#!/usr/bin/env python
# coding: utf-8
import os,sys
import numpy as np
import scipy
from scipy import ndimage
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.keras.applications.resnet50 import ResNet50
from tensorflow.keras.preprocessing import image
from tensorflow.keras.applications.resnet50 import preprocess_input, decode_predictions
from PIL import Image
import random
def DataSet():
train_path_glue ='/data_1/Yang/project_new/2020/tf_study/dog_cat/data/cats_and_dogs_filtered/train/cats/'
train_path_medicine = '/data_1/Yang/project_new/2020/tf_study/dog_cat/data/cats_and_dogs_filtered/train/dogs/'
test_path_glue ='/data_1/Yang/project_new/2020/tf_study/dog_cat/data/cats_and_dogs_filtered/validation/cats/'
test_path_medicine = '/data_1/Yang/project_new/2020/tf_study/dog_cat/data/cats_and_dogs_filtered/validation/dogs/'
imglist_train_glue = os.listdir(train_path_glue)
imglist_train_medicine = os.listdir(train_path_medicine)
imglist_test_glue = os.listdir(test_path_glue)
imglist_test_medicine = os.listdir(test_path_medicine)
X_train = np.empty((len(imglist_train_glue) + len(imglist_train_medicine), 224, 224, 3))
Y_train = np.empty((len(imglist_train_glue) + len(imglist_train_medicine), 2))
count = 0
for img_name in imglist_train_glue:
img_path = train_path_glue + img_name
img = image.load_img(img_path, target_size=(224, 224))
img = image.img_to_array(img) / 255.0
X_train[count] = img
Y_train[count] = np.array((1,0))
count+=1
for img_name in imglist_train_medicine:
img_path = train_path_medicine + img_name
img = image.load_img(img_path, target_size=(224, 224))
img = image.img_to_array(img) / 255.0
X_train[count] = img
Y_train[count] = np.array((0,1))
count+=1
X_test = np.empty((len(imglist_test_glue) + len(imglist_test_medicine), 224, 224, 3))
Y_test = np.empty((len(imglist_test_glue) + len(imglist_test_medicine), 2))
count = 0
for img_name in imglist_test_glue:
img_path = test_path_glue + img_name
img = image.load_img(img_path, target_size=(224, 224))
img = image.img_to_array(img) / 255.0
X_test[count] = img
Y_test[count] = np.array((1,0))
count+=1
for img_name in imglist_test_medicine:
img_path = test_path_medicine + img_name
img = image.load_img(img_path, target_size=(224, 224))
img = image.img_to_array(img) / 255.0
X_test[count] = img
Y_test[count] = np.array((0,1))
count+=1
index = [i for i in range(len(X_train))]
random.shuffle(index)
X_train = X_train[index]
Y_train = Y_train[index]
index = [i for i in range(len(X_test))]
random.shuffle(index)
X_test = X_test[index]
Y_test = Y_test[index]
return X_train,Y_train,X_test,Y_test
X_train,Y_train,X_test,Y_test = DataSet()
print('X_train shape : ',X_train.shape)
print('Y_train shape : ',Y_train.shape)
print('X_test shape : ',X_test.shape)
print('Y_test shape : ',Y_test.shape)
# # model
model = ResNet50(
weights=None,
classes=2
)
model.compile(optimizer=tf.train.AdamOptimizer(0.0001),
loss='categorical_crossentropy',
metrics=['accuracy'])
# # train
model.fit(X_train, Y_train, epochs=100, batch_size=10)
# # evaluate
model.evaluate(X_test, Y_test, batch_size=4)
# # save
model.save('my_resnet_model.h5')
# # restore
model = tf.keras.models.load_model('my_resnet_model.h5')
# # test
#img_path = "../my_nn/dataset/test/medicine/IMG_20190717_135408_BURST91.jpg"
img_path = "/data_1/Yang/project_new/2020/tf_study/dog_cat/data/cats_and_dogs_filtered/validation/dogs/dog.2001.jpg"
img = image.load_img(img_path, target_size=(224, 224))
plt.imshow(img)
img = image.img_to_array(img) / 255.0
img = np.expand_dims(img, axis=0) # 为batch添加第四维
print(model.predict(img))
np.argmax(model.predict(img))
训练了一晚,精度为1了。
1430/2000 [====================>.........] - ETA: 7s - loss: 7.3690e-05 - acc: 1.0000
1440/2000 [====================>.........] - ETA: 7s - loss: 7.3408e-05 - acc: 1.0000
1450/2000 [====================>.........] - ETA: 7s - loss: 7.3001e-05 - acc: 1.0000
1460/2000 [====================>.........] - ETA: 7s - loss: 7.2536e-05 - acc: 1.0000
1470/2000 [=====================>........] - ETA: 7s - loss: 7.2071e-05 - acc: 1.0000
1480/2000 [=====================>........] - ETA: 7s - loss: 7.1652e-05 - acc: 1.0000
1490/2000 [=====================>........] - ETA: 7s - loss: 7.1217e-05 - acc: 1.0000
1500/2000 [=====================>........] - ETA: 6s - loss: 7.0746e-05 - acc: 1.0000
1510/2000 [=====================>........] - ETA: 6s - loss: 7.0286e-05 - acc: 1.0000
1520/2000 [=====================>........] - ETA: 6s - loss: 6.9827e-05 - acc: 1.0000
1530/2000 [=====================>........] - ETA: 6s - loss: 6.9371e-05 - acc: 1.0000
1540/2000 [======================>.......] - ETA: 6s - loss: 6.8931e-05 - acc: 1.0000
1550/2000 [======================>.......] - ETA: 6s - loss: 6.8540e-05 - acc: 1.0000
1560/2000 [======================>.......] - ETA: 6s - loss: 6.8104e-05 - acc: 1.0000
1570/2000 [======================>.......] - ETA: 5s - loss: 6.7679e-05 - acc: 1.0000
1580/2000 [======================>.......] - ETA: 5s - loss: 6.7253e-05 - acc: 1.0000
1590/2000 [======================>.......] - ETA: 5s - loss: 6.6830e-05 - acc: 1.0000
1600/2000 [=======================>......] - ETA: 5s - loss: 6.6413e-05 - acc: 1.0000
1610/2000 [=======================>......] - ETA: 5s - loss: 6.6007e-05 - acc: 1.0000
1620/2000 [=======================>......] - ETA: 5s - loss: 6.5846e-05 - acc: 1.0000
1630/2000 [=======================>......] - ETA: 5s - loss: 6.5456e-05 - acc: 1.0000
1640/2000 [=======================>......] - ETA: 4s - loss: 6.5083e-05 - acc: 1.0000
1650/2000 [=======================>......] - ETA: 4s - loss: 6.4695e-05 - acc: 1.0000
1660/2000 [=======================>......] - ETA: 4s - loss: 6.4306e-05 - acc: 1.0000
1670/2000 [========================>.....] - ETA: 4s - loss: 6.3945e-05 - acc: 1.0000


数据集下载链接:
https://download.csdn.net/download/yang332233/12245950
###############################################################################################################
示例2####################################################################################################
###############################################################################################################
import os
import zipfile
import tensorflow as tf
from tensorflow.keras.optimizers import RMSprop
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# local_zip = '/tmp/cats_and_dogs_filtered.zip'
# zip_ref = zipfile.ZipFile(local_zip, 'r')
# zip_ref.extractall('/tmp')
# zip_ref.close()
base_dir = '/data_1/Yang/project_new/2020/tf_study/dog_cat/data/cats_and_dogs_filtered'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
# Directory with our training cat pictures
train_cats_dir = os.path.join(train_dir, 'cats')
# Directory with our training dog pictures
train_dogs_dir = os.path.join(train_dir, 'dogs')
# Directory with our validation cat pictures
validation_cats_dir = os.path.join(validation_dir, 'cats')
# Directory with our validation dog pictures
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(150, 150, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(128, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(128, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy',
optimizer=RMSprop(lr=1e-4),
metrics=['acc'])
# All images will be rescaled by 1./255
# train_datagen = ImageDataGenerator(rescale=1./255)
train_datagen = ImageDataGenerator(
rescale=1. / 255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
test_datagen = ImageDataGenerator(rescale=1./255)
# Flow training images in batches of 20 using train_datagen generator
train_generator = train_datagen.flow_from_directory(
train_dir, # This is the source directory for training images
target_size=(150, 150), # All images will be resized to 150x150
batch_size=20,
# Since we use binary_crossentropy loss, we need binary labels
class_mode='binary')
# Flow validation images in batches of 20 using test_datagen generator
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
history = model.fit_generator(
train_generator,
steps_per_epoch=100, # 2000 images = batch_size * steps
epochs=100,
validation_data=validation_generator,
validation_steps=50, # 1000 images = batch_size * steps
verbose=2)
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training accuracy')
plt.plot(epochs, val_acc, 'b', label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training Loss')
plt.plot(epochs, val_loss, 'b', label='Validation Loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
from tensorflow.keras.preprocessing.image import ImageDataGenerator
def get_train_dataset(dataset_path, batch_size):
train_datagen = ImageDataGenerator(featurewise_center=True, featurewise_std_normalization=True, rotation_range=20,
width_shift_range=0.2, height_shift_range=0.2, horizontal_flip=True)
train_generator = train_datagen.flow_from_directory(dataset_path, target_size=(224, 224),
batch_size = batch_size, class_mode='categorical')
return train_generator
def get_val_dataset(dataset_path, batch_size):
val_datagen = ImageDataGenerator()
val_generator = val_datagen.flow_from_directory(dataset_path, target_size=(224, 224),
batch_size = batch_size, class_mode='categorical')
return val_generator
示例3
from keras.applications import VGG16
from keras.preprocessing.image import ImageDataGenerator
from keras import models
from keras import layers
from keras import optimizers
import matplotlib.pyplot as plt
train_dir = r'D:\kaggle\\dogsvscats\\cats_and_dogs_small\\train'
validation_dir = r'D:\kaggle\\dogsvscats\\cats_and_dogs_small\\validation'
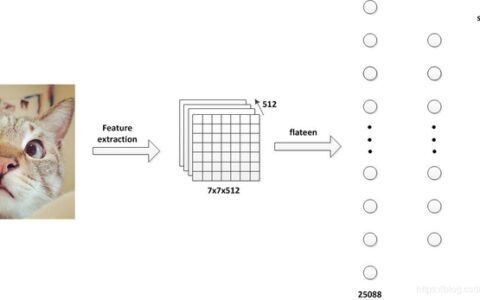
conv_base = VGG16(weights='imagenet',
include_top=False,
input_shape=(150, 150, 3))
conv_base.trainable = False
model = models.Sequential()
model.add(conv_base)
model.add(layers.Flatten())
model.add(layers.Dense(256, activation='relu', input_dim=4 * 4 * 512))
model.add(layers.Dense(1, activation='sigmoid'))
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
directory=train_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
directory=validation_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary')
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=2e-5),
metrics=['acc'])
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=100,
validation_data=validation_generator,
validation_steps=50)
model.save('cats_and_dogs_small_4.h5')
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
样例4#########
# encoding:utf-8
'''
用于训练垃圾分类模型
'''
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
from keras.callbacks import ModelCheckpoint
from keras import backend as K
# dimensions of our images.
img_width, img_height = 512, 384
train_data_dir = 'data/train'
validation_data_dir = 'data/validation'
nb_train_samples = 2357
nb_validation_samples = 170
epochs = 30
batch_size = 20
if K.image_data_format() == 'channels_first':
input_shape = (3, img_width, img_height)
else:
input_shape = (img_width, img_height, 3)
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=input_shape))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(3)) # 3分类
model.add(Activation('softmax')) # 采用Softmax
model.compile(loss='categorical_crossentropy', # 多分类
optimizer='rmsprop',
metrics=['accuracy'])
# this is the augmentation configuration we will use for training
train_datagen = ImageDataGenerator(
rescale=1. / 255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
# this is the augmentation configuration we will use for testing:
# only rescaling
test_datagen = ImageDataGenerator(rescale=1. / 255)
train_generator = train_datagen.flow_from_directory(
train_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode='categorical') # 多分类
validation_generator = test_datagen.flow_from_directory(
validation_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode='categorical') # 多分类
filepath="weights-improvement-{epoch:02d}-{val_acc:.2f}.h5"
checkpoint = ModelCheckpoint(filepath, monitor='val_acc', verbose=0, save_best_only=False, save_weights_only=False, mode='auto', period=1)
callbacks_list = [checkpoint]
model.fit_generator(
train_generator,
steps_per_epoch=nb_train_samples // batch_size,
epochs=epochs,
callbacks=callbacks_list,
validation_data=validation_generator,
validation_steps=nb_validation_samples // batch_size)
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:tf2.0/1.15 keras 简单的二分类 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫