Tensorflow循环神经网络
- 循环神经网络
- 梯度消失问题
- LSTM网络
- RNN其他变种
- 用RNN和Tensorflow实现手写数字分类
一.循环神经网络
from IPython.display import Image
Image(filename="./data/rnn_1.png",width=500)
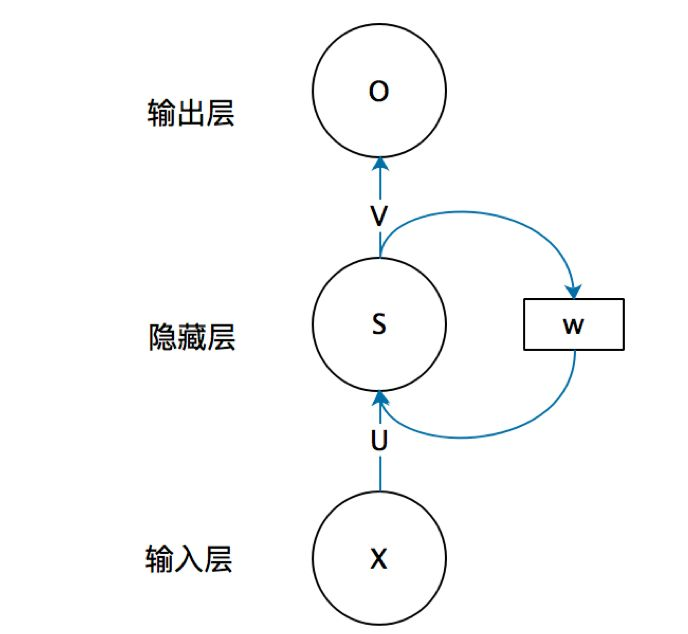

RNN背后的思想就是利用顺序信息.在传统的神经网络中,我们假设所有输入(或输出)彼此独立.但对于许多任务而言,这是一个非常糟糕的模型.如果你想预测句子中的下一个单词,你最好知道它前面有哪些单词.RNN对序列的每个元素执行相同的任务,输出取决于先前的计算.下面是典型的RNN样子
from IPython.display import Image
Image(filename="./data/rnn_2.png",width=500)
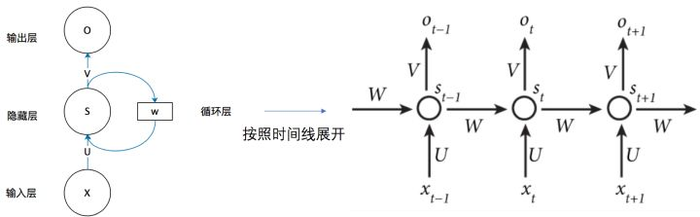
其中U是输入到隐含层的权重矩阵,W是状态到隐含层的权重矩阵,s为状态,V是隐含层到输出层的权重矩阵.它的共享参数方式是各个时间节点的W,U,V都是不变的,这个机制就像卷积神经网络的过滤器机制一样,通过这种方法实现参数共享,同时大大降低参数量
Image(filename="./data/rnn_3.png",width=500)
在Tensorflow中,将图中间循环体结构叫作cell,可以使用tf.nn.rnn_cell.BasicRNNCell或者tf.contrib.rnn.BasicRNNCell表达,这两个表达仅是同一个对象的不同名字,没有本质的区别.例如,tf.nn.rnn_cell.BasicRNNCell定义的参数如下代码所示:
tf.nn.rnn_cell.BasicRNNCell(num_units,activation=None,reuse=None,name=None)
参数说明如下:
- num_units:int类型,必选参数.表示cell由多少个类似于cell的单元构成
- activation:string类型,激活函数,默认为tanh
- reuse:bool类型.代表是否重新使用scope中的参数
- name:string类型.名称
二.前向传播与随时间方向传播
1.RNN前向传播
Image(filename="./data/rnn_example.png",width=500)
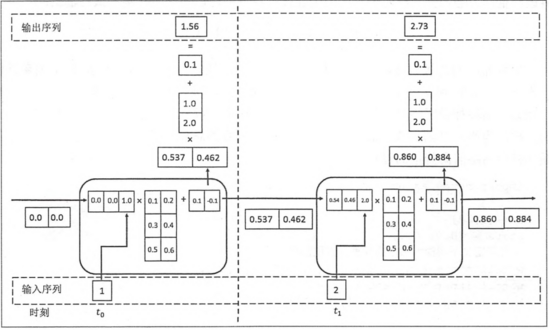
import numpy as np
X=[1,2]
state=[0.0,0.0]
w_cell_state=np.asarray([[0.1,0.2],[0.3,0.4],[0.5,0.6]])
b_cell=np.asarray([0.1,-0.1])
w_output=np.asarray([[1.0],[2.0]])
b_output=0.1
for i in range(len(X)):
state=np.append(state,X[i])
before_activation=np.dot(state,w_cell_state)+b_cell
state=np.tanh(before_activation)
final_output=np.dot(state,w_output)+b_output
print("状态值_%i"%i,state)
print("输出值-%i"%i,final_output)
状态值_0 [0.53704957 0.46211716]
输出值-0 [1.56128388]
状态值_1 [0.85973818 0.88366641]
输出值-1 [2.72707101]
2.RNN随时间反向传播
RNN的反向传播训练算法称为随时间反向传播(Backpropagation Through Time,BPTT)算法,其基本原理和反向传播算法是一样的,只不过反向传播算法是按照层进行反向传播的,而BPTT是按照时间进行反向传播的
三.梯度消失或爆炸
在实际应用中,上述介绍的标准循环神经网络训练的优化算法面临一个很大的难题,就是长期依赖问题.由于网络结构变深,使得模型丧失了学习先前信息的能力.通俗地讲,标准的循环神经网络虽然有了记忆,但很健忘.循环神经网络实际上是在长时间序列的各个时刻重复应用相同操作来构建非常深的计算图,并且模型参数共享,这让问题变得更加凸显.例如,W是一个在时间步中反复被用于相乘的矩阵,举个简单情况,比方说W可以由特征值分解

因此很容易看出:

当特征值r_i不在1附近时,若在量级上大于1则会爆炸;若小于1则会消失.这便是著名的梯度消失或爆炸问题(vanishing and exploding gradient problem).梯度的消失使得我们难以知道参数朝哪个方向移动能改进代价函数,而梯度的爆炸会使学习过程变得不稳定
实际上梯度消失或爆炸问题应该是深度学习中的一个基本问题,在任何深度神经网络中都可能存在,而不仅是循环神经网络所独有.在RNN中,相邻时间步是连接在一起的,因此它们的权重偏导数要么都小于1,要么都大于1,RNN中每个权重都会向相同的反方向变化,这样与前馈神经网络相比,RNN的梯度消失或爆炸会更加明显
如何避免梯度消失或爆炸问题?目前最流行的一种解决方案称为长短时记忆网络(Long Short-Term Memory,LSTM),还有基于LSTM的几种变种算法,如GRU(Gated Recurrent Unit,GRU)算法等
三.LSTM算法
LSTM能够有效解决信息的长期依赖,避免梯度消失或爆炸.事实上,LSTM的设计就是专门用于解决长期依赖问题的.与传统RNN相比,它在结构上的独特之处是它精巧地设计了循环体结构.LSTM用两个门来控制单元状态h的内容:一个是遗忘门(forget gate),它决定了上一时刻的单元状态h_t-1有多少保留到当前时刻c_t;另一个是输入门(input gate),它决定了当前时刻网络的输入x_t有多少保存到单元状态c_t.LSTM用输出门(output gate)来控制单元状态h_t有多少输出到LSTM的当前输出值h
Image(filename="./data/LSTM.png",width=500)
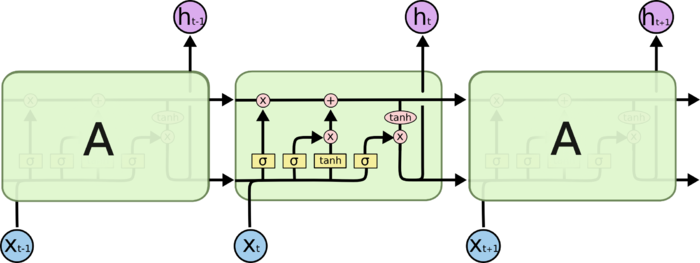
Image(filename="./data/LSTM2.png",width=500)

LSTM对神经元状态的修改是通过一种叫"门"的结构完成的,门使得信息可以有选择性地通过.LSTM中门是由一个sigmoid函数和一个按位乘积运算元件构成的
Image(filename="./data/LSTM3-gate.png",width=500)
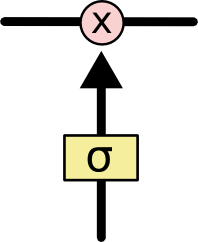
sigmoid函数使得其输出结果在0到1之间,sigmoid的输出结果为0时,则不允许任何信息通过;sigmoid为1时则允许全部信息通过;sigmoid的输出位于(0,1)之间时,则允许部分信息通过.LSTM有三个这样门结构,即输入门,遗忘门和输出门,用来保护和控制神经元状态的改变
与标准的RNN一样,在Tensorflow中,LSTM的循环结构也有较好的封装类,有tf.nn.rnn_cell.BasicLSTMCell或tf.contrib.rnn.BasicLSTMCell,两者功能相同,使用参数也完全一致
tf.nn.rnn_cell.BasicLSTMCell(num_units,forget_bias=1.0,state_is_tuple=True,activation=None,reuse=None,name=None)
参数说明:
- num_units:int,表示LSTM cell中基本神经单元的个数
- forget_bias:float,默认为1,遗忘门中的bias添加项
- activation:string,内部状态的激活函数,默认为tanh
- reuse:bool,可选参数,默认为True,决定是否重用当前变量scope中的变量
- name:string,可选参数,默认为None.指layer的名称,相同名称的层会共享变量,使用时应注意与reuse配合
以下代码完成了一个简单的LSTM网络结构的构建
import tensorflow as tf
num_units=128
num_layers=2
batch_size=100
# 创建一个BasicLSTMCell,即LSTM循环体
# num_units为循环体中基本单元的个数,数量越多,网络的特征表达能力越强
rnn_cell=tf.contrib.rnn.BasicLSTMCell(num_units)
# 使用多层结构,返回值仍然为cell结构
if num_layers>=2:
rnn_cell=tf.nn.rnn_cell.MultiRNNCell([rnn_cell]*num_layers)
# 定义初始化状态
initial_state=rnn_cell.zero_state(batch_size,dtype=tf.float32)
# 定义输入数据结构以完成循环神经网络的构建
outputs,state=tf.nn.dynamic_rnn(rnn_cell,input_data,initial_state=initial_state,dtype=tf.float32)
# outputs是一个张量,其形状为[batch_size,max_time,cell_state_size]
# state是一个张量,其形状为[batch_size,cell_state_size]
五.RNN其他变种
1.GRU
RNN的改进版LSTM,它有效克服了传统RNN的一些不足,比较好地解决了梯度消失,长期依赖等问题.不过LSTM也有一些不足,如结构比较复杂,计算复杂度较高.GRU对LSTM做了很多简化,比LSTM少一个Gate,因此计算效率更高
2.Bi-RNN
RNN可以处理不固定长度时序数据,无法利用未来信息.Bi-RNN同时使用时序数据输入历史及未来数据,时序相反时两个循环神经网络连接同一输出,输出层可以同时获取历史未来信息
Image(filename="./data/Bi-RNN.png",width=500)
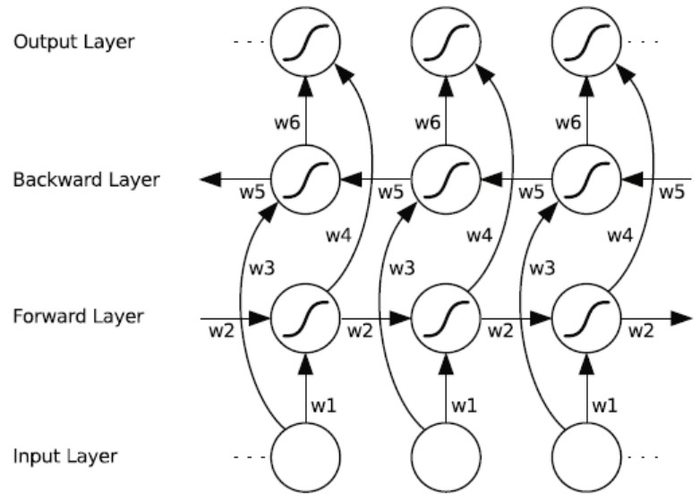
双向循环神经网络的基本思想是:每一个训练序列向前和向后分别是两个循环神经网络(RNN),而且这两个都连接着一个输出层.这个结果提供给输出层输入序列中每一个点完整的过去和未来的上下文信息.六个独特的权值在每一个时步被重复利用,六个权值分别对应着输入到向前和向后隐含层(w1,w3),隐含层到隐含层自己(w2,w5),向前和向后隐含层到输出层(w4,w6).值得注意的是,向前和向后隐含层之间没有信息流,这保证了展开图是非循环的
六.RNN应用场景
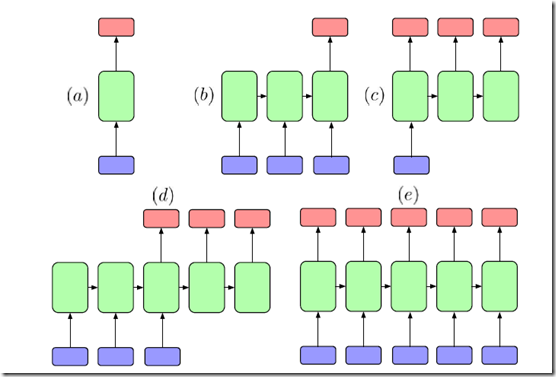
RNN网络适合于处理序列数据,序列长度一般不是固定的
Image(filename="./data/RNN_4.png",width=500)
七.用LSTM实现分类
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import numpy as np
import matplotlib.pyplot as plt
tf.set_random_seed(1)
np.random.seed(1)
# 定义超参数
BATCH_SIZE=64
TIME_STEP=28
INPUT_SIZE=28
LR=0.1
#读人数据
mnist=input_data.read_data_sets("./data/mnist/",one_hot=True)
test_x=mnist.test.images[:2000]
test_y=mnist.test.labels[:2000]
# 画出一张图片观察一下
print(mnist.train.images.shape)
print(mnist.train.labels.shape)
plt.imshow(mnist.train.images[0].reshape((28,28)),cmap="gray")
plt.title("%i"%np.argmax(mnist.train.labels[0]))
plt.show()
# 定义表示x向量的tensorflow.placeholder
tf_x=tf.placeholder(tf.float32,[None,TIME_STEP*INPUT_SIZE])
image=tf.reshape(tf_x,[-1,TIME_STEP,INPUT_SIZE])
# 定义表示 y 向量的placeholder
tf_y=tf.placeholder(tf.int32,[None,10])
# RNN 的循环体结构,使用 LSTM
rnn_cell=tf.contrib.rnn.BasicLSTMCell(num_units=64)
outputs,(h_c,h_n)=tf.nn.dynamic_rnn(
rnn_cell,
image,
initial_state=None,
dtype=tf.float32,
time_major=False,
)
output=tf.layers.dense(outputs[:,-1,:],10)
loss=tf.losses.softmax_cross_entropy(onehot_labels=tf_y,logits=output)
train_op=tf.train.AdamOptimizer(LR).minimize(loss)
# 预测精度
accuracy=tf.metrics.accuracy(labels=tf.argmax(tf_y,axis=1),predictions=tf.argmax(output,axis=1),)[1]
session=tf.Session()
init_op=tf.group(tf.global_variables_initializer(),tf.local_variables_initializer())
session.run(init_op)
for step in range(1200):
b_x,b_y=mnist.train.next_batch(BATCH_SIZE)
_,loss_=session.run([train_op,loss],{tf_x:b_x,tf_y:b_y})
if step%50==0:
accuracy_=session.run(accuracy,{tf_x:test_x,tf_y:test_y})
print("Train loss:%.4f"%loss_,"| Test accuracy:%.2f"%accuracy_)
#输出测试集中的十个预测结果
test_output=session.run(output,{tf_x:test_x[:10]})
pred_y=np.argmax(test_output,1)
print(pred_y,"prediction number")
print(np.argmax(test_y[:10],1),"real number")
(55000, 784)
(55000, 10)
<Figure size 640x480 with 1 Axes>
WARNING:tensorflow:From <ipython-input-1-571f25e9d86b>:35: BasicLSTMCell.__init__ (from tensorflow.python.ops.rnn_cell_impl) is deprecated and will be removed in a future version.
Instructions for updating:
This class is equivalent as tf.keras.layers.LSTMCell, and will be replaced by that in Tensorflow 2.0.
WARNING:tensorflow:From <ipython-input-1-571f25e9d86b>:42: dynamic_rnn (from tensorflow.python.ops.rnn) is deprecated and will be removed in a future version.
Instructions for updating:
Please use `keras.layers.RNN(cell)`, which is equivalent to this API
WARNING:tensorflow:From E:Anacondaenvsmytensorflowlibsite-packagestensorflowpythonopstensor_array_ops.py:162: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.
Instructions for updating:
Colocations handled automatically by placer.
WARNING:tensorflow:From <ipython-input-1-571f25e9d86b>:45: dense (from tensorflow.python.layers.core) is deprecated and will be removed in a future version.
Instructions for updating:
Use keras.layers.dense instead.
WARNING:tensorflow:From E:Anacondaenvsmytensorflowlibsite-packagestensorflowpythonopslosseslosses_impl.py:209: to_float (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.cast instead.
Train loss:2.3271 | Test accuracy:0.10
Train loss:1.5117 | Test accuracy:0.26
Train loss:1.0649 | Test accuracy:0.38
Train loss:0.9420 | Test accuracy:0.46
Train loss:0.4853 | Test accuracy:0.51
Train loss:0.5550 | Test accuracy:0.56
Train loss:0.5579 | Test accuracy:0.59
Train loss:0.4607 | Test accuracy:0.61
Train loss:0.7924 | Test accuracy:0.63
Train loss:0.6559 | Test accuracy:0.65
Train loss:0.3282 | Test accuracy:0.66
Train loss:0.5112 | Test accuracy:0.67
Train loss:0.5746 | Test accuracy:0.68
Train loss:0.5322 | Test accuracy:0.69
Train loss:0.6505 | Test accuracy:0.70
Train loss:0.6257 | Test accuracy:0.71
Train loss:0.5075 | Test accuracy:0.71
Train loss:0.9287 | Test accuracy:0.72
Train loss:0.4810 | Test accuracy:0.73
Train loss:0.3196 | Test accuracy:0.73
Train loss:0.5486 | Test accuracy:0.74
Train loss:0.6377 | Test accuracy:0.74
Train loss:0.6051 | Test accuracy:0.74
Train loss:0.6930 | Test accuracy:0.74
[7 2 1 0 4 1 4 7 6 9] prediction number
[7 2 1 0 4 1 4 9 5 9] real number
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:Tensorflow循环神经网络 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 