
1 导引
目前,知识图谱(Knowlege Graph)在医疗、金融等领域都取得了广泛的应用。我们将知识图谱定义为\(\mathcal{g}=\{\mathcal{E}, \mathcal{R}, \mathcal{T}\}\),这里\(\mathcal{E}=\left\{e_{i}\right\}_{i=1}^{n}\)是由\(n\)个实体(entity)组成的集合,\(\mathcal{R}=\left\{r_{i}\right\}_{i=1}^{m}\)是由\(m\)个关系(relation)组成的集合。元组集合\(\mathcal{T}=\{(h, r, t) \in \mathcal{E} \times \mathcal{R} \times \mathcal{E}\}\)则建模了不同实体之间的关系。知识图谱嵌入是知识图谱在应用中非常重要的一步。我们先通过知识图谱嵌入将知识图谱中的实体和关系嵌入到embeddings向量,然后再在下游进行实体分类或者知识图谱补全的任务。
对于知识图谱嵌入任务我们常采用基于负采样的交叉熵函数[1]:
\mathcal{L}=\sum_{(h, r, t) \in \mathcal{T}} &-\log \left(\sigma\left(f_r(h, t)\right)\right) \\
&-\gamma \mathbb{E}_{t^{-} \sim P_{h}^{-}(\mathcal{E})}\log\sigma\left(-f_r(h, t^{-})\right)
\end{aligned}
\]
这里\((h,r,t)\)即知识图谱中存在的元组,其对应的负样本\((h,r,t^{-})\)即图谱中不存在的元组;\(\sigma\)为sigmoid函数;\(P_{h}^{-}(\mathcal{E})\)为实体集\(\mathcal{E}\)的负采样分布(可能是关于\(h\)的),最简单的设置为均匀分布(不过易造成“假阴性结果”,即采样实际上存在于图谱中的负样本,一种改进方法参见[2]);超参数\(\gamma>0\)。
这里\(f_r(h, t)\)称为Score function。适用于常见经典知识图谱的Score function \(f_r(h, t)\)可以参见下图。


这里\(\textbf{h}, \textbf{r}, \textbf{t}\)是\(h, r, t\)对应的embeddings。\(\text{Re}(\cdot)\)表示复值向量的实值部分。\(\circ\)表示逐项乘积(即Hadamard乘积)。
在实际应用中我们常常面临一系列来自不同数据持有方的知识图谱,我们将其称为多源知识图谱(Multi-Source KG)。我们将来自\(K\)个不同数据持有方的知识图谱集合记为\(\mathcal{G}=\left\{g_{k}\right\}_{k=1}^{K}=\left\{\left\{\mathcal{E}_{k}, \mathcal{R}_{k}, \mathcal{T}_{k}\right\}\right\}_{k=1}^{K}\),按照数据异构程度可分为以下两种形式:
多源同领域
这种类型中各知识图谱的领域(domain)相同,比如都是来自不同银行的用户知识图谱。这些知识图谱中也可能有实体重叠(overlapped),因为在日常生活中,一个用户很可能在不同银行都产生有相关的数据(元组)[2]。

多源跨领域
这种情况下数据更具有异构性,各个知识图谱之间是跨领域(cross domain)的 ,如下图中所示的大学(university)、文学(literature)和宾夕法尼亚州(pennsylvania)这三个不同领域的知识图谱[3]。这种知识图谱中也有可能出现实体重叠,比如CMU实体在大学知识图谱和宾夕法尼亚州知识图谱中就同时出现(当然在两个知识图谱中的嵌入向量是不同的)。

如果能让在多个知识图谱间进行知识共享,那么很可能提高实体的嵌入质量与下游任务的表现。目前多源知识图谱融合(cross source knowlege graph fusion)领域的工作大都是需要先将多个知识图谱集中起来的。然而,在现实场景中,不同部门之间由于数据隐私的问题,共享数据是很困难的,那么联邦学习在这里就成为了一个很好的解决方案。
在联邦场景下,对于多源且同领域的情况,我们可以采用传统FedAvg的思想,训练一个让多方共享的嵌入模型;然而对于多源且不同领域的情况,不同的知识图谱就应当使用不同的嵌入模型。不过不论是在同领域和不同领域的情况下,都需要涉及对某些知识图谱间重叠(也称为对齐的,aligned)实体的embeddings进行统一(unify),以提高整体的学习效果,类似于分布式优化算法中聚合的意思。
2 联邦多源知识图谱嵌入论文阅读
2.1 IJCKG 2021:《FedE: Embedding Knowledge Graphs in Federated Setting》[3]
这篇论文属于多源同领域的类型。该问题的靓点在于首次采用FedAvg的框架对知识图谱嵌入模型进行训练,其解决方案非常直接:所有client共享一份所有实体和关系的嵌入,然后在本地进行优化时通过查表的方式获得元组\((h, r, t)\)对应的嵌入向量。
本篇论文算法的每轮通信描述如下:
(1) 第\(k\)个client节点执行
- 从server接收所有实体的嵌入矩阵\(\textbf{E}\),令本地嵌入矩阵\(\textbf{E}_k=\textbf{P}_k^T \textbf{E}\)。
- 执行\(E\)个局部epoch的SGD:
\[\textbf{E}_k = \textbf{E}_k - \eta \nabla \mathcal{L}(\textbf{E}_k; \mathcal{b})
\](此处将局部元组数据\(\mathcal{T}_k\)划分为多个批量\(\mathcal{b}\))
- 将\(\textbf{P}_k \textbf{E}_k\)发往server。
(2) server节点执行
-
从\(N\)个client接收\(\{\textbf{P}_k \textbf{E}_k\}_{k=1}^N\)。
-
进行参数聚合:
\]
- 将嵌入矩阵\(\textbf{E}\)发往对应的client。
上面只展示了实体embeddings的更新流程,关系embeddings的更新同理,此处从简省略掉。这里\(\textbf{E}_k\in \mathbb{R}^{n_k\times d_e}\)表示本地实体的embeddings,\(d_e\)为实体嵌入维度;\(\textbf{P}_k\in \{0, 1\}^{n\times n_k}\)用于将客户端\(k\)的本地embeddings映射到服务端的全局embeddings中,\((\textbf{P}_k)_{ij}=1\)意为全局embeddings中的第\(i\)个实体对应client中的第\(j\)个实体;\((\textbf{v}_k)_{i}=1\)意为第\(i\)个实体在client \(k\)中存在,\(\oslash\)表示逐元素除,\(\left(\mathbb{1} \oslash \sum \mathbf{v}_k\right)\)表示给聚合结果的加权,在所有client中出现多的实体权重小;\(\otimes\)表示带广播的逐元素乘,\([\textbf{v} \otimes \textbf{M}]_{i,j}=\textbf{v}_i \times \textbf{M}_{i,j}\)。
整个算法流程如下图所示: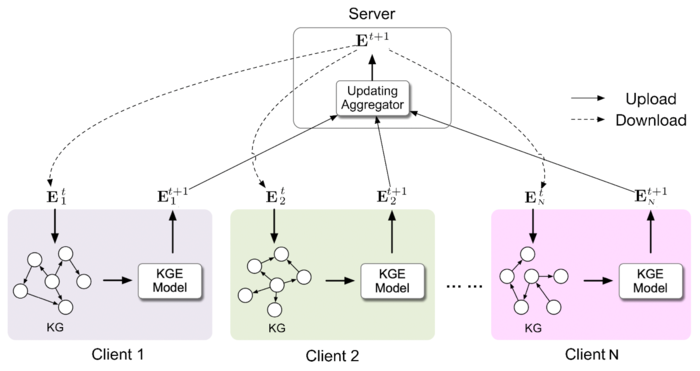
该算法本地优化采用的损失函数为论文[2]中提出的标准损失函数的变种,写为如下形式(考虑本地数据集\(\mathcal{T}_k\)的一个批量\(b\)):
\mathcal{L}=\sum_{(h, r, t) \in \mathcal{b}} & -\log \left(\sigma\left(f_r(h, t)-\gamma\right)\right) \\
&-\sum_{i=1}^{n^{-}}p(h, r, t_i^{-})\log \sigma\left(\gamma-f_r(h, t^{-}_i)\right)
\end{aligned}
\]
这里\(\gamma\)是一个间隔超参数;\((h, r, t_i^{-})\)是\((h, r, t)\)对应的负样本,\((h, r, t_i^{-})\notin \mathcal{T}_k\);\(n^{-}\)为负样本的数量。\(p\left(h, r, t_{i}^{-}\right)\)为对应负样本的权重,这种非均匀的负采样叫做自对抗负采样(self-adversarial negative sampling),权重定义如下:
\]
这里\(\alpha\)是温度。
2.2 CIKM 2021:《Differentially Private Federated Knowledge Graphs Embedding》[4]
这篇论文考虑的是各知识图谱之间跨领域的情况。这种情况下因为数据更加异构,就不能单纯地对重叠实体及关系的embeddings进行平均了。本文的靓点在于提出了一种隐私保护的对抗转换网络(privacy-preserving adversarial translation, PPAT),可以在隐私保护的前提下完成两两知识图谱间重叠实体及关系embeddings的统一。

如上图就展示了使用了论文提出的PPAT网络后的整个去中心化异步训练流程。图中\(\text{Train}\)表示本地训练知识图谱嵌入模型;\(\text{PPAT}(g_k, g_l)\)表示用PAPAT网络生成的\(g_k\)和\(g_l\)之间重叠部分的embeddings;\(\text{KGEmb-Update}\)表示更新之前PAPAT网络所生产的embeddings并再对client中所有embeddings进行训练(同\(\text{Train}\))。如果在\(\text{KGEmb-Update}\)之后的本地评估结果没有提升,则会对client进行回退(backtrack),也即舍弃新训练得到的embeddings并使用训练前的旧版本。
接下来我们来看PPAT网络是怎么实现的。该网络利用GAN结构来辅助重叠实体embeddings的统一。给定任意两个图\((g_k,g_l)\),论文将生成器设置于client \(k\)上,判别器设置与client \(j\)上。生成器的目标是将\(g_k\)中重叠实体的embeddings转换到\(g_l\)的嵌入空间;判别器负责区分生成器生成的人工embeddings和\(g_l\)中的基准embeddings。在GAN训练完毕后,生成器产生的人工embeddings能够学得两个知识图谱的特征,因此可以做为\(\mathcal{E}_{k} \cap \mathcal{E}_{l}\)与\(R_{k} \cap R_{l}\)的原始embeddings的有效替代(此时即完成了对embeddings的统一)。
这里需要注意的是,论文将原始GAN的判别器改为了多个学生判别器和一个教师判别器。论文在多个教师判别器的投票表决结果上加以Laplace噪声,得到带噪声的标签来训练学生判别器,这样学生判别器具有差分隐私性。而生成器又由学生判别器训练,则同样具有了差分隐私性。最终促使生成器产生带有差分隐私保护的embeddings。设生成器为\(G\)(参数为\(\theta_G\)),学生判别器为\(S\)(参数为\(\theta_S\)),多个教师判别器为\(T=\{ T_1,T_2,\cdots, T_{|T|}\}\)(参数为\(\theta_{T}^{1}, \theta_{T}^{2}, \ldots, \theta_{T}^{|T|}\)。这里使用\(X=\left\{x_{1}, x_{2}, \ldots, x_{n}\right\}\)来表示\(g_k\)中\(\mathcal{E}_{k} \cap \mathcal{E}_{l}\)与\(R_{k} \cap R_{l}\)的embeddings,用\(Y=\left\{y_{1}, y_{2}, \ldots, y_{n}\right\}\)来表示\(g_l\)中\(\mathcal{E}_{k} \cap \mathcal{E}_{l}\)与\(R_{k} \cap R_{l}\)的embeddings,则整个PPAT网络流程可描述如下:

如上图所示,生成器\(G\)的目标是产生与\(Y\)相似的对抗样本\(G(X)\),以求学生判别器\(S\)不能够识别它们。下面这个式子是生成器的损失函数:
\]
这里\(G(X)=WX\);\(S\)是一个参数为\(\theta_S\)的学生判别器,它同时将\(G(X)\)和\(Y\)做为输入。
教师判别器\(T=\{ T_1,T_2,\cdots, T_{|T|}\}\)的学习目标和原始GAN中判别器相似,也即区分伪造样本\(G(X)\)与真样本\(Y\)。唯一的不同是各个教师判别器会使用划分好的数据集来训练,第\(t\)个教师判别器的损失函数如下:
\]
这里\(D^t\)是\(T^t\)对应的数据集\(X\)和\(Y\)的子集,满足\(|D_t|=\frac{n}{T}\)且子集之间无交集。
而学生判别器\(S\)的学习目标则是在给定带噪声标签的情况下,对生成器产生的真假样本进行分类。这里所谓的带噪声标签是在教师判别器的投票结果的基础上,加以随机的Laplace噪声来生成。下面的式子描述了在带噪声标签的生成机制(即所谓PATE机制):
\]
这里\(V_0, V_1\)为用于引入噪声的IID的Laplace分布随机变量。\(n_j(x)\)表示对于输入\(x\)预测类别为\(c\)的教师数量:
\]
(此处符号不严谨,\(T_t(x)\)应该是个概率值,但意会意思即可)
学生判别器则利用带有上述标签的生成样本来训练自身。学生判别器的损失函数定义如下:
\]
这里\(\gamma_{i}=P A T E_{\lambda}\left(x_{i}\right)\)即生成的带噪声标签。
这样学生判别器\(S\)由带噪声的标签训练,则具有差分隐私性。而生成器又由学生判别器训练,则同样具有了差分隐私性。最终促使生成器产生带有差分隐私保护的embeddings。
参考
- [1] Hamilton W L. Graph representation learning[J]. Synthesis Lectures on Artifical Intelligence and Machine Learning, 2020, 14(3): 1-159.
- [2] Sun Z, Deng Z H, Nie J Y, et al. Rotate: Knowledge graph embedding by relational rotation in complex space[J]. arXiv preprint arXiv:1902.10197, 2019.
- [3] Chen M, Zhang W, Yuan Z, et al. Fede: Embedding knowledge graphs in federated setting[C]//The 10th International Joint Conference on Knowledge Graphs. 2021: 80-88.
- [4] Peng H, Li H, Song Y, et al. Differentially private federated knowledge graphs embedding[C]//Proceedings of the 30th ACM International Conference on Information & Knowledge Management. 2021: 1416-1425.
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:联邦学习:联邦场景下的多源知识图谱嵌入 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 