01|基于图像的火焰检测算法
-
数据集总共数量,包括的干扰,用来训练的数量、用来测试的数量。
-
训练测试结果


-
仿真实验环境
-
指标公式
用正类预测正确率 \(\left(T_{\mathrm{PR}}\right)\) 与反类预测正确率\(\left(T_{\mathrm{NR}}\right)\) 来描述实验结果的准确性,定义如下
\[T_{\mathrm{PR}}=\frac{T_{\mathrm{P}}}{T_{\mathrm{P}}+F_{\mathrm{N}}} \\
T_{\mathrm{NR}}=\frac{T_{\mathrm{N}}}{F_{\mathrm{P}}+T_{\mathrm{N}}}
\]式中 \(: T_{\mathrm{P}}\) 表示预测结果为正类,实际上是正类 \(; F_{\mathrm{P}}\) 表示预测结果为正类,实际上是反类;FN 表示预测结 果为反类,实际上是正类;TN表示预测结果为反类, 实际上是反类。
-
算法结果比较
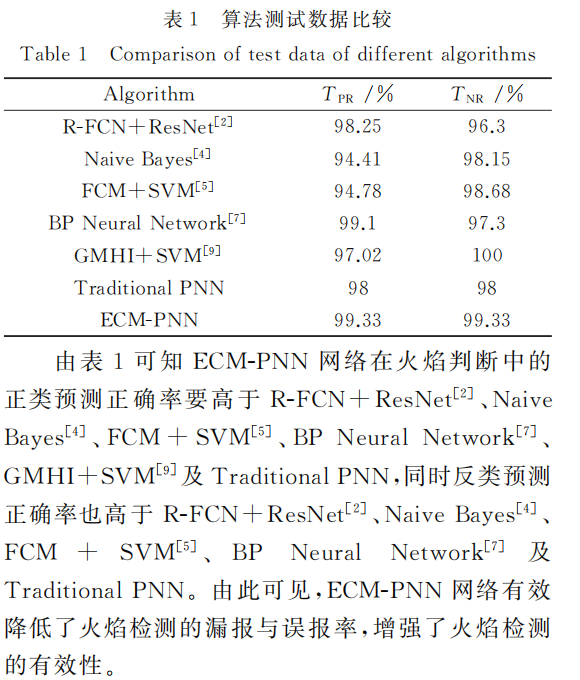
02|基于图像处理的森林火险检测系统
03|基于视频图像的火焰检测
实验环境
-
对比方法

-
实验结论
特征提取的火焰区域更加完整,更加准确,但是背景差分将固定的图像作为背景图像时,周围许多的环
境因素会不同程度上影响到检测的准确性。实验结果也表明,一般情况下自然环境中的火灾重心高度系
数会随着燃烧时间而变大,但是最大不会超过 0.45。
04| 基于计算机视觉的森林火灾识别算法设计
-
试验平台搭建
-
说明实验设计

实验结果
通过上述所设计的3组对照试验,可以得出单纯的采用一种特征对烟雾与火焰的判别有一定的准确度,但是精度不高。若利用图像的综合特征进行分类,试验结果表明比采用单类特征的分类效果要好。由于林火行为的复杂性与特殊性,在火灾初期通常是先产生烟雾,单一的采用火焰识别容易错过扑灭最佳时机,故采用烟火综合特征共同判断森林火灾,识别准确率可达97.82%。
通过比较容易得出,利用图像综合特征识别方法比采用单类特征识别效果更好,而且通常情况下使用的特征越多,分类效果越好,但是这并不绝对,还要根据所处环境、气候以及识别对象综合进行考虑,选取最优的特征组合从而得到更佳的试验结果。
05|从传统到深度:视觉烟雾识别、 检测与分割
06|Using Popular Object Detection Methods for Real Time Forest Fire Detection
In this section, we will show experiments results through 3 object detection methods, Faster R-CNN, YOLO (tiny-yolo-voc1, tiny-yolo-voc, yolo-voc.2.0, and yolov3) and SSD.
For Faster R-CNN, we give a result based on 120000 iteration times. For YOLO, we find that YOLO has a bad performance on smaller cooler fire detection, so we try to adjust the structure of tiny-yolo-voc by adding two more layers (one is convolutional layer and the other is maxpooling layer, the filter of convolutional layer is 8). When training is finished, we finally find that these two added layer boost the original smaller fire detection accuracy rate. The experiment result proves that more layer with small filter catch more details. For SSD, we test its static and real-time detection accuracy rate on smaller fire, the result shows that this methods has better performance than YOLO (tiny-yolo-voc), it can make an accurate and real-time detection an smaller fire.
对比三种目标检测方法 : Faster R-CNN YOLO SSD
Faster R-CNN的训练轮数是120000
yolo在smaller cooler fire detection上表现不佳,在增加了一个八个滤波器的卷积层和一个最大池化层之后,原本的小火焰检测准确率提高了。
实验证明更多的层(因为其滤波器更多)可以捕获更多的细节信息。
SSD的静态和实时检测准确率在小火焰的上比YOLO效果更好,更适合进行准确而实时的小火焰检测
A. Faster R-CNN
We use 1000 fire pictures with 300*300 size as benchmark. BBox-Label-Tool v2 is used to label the pictures, fire and smoke are both labeled therein. We alter the iterations for each training stage at 120000, 60000, 120000, and 60000 and keep the default values for all the other settings.
使用了300*300图片大小的1000章火焰图片作为Benchmark
标注图片的工具是BBox-Label-Tool v2。 therein 其中标注了火焰和烟雾(smoke)
改变训练轮数在120000,6000,同时保持其他的默认设置
Fire and smoke detection accuracy rate both are very good, even the very small fire Faster R-CNN can detect rightly. For smoke detection accuracy rate, Faster R-CNN is close to 1. For fire detection, detection accuracy rate for the small fire is 0.99 and the dark fire is 0.974. We only show static picture herein, because as the author of SSD said, it can only operates at only 7 frames per second (FPS), too slow for real-time fire-detection applications. We focus on research on YOLO and SSD, the later has higher FPS and can satisfy the real-time detection need. Table I describes performance for Faster R-CNN.
火焰和烟雾的检测准确率都非常好,即使是非常小的火焰Faster R-CNN 都能正确地检测。
对于烟雾检测准确率,Faster R-CNN 接近1。对于火焰检测,检测准确率对于小火是0.99。对于暗火是0.974。
在此,仅展示静态图片,正如ssd的作者所说他只能在7FPS上运行,对于实时火焰检测来说实在太慢。
我们重点研究YOLO和SSD,后者有更高的FPS而且可以满足实时火焰检测的需要。

B. YOLO
For YOLO, we test how different layers structure influence the accuracy rate. Still, we use 1000 pictures to make the fire/smoke datasets, the same datasets for those three object detection methods. We use the tiny-yolo-voc structure to train the datasets, finally find that when the iteration times equals to 120000 and learning rate is 0.01, this original structure has plain accuracy. We adjust the tiny-yolo-voc by adding two layers, which include 1 convolutional layer(the filter is 8) and 1 maxpooling layer, the results proves that this new structure improves both fire and smoke detection accuracy. Even we train the yolo-voc.2.0, this new structure still shows better performance. But in the end, yolov3 performs better. When we train the original tiny-yolo-voc, we initialize the images size as 416*416, during the experiments, we find that when the image size is set as 608*608, the performances become better. So next when we train yolo-voc.2.0 and tiny-yolo-voc1, we both initialize the image size at 608*608. When we utilize tiny-yolo-voc1 to train fire only, it performs best. But when the new class smoke is added, the fire accuracy decrease 10%. When we train dataset using yolov3, we finally find that this configuration performs best. Herein single training means fire training, combine training means fire/smoke joint training. Figure 2 shows performance for YOLOv3. YOLOv3 has a bad performance for small fire.
我们测试了不同的网络层结构如何影响准确率。尽管如此,我们还是使用了1000张图片来制作火灾/烟雾数据集,这三个目标检测方法的数据集是相同的。
我们用tiny-yolo-voc 结构,来训练数据集,最终发现当训练轮数等于120000而学习率是0.01时,该原始结构具有较好的(plain 朴素 简单的)准确率
通过增加两个层(8个滤波器的卷积层和一个最大池化层)调整tiny-yolo-voc,这种结构会同时提高火焰和烟雾的准确率。
yolo voc.2.0 依然比改进之后的tiny-yolo-voc效果差。但是yolo v3就要比改进之后的tiny-yolo-voc效果好了。
当我们训练原始tiny yolo voc 时,初始化图片大小是416*416,在实验过程中,我们发现当图片大小是 608*608时,训练效果会变得更好。
当我们利用(utilize)tiny-yolo-voc1 只训练火焰,效果是最好的。
但是新的类别,烟雾,加进来时,火焰准确率就下降了10%。


C. SSD
In this section, we use SSD 300*300 model to train our fire datasets. The resized width and resize height are both 300, the batch size equals to 1, number of the testing images equals to 342 and number of the training image is 668, the iteration times is 120000. When the training ends, we finally find that the fire detection accuracy for 100 images is up to 1, except one very small fire which equals to 0.58. For smoke detection, accuracy of in 100 test images are 0, but 13 in 27 are no smoke images, so the missing detection rate is 14 percent. The smoke accuracy rate of these remain 73 images are up to 97.88 percent.
这节描述的是SSD300的模型。
图片被resize到300*300,batch size设置为1,训练集是668张,测试集是342张,训练轮数是120000。
火焰准确率达到了1,除了非常小的火焰约等于0.58。对于烟雾检测,除了没有烟雾的图片集,其余的达到了97.88%的准确率

D. Area changes
For false detection, we think area changes detection helps a lot. When the fire is bigger and bigger, the area of the fire is growing. The SSD can detect the area of the fire by four value, Xmin, Ymin, Xmax and Ymax. These four values present the coordinates of the top left corner and the coordinates of the lower right corner, then we calculate the area very easily. We catch the two interval frame of the fire usually, when the area grows bigger, this must be the fire.
对于错误检测,我们认为面积变化会有所影响。当火焰越来越大,这个区域的火焰在生长。SSD可以检测到火焰通过值,最小值,最大值。这4个值分别表示左上角的坐标和右下角的坐标( coordinates ),然后我们非常容易计算出面积。我们可以通过火的两个区间(interval)框架( frame),当区域变大,肯定就是火。
07|A convolutional neural network-based flame detection methodin video
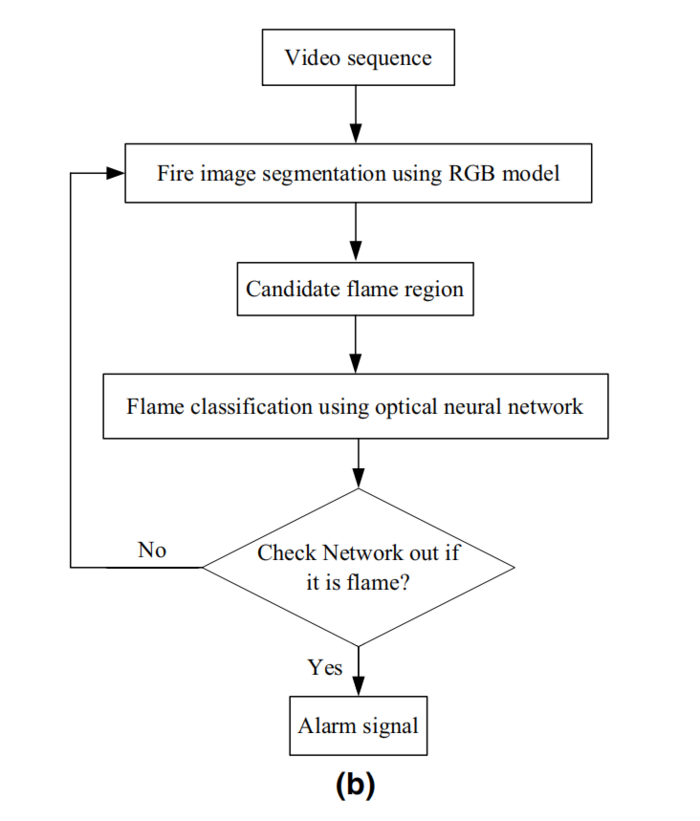
The proposed algorithm based on convolutional neural network (CNN) is implemented in C language and Caffe model on a standard desktop PC which is equipped with a Octa-Core, CPU 3.6 GHz and 8 GB RAM. The flowchart of the method is shown in Fig. 2b.
这个建议的算法是基于CNN卷积神经网络通过c语言和caffe实现的,
在xx的电脑配置上。
流程图是Fig . 2b.
In the processing of training neural network model, the training of convolutional layer is to train some convolutional filters, which have high activation of the unique mode to achieve the purpose of CNN. The more convolutional layers, the more complicate features. In this paper, to train the better convolutional kernels and obtain the more effective combination mode of these convolutional kernels, the optimal parameters are obtained by the proposed model, and then test samples are effectively classified by optimal parameters. The loss function curve of train set and test set are shown in Fig. 5a. From this curve, we can see that as the number of training and testing iterations increases, the loss functions all decrease and then the curves tend to stabilize. The test accuracy curve is shown in Fig. 5b. From this curve, we can see that as the number of training iterations increases, the test accuracy improves and then the curve reaches highest accuracy which is 97.64% when the number of iterations is 50,000.
训练神经网络模型的过程中,卷积层的训练是去训练卷积核(卷积滤波器),其具有高度激活(activation)的独特模式(unique mode)达到CNN的目的(获取图像特征?)。
在本文中,为了训练出更好的卷积核并且获得这些卷积核更有效的组合模式(combination mode),
在建议模型中获得了优化参数,测试样本被有效优化参数地分类。(通过提出的模型得到最优参数,然后通过最优参数对测试样本进行有效分类。)训练集和测试集的损失函数曲线(curve)如图5a
通过这个曲线,我们可以知道,随着训练和测试的轮数增加,损失函数都递减,而且曲线都趋于平滑。
fig 5b 显示了测试准确率曲线。根据这个曲线,我们可以知道,随着训练轮数的增加,这个测试准确率在增强,并且在训练到50000轮时,准确率达到了97.64%。

In the previous studies [16, 34], different color spaces were used to extract flame color features, these methods have achieved good results. However, the processes of color space transformation and feature extraction are too complicated to meet the real-time requirements. Due to the high intensity of the flame area based on near-infrared image, the researchers present a lot of fire detection algorithms based on near-infrared image [35, 36]. The methods reduce the highlighted interference and obtain better results, but the requirement of hardware equipment is higher. According to the advantages of flame detection based on near-infrared video images, the researchers proposed a dual-spectrum flame feature detection method [37, 38], which combines the flame features of visible video images with the flame features of near-infrared video images. This method can effectively eliminate the small hole phenomenon in the segmentation area.
在先前的研究中,不同的颜色空间被用来获取火焰颜色特征(flame color features),这些方法已经达到了很好的实验结果。
然而,这个 颜色空间转换和特征提取的过程非常难以达到实时的需求。
由于基于近红外图像(near-infrared )的火焰区域强度(intensity )较高,研究者提出了很多基于近红外图像(near-infrared)的火灾检测算法[ 35,36 ]。
这种方法减少突出干扰(highlighted interference ),会获得更好的效果,但是对硬件需求会更高。
根据基于近红外视频图片优点进行火焰检测,研究者提出了双光谱(dual-spectrum)火焰特征检测方法,其结合了可视化视频图像和近红外视频图像的火焰特征。根据基于近红外视频图像的火焰检测的优点,研究人员提出了一种将可见光视频图像的火焰特征与近红外视频图像的火焰特征相结合的双光谱火焰特征检测方法[ 37,38 ]。
这种方法可以有效地消除(eliminate)分割区域的小洞现象。该方法能有效消除(eliminate)分割区域中的小孔现象。
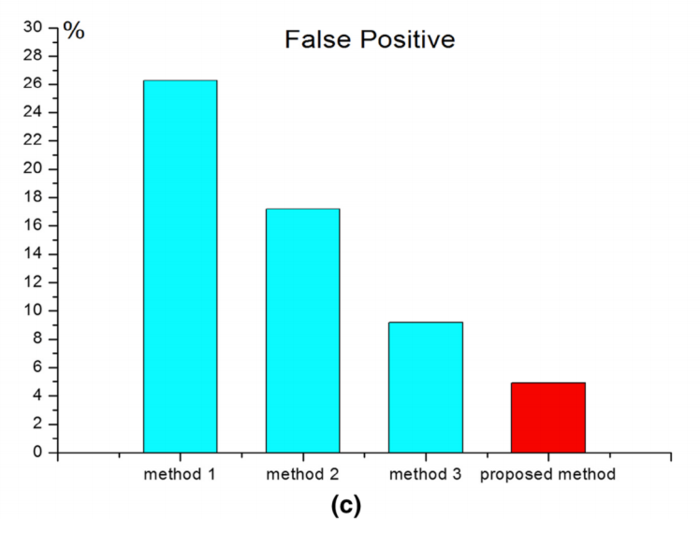
To evaluate the performance of the proposed method, experimental results were compared with obtained by the flame detection methods in the same scene, as shown in Fig. \(5 \mathrm{c}\). The first recognition method is based on color video image. The color model is used in our previous study and shown as:
\(\left\{\begin{array}{l}0<R-G<120 \\ 60<R-B<160 \\ 10<G-B<120\end{array}\right.\)
Here, R, G and B represent the value of R channel, Gchannel andB channel, respectively. The thresholds are determined by empirical values.
为了评估这些方法的性能,实验结果将在同一场景下和获取火焰检测方法进行比较,如图Fig.5c。第一个方法是基于视频图像颜色的。颜色模型在我们之前的研究中被表示为:
RGB颜色分别代表不同颜色通道,分别(respectively)。
阈值是通过经验值确定的。
The second recognition method is based on near-infrared video image, and the flame area is extracted by the regional growth algorithm [39], which is suitable for flame segmentation. The selection regulation of pixel is shown as:
1, R_{1}(x, y) * R_{2}(x, y)=1 \\
0, \text { otherwise }
\end{array}\right.
\]
Here, \(R_{1}(x, y)=\left\{\begin{array}{l}1, f(x, y) \geq T_{\text {gray }} \\ 0, \text { otherwise }\end{array}\right.\), \(R_{2}(x, y)=\left\{\begin{array}{l}1,\left|f_{t}(x, y)-f_{t-1}(x, y)\right| \geq T_{m} \\ 0, \text { otherwise }\end{array}\right.\),\(T_{gray}\) denotes the threshold of pixel intensity, \(f_{t}(x, y)\) and \(f_{t-1}(x, y)\) denote video images at \(t\) and \(t-1\), respectively, \(T_{m}\) denotes the threshold of frame difference between \(f_{t}(x, y)\) and \(f_{t-1}(x, y)\). Then, the four-neighborhood growth mode is adopted to obtain the whole area of flame.
第二种识别( recognition)方法是基于近红外视频图像,通过区域生长算法提取火焰区域,适合于火焰分割。这个选择规则像素值被表示为:
其中,\(T_{gray}\)表示( denotes)像素强度阈值(threshold)。
\(T_{m}\) 表示火焰阈值差别在 \(f_{t}(x, y)\) 和 \(f_{t-1}(x, y)\)之间的。
然后, 整个火焰区域会被四领域生长模型采用。然后,采用四邻域生长模式获得整个火焰区域。
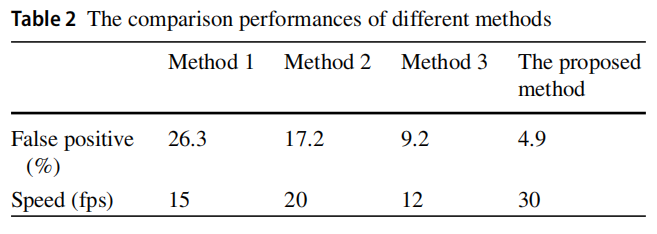
The third recognition method is used in our previous study which combines the first two methods, and the last method is proposed method. However, flame detection rates of first three methods are quite lower than the proposed detection rate. The comparison of computation speed of different methods is present in Table 2.
第三种识别方法会被我们之前的研究方法结合了前两种方法,最近的方法被建议方法。但是,前3种方法的火焰检测率都相当低于本文提出的检测率。不同方法的计算速度比较见表2。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:目标检测 | 火焰烟雾检测论文(实验部分) - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 