类似的问题。
尽管需要进行一些微调,但这为我们节省了大量的时间和计算资源。
一个好的初始化优势都有哪些呢?
- 1,加速梯度下降的收敛速度
- 2,更有可能获得一个低模型误差,或者低泛化误差的模型
- 3,降低因未初始化或初始化不当导致的梯度消失或者梯度爆炸问题。此情况会导致模型训练速度变慢,崩溃,直到失败
- 4,其中随机初始化,可以打破对称性,从而保证不同的隐藏单位可以学到不同的东西。
1.5 什么是finetuning?
finetuning就是使用已用于其他目标,预训练好的权重或者部分权重,作为初始值开始训练,那么为什么我们不用随机选取的几个数作为权重初始值?原因很简单,第一,自己从头训练卷积神经网络容易出现问题,第二,finetuning能很快收敛到一个较理想的状态,省时又省心。
那么finetuning的具体做法是什么?
- 复用相同层的权重,新定义层取随机权重初始值
- 调大新定一层的学习率,调小服用层学习率
1.6 预训练模型最好结果
2018年NLP领域取得最重大突破!谷歌AI团队新发布的BERT模型,在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩:全部两个衡量指标上全面超越人类,并且还在11种不同NLP测试中创出最佳成绩。毋庸置疑,BERT模型开启了NLP的新时代!而谷歌提出的BERT就是在OpenAI的GPT的基础上对预训练的目标进行了修改,并用更大的模型以及更多的数据去进行预训练,从而得到了目前为止最好的效果。
旁注:如何从头开始训练架构以获得预训练的重量?这根本不容易回答,而且相关信息相当稀少。从纸张到纸张需要大量的跳跃才能将训练的所有方面(增强,训练 - 测试分裂,重量衰减,时间表等)拼凑在一起。我试着破解其中一些我过去做过的实验,你可以在这里或这里看看这些尝试。更有趣的是DAWNBench比赛网站。在这里,各个团队已经尝试将他们的神经网络训练到某种程度的准确性,同时提高资源使用效率和优化速度。这通常不是架构最初如何训练,而是一个非常有用的信息源(因为代码也可用)。
1.7 TensorFlow VGG-16预训练模型
参考博文:https://blog.csdn.net/daydayup_668819/article/details/70225244
在我们的实际项目中,一般不会直接从第一层直接开始训练,而是通过在大的数据集上(如ImageNet)训练好的模型,把前面那些层的参数固定,在运用到我们新的问题上,修改最后一到两层,用自己的数据去微调(finetuning),一般效果也很好。
所谓finetuning,就是说我们针对某相似任务已经训练好的模型,比如CaffeNet,VGG-16,ResNet等,再通过自己的数据集进行权重更新,如果数据量比较小,可以只更新最后一层,其他层的权重不变,如果数据量中等,可以训练后面几层,如果数据量很大,那OK,直接从头训练,只不过花在训练的时间比较多。
在网络训练好之后,只需要forward过程就能做预测,当然,我们也可以直接把这个网络当成一个feature extractor 来用,可以直接用任何一层的输出作为特征,根据R-CNN对AlexNet的实验结果,如果不做 fine-tuning,pool5和fc6和fc7的特征效果并没有很强的提升,所以如果直接用作feature extractor,直接用pool的最后一层输出就OK。
VGG-16是一种深度卷积神经网络模型,16表示其深度。模型可以达到92.7%的测试准确度,它的数据集包括1400万张图像,1000个类别。
2,模型文档
Keras的应用模块(keras.applications)提供了带有预训练权重的深度学习模型,这些模型可以用来进行预测,特征提取和微调(fine-tuning)。
2.1 模型概览
在ImageNet上预训练过的用于图像分类的模型:
- Xception
- VGG16
- VGG19
- ResNet, ResNetV2, ResNeXt
- InceptionV3
- InceptionResNetV2
- MobileNet
- MobileNetV2
- DenseNet
- NASNet
模型的top-1准确率和 top-5准确率分别如下(均是在ImageNet验证集上的结果)
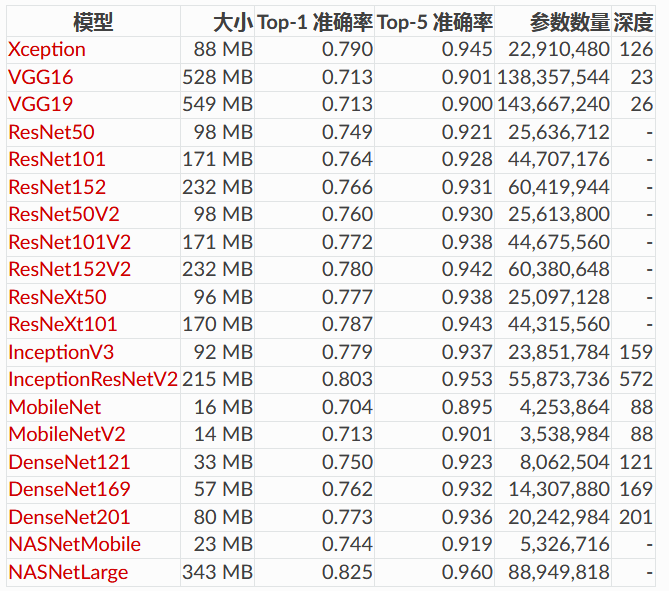

(其中Depth 表示网络拓扑深度。这包括激活层等)
下面对Keras中几个模型进行详细说明(官网地址:https://keras-cn.readthedocs.io/en/latest/legacy/other/application/ https://keras.io/zh/applications/)
2.2 Xception模型
keras.applications.xception.Xception(include_top=True,
weights=\'imagenet\', input_tensor=None,
input_shape=None, classes=1000)
Xception V1模型,权重由 ImageNet 训练而言,在ImageNet上,该模型取得了验证集 top1 0.790 和 top 5 0.945 的正确率。
注意,该模型目前仅能以 TensorFlow 为后端使用,由于它依赖于 “Separable Convolution”层,目前该模型只支持 tf 的维度顺序(width,height,channels)。
默认输入图片大小为 299*299
参数:
- include_top:是否保留顶层的3个全连接网络
- weights:None代表随机初始化,即不加载预训练权重,“Imagenet”表示加载预训练权重
- input_tensor:可填入Keras tensor 作为模型的图像输出 tensor
- input_shape:可选,仅当 include_top=False 有效,应为长为3的 tuple,指明输入图片的 shape,图片的宽高必须大于 71,如(150, 150, 3)
- classes:可选,图片分类的类别数,仅当 include_top=True 并且不加载预训练权重时可用。
返回值:
Keras模型对象
参考文献:
https://arxiv.org/abs/1610.02357
2.3 VGG16模型
keras.applications.vgg16.VGG16(include_top=True, weights=\'imagenet\',
input_tensor=None, input_shape=None,
classes=1000)
vgg16模型,权重由 ImageNet 训练
该模型在 Theano和TensorFlow后端均可使用,并接受th和tf两种输入维度顺序
模型的默认输入尺寸为 224*224
参数:
- include_top:是否保留顶层的3个全连接网络
- weights:None代表随机初始化,即不加载预训练权重,“Imagenet”表示加载预训练权重
- input_tensor:可填入Keras tensor 作为模型的图像输出 tensor
- input_shape:可选,仅当 include_top=False 有效,应为长为3的 tuple,指明输入图片的 shape,图片的宽高必须大于 48,如(200, 200, 3)
- pooling:当 include_top=False时,该参数指定了池化方式。None代表不池化,最后一个卷积层的输出为 4D张量,‘avg’代表全局平均池化,‘max’代表全局最大值池化
- classes:可选,图片分类的类别数,仅当 include_top=True 并且不加载预训练权重时可用。
返回值:
Keras模型对象
参考文献:
https://arxiv.org/abs/1409.1556
2.4 VGG19模型
keras.applications.vgg19.VGG19(include_top=True, weights=\'imagenet\',
input_tensor=None, input_shape=None,
classes=1000)
vgg19模型,权重由 ImageNet 训练
该模型在 Theano和TensorFlow后端均可使用,并接受th和tf两种输入维度顺序
模型的默认输入尺寸为 224*224
参数:
- include_top:是否保留顶层的3个全连接网络
- weights:None代表随机初始化,即不加载预训练权重,“Imagenet”表示加载预训练权重
- input_tensor:可填入Keras tensor 作为模型的图像输出 tensor
- input_shape:可选,仅当 include_top=False 有效,应为长为3的 tuple,指明输入图片的 shape,图片的宽高必须大于 48,如(200, 200, 3)
- pooling:当 include_top=False时,该参数指定了池化方式。None代表不池化,最后一个卷积层的输出为 4D张量,‘avg’代表全局平均池化,‘max’代表全局最大值池化
- classes:可选,图片分类的类别数,仅当 include_top=True 并且不加载预训练权重时可用。
返回值:
Keras模型对象
参考文献:
https://arxiv.org/abs/1409.1556
预训练权重由牛津VGG组发布的预训练权重移植而来
2.5 ResNet50模型
keras.applications.resnet50.ResNet50(include_top=True,
weights=\'imagenet\', input_tensor=None,
input_shape=None, classes=1000)
50层残差网络模型,权重由 ImageNet 训练
该模型在Theano和TensorFlow后端均可使用,并接受 th 和 tf两种输入维度顺序
默认输入图片大小为 299*299
参数:
- include_top:是否保留顶层的3个全连接网络
- weights:None代表随机初始化,即不加载预训练权重,“Imagenet”表示加载预训练权重
- input_tensor:可填入Keras tensor 作为模型的图像输出 tensor
- input_shape:可选,仅当 include_top=False 有效,应为长为3的 tuple,指明输入图片的 shape,图片的宽高必须大于 71,如(150, 150, 3)
- classes:可选,图片分类的类别数,仅当 include_top=True 并且不加载预训练权重时可用。
返回值:
Keras模型对象
参考文献:
https://arxiv.org/abs/1512.03385
2.6 Inception V3模型
keras.applications.inception_v3.InceptionV3(include_top=True,
weights=\'imagenet\', input_tensor=None,
input_shape=None, classes=1000)
Inception V3模型,权重由 ImageNet 训练
该模型在 Theano和TensorFlow后端均可使用,并接受th 和 tf两种输入维度顺序
默认输入图片大小为 299*299
参数:
- include_top:是否保留顶层的3个全连接网络
- weights:None代表随机初始化,即不加载预训练权重,“Imagenet”表示加载预训练权重
- input_tensor:可填入Keras tensor 作为模型的图像输出 tensor
- input_shape:可选,仅当 include_top=False 有效,应为长为3的 tuple,指明输入图片的 shape,图片的宽高必须大于 71,如(150, 150, 3)
- classes:可选,图片分类的类别数,仅当 include_top=True 并且不加载预训练权重时可用。
返回值:
Keras模型对象
参考文献:
https://arxiv.org/abs/1512.00567
2.7 InceptionResNetV2模型
keras.applications.inception_resnet_v2.InceptionResNetV2(include_top=True,
weights=\'imagenet\', input_tensor=None,
input_shape=None, pooling=None, classes=1000)
Inception-ResNet V2 模型,权重由 ImageNet 训练
该模型在 Theano和TensorFlow后端均可使用,并接受th 和 tf两种输入维度顺序
默认输入图片大小为 299*299
参数:
- include_top:是否保留顶层的3个全连接网络
- weights:None代表随机初始化,即不加载预训练权重,“Imagenet”表示加载预训练权重
- input_tensor:可填入Keras tensor 作为模型的图像输出 tensor
- input_shape:可选,仅当 include_top=False 有效,应为长为3的 tuple,指明输入图片的 shape,图片的宽高必须大于 71,如(150, 150, 3)
- pooling:可选,当 include_top为False时,该参数指定了特征提取时的池化方式。
- None代表不池化,直接输出最后一层卷积层的输出,该输出是一个四维张量
- avg 代表全局平均池化(GlobalAveragePooling2D),相当于在最后一层卷积层后面再加上一层全局平均池化层,输出是一个二维张量。
- max 代表全局最大池化
- classes:可选,图片分类的类别数,仅当 include_top=True 并且不加载预训练权重时可用。
返回值:
Keras模型对象
参考文献:
https://arxiv.org/abs/1602.07261
2.8 MobileNet 模型
keras.applications.mobilenet.MobileNet(input_shape=None, alpha=1.0,
depth_multiplier=1, dropout=1e-3, include_top=True,
weights=\'imagenet\', input_tensor=None, pooling=None,
classes=1000)
Mobilenet 模型,权重由 ImageNet 训练
该模型只支持 channels_last 的维度顺序(高度,宽度,通道)
默认输入图片大小为 224*224
参数:
-
input_shape: 可选,输入尺寸元组,仅当
include_top=False时有效,否则输入形状必须是(224, 224, 3)(channels_last格式)或(3, 224, 224)(channels_first格式)。它必须为 3 个输入通道,且宽高必须不小于 32,比如(200, 200, 3)是一个合法的输入尺寸。 -
alpha: 控制网络的宽度:
- 如果
alpha< 1.0,则同比例减少每层的滤波器个数。 - 如果
alpha> 1.0,则同比例增加每层的滤波器个数。 - 如果
alpha= 1,使用论文默认的滤波器个数
- 如果
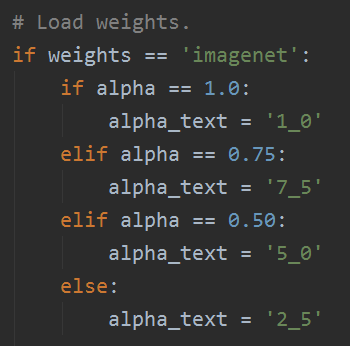
- depth_multiplier: depthwise卷积的深度乘子,也称为(分辨率乘子)
- dropout: dropout 概率
- include_top: 是否包括顶层的全连接层。
-
weights:
None代表随机初始化,\'imagenet\'代表加载在 ImageNet 上预训练的权值。 -
input_tensor: 可选,Keras tensor 作为模型的输入(比如
layers.Input()输出的 tensor)。 -
pooling: 可选,当
include_top为False时,该参数指定了特征提取时的池化方式。-
None代表不池化,直接输出最后一层卷积层的输出,该输出是一个四维张量。 -
\'avg\'代表全局平均池化(GlobalAveragePooling2D),相当于在最后一层卷积层后面再加一层全局平均池化层,输出是一个二维张量。 -
\'max\'代表全局最大池化
-
-
classes: 可选,图片分类的类别数,仅当
include_top为True并且不加载预训练权值时可用。
返回值:
Keras模型对象
参考文献:
https://arxiv.org/pdf/1704.04861.pdf
2.9 MusicTaggerCRNN模型
keras.applications.music_tagger_crnn.MusicTaggerCRNN(weights=\'msd\',
input_tensor=None, include_top=True, classes=50)
该模型是一个卷积循环模型,以向量化的 MelSpectrogram 音乐数据为输入,能够输出音乐的风格。你可以用 keras.applications.musiic_tagger_crnn.preprocess_input 来将一个音乐文件向量化为 spectrogram,注意,使用该功能需要安装 Librosa,请参考以下使用范例。
参数:
- include_top:是否保留顶层的3个全连接网络
- weights:None代表随机初始化,即不加载预训练权重,“msd" 代表加载预训练权重(训练自Millon Song DataSet:http://labrosa.ee.columbia.edu/millionsong/)
- input_tensor:可填入Keras tensor 作为模型的图像输出 tensor
- input_shape:可选,仅当 include_top=False 有效,应为长为3的 tuple,指明输入图片的 shape,图片的宽高必须大于 71,如(150, 150, 3)
- classes:可选,图片分类的类别数,仅当 include_top=True 并且不加载预训练权重时可用。
返回值:
Keras模型对象
参考文献:
https://arxiv.org/abs/1609.04243
使用范例:音乐特征抽取与风格标定
from keras.applications.music_tagger_crnn import MusicTaggerCRNN from keras.applications.music_tagger_crnn import preprocess_input, decode_predictions import numpy as np # 1. Tagging model = MusicTaggerCRNN(weights=\'msd\') audio_path = \'audio_file.mp3\' melgram = preprocess_input(audio_path) melgrams = np.expand_dims(melgram, axis=0) preds = model.predict(melgrams) print(\'Predicted:\') print(decode_predictions(preds)) # print: (\'Predicted:\', [[(\'rock\', 0.097071797), (\'pop\', 0.042456303), (\'alternative\', 0.032439161), (\'indie\', 0.024491295), (\'female vocalists\', 0.016455274)]]) #. 2. Feature extraction model = MusicTaggerCRNN(weights=\'msd\', include_top=False) audio_path = \'audio_file.mp3\' melgram = preprocess_input(audio_path) melgrams = np.expand_dims(melgram, axis=0) feats = model.predict(melgrams) print(\'Features:\') print(feats[0, :10]) # print: (\'Features:\', [-0.19160545 0.94259131 -0.9991011 0.47644514 -0.19089699 0.99033844 0.1103896 -0.00340496 0.14823607 0.59856361])
3,图片分类模型的示例
应用于图像分类的模型,权重训练自 ImageNet:Xception VGG16 VGG19 ResNet50 InceptionV3
所有的这些模型(除了Xception)都兼容 Theano 和 TensorFlow,并会自动基于 ~/.keras/keras.json 的Keras 的图像维度进行自动设置。例如,如果你设置 data_format = \'channel_last\',则加载的模型将按照 TensorFlow的维度顺序来构造,即“Width-Height-Depth”的顺序。
3.1 利用ResNet50 网络进行 ImageNet分类
代码如下:
# 利用ResNet50网络进行 ImageNet 分类 from keras.applications.resnet50 import ResNet50 from keras.preprocessing import image from keras.applications.resnet50 import preprocess_input, decode_predictions import numpy as np model = ResNet50(weights=\'imagenet\') img_path = \'elephant.jpg\' img = image.load_img(img_path, target_size=(224, 224)) x = image.img_to_array(img) x = np.expand_dims(x, axis=0) x = preprocess_input(x) preds = model.predict(x) # decode the results into a list of tuples(class description, probability) # one such list for each sample in the batch print(\'Predicted:\', decode_predictions(preds, top=3)[0]) \'\'\' Predicted: [(\'n01871265\', \'tusker\', 0.40863296), (\'n02504458\', \'African_elephant\', 0.36055887), (\'n02504013\', \'Indian_elephant\', 0.22416794)] \'\'\'
3.2 利用 VGG16 提取特征
代码如下:
# 利用VGG16提取特征 from keras.applications.vgg16 import VGG16 from keras.preprocessing import image from keras.applications.vgg16 import preprocess_input import numpy as np model = VGG16(weights=\'imagenet\', include_top=False) img_path = \'elephant.jpg\' img = image.load_img(img_path, target_size=(224, 224)) x = image.img_to_array(img) x = np.expand_dims(x, axis=0) x = preprocess_input(x) features = model.predict(x) print(features.shape, type(features)) # (1, 7, 7, 512) <class \'numpy.ndarray\'>
3.3 从 VGG19的任意中间层中抽取特征
代码如下:
# 利用VGG19提取特征
from keras.applications.vgg19 import VGG19
from keras.preprocessing import image
from keras.applications.vgg19 import preprocess_input
from keras.models import Model
import numpy as np
base_model = VGG19(weights=\'imagenet\')
model = Model(inputs=base_model.input,
outputs=base_model.get_layer(\'block4_pool\').output)
img_path = \'elephant.jpg\'
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
block4_pool_features = model.predict(x)
print(block4_pool_features.shape, type(block4_pool_features))
注意,这里将模型下载到本地,就不用了先加载网上的模型了,这样比较快,下载到本地,然后修改源码路径即可
3.4 在新类上 finetune inceptionV3
代码如下:
from keras.applications.inception_v3 import InceptionV3
from keras.preprocessing import image
from keras.models import Model
from keras.layers import Dense, GlobalAveragePooling2D
from keras import backend as K
# create the base pre-trained model
base_model = InceptionV3(weights=\'imagenet\', include_top=False)
# add a global spatial average pooling layer
x = base_model.output
x = GlobalAveragePooling2D()(x)
# let\'s add a fully-connected layer
x = Dense(1024, activation=\'relu\')(x)
# and a logistic layer -- let\'s say we have 200 classes
predictions = Dense(200, activation=\'softmax\')(x)
# this is the model we will train
model = Model(input=base_model.input, output=predictions)
# first: train only the top layers (which were randomly initialized)
# i.e. freeze all convolutional InceptionV3 layers
for layer in base_model.layers:
layer.trainable = False
# compile the model (should be done *after* setting layers to non-trainable)
model.compile(optimizer=\'rmsprop\', loss=\'categorical_crossentropy\')
# train the model on the new data for a few epochs
model.fit_generator(...)
# at this point, the top layers are well trained and we can start fine-tuning
# convolutional layers from inception V3. We will freeze the bottom N layers
# and train the remaining top layers.
# let\'s visualize layer names and layer indices to see how many layers
# we should freeze:
for i, layer in enumerate(base_model.layers):
print(i, layer.name)
# we chose to train the top 2 inception blocks, i.e. we will freeze
# the first 172 layers and unfreeze the rest:
for layer in model.layers[:172]:
layer.trainable = False
for layer in model.layers[172:]:
layer.trainable = True
# we need to recompile the model for these modifications to take effect
# we use SGD with a low learning rate
from keras.optimizers import SGD
model.compile(optimizer=SGD(lr=0.0001, momentum=0.9), loss=\'categorical_crossentropy\')
# we train our model again (this time fine-tuning the top 2 inception blocks
# alongside the top Dense layers
model.fit_generator(...)
3.5 在定制的输入 tensor 上构建 Inception V3
代码如下:
from keras.applications.inception_v3 import InceptionV3
from keras.layers import Input
# this could alse be the output a different Keras model or layer
input_tensor = Input(shape=(224, 224, 3))
model = InceptionV3(input_tensor=input_tensor,
weights=\'imagenet\',
include_top=True)
\'\'\'
Downloading data from https://github.com/fchollet/deep-learning-models/releases/download/v0.5/inception_v3_weights_tf_dim_ordering_tf_kernels.h5
\'\'\'
4,模型说明
4.1 th与tf 的区别
Keras提供了两套后端,Theano 和 TensorFlow,tf和th 的大部分功能都被 backend 统一包装起来了,但是二者还是存在不少的冲突,有时候需要特别注意Keras是运行在哪种后端上,他们的主要冲突是维度顺序,也就是数据格式的区别,channels_last 对应的是 tf,channels_first 对应的是 th。
比如:
vgg16_weights_th_dim_ordering_th_kernels_notop.h5 vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5
4.2 notop模型是指什么?
notop 表示是否包含最后三个全连接层(whether to include the 3 fully-connected layers at the top of the network),用来做 fine-tuning 专用,专门开源了这类模型。
就比如上面模型中出现的 include_top=False/True,一般来说为TRUE,表示保留顶层的全连接网络。
4.3 H5py简述
Keras中已训练模型为H5PY 格式的,不是 caffe 的 .caffemodel
htpy.File 类似于Python的词典对象,因此我们可以查看所有的键值。
读入如下:
# 读入模型 file=h5py.File(\'.../notop.h5\',\'r\') # 代表file的属性,其中有一个属性为 \'nb_layers\' file.attrs[\'nb_layers\'] f.keys() [u\'block1_conv1\', u\'block1_conv2\', u\'block1_pool\', u\'block2_conv1\', u\'block2_conv2\', u\'block2_pool\', u\'block3_conv1\', u\'block3_conv2\', u\'block3_conv3\', u\'block3_pool\', u\'block4_conv1\', u\'block4_conv2\', u\'block4_conv3\', u\'block4_pool\', u\'block5_conv1\', u\'block5_conv2\', u\'block5_conv3\', u\'block5_pool\']
可以使用下面代码看file中各个层内有什么
for name in file:
print(name)
# 类似f.keys()
结果如下:
block1_conv1 block1_conv2 block1_pool block2_conv1 block2_conv2 block2_pool block3_conv1 block3_conv2 block3_conv3 block3_pool block4_conv1 block4_conv2 block4_conv3 block4_pool block5_conv1 block5_conv2 block5_conv3 block5_pool
5,Keras-application-VGG16解读
注意:在计算机视觉CV任务中,对于远大于可用内存的大型图片数据集,应用深度学习模型 VGG16 提取 bottleneck特征,用 HDF5保存特征 array,是目前我感觉的最佳方案。
5.1 函数式
此py文件来源于:https://github.com/fchollet/deep-learning-models/blob/master/vgg16.py
此解读文件来源于:https://blog.csdn.net/sinat_26917383/article/details/72859145
VGG16默认的输入数据格式应该是:channels_last
代码如下:
# -*- coding: utf-8 -*-
\'\'\'VGG16 model for Keras.
# Reference:
- [Very Deep Convolutional Networks for Large-Scale Image Recognition](https://arxiv.org/abs/1409.1556)
\'\'\'
from __future__ import print_function
import numpy as np
import warnings
from keras.models import Model
from keras.layers import Flatten
from keras.layers import Dense
from keras.layers import Input
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
from keras.layers import GlobalMaxPooling2D
from keras.layers import GlobalAveragePooling2D
from keras.preprocessing import image
from keras.utils import layer_utils
from keras.utils.data_utils import get_file
from keras import backend as K
from keras.applications.imagenet_utils import decode_predictions
# decode_predictions 输出5个最高概率:(类名, 语义概念, 预测概率) decode_predictions(y_pred)
from keras.applications.imagenet_utils import preprocess_input
# 预处理 图像编码服从规定,譬如,RGB,GBR这一类的,preprocess_input(x)
from keras.applications.imagenet_utils import _obtain_input_shape
# 确定适当的输入形状,相当于opencv中的read.img,将图像变为数组
from keras.engine.topology import get_source_inputs
WEIGHTS_PATH = \'https://github.com/fchollet/deep-learning-models/releases/download/v0.1/vgg16_weights_tf_dim_ordering_tf_kernels.h5\'
WEIGHTS_PATH_NO_TOP = \'https://github.com/fchollet/deep-learning-models/releases/download/v0.1/vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5\'
def VGG16(include_top=True, weights=\'imagenet\',
input_tensor=None, input_shape=None,
pooling=None,
classes=1000):
# 检查weight与分类设置是否正确
if weights not in {\'imagenet\', None}:
raise ValueError(\'The `weights` argument should be either \'
\'`None` (random initialization) or `imagenet` \'
\'(pre-training on ImageNet).\')
if weights == \'imagenet\' and include_top and classes != 1000:
raise ValueError(\'If using `weights` as imagenet with `include_top`\'
\' as true, `classes` should be 1000\')
# 设置图像尺寸,类似caffe中的transform
# Determine proper input shape
input_shape = _obtain_input_shape(input_shape,
default_size=224,
min_size=48,
# 模型所能接受的最小长宽
data_format=K.image_data_format(),
# 数据的使用格式
include_top=include_top)
#是否通过一个Flatten层再连接到分类器
# 数据简单处理,resize
if input_tensor is None:
img_input = Input(shape=input_shape)
# 这里的Input是keras的格式,可以用于转换
else:
if not K.is_keras_tensor(input_tensor):
img_input = Input(tensor=input_tensor, shape=input_shape)
else:
img_input = input_tensor
# 如果是tensor的数据格式,需要两步走:
# 先判断是否是keras指定的数据类型,is_keras_tensor
# 然后get_source_inputs(input_tensor)
# 编写网络结构,prototxt
# Block 1
x = Conv2D(64, (3, 3), activation=\'relu\', padding=\'same\', name=\'block1_conv1\')(img_input)
x = Conv2D(64, (3, 3), activation=\'relu\', padding=\'same\', name=\'block1_conv2\')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name=\'block1_pool\')(x)
# Block 2
x = Conv2D(128, (3, 3), activation=\'relu\', padding=\'same\', name=\'block2_conv1\')(x)
x = Conv2D(128, (3, 3), activation=\'relu\', padding=\'same\', name=\'block2_conv2\')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name=\'block2_pool\')(x)
# Block 3
x = Conv2D(256, (3, 3), activation=\'relu\', padding=\'same\', name=\'block3_conv1\')(x)
x = Conv2D(256, (3, 3), activation=\'relu\', padding=\'same\', name=\'block3_conv2\')(x)
x = Conv2D(256, (3, 3), activation=\'relu\', padding=\'same\', name=\'block3_conv3\')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name=\'block3_pool\')(x)
# Block 4
x = Conv2D(512, (3, 3), activation=\'relu\', padding=\'same\', name=\'block4_conv1\')(x)
x = Conv2D(512, (3, 3), activation=\'relu\', padding=\'same\', name=\'block4_conv2\')(x)
x = Conv2D(512, (3, 3), activation=\'relu\', padding=\'same\', name=\'block4_conv3\')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name=\'block4_pool\')(x)
# Block 5
x = Conv2D(512, (3, 3), activation=\'relu\', padding=\'same\', name=\'block5_conv1\')(x)
x = Conv2D(512, (3, 3), activation=\'relu\', padding=\'same\', name=\'block5_conv2\')(x)
x = Conv2D(512, (3, 3), activation=\'relu\', padding=\'same\', name=\'block5_conv3\')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name=\'block5_pool\')(x)
if include_top:
# Classification block
x = Flatten(name=\'flatten\')(x)
x = Dense(4096, activation=\'relu\', name=\'fc1\')(x)
x = Dense(4096, activation=\'relu\', name=\'fc2\')(x)
x = Dense(classes, activation=\'softmax\', name=\'predictions\')(x)
else:
if pooling == \'avg\':
x = GlobalAveragePooling2D()(x)
elif pooling == \'max\':
x = GlobalMaxPooling2D()(x)
# 调整数据
# Ensure that the model takes into account
# any potential predecessors of `input_tensor`.
if input_tensor is not None:
inputs = get_source_inputs(input_tensor)
# get_source_inputs 返回计算需要的数据列表,List of input tensors.
# 如果是tensor的数据格式,需要两步走:
# 先判断是否是keras指定的数据类型,is_keras_tensor
# 然后get_source_inputs(input_tensor)
else:
inputs = img_input
# 创建模型
# Create model.
model = Model(inputs, x, name=\'vgg16\')
# 加载权重
# load weights
if weights == \'imagenet\':
if include_top:
weights_path = get_file(\'vgg16_weights_tf_dim_ordering_tf_kernels.h5\',
WEIGHTS_PATH,
cache_subdir=\'models\')
else:
weights_path = get_file(\'vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5\',
WEIGHTS_PATH_NO_TOP,
cache_subdir=\'models\')
model.load_weights(weights_path)
if K.backend() == \'theano\':
layer_utils.convert_all_kernels_in_model(model)
if K.image_data_format() == \'channels_first\':
if include_top:
maxpool = model.get_layer(name=\'block5_pool\')
shape = maxpool.output_shape[1:]
dense = model.get_layer(name=\'fc1\')
layer_utils.convert_dense_weights_data_format(dense, shape, \'channels_first\')
if K.backend() == \'tensorflow\':
warnings.warn(\'You are using the TensorFlow backend, yet you \'
\'are using the Theano \'
\'image data format convention \'
\'(`image_data_format="channels_first"`). \'
\'For best performance, set \'
\'`image_data_format="channels_last"` in \'
\'your Keras config \'
\'at ~/.keras/keras.json.\')
return model
if __name__ == \'__main__\':
model = VGG16(include_top=True, weights=\'imagenet\')
img_path = \'elephant.jpg\'
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
print(\'Input image shape:\', x.shape)
preds = model.predict(x)
print(\'Predicted:\', decode_predictions(preds))
# decode_predictions 输出5个最高概率:(类名, 语义概念, 预测概率)
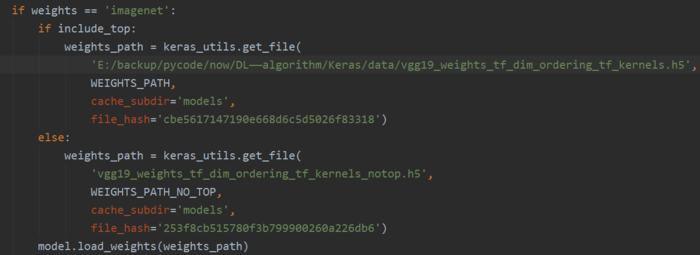
1,将模型下载到本地,不必每次从网站进行加载
当模型下载好了,就可以修改以下内容:
WEIGHTS_PATH = (\'https://github.com/fchollet/deep-learning-models/\'
\'releases/download/v0.1/\'
\'vgg19_weights_tf_dim_ordering_tf_kernels.h5\')
WEIGHTS_PATH_NO_TOP = (\'https://github.com/fchollet/deep-learning-models/\'
\'releases/download/v0.1/\'
\'vgg19_weights_tf_dim_ordering_tf_kernels_notop.h5\')
# Load weights.
if weights == \'imagenet\':
if include_top:
weights_path = keras_utils.get_file(
\'vgg19_weights_tf_dim_ordering_tf_kernels.h5\',
WEIGHTS_PATH,
cache_subdir=\'models\',
file_hash=\'cbe5617147190e668d6c5d5026f83318\')
else:
weights_path = keras_utils.get_file(
\'vgg19_weights_tf_dim_ordering_tf_kernels_notop.h5\',
WEIGHTS_PATH_NO_TOP,
cache_subdir=\'models\',
file_hash=\'253f8cb515780f3b799900260a226db6\')
model.load_weights(weights_path)
if backend.backend() == \'theano\':
keras_utils.convert_all_kernels_in_model(model)
elif weights is not None:
model.load_weights(weights)
2,几个layer中的新用法
from keras.applications.imagenet_utils import decode_predictions decode_predictions 输出5个最高概率:(类名, 语义概念, 预测概率) decode_predictions(y_pred) from keras.applications.imagenet_utils import preprocess_input 预处理 图像编码服从规定,譬如,RGB,GBR这一类的,preprocess_input(x) from keras.applications.imagenet_utils import _obtain_input_shape 确定适当的输入形状,相当于opencv中的read.img,将图像变为数组
- (1)decode_predictions用在最后输出结果上,比较好用【print(‘Predicted:’, decode_predictions(preds))】;
- (2)preprocess_input,改变编码,【preprocess_input(x)】;
- (3)_obtain_input_shape
3,当inclide_top=True 时
fc_model = VGG16(include_top=True) notop_model = VGG16(include_top=False)
当使用VGG16做 fine-tuning 的时候,得到的 notop_model 就是没有全连接层的模型,然后再去添加自己的层。
当是健全的网络结构的时候,fc_model需要添加以下的内容以补全网络结构:
x = Flatten(name=\'flatten\')(x) x = Dense(4096, activation=\'relu\', name=\'fc1\')(x) x = Dense(4096, activation=\'relu\', name=\'fc2\')(x) x = Dense(classes, activation=\'softmax\', name=\'predictions\')(x)
pool层之后接一个 flatten层,修改数据格式,然后接两个 dense层,最后有softmax的dense层。
4,如果输入的数据格式是 channels_first
其实我都默认是使用TensorFlow后端,所以数据格式一般是 channels_last,但是如果input格式是“channels_first”,fc_model 还需要修改一下格式,因为VGG16源码是以 “channels_last”定义的,所以需要转换一下输出格式,
maxpool = model.get_layer(name=\'block5_pool\') # model.get_layer()依据层名或下标获得层对象 shape = maxpool.output_shape[1:] # 获取block5_pool层输出的数据格式 dense = model.get_layer(name=\'fc1\') layer_utils.convert_dense_weights_data_format(dense, shape, \'channels_first\')
其中layer_utils.convert_dense_weights_data_format的作用很特殊,官方文档中没有说明,本质上用来修改数据格式,因为层中有 Flatten层把数据格式换了,所以需要修改一下。
5.2 序列式
本节节选自Keras中文文档《CNN眼中的世界:利用Keras解释CNN的滤波器》(https://keras-cn.readthedocs.io/en/latest/blog/cnn_see_world/)
已训练好VGG16和VGG19模型的权重:
- 国外:https://gist.github.com/baraldilorenzo/07d7802847aaad0a35d3
- 国内:http://files.heuritech.com/weights/vgg16_weights.h5
前面是VGG16架构的函数式模型的结构,那么在官方文档这个案例中,也有VGG16架构的序列式,都拿来比对一下比较好。
首先我们在Keras中定义 VGG 网络的结构
from keras.models import Sequential from keras.layers import Convolution2D, ZeroPadding2D, MaxPooling2D img_width, img_height = 128, 128 # build the VGG16 network model = Sequential() model.add(ZeroPadding2D((1, 1), batch_input_shape=(1, 3, img_width, img_height))) first_layer = model.layers[-1] # this is a placeholder tensor that will contain our generated images input_img = first_layer.input # build the rest of the network model.add(Convolution2D(64, 3, 3, activation=\'relu\', name=\'conv1_1\')) model.add(ZeroPadding2D((1, 1))) model.add(Convolution2D(64, 3, 3, activation=\'relu\', name=\'conv1_2\')) model.add(MaxPooling2D((2, 2), strides=(2, 2))) model.add(ZeroPadding2D((1, 1))) model.add(Convolution2D(128, 3, 3, activation=\'relu\', name=\'conv2_1\')) model.add(ZeroPadding2D((1, 1))) model.add(Convolution2D(128, 3, 3, activation=\'relu\', name=\'conv2_2\')) model.add(MaxPooling2D((2, 2), strides=(2, 2))) model.add(ZeroPadding2D((1, 1))) model.add(Convolution2D(256, 3, 3, activation=\'relu\', name=\'conv3_1\')) model.add(ZeroPadding2D((1, 1))) model.add(Convolution2D(256, 3, 3, activation=\'relu\', name=\'conv3_2\')) model.add(ZeroPadding2D((1, 1))) model.add(Convolution2D(256, 3, 3, activation=\'relu\', name=\'conv3_3\')) model.add(MaxPooling2D((2, 2), strides=(2, 2))) model.add(ZeroPadding2D((1, 1))) model.add(Convolution2D(512, 3, 3, activation=\'relu\', name=\'conv4_1\')) model.add(ZeroPadding2D((1, 1))) model.add(Convolution2D(512, 3, 3, activation=\'relu\', name=\'conv4_2\')) model.add(ZeroPadding2D((1, 1))) model.add(Convolution2D(512, 3, 3, activation=\'relu\', name=\'conv4_3\')) model.add(MaxPooling2D((2, 2), strides=(2, 2))) model.add(ZeroPadding2D((1, 1))) model.add(Convolution2D(512, 3, 3, activation=\'relu\', name=\'conv5_1\')) model.add(ZeroPadding2D((1, 1))) model.add(Convolution2D(512, 3, 3, activation=\'relu\', name=\'conv5_2\')) model.add(ZeroPadding2D((1, 1))) model.add(Convolution2D(512, 3, 3, activation=\'relu\', name=\'conv5_3\')) model.add(MaxPooling2D((2, 2), strides=(2, 2))) # get the symbolic outputs of each "key" layer (we gave them unique names). layer_dict = dict([(layer.name, layer) for layer in model.layers])
从使用 Convolution2D 来看,是比较早的版本写的。
Sequential模型如何部分layer载入权重
下面我们将预训练好的权重载入模型,一般而言我们可以通过 Model.load_weights()载入,但这种办法是载入全部的权重,并不适用。
之前所看到的 no_top 模型就是用来应付此时的,这里我们只载入一部分参数,用的时 set_weights() 函数,所以我们需要手工载入:
import h5py
weights_path = \'.../vgg16_weights.h5\'
f = h5py.File(weights_path)
for k in range(f.attrs[\'nb_layers\']):
if k >= len(model.layers):
break
g = f[\'layer_{}\'.format(k)]
weights = [g[\'param_{}\'.format(p)] for p in range(g.attrs[\'nb_params\'])]
model.layers[k].set_weights(weights)
f.close()
print(\'Model loaded.\')
但是 ,载入的.h5模型,没有属性nb_layers,会报错,如下:

6,使用预训练模型Mobilenet网络训练
6.1 导入预训练权重与网络框架
首先下载模型:https://github.com/fchollet/deep-learning-models/releases
当然也可以不下载,直接导入即可,我下载下来为了方便快捷。下载后则需要修改部分源码。
WEIGHTS_PATH = \'/data/mobilenet_5_0_224_tf.h5\' WEIGHTS_PATH_NO_TOP = \'/data/mobilenet_5_0_224_tf_no_top.h5\' from keras.applications.mobilenet import MobileNet model = MobileNet(include_top=False, weights=\'imagenet\')
其中 WEIGHTS_PATH_NO_TOP 就是去掉了全连接层,可以用它直接提取 bottleneck的特征。
6.2 提取图片的 bottleneck特征
我们仍然采取上一篇文章中使用的数据,如果需要的话,可以去上一篇文章中的连接去找。
只不过这次尝试使用mobilenet的预训练模型提取图片特征,而不是VGG模型,我想看看Mobilenet的效果如何,顺便看看自己掌握了没有。
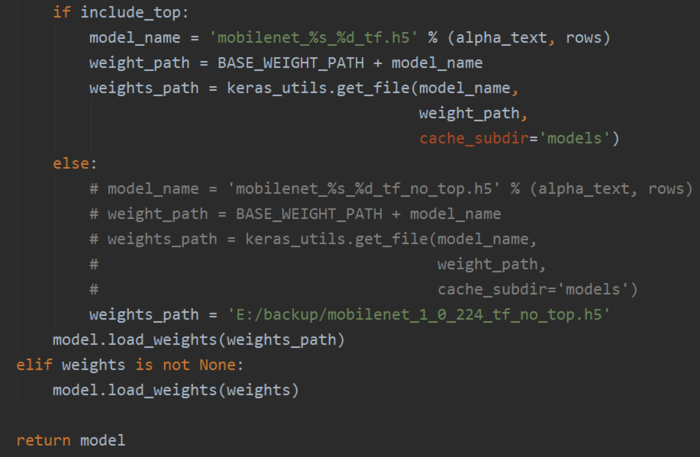
其实代码和上一节的大同小异,只不过这次我使用的更加娴熟了,而且有些参数的意思也更加明确了,而且有些参数还是不要写死的好,具体可以参考我的代码。
完整代码如下:
from keras.applications.mobilenet import MobileNet
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
from keras.preprocessing.image import ImageDataGenerator
import numpy as np
import os
import keras
import tensorflow as tf
from keras.backend.tensorflow_backend import set_session
os.environ[\'CUDA_VISIBLE_DEVICES\'] = \'1,2\'
config = tf.ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction = 0.3
set_session(tf.Session(config=config))
def save_bottleneck_features():
model = MobileNet(include_top=False, weights=\'imagenet\', input_shape=(150, 150, 3))
print(\'load model ok\')
datagen = ImageDataGenerator(rescale=1. / 255)
# train set image generator
train_generator = datagen.flow_from_directory(
\'/data/lebron/data/mytrain\',
target_size=(150, 150),
batch_size=batch_size,
class_mode=None,
shuffle=False
)
# test set image generator
test_generator = datagen.flow_from_directory(
\'/data/lebron/data/mytest\',
target_size=(150, 150),
batch_size=batch_size,
class_mode=None,
shuffle=False
)
# load weight
model.load_weights(WEIGHTS_PATH_NO_TOP)
print(\'load weight ok\')
# get bottleneck feature
bottleneck_features_train = model.predict_generator(train_generator, 10)
np.save(save_train_path, bottleneck_features_train)
bottleneck_features_validation = model.predict_generator(test_generator, 2)
np.save(save_test_path, bottleneck_features_validation)
def train_fine_tune():
# load bottleneck features
train_data = np.load(save_train_path)
train_labels = np.array(
[0] * 100 + [1] * 100 + [2] * 100 + [3] * 100 + [4] * 100
)
validation_data = np.load(save_test_path)
validation_labels = np.array(
[0] * 20 + [1] * 20 + [2] * 20 + [3] * 20 + [4] * 20
)
# set labels
train_labels = keras.utils.to_categorical(train_labels, 5)
validation_labels = keras.utils.to_categorical(validation_labels, 5)
model = Sequential()
model.add(Flatten(input_shape=train_data.shape[1:]))
model.add(Dense(256, activation=\'relu\'))
model.add(Dropout(0.5))
model.add(Dense(5, activation=\'softmax\'))
model.compile(loss=\'categorical_crossentropy\',
optimizer=\'rmsprop\',
metrics=[\'accuracy\'])
model.fit(train_data, train_labels,
nb_epoch=500, batch_size=25,
validation_data=(validation_data, validation_labels))
if __name__ == \'__main__\':
WEIGHTS_PATH = \'/data/model/mobilenet_1_0_224_tf.h5\'
WEIGHTS_PATH_NO_TOP = \'/data/model/mobilenet_1_0_224_tf_no_top.h5\'
save_train_path = \'/data/bottleneck_features_train.npy\'
save_test_path = \'/data/bottleneck_features_validation.npy\'
batch_size = 50
save_bottleneck_features()
train_data = np.load(save_train_path)
validation_data = np.load(save_test_path)
print(train_data.shape, validation_data.shape)
train_fine_tune()
print(\'game over\')
训练的结果就不展示了,这里说一下准确率是百分之八十,loss有点高,降不下来,我会再学习研究的。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:我的Keras使用总结(4)——Application中五款预训练模型学习及其应用 我的Keras使用总结(3)——利用bottleneck features进行微调预训练模型VGG16 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 