Pandas DataFrame结构是什么?
Pandas DataFrame 是一种二维、大小可变且表格型的数据结构,它可以存储许多类型的数据并提供多种数据操作功能。
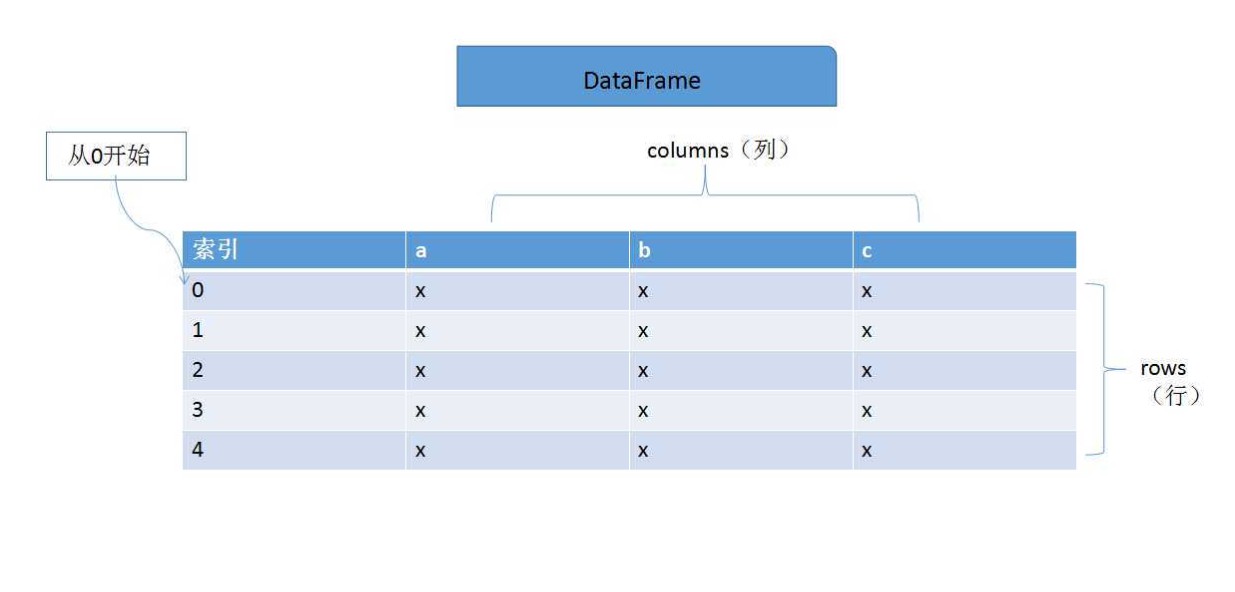
DataFrame 既有行索引也有列索引,类似于一个电子表格或 SQL 表格,能够更加方便地处理数据。结构如下图:
Pandas DataFrame 的作用主要有:
-
数据的读取和写入:可以通过 DataFrame 快速读取和写入多种数据源的数据,例如 CSV、Excel、SQL 数据库、HDF5 等。
-
数据清洗和预处理:可以使用 DataFrame 进行数据清洗和预处理,例如缺失值处理、重复值处理、数据转换、数据合并、数据分组等。
-
数据分析和可视化:Pandas 为 DataFrame 提供了大量的数据分析和统计计算方法,例如排序、过滤、聚合、透视表等,还可以通过 Matplotlib 或其他可视化工具进行数据可视化。
-
机器学习和数据挖掘:Pandas 与 NumPy、Scikit-learn 等 Python 库结合使用,可以进行机器学习和数据挖掘。
Pandas 创建DataFrame对象
在 Pandas 中,创建 DataFrame 对象有多种方法,包括从列表、字典、Series 对象等数据结构中创建,也可以通过读取外部文件的方式进行创建。下面分别介绍常见的创建方法:
从列表中创建
可以通过传递一个由等长列表或 NumPy 数组组成的列表来创建一个 DataFrame。示例如下:
import pandas as pd
data = [['Alice', 25], ['Bob', 30], ['Charlie', 35]]
df = pd.DataFrame(data, columns=['Name', 'Age'])
print(df)输出结果如下:
Name Age
0 Alice 25
1 Bob 30
2 Charlie 35从字典中创建
可以通过传递一个字典来创建 DataFrame,其中字典的键为列名,字典的值为该列的数据。示例如下:
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie'], 'Age': [25, 30, 35]}
df = pd.DataFrame(data)
print(df)输出结果如下:
Name Age
0 Alice 25
1 Bob 30
2 Charlie 35从 Series 对象中创建
可以通过传递一个由 Series 对象组成的字典来创建 DataFrame,其中字典的键为列名,字典的值为该列的数据。示例如下:
import pandas as pd
data = {'Name': pd.Series(['Alice', 'Bob', 'Charlie']), 'Age': pd.Series([25, 30, 35])}
df = pd.DataFrame(data)
print(df)输出结果如下:
Name Age
0 Alice 25
1 Bob 30
2 Charlie 35从 NumPy 数组中创建
可以通过传递一个由 NumPy 数组组成的字典来创建 DataFrame,其中字典的键为列名,字典的值为该列的数据。示例如下:
import pandas as pd
import numpy as np
data = {'Name': ['Alice', 'Bob', 'Charlie'], 'Age': np.array([25, 30, 35])}
df = pd.DataFrame(data)
print(df)输出结果如下:
Name Age
0 Alice 25
1 Bob 30
2 Charlie 35从外部文件中读取:可以通过读取外部文件的方式来创建 DataFrame,包括读取 CSV、Excel、SQL 数据库等。示例如下:
import pandas as pd
# 从 CSV 文件中读取数据
df = pd.read_csv('data.csv')
# 从 Excel 文件中读取数据
df = pd.read_excel('data.xlsx')
# 从 SQL 数据库中读取数据
import sqlite3
conn = sqlite3.connect('example.db')
df = pd.read_sql_query('SELECT * FROM table_name', conn)通过以上几种方法,可以创建出不同形式的 DataFrame 对象,满足不同的数据处理需求。
Pandas 访问DataFrame结构对象
Pandas也提供了多种方法来访问DataFrame对象的数据,包括以下常用方法:
使用列名访问列数据
可以通过DataFrame的列名来访问DataFrame中的数据,可以使用类似字典的方式或者属性的方式来访问。例如,假设有如下DataFrame:
import pandas as pd
data = {'name': ['Alice', 'Bob', 'Charlie', 'David', 'Eva'],
'age': [25, 32, 18, 47, 21],
'gender': ['F', 'M', 'M', 'M', 'F']}
df = pd.DataFrame(data)可以使用df['name']或者df.name来访问name这一列的数据。
使用行索引和列索引访问数据
可以使用loc和iloc属性来访问DataFrame中的数据,其中loc使用行和列的标签来访问数据,iloc使用行和列的索引来访问数据。例如,假设有如下DataFrame:
import pandas as pd
data = {'name': ['Alice', 'Bob', 'Charlie', 'David', 'Eva'],
'age': [25, 32, 18, 47, 21],
'gender': ['F', 'M', 'M', 'M', 'F']}
df = pd.DataFrame(data, index=['a', 'b', 'c', 'd', 'e'])可以使用df.loc['a', 'name']来访问第一行第一列的数据,使用df.iloc[0, 0]来访问第一行第一列的数据。
使用条件访问数据
可以使用布尔型数组或者条件表达式来访问满足特定条件的数据。例如,假设有如下DataFrame:
import pandas as pd
data = {'name': ['Alice', 'Bob', 'Charlie', 'David', 'Eva'],
'age': [25, 32, 18, 47, 21],
'gender': ['F', 'M', 'M', 'M', 'F']}
df = pd.DataFrame(data)可以使用df[df['age'] > 30]来访问年龄大于30的数据。
使用函数访问数据
可以使用apply或者applymap方法来对DataFrame中的数据进行函数操作。其中,apply用于对每一列或者每一行进行操作,applymap用于对DataFrame中的每个元素进行操作。
例如,假设有如下DataFrame:
import pandas as pd
data = {'name': ['Alice', 'Bob', 'Charlie', 'David', 'Eva'],
'age': [25, 32, 18, 47, 21],
'gender': ['F', 'M', 'M', 'M', 'F']}
df = pd.DataFrame(data)可以使用df['age'].apply(lambda x: x * 2)来将年龄列中的每个数值乘以2,使用df.applymap(lambda x: str(x))来将DataFrame中的每个元素转换为字符串类型。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:Pandas DataFrame结构对象的创建与访问方法 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 