1.gensim的安装
可以使用如下命令安装gensim
conda install -i https://pypi.tuna.tsinghua.edu.cn/simple gensim==3.8.2
2.生成分词列表
这一步已经有生成好的分词列表可以忽略
项目列表:

点击查看代码
# coding:utf-8
from gensim.models import Word2Vec, word2vec
import jieba
import multiprocessing
import torch
# 1. 停用词表
def get_stop_words(filepath='第2题/stop_word.txt') -> list:
return open(filepath, 'r', encoding='utf-8').readlines()[0].split(',')
# 2.分词
def cut_words(sentence, stop_words, save_path=None):
cut_sentence = []
for line in sentence:
cuts = jieba.cut(line, cut_all=False)
new_cuts = []
for cut in cuts:
if cut not in stop_words:
new_cuts.append(cut)
cut_sentence.append(new_cuts)
if save_path:
with open(save_path, 'w') as f:
for ele in cut_sentence:
for e in ele:
e = e + 'n'
f.write(e)
f.flush()
return cut_sentence # 返回 list to list 格式数据
def train_word2vec(words_file):
# 可以用BrownCorpus,Text8Corpus或lineSentence来构建sentences
sentences = list(word2vec.LineSentence(words_file)) # 加载分词后的文件
model = Word2Vec(sentences, size=256, min_count=1, window=5, sg=0, workers=multiprocessing.cpu_count())
return model
def train_word2vec_2(words_file):
sentences = list(word2vec.LineSentence(words_file))
model = Word2Vec(vector_size=256, min_count=1)
# 加载词表
model.build_vocab(sentences)
# 训练
model.train(sentences, total_examples=model.corpus_count, epochs=10)
return model
if __name__ == '__main__':
sentences_list: list = [
'推荐系统可以在海量的数据信息中获取用户偏好,从而更好地实现个性化推荐、提高用户体检以及解决互联网中的信息过载。但其仍然存在冷启动和数据稀疏问题,这也成为当前推荐系统研究重点。知识图谱作为一种拥有大量实体和丰富语义关系结构化知识库,可以辅助推荐系统。其不但能够提高推荐系统的准确性,还能够为推荐项目提供可解释性,从而增强用户对推荐系统的信任度,为解决推荐系统中存在的一系列关键问题提供了新方法、新思路。论文首先针对知识图谱推荐系统进行研究与分析,以应用领域为分类依据将知识图谱推荐系统分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,同时根据这些知识图谱推荐方法的特点进一步分类,对每类方法进行定量分析和定性分析;之后列举出知识图谱推荐系统在其应用领域中常用的数据集,对数据集的规模和特点概述;最后对知识图谱推荐系统未来的研究方向进行展望和总结。优惠的政策和政府对产业发展的重视也吸引了更多医美企业来成都寻觅机遇。2018年成都医美机构的数量一度飙升至407家,较之前一年激增131家。',
'互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐系统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。中国医学科学院整形外科医院也选择于2018年将首家京外分院——成都八大处医疗美容医院落地蓉城。不断增长的营收数据没有让人失望',
'多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。成都八大处医疗美容医院院长唐勇告诉记者,在因新冠肺炎疫情停业近40天的情况下,该院2020年的营收相比2019年仍实现了约30%的增长。'
'“成都打造‘医美之都’的过程中,优惠的政策、聚合的资源、配套的宣传措施等为医美行业造起了‘势’,对行业发展起到积极的推动作用,城市产业氛围十分友好。',
'基于嵌入的方法可以将知识图谱中的图数据通过一些表征学习方法得到特征的低维向量表示而且还能保留知识图谱中实体和项目之间的语义信息,知识图谱通过嵌入的方式将更加全面的数据信息提供给推荐系统。但此类方法会忽略掉知识图谱中路径的设计以及多跳实体之间的关联信息,导致基于嵌入的方法可解释性不强其中公式(4)中的Ρ(vj∣∣ui)表示用户ui首先选择项目vj的概率。公式(3)中pθ(vj∣∣ui,r)表示推荐系统中的评分函数pture(vj∣∣ui,r)表示用户真实偏好。Ye等人[38]提出了BEM边界元模型,BEM模型要学习两类知识图,用TransE模型学习项目属性知识图谱,该知识图谱包含着项目的属性信息,用GraphSAGE[39]模型学习用户行为知识图谱,该知识图谱包含了用户行为信息,如用户之间的关联信息、用户的共同购买信息和共同收藏信息等。BEM通过对两类知识图谱的学习得到初始嵌入表示,再通过贝叶斯模型对嵌入表示进行细化,推荐系统会根据用户之间的共同行为,在行为知识图谱中找到最相关的项目进行推荐。两阶段学习法非常易于实现,更加适合大规模的数据。但是它的推荐模块和KGE[40]模块结构性松散,相互依赖程度较低。b) 联合学习法。将知识图谱的特征学习和推荐系统的函数部分进行结合,推荐系统可以指导知识图谱的学习表征过程,实现端到端的联合学习。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,知识图谱技术在各行业事故故障智能化服务中已得到了广泛的研究和应用。在电力行业,李新鹏等人[7]通过构建调度自动化系统的知识图谱,实现系统故障的智能诊断和分析;郭榕等人[8]针对电网故障处置预案数据,构建电网故障处置知识图谱,提升了电网故障处置能力和智能化水平;在中石油领域,陈传刚等人[9]构建基于知识图谱的站场故障预警模型,实现现场事故预警;在铁路领域,杨连报等人[10]通过构建铁路设备事故故障部位知识图谱,实现了设备故障关联分析和原因推荐。基于各行业对知识图谱构建方法及应用模式的研究,本文在研究铁路运输设备安全保障体系的基础上,提出了铁路运输设备故障知识图谱构建与应用架构,以及设备故障知识图谱应用场景本研究也存在一些不足之处,一是因为诊疗指南是医学知识的高度凝练,能够抽取并用来构建知识图谱的知识的数量较为有限,后续将进一步扩充相关的高质量的知识来源,不断对本研究所构建的知识图谱进行丰富和扩展。二是因为目前诊疗指南中的部分数据和关联从知识图谱构建的角度而言存在一定的交叉重叠,为了解决这个问题,我们在数据收集、本体构建和知识融合等环节,需要临床医师根据知识图谱开发的要求,完成交叉知识的拆解和融合才能够更合理的构建知识图谱。三是目前本研究构建的知识图谱中使用的输入症状词语必须与临床指南中用语一致才能识别,还未能支持输入症状列表进行中医临床辅助决策,下一步应在此研究基础上实现自然语言处理功能,训练与指南数据和知识图谱适配的自然语言处理模型,实现从自然语言中自动抽取知识图谱能够识别的用语,并基于知识图谱实现症状列表输入功能。四是目前还未能支持证候的兼夹性和患者更加个体的信息,下一步将开发设置支持多证候显示的知识图谱,以支持兼夹证候的显示,并且从本体层设计纳入更多的体现患者个体差异的数据结构,将临床中患者的个体差异体现在知识图谱展示的诊疗过程中从而将模型整合成为功能更贴近真实临床的中医临床辅助决策系统。上述知识图谱的几个模块,即为依据中医诊疗指南进行辨证论治的过程。通过症状(临床表现)的组合文本,提炼出相应的证候要素,在证候要素的基础上组合出相应的证候类型,根据相应的证候类型即可推断相应的治法,确立治法后,即可推荐相应的中成药和中药方剂,并进一步可视化展示中药方剂所用的中药列表。这个过程即模拟了中医辨证论治冠心病稳定型心绞痛的过程,是诊疗指南的可视化和网络化的展示。下面我们将使用知识图谱的查询检索功能进行展示。图5为“证候类型”、“治法”、“中成药”、“方剂”和“中药”的知识图谱示意图。其中橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体,粉色节点代表“方剂”实体,绿色节点代表“中药”实体。联结“证候类型”实体和“治法”实体之间的边表示“证候类型”对应该“治法”,联结“治法”实体和“方剂”实体之间的边表示该“治法”推荐选择该“方剂”,联结“方剂”实体和“中药”实体之间的边表示该“方剂”由该“中药”组成。如图5所示,“气虚血瘀证”所对应的治法为“益气活血,补虚止痛”,该治法所对应的治疗手段中的中药方剂推荐“八珍汤加味”。方剂“八珍汤加味”的组成中药有“党参”、“白术”、“茯苓”、“甘草”、“当归”“红花”“赤芍”等11种。通过所构建的知识图谱,输入相应的证候类型,即可自动组合出对应的治法,推荐中药方剂,以及显示中药方剂所用的中药药味而图2为“临床表现”与“证候要素”知识图谱的示意图。其中蓝色节点代表“临床表现”实体、紫色节点代表“证候要素”实体,从“临床表现”实体指向“证候要素”实体的有向箭头代表二者之间的关联,即“临床表现”中提炼出该“证候要素”,如“神疲”、“乏力”等临床表现,能够相应的提炼出证候要素“气虚”。通过所构建的知识图谱,可输入相应的临床表现,即可自动提炼组合出对应的证候要素且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。多任务学习法。将嵌入模块和推荐模块设计成了相关又分离的任务,将图3为“证候要素”、“证候类型”和“治法”的知识图谱示意图。其中紫色节点代表“证候要素”实体,橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体。从“证候要素”实体指向“证候类型”实体的有向箭头代表二者之间的关联,即“证候要素”组成该“证候类型”。从“证候类型”实体指向“治法”实体的有向箭头代表二者之间的关联,即“证候类型”对应的治法为该“治法”。“气虚”和“阴虚”这2个证候要素,共同组成“气阴两虚证”这一证候类型,而“气阴两虚证”对应的治法为“益气养阴,活血通络”。通过所构建的知识图谱,输入相应的证候要素列表,即可自动组合出对应的证候类型这些任务放在同一个框架中进行交替学习,使用py2neo将诊疗指南中提取整理好的结构化数据导入到Neo4j数据库中,并进而完成基于中医诊疗指南的冠心病知识图谱构建。构建的知识图谱可通过py2neo或用Cypher语句进行查询和调用。因所构建的知识图谱节点较多,并且节点之间的关联复杂,难以在一张图上做清晰的显示,而诊疗指南中,“气虚”证候要素组合为证候类型的组合可能性较多,为了便于展示尽可能多的组合方式和节点关联,以“气虚”这一个证候要素相关的知识图谱为例(包含临床表现、证候要素、证候类型、治法、中成药、方剂和中药等节点及之间的关联),对所构建的知识图谱的节点和关联进行阐述Wang等人[43]提出了MKR模型,Cao等人[44]提出了KTUP模型。典型的例子就是MRK模型。该模型是由KGE模块和推荐模块组成的,将知识图谱以三元组的形式输入KGE模块,通过KGE模块预测出尾实体。用户和项目的特征表示作为推荐模块的输入,通过推荐模块得到项目点击率的估计值。在KGE模块和推荐模块中间有一个交叉特征共享单元,两个模块可以通过该共享单元进行数据交换,这样就可以得到用户的最终表示uL,如公式(6)所示。项目的最终表示vL,如公式(7)所示。其中vL是由L个交叉压缩单元提取的特征,CL是第L层的交叉特征矩阵,Sv表示的是项目v的相关实体集合。公式(8)为预测函数,目的是将用户的最终表示uL和项目的最终表示vL结合起来。知识图谱根据关系连接各实体并生成路径,用户能够通过路径去发现与实体具有关联性的潜在项目,从而获取更加准确的用户偏好。在表3中,汇总出了多领域知识图谱推荐系统基于路径的方法Hete-MF模型只是使用了项目之间的相似度,多方法推荐。不同的推荐方法都有各自的优缺点,当面对不同需求、不同上下文场景时应选择不同的推荐算法。不可能存在一个推荐算法在任何时候下都优于其他算法的情况。所以要充分运用不同推荐算法各自的优势,取长补短,相互融合形成一个强大的推荐框架,而且将多种推荐方法融合,可以有效的提高推荐效果。RippleNet模型、KGCN模型和KGAT模型都是典型的混合模型,它们将基于嵌入和基于路径的方法融合,充分利用了知识图谱中的实体信息和语义关系,实现更精确的推荐。但是多种方法结合也导致了计算量大,模型复杂,系统开销大,推荐速度慢等问题。如何在多方法融合的系统中,针对不同的情况系统可以快速做出推荐响应并尽量降低成本和开销,在未来推荐系统的发展中值得研究Luo等人[47]提出的Hete-CF模型是将用户之间的相似度、项目之间的相似度和用户项目之间的相似度都作为正则化来挖掘用户偏好。与上述模型思想相似的还有HeteRec[48]模型和HeteRec-p[49]模型。由Shi等人[50]提出的SemRec模型与上述的四类模型不同,SemRec模型根据知识图谱中的路径生成一个用户对项目评级的强度矩阵,评级强度矩阵就代表了用户的偏好,模型再根据相似用户的评分,预测推荐系统目标用户对项目的评分,根据评分进行排序,从高到低推荐给用户。公式(17)是用户之间相似度正则化目标函数该模型首先根据用户的交互历史训练出一个关系矩阵给路径中的各跳邻居分配权重,由于知识图谱是由三元组组成的,RippleNet模型根据三元组中的头实体、关系权重以及候选项得出尾实体的权重,计算出多跳邻居和候选项之间的相似度,路径中的每一层用户都会有一个用户表示,最后将每一层的用户表示结合生成用户的最终表示,反映出用户的偏好,计算得到用户的点击概率,根据点击概率给用户做推荐出于对安全性、可靠性等因素的考虑,大量消费者自然而然地流动到医美资源集聚的城市“求美”,“医美旅游”悄然兴起知识图谱是人工智能的重要研究领域,本质是构建和存储不同类型数据的关联性,用图网络来表示知识及其属性和关联,可在一定程度上表征复杂的知识结构和关联,尤其适宜中医领域的知识特点,如尹丹等[2]基于知识图谱,模拟了“方证对应”的诊疗过程。但目前知识图谱相关研究多基于网络爬虫技术批量格式化的爬取大量的医疗相关数据,并基于此数据构建知识图谱[3,4,5]。这类知识图谱普遍存在着数据一致性差,无效数据较多,以及数据缺失严重[6]等问题,生成的知识图谱冗余度[7]较大,对于医疗尤其是临床的实际意义和应用价值有限。中医药临床指南与共识推进了中医药标准化和规范化进程。中华中医药学会心血管病分会发布的《冠心病稳定型心绞痛中医诊疗指南》是基于大量具有独特疗效的中医诊治冠心病稳定型心绞痛临床诊疗经验制定的,能够规范中医诊疗过程和促进提升中医诊疗的整体水平[8],在冠心病稳定型心绞痛的诊疗中具有规范性和权威性。以此为模式实体是本体、实例和关系的整和。比如临床表现“乏力”是本体中的一个概念,“乏力”也是一个具体的临床表现个体,称为实例,其有对应的属性如“分值”和对应的“证候要素”—“气虚”,“乏力”以及本体“症状”和相关的属性,称为“实体”。本研究使用知识图谱常用的三元组数据模型来描述诊疗指南中的知识和知识之间的关系。三元组关系类似于“主谓宾”的关系,表征主语和宾语之间的关联特征。诊疗指南中的数据字段有“临床表现”、“证候要素”、“证候类型”、“治法”、“方剂”、“中成药”和“中药”等。他们之间的关联关系分别为:从“临床表现”提炼“证候要素”,由“证候要素”组成“证候类型”,“证候类型”对应相应的“治法”,依据“治法”选择“方剂”,依据“治法”选择“中成药”,“方剂”包含“中药”。基于上述抽取的本体之间的关系,可设计三元组结构表见表2构建中医冠心病诊疗的知识图谱,对于冠心病中医诊疗的标准化和规范化以及经验的传承具有重要意义。本研究基于知识图谱技术,以《冠心病稳定型心绞痛中医诊疗指南》为模式构建知识图谱,通过编程实现以临床表现的输入调用知识图谱,可视化展示冠心病稳定型心绞痛的中医规范化诊疗过程,以期为直观地展现中医诊疗过程提供了一种可参考的新的范式。1.1数据和知识来源本研究所用到的数据和知识来源于中本体是概念的集合和框架,类似于面相对象程序设计中的类,是知识图谱的架构,也是知识图谱结构化的基础逻辑,将本体整理成相应的结构表,有助于对知识图谱的理解。根据诊疗指南中的本体结构特征,本研究针对诊疗指南进行本体的提取,首先提取“临床表现”、“证候要素”、“证候类型”、“治法”、“方剂(方药)”和“中成药”等,其中“方剂”和“中成药”都可抽象为“治疗手段”,所以将“治疗手段”作为一级本体,而“方剂”和“中成药”作为二级本体。然后根据提取的本体,提取实例,分别为“胸闷痛”、“气虚”、“气滞血瘀”和“冠心2号方”[11]等,最后抽取本体之间的关系,即“临床表现”提炼“证候要素”、“证候要素”组成“证候类型”、“证候类型”对应“治法”等。据此本文设计本体的结构见表1华中医药学会心血管病分会发布的《冠心病稳定型心绞痛中医诊疗指南》[8]。1.2 软件工具本研究的知识图谱使用Neo4j (www.neo4j.com)社区版实现,Neo4j是一个开源的基于java的高性能的NoSQL的图数据库,不同于传图4为“证候类型”、“治法”、“中成药”和“方剂”的知识图谱示意图。其中橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体,深绿色节点代表“中成药”实体,粉色节点代表“方剂”实体。从“证候类型”实体指向“治法”实体的有向箭头代表二者之间的关联,即“证候类型”对应的治法为该“治法”。从“治法”实体指向8个“中成药”实体的有向箭头代表二者之间的关联,即该“治法”被选择后,推荐选择的中成药为8个“中成药”实体所对应的中成药。此外,从“治法”实体还有一个指向“方剂”实体的有向箭头,代表二者之间的关联为该“治法”被选择后,推荐选择的中药方剂为该“方剂”实体所对应的中药方剂。“气虚血瘀证”所对应的治法为“益气活血,补虚止痛”,该治法所对应的治疗手段有2种,第1种是中成药,第2种是中药方剂。该治法推荐选择的中成药有“通心络胶囊”、“通心舒胶囊”、“血栓心脉宁片”等8种,推荐的中药方剂为“八珍汤加味”。从诊疗指南可见,“八珍汤加味”的组成药味有“党参、白术、茯苓、甘草、当归、生地黄、赤芍、川芎、桃仁、红花、丹参”,根据《中华人民共和国药典》[12]和《中药学》[13]的药物功效分类和《方剂学》的内容,除了八珍汤的八味药组和使用具有气血双补的功效外,川芎、桃仁、红花和丹参为活血化瘀药具有活血化瘀的功效。王阶教授根据多年临床研究指出,补气强心为治疗冠心病的第一要义[14],选用八珍汤加味能够气血同补兼具活血通络,补气通络之法为王阶教授治疗冠心病的宝贵经验[15]。通过所构建的知识图谱,输入相应的证候类型,即可自动组合出对应的治法,推荐的中成药和中药方剂统数据库中使用的关系模型[9],它将结构化的数据存储在灵活的图网络中而不是表中,更适合表征具有复杂关联的数据及之间的关系,从而在各个行业中得到广泛应用。知识图谱构建和调用过程我们使用Python中的py2neo (https://github.com/py2neo-org/py2neo)来实现。Py2neo是一个Python库和工具包,用于从Python应用程序和命令行中调用或操作Neo4j。其中Node和Relationship这两个对象是py2neo的关键,它们都扩展了Subgraph类,提供了一套全面的图结构数据类型和操作支持,从而在如何调用和操作图数据方面提供了显著的灵活性。1.3 知识图谱概念知识图谱是使用图结构的数据模型或拓扑结构来集成和表示数据的知识库。知识图谱通常用于存储实体(对象、事件、情况或抽象概念)的相互关联的描述,同时还对所用术语背后的语义进行编码[10]。自语义网发展以来,知识图谱往往与关联的开放数据项目相关联,侧重于概念与实体之间的联系的存储和表示。利用知识图谱能够关联核心医学概念及医疗知识,从海量临床医案中对经验和知识进行提炼整理、录入标注和体系构建,以解决优质医疗资源短缺和医疗需求持续增加的矛盾。知识图谱的基本构建流程包括本体构建、实体配置、知识抽取和知识融合等。1.4 知识图谱设计1.4.1 流程设计本研究首先根据诊疗指南中的知识和信息,按照知识图谱构建的方法,从抽象的层面分别定义实体、关系和属性,然后将指南中本研究所需要的结构化数据、半结构化数据和非结构化数据,分别进行整理和提取,形成本研究所需要的数据(包含节点、属性与关系)。在此基础上,我们进行实体消歧、实体对齐等知识融合过程。随后本研究通过Python的py2neo库调用Neo4j,将知识数据导入Neo4j中构建知识图谱。然后通过Python编程将程序图5为“证候类型”、“治法”、“中成药”、“方剂”和“中药”的知识图谱示意图。其中橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体,粉色节点代表“方剂”实体,绿色节点代表“中药”实体。联结“证候类型”实体和“治法”实体之间的边表示“证候类型”对应该“治法”,联结“治法”实体和“方剂”实体之间的边表示该“治法”推荐选择该“方剂”,联结“方剂”实体和“中药”实体之间的边表示该“方剂”由该“中药”组成。如图5所示,“气虚血瘀证”所对应的治法为“益气活血,补虚止痛”,该治法所对应的治疗手段中的中药方剂推荐“八珍汤加味”。方剂“八珍汤加味”的组成中药有“党参”、“白术”、“茯苓”、“甘草”、“当归”“红花”“赤芍”等11种。通过所构建的知识图谱,输入相应的证候类型,即可自动组合出对应的治法,推荐中药方剂,以及显示中药方剂所用的中药药味而图2为“临床表现”与“证候要素”知识图谱的示意图。其中蓝色节点代表“临床表现”实体、紫色节点代表“证候要素”实体,从“临床表现”实体指向“证候要素”实体的有向箭头代表二者之间的关联,即“临床表现”中提炼出该“证候要素”,如“神疲”、“乏力”等临床表现,能够相应的提炼出证候要素“气虚”。通过所构建的知识图谱,可输入相应的临床表现,即可自动提炼组合出对应的证候要素且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。多任务学习法。将嵌入模块和推荐模块设计成了相关又分离的任务,将图3为“证候要素”、“证候类型”和“治法”的知识图谱示意图。其中紫色节点代表“证候要素”实体,橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体。从“证候要素”实体指向“证候类型”实体的有向箭头代表二者之间的关联,即“证候要素”组成该“证候类型”。从“证候类型”实体指向“治法”实体的有向箭头代表二者之间的关联,即“证候类型”对应的治法为该“治法”。“气虚”和“阴虚”这2个证候要素,共同组成“气阴两虚证”这一证候类型,而“气阴两虚证”对应的治法为“益气养阴,活血通络”。通过所构建的知识图谱,输入相应的证候要素列表,即可自动组合出对应的证候类型这些任务放在同一个框架中进行交替学习,使用py2neo将诊疗指南中提取整理好的结构化数据导入到Neo4j数据库中,并进而完成基于中医诊疗指南的冠心病知识图谱构建。构建的知识图谱可通过py2neo或用Cypher语句进行查询和调用。因所构建的知识图谱节点较多,并且节点之间的关联复杂,难以在一张图上做清晰的显示,而诊疗指南中,“气虚”证候要素组合为证候类型的组合可能性较多,为了便于展示尽可能多的组合方式和节点关联,以“气虚”这一个证候要素相关的知识图谱为例(包含临床表现、证候要素、证候类型、治法、中成药、方剂和中药等节点及之间的关联),对所构建的知识图谱的节点和关联进行阐述Wang等人[43]提出了MKR模型,Cao等人[44]提出了KTUP模型。典型的例子就是MRK模型。该模型是由KGE模块和推荐模块组成的,将知识图谱以三元组的形式输入KGE模块,通过KGE模块预测出尾实体。用户和项目的特征表示作为推荐模块的输入,通过推荐模块得到项目点击率的估计值。在KGE模块和推荐模块中间有一个交叉特征共享单元,两个模块可以通过该共享单元进行数据交换,这样就可以得到用户的最终表示uL,如公式(6)所示。项目的最终表示vL,如公式(7)所示。其中vL是由L个交叉压缩单元提取的特征,CL是第L层的交叉特征矩阵,Sv表示的是项目v的相关实体集合。公式(8)为预测函数,目的是将用户的最终表示uL和项目的最终表示vL结合起来。知识图谱根据关系连接各实体并生成路径,用户能够通过路径去发现与实体具有关联性的潜在项目,从而获取更加准确的用户偏好。在表3中,汇总出了多领域知识图谱推荐系统基于路径的方法Hete-MF模型只是使用了项目之间的相似度,多方法推荐。不同的推荐方法都有各自的优缺点,当面对不同需求、不同上下文场景时应选择不同的推荐算法。不可能存在一个推荐算法在任何时候下都优于其他算法的情况。所以要充分运用不同推荐算法各自的优势,取长补短,相互融合形成一个强大的推荐框架,而且将多种推荐方法融合,可以有效的提高推荐效果。RippleNet模型、KGCN模型和KGAT模型都是典型的混合模型,它们将基于嵌入和基于路径的方法融合,充分利用了知识图谱中的实体信息和语义关系,实现更精确的推荐。但是多种方法结合也导致了计算量大,模型复杂,系统开销大,推荐速度慢等问题。如何在多方法融合的系统中,针对不同的情况系统可以快速做出推荐响应并尽量降低成本和开销,在未来推荐系统的发展中值得研究Luo等人[47]提出的Hete-CF模型是将用户之间的相似度、项目之间的相似度和用户项目之间的相似度都作为正则化来挖掘用户偏好。与上述模型思想相似的还有HeteRec[48]模型和HeteRec-p[49]模型。由Shi等人[50]提出的SemRec模型与上述的四类模型不同,SemRec模型根据知识图谱中的路径生成一个用户对项目评级的强度矩阵,评级强度矩阵就代表了用户的偏好,模型再根据相似用户的评分,预测推荐系统目标用户对项目的评分,根据评分进行排序,从高到低推荐给用户。公式(17)是用户之间相似度正则化目标函数该模型首先根据用户的交互历史训练出一个关系矩阵给路径中的各跳邻居分配权重,由于知识图谱是由三元组组成的,RippleNet模型根据三元组中的头实体、关系权重以及候选项得出尾实体的权重,计算出多跳邻居和候选项之间的相似度,路径中的每一层用户都会有一个用户表示,最后将每一层的用户表示结合生成用户的最终表示,反映出用户的偏好,计算得到用户的点击概率,根据点击概率给用户做推荐出于对安全性、可靠性等因素的考虑,大量消费者自然而然地流动到医美资源集聚的城市“求美”,“医美旅游”悄然兴起知识图谱是人工智能的重要研究领域,本质是构建和存储不同类型数据的关联性,用图网络来表示知识及其属性和关联,可在一定程度上表征复杂的知识结构和关联,尤其适宜中医领域的知识特点,如尹丹等[2]基于知识图谱,模拟了“方证对应”的诊疗过程。但目前知识图谱相关研究多基于网络爬虫技术批量格式化的爬取大量的医疗相关数据,并基于此数据构建知识图谱[3,4,5]。这类知识图谱普遍存在着数据一致性差,无效数据较多,以及数据缺失严重[6]等问题,生成的知识图谱冗余度[7]较大,对于医疗尤其是临床的实际意义和应用价值有限。中医药临床指南与共识推进了中医药标准化和规范化进程。中华中医药学会心血管病分会发布的《冠心病稳定型心绞痛中医诊疗指南》是基于大量具有独特疗效的中医诊治冠心病稳定型心绞痛临床诊疗经验制定的,能够规范中医诊疗过程和促进提升中医诊疗的整体水平[8],在冠心病稳定型心绞痛的诊疗中具有规范性和权威性。以此为模式实体是本体、实例和关系的整和。比如临床表现“乏力”是本体中的一个概念,“乏力”也是一个具体的临床表现个体,称为实例,其有对应的属性如“分值”和对应的“证候要素”—“气虚”,“乏力”以及本体“症状”和相关的属性,称为“实体”。本研究使用知识图谱常用的三元组数据模型来描述诊疗指南中的知识和知识之间的关系。三元组关系类似于“主谓宾”的关系,表征主语和宾语之间的关联特征。诊疗指南中的数据字段有“临床表现”、“证候要素”、“证候类型”、“治法”、“方剂”、“中成药”和“中药”等。他们之间的关联关系分别为:从“临床表现”提炼“证候要素”,由“证候要素”组成“证候类型”,“证候类型”对应相应的“治法”,依据“治法”选择“方剂”,依据“治法”选择“中成药”,“方剂”包含“中药”。基于上述抽取的本体之间的关系,可设计三元组结构表见表2构建中医冠心病诊疗的知识图谱,对于冠心病中医诊疗的标准化和规范化以及经验的传承具有重要意义。本研究基于知识图谱技术,以《冠心病稳定型心绞痛中医诊疗指南》为模式构建知识图谱,通过编程实现以临床表现的输入调用知识图谱,可视化展示冠心病稳定型心绞痛的中医规范化诊疗过程,以期为直观地展现中医诊疗过程提供了一种可参考的新的范式。1.1数据和知识来源本研究所用到的数据和知识来源于中本体是概念的集合和框架,类似于面相对象程序设计中的类,是知识图谱的架构,也是知识图谱结构化的基础逻辑,将本体整理成相应的结构表,有助于对知识图谱的理解。根据诊疗指南中的本体结构特征,本研究针对诊疗指南进行本体的提取,首先提取“临床表现”、“证候要素”、“证候类型”、“治法”、“方剂(方药)”和“中成药”等,其中“方剂”和“中成药”都可抽象为“治疗手段”,所以将“治疗手段”作为一级本体,而“方剂”和“中成药”作为二级本体。然后根据提取的本体,提取实例,分别为“胸闷痛”、“气虚”、“气滞血瘀”和“冠心2号方”[11]等,最后抽取本体之间的关系,即“临床表现”提炼“证候要素”、“证候要素”组成“证候类型”、“证候类型”对应“治法”等。据此本文设计本体的结构见表1华中医药学会心血管病分会发布的《冠心病稳定型心绞痛中医诊疗指南》[8]。1.2 软件工具本研究的知识图谱使用Neo4j (www.neo4j.com)社区版实现,Neo4j是一个开源的基于java的高性能的NoSQL的图数据库,不同于传图4为“证候类型”、“治法”、“中成药”和“方剂”的知识图谱示意图。其中橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体,深绿色节点代表“中成药”实体,粉色节点代表“方剂”实体。从“证候类型”实体指向“治法”实体的有向箭头代表二者之间的关联,即“证候类型”对应的治法为该“治法”。从“治法”实体指向8个“中成药”实体的有向箭头代表二者之间的关联,即该“治法”被选择后,推荐选择的中成药为8个“中成药”实体所对应的中成药。此外,从“治法”实体还有一个指向“方剂”实体的有向箭头,代表二者之间的关联为该“治法”被选择后,推荐选择的中药方剂为该“方剂”实体所对应的中药方剂。“气虚血瘀证”所对应的治法为“益气活血,补虚止痛”,该治法所对应的治疗手段有2种,第1种是中成药,第2种是中药方剂。该治法推荐选择的中成药有“通心络胶囊”、“通心舒胶囊”、“血栓心脉宁片”等8种,推荐的中药方剂为“八珍汤加味”。从诊疗指南可见,“八珍汤加味”的组成药味有“党参、白术、茯苓、甘草、当归、生地黄、赤芍、川芎、桃仁、红花、丹参”,根据《中华人民共和国药典》[12]和《中药学》[13]的药物功效分类和《方剂学》的内容,除了八珍汤的八味药组和使用具有气血双补的功效外,川芎、桃仁、红花和丹参为活血化瘀药具有活血化瘀的功效。王阶教授根据多年临床研究指出,补气强心为治疗冠心病的第一要义[14],冠心病因其发病率和危害已经成为全球重大公共卫生问题[19],给公共医疗带来很大负担[20]。临床指南作为综合当前最佳研究证据和指导临床实践的文件,是医疗水平稳定的重要保证。《冠心病稳定型心绞痛中医诊疗指南》是由中华中医药学会心血管病分会组织相关专家编撰的。编撰过程参照国际最新的临床指南的制订方法,并在相关法律法规和技术文件指导的框架下,通过辨证论治的数据和关系突出体现了传统中医辨证论治的思想。编撰过程深度结合循证医学原理,在古今文献的回顾分析、临床流行病学调查、中成药系统综述、名老中医经验总结、专家咨询等系统研究工作的基础上,对冠心病稳定型心绞痛的基本证候特点、辨证用药规律等进行了系统地梳理、归纳和总结。《冠心病稳定型心绞痛中医诊疗指南》为中医、中西医结合临床医师规范化开展冠心病的防治工作提供权威指导。选用八珍汤加味能够气血同补兼具活血通络,补气通络之法为王阶教授治疗冠心病的宝贵经验[15]。通过所构建的知识图谱,输入相应的证候类型,即可自动组合出对应的治法,推荐的中成药和中药方剂统数据库中使用的关系模型[9],它将结构化的数据存储在灵活的图网络中而不是表中,更适合表征具有复杂关联的数据及之间的关系,从而在各个行业中得到广泛应用。知识图谱构建和调用过程我们使用Python中的py2neo (https://github.com/py2neo-org/py2neo)来实现。Py2neo是一个Python库和工具包,用于从Python应用程序和命令行中调用或操作Neo4j。其中Node和Relationship这两个对象是py2neo的关键,它们都扩展了Subgraph类,提供了一套全面的图结构数据类型和操作支持,从而在如何调用和操作图数据方面提供了显著的灵活性。1.3 知识图谱概念知识图谱是使用图结构的数据模型或拓扑结构来集成和表示数据的知识库。知识图谱通常用于存储实体(对象、事件、情况或抽象概念)的相互关联的描述,铁路运输设备状态是铁路安全运输的根本,良好的设备状态既是运输生产的物质基础,又是运输安全的重要保证[1]。随着铁路运营里程的积累和铁路设备的更新迭代,积累了大量的铁路运输设备故障数据。这些故障数据记录了故障发生的详细信息,包括故障的基础信息和对故障的人工分析数据,蕴含了铁路运输设备的重要价值信息。科学分析设备故障数据是将故障从消极转变为积极的有效途径,但由于这些故障数据存在存储分散、数据格式不同、存储形式各异的情况,给数据分析带来了困难[2]。知识图谱能够有效地将多源异构数据转化为基于深层语义的知识服务,基于知识图谱技术实现设备故障的深度挖掘和智能应用,是分析铁路运输设备故障数据的有效途径同时还对所用术语背后的语义进行编码[10]。自语义网发展以来,知识图谱往往与关联的开放数据项目相关联,侧重于概念与实体之间的联系的存储和表示。利用知识图谱能够关联核心医学概念及医疗知识,从海量临床医案中对经验和知识进行提炼整理、录入标注和体系构建,以解决优质医疗资源短缺和医疗需求持续增加的矛盾。知识图谱的基本构建流程包括本体构建、实体配置、知识抽取和知识融合等。1.4 知识图谱设计1.4.1 流程设计本研究首先根据诊疗指南中的知识和信息,按照知识图谱构建的方法,从抽象的层面分别定义实体、关系和属性,然后将指南中本研究所需要的结构化数据、半结构化数本研究结合目前中医诊疗经验传承中存在的问题,针对冠心病稳定型心绞痛这个单一病种,提出了一种基于凝结了中医行业专家经验和循证证据所形成的诊疗指南,来构建知识图谱的方法。与一些相关的研究不同的是,该方法没有选择使用基于网络爬虫的大数据来构建知识图谱,而是选择使用规范化、规则化程度较高的中医诊疗指南中的医学知识和术语构建知识图谱并可视化的展示和描述中医诊治冠心病稳定型心绞痛的过程。而知识图谱通过描述实体及其关系来表示语义,知识图谱可以使用本体作为模式层,通过这样的设计,基于知识图谱设计的模型将不仅支持显示知识相关的查询,同时也支持与隐式知识相关的逻辑推理。该方法能够从患者的输入症状出发,经过知识图谱的查询和计算,得到患者可能的证候类型以及应该选择的治法和方剂。这是一种构建中医临床辅助决策系统的有益尝试据和非结构化数据,分别进行整理和提取,形成本研究所需要的数据(包含节点、属性与关系)。在此基础上,我们进行实体消歧、实体对齐等知识融合过程。随后本研究通过Python的py2neo库调用Neo4j,将知识数据导入Neo4j中构建知识图谱。然后通过Python编程将程序构建的基于中医诊疗指南的知识图谱,支持基于图数据库的查询功能。我们以诊疗指南中第一个证候对应的第一个临床表现(胸固定性痛)为例来说明。如查询“临床表现”为“胸固定性痛”,则展示如图6所示的知识图谱。蓝色节点为查询的症状“胸固定性痛”,其对应的“证候要素”为“血瘀”,“血瘀”能够组成“气虚血瘀证”、“气滞血瘀证”、“心血瘀阻证”“痰瘀互结证”4个证型。4个证型又分别对应治法和方剂以及中成药等。从而实现基于中医诊疗指南和专家经验的知识图谱可视化展示过程,为直观地展现中医诊疗过程提供一种新的方式。上述知识图谱的几个模块,即为依据中医诊疗指南进行辨证论治的过程。通过症状(临床表现)的组合文本,提炼出相应的证候要素,在证候要素的基础上组合出相应的证候类型,根据相应的证候类型即可推断相应的治法,确立治法后,即可推荐相应的中成药和中药方剂,并进一步可视化展示中药方剂所用的中药列表。这个过程即模拟了中医辨证论治冠心病稳定型心绞痛的过程,是诊疗指南的可视化和网络化的展示。下面我们将使用知识图谱的查询检索功能进行展示。图5为“证候类型”、“治法”、“中成药”、“方剂”和“中药”的知识图谱示意图。其中橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体,粉色节点代表“方剂”实体,绿色节点代表“中药”实体。联结“证候类型”实体和“治法”实体之间的边表示“证候类型”对应该“治法”,联结“治法”实体和“方剂”实体之间的边表示该“治法”推荐选择该“方剂”,联结“方剂”实体和“中药”实体之间的边表示该“方剂”由该“中药”组成。如图5所示,“气虚血瘀证”所对应的治法为“益气活血,补虚止痛”,该治法所对应的治疗手段中的中药方剂推荐“八珍汤加味”。方剂“八珍汤加味”的组成中药有“党参”、“白术”、“茯苓”、“甘草”、“当归”“红花”“赤芍”等11种。通过所构建的知识图谱,输入相应的证候类型,即可自动组合出对应的治法,推荐中药方剂,以及显示中药方剂所用的中药药味而图2为“临床表现”与“证候要素”知识图谱的示意图。其中蓝色节点代表“临床表现”实体、紫色节点代表“证候要素”实体,从“临床表现”实体指向“证候要素”实体的有向箭头代表二者之间的关联,即“临床表现”中提炼出该“证候要素”,如“神疲”、“乏力”等临床表现,能够相应的提炼出证候要素“气虚”。通过所构建的知识图谱,可输入相应的临床表现,即可自动提炼组合出对应的证候要素且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。多任务学习法。将嵌入模块和推荐模块设计成了相关又分离的任务,将图3为“证候要素”、“证候类型”和“治法”的知识图谱示意图。其中紫色节点代表“证候要素”实体,橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体。从“证候要素”实体指向“证候类型”实体的有向箭头代表二者之间的关联,即“证候要素”组成该“证候类型”。从“证候类型”实体指向“治法”实体的有向箭头代表二者之间的关联,即“证候类型”对应的治法为该“治法”。“气虚”和“阴虚”这2个证候要素,共同组成“气阴两虚证”这一证候类型,而“气阴两虚证”对应的治法为“益气养阴,活血通络”。通过所构建的知识图谱,输入相应的证候要素列表,即可自动组合出对应的证候类型这些任务放在同一个框架中进行交替学习,使用py2neo将诊疗指南中提取整理好的结构化数据导入到Neo4j数据库中,并进而完成基于中医诊疗指南的冠心病知识图谱构建。构建的知识图谱可通过py2neo或用Cypher语句进行查询和调用。因所构建的知识图谱节点较多,并且节点之间的关联复杂,难以在一张图上做清晰的显示,而诊疗指南中,“气虚”证候要素组合为证候类型的组合可能性较多,为了便于展示尽可能多的组合方式和节点关联,以“气虚”这一个证候要素相关的知识图谱为例(包含临床表现、证候要素、证候类型、治法、中成药、方剂和中药等节点及之间的关联),对所构建的知识图谱的节点和关联进行阐述Wang等人[43]提出了MKR模型,Cao等人[44]提出了KTUP模型。典型的例子就是MRK模型。该模型是由KGE模块和推荐模块组成的,将知识图谱以三元组的形式输入KGE模块,通过KGE模块预测出尾实体。用户和项目的特征表示作为推荐模块的输入,通过推荐模块得到项目点击率的估计值。在KGE模块和推荐模块中间有一个交叉特征共享单元,两个模块可以通过该共享单元进行数据交换,这样就可以得到用户的最终表示uL,如公式(6)所示。项目的最终表示vL,如公式(7)所示。其中vL是由L个交叉压缩单元提取的特征,CL是第L层的交叉特征矩阵,Sv表示的是项目v的相关实体集合。公式(8)为预测函数,目的是将用户的最终表示uL和项目的最终表示vL结合起来。知识图谱根据关系连接各实体并生成路径,用户能够通过路径去发现与实体具有关联性的潜在项目,从而获取更加准确的用户偏好。在表3中,汇总出了多领域知识图谱推荐系统基于路径的方法Hete-MF模型只是使用了项目之间的相似度,多方法推荐。不同的推荐方法都有各自的优缺点,当面对不同需求、不同上下文场景时应选择不同的推荐算法。不可能存在一个推荐算法在任何时候下都优于其他算法的情况。所以要充分运用不同推荐算法各自的优势,取长补短,相互融合形成一个强大的推荐框架,而且将多种推荐方法融合,可以有效的提高推荐效果。RippleNet模型、KGCN模型和KGAT模型都是典型的混合模型,它们将基于嵌入和基于路径的方法融合,充分利用了知识图谱中的实体信息和语义关系,实现更精确的推荐。但是多种方法结合也导致了计算量大,模型复杂,系统开销大,推荐速度慢等问题。如何在多方法融合的系统中,针对不同的情况系统可以快速做出推荐响应并尽量降低成本和开销,在未来推荐系统的发展中值得研究Luo等人[47]提出的Hete-CF模型是将用户之间的相似度、项目之间的相似度和用户项目之间的相似度都作为正则化来挖掘用户偏好。与上述模型思想相似的还有HeteRec[48]模型和HeteRec-p[49]模型。由Shi等人[50]提出的SemRec模型与上述的四类模型不同,SemRec模型根据知识图谱中的路径生成一个用户对项目评级的强度矩阵,评级强度矩阵就代表了用户的偏好,模型再根据相似用户的评分,预测推荐系统目标用户对项目的评分,根据评分进行排序,从高到低推荐给用户。公式(17)是用户之间相似度正则化目标函数该模型首先根据用户的交互历史训练出一个关系矩阵给路径中的各跳邻居分配权重,由于知识图谱是由三元组组成的,RippleNet模型根据三元组中的头实体、关系权重以及候选项得出尾实体的权重,计算出多跳邻居和候选项之间的相似度,路径中的每一层用户都会有一个用户表示,最后将每一层的用户表示结合生成用户的最终表示,反映出用户的偏好,计算得到用户的点击概率,根据点击概率给用户做推荐出于对安全性、可靠性等因素的考虑,大量消费者自然而然地流动到医美资源集聚的城市“求美”,“医美旅游”悄然兴起知识图谱是人工智能的重要研究领域,本质是构建和存储不同类型数据的关联性,用图网络来表示知识及其属性和关联,可在一定程度上表征复杂的知识结构和关联,尤其适宜中医领域的知识特点,如尹丹等[2]基于知识图谱,模拟了“方证对应”的诊疗过程。但目前知识图谱相关研究多基于网络爬虫技术批量格式化的爬取大量的医疗相关数据,并基于此数据构建知识图谱[3,4,5]。这类知识图谱普遍存在着数据一致性差,无效数据较多,以及数据缺失严重[6]等问题,生成的知识图谱冗余度[7]较大,对于医疗尤其是临床的实际意义和应用价值有限。中医药临床指南与共识推进了中医药标准化和规范化进程。中华中医药学会心血管病分会发布的《冠心病稳定型心绞痛中医诊疗指南》是基于大量具有独特疗效的中医诊治冠心病稳定型心绞痛临床诊疗经验制定的,能够规范中医诊疗过程和促进提升中医诊疗的整体水平[8],在冠心病稳定型心绞痛的诊疗中具有规范性和权威性。以此为模式实体是本体、实例和关系的整和。比如临床表现“乏力”是本体中的一个概念,“乏力”也是一个具体的临床表现个体,称为实例,其有对应的属性如“分值”和对应的“证候要素”—“气虚”,“乏力”以及本体“症状”和相关的属性,称为“实体”。本研究使用知识图谱常用的三元组数据模型来描述诊疗指南中的知识和知识之间的关系。三元组关系类似于“主谓宾”的关系,表征主语和宾语之间的关联特征。诊疗指南中的数据字段有“临床表现”、“证候要素”、“证候类型”、“治法”、“方剂”、“中成药”和“中药”等。他们之间的关联关系分别为:从“临床表现”提炼“证候要素”,由“证候要素”组成“证候类型”,“证候类型”对应相应的“治法”,依据“治法”选择“方剂”,依据“治法”选择“中成药”,“方剂”包含“中药”。基于上述抽取的本体之间的关系,可设计三元组结构表见表2构建中医冠心病诊疗的知识图谱,对于冠心病中医诊疗的标准化和规范化以及经验的传承具有重要意义。本研究基于知识图谱技术,以《冠心病稳定型心绞痛中医诊疗指南》为模式构建知识图谱,通过编程实现以临床表现的输入调用知识图谱,可视化展示冠心病稳定型心绞痛的中医规范化诊疗过程,以期为直观地展现中医诊疗过程提供了一种可参考的新的范式。1.1数据和知识来源本研究所用到的数据和知识来源于中本体是概念的集合和框架,类似于面相对象程序设计中的类,是知识图谱的架构,也是知识图谱结构化的基础逻辑,将本体整理成相应的结构表,有助于对知识图谱的理解。根据诊疗指南中的本体结构特征,本研究针对诊疗指南进行本体的提取,首先提取“临床表现”、“证候要素”、“证候类型”、“治法”、“方剂(方药)”和“中成药”等,其中“方剂”和“中成药”都可抽象为“治疗手段”,所以将“治疗手段”作为一级本体,而“方剂”和“中成药”作为二级本体。然后根据提取的本体,提取实例,分别为“胸闷痛”、“气虚”、“气滞血瘀”和“冠心2号方”[11]等,最后抽取本体之间的关系,即“临床表现”提炼“证候要素”、“证候要素”组成“证候类型”、“证候类型”对应“治法”等。据此本文设计本体的结构见表1华中医药学会心血管病分会发布的《冠心病稳定型心绞痛中医诊疗指南》[8]。1.2 软件工具本研究的知识图谱使用Neo4j (www.neo4j.com)社区版实现,Neo4j是一个开源的基于java的高性能的NoSQL的图数据库,不同于传图4为“证候类型”、“治法”、“中成药”和“方剂”的知识图谱示意图。其中橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体,深绿色节点代表“中成药”实体,粉色节点代表“方剂”实体。从“证候类型”实体指向“治法”实体的有向箭头代表二者之间的关联,即“证候类型”对应的治法为该“治法”。从“治法”实体指向8个“中成药”实体的有向箭头代表二者之间的关联,即该“治法”被选择后,推荐选择的中成药为8个“中成药”实体所对应的中成药。此外,从“治法”实体还有一个指向“方剂”实体的有向箭头,代表二者之间的关联为该“治法”被选择后,推荐选择的中药方剂为该“方剂”实体所对应的中药方剂。“气虚血瘀证”所对应的治法为“益气活血,补虚止痛”,该治法所对应的治疗手段有2种,第1种是中成药,第2种是中药方剂。该治法推荐选择的中成药有“通心络胶囊”、“通心舒胶囊”、“血栓心脉宁片”等8种,推荐的中药方剂为“八珍汤加味”。从诊疗指南可见,“八珍汤加味”的组成药味有“党参、白术、茯苓、甘草、当归、生地黄、赤芍、川芎、桃仁、红花、丹参”,根据《中华人民共和国药典》[12]和《中药学》[13]的药物功效分类和《方剂学》的内容,除了八珍汤的八味药组和使用具有气血双补的功效外,川芎、桃仁、红花和丹参为活血化瘀药具有活血化瘀的功效。王阶教授根据多年临床研究指出,补气强心为治疗冠心病的第一要义[14],选用八珍汤加味能够气血同补兼具活血通络,补气通络之法为王阶教授治疗冠心病的宝贵经验[15]。通过所构建的知识图谱,输入相应的证候类型,即可自动组合出对应的治法,推荐的中成药和中药方剂统数据库中使用的关系模型[9],它将结构化的数据存储在灵活的图网络中而不是表中,更适合表征具有复杂关联的数据及之间的关系,从而在各个行业中得到广泛应用。知识图谱构建和调用过程我们使用Python中的py2neo (https://github.com/py2neo-org/py2neo)来实现。Py2neo是一个Python库和工具包,用于从Python应用程序和命令行中调用或操作Neo4j。其中Node和Relationship这两个对象是py2neo的关键,它们都扩展了Subgraph类,提供了一套全面的图结构数据类型和操作支持,从而在如何调用和操作图数据方面提供了显著的灵活性。1.3 知识图谱概念知识图谱是使用图结构的数据模型或拓扑结构来集成和表示数据的知识库。知识图谱通常用于存储实体(对象、事件、情况或抽象概念)的相互关联的描述,同时还对所用术语背后的语义进行编码[10]。自语义网发展以来,知识图谱往往与关联的开放数据项目相关联,侧重于概念与实体之间的联系的存储和表示。利用知识图谱能够关联核心医学概念及医疗知识,从海量临床医案中对经验和知识进行提炼整理、录入标注和体系构建,以解决优质医疗资源短缺和医疗需求持续增加的矛盾。知识图谱的基本构建流程包括本体构建、实体配置、知识抽取和知识融合等。1.4 知识图谱设计1.4.1 流程设计本研究首先根据诊疗指南中的知识和信息,按照知识图谱构建的方法,从抽象的层面分别定义实体、关系和属性,然后将指南中本研究所需要的结构化数据、半结构化数据和非结构化数据,分别进行整理和提取,形成本研究所需要的数据(包含节点、属性与关系)。在此基础上,我们进行实体消歧、实体对齐等知识融合过程。随后本研究通过Python的py2neo库调用Neo4j,将知识数据导入Neo4j中构建知识图谱。然后通过Python编程将程序图5为“证候类型”、“治法”、“中成药”、“方剂”和“中药”的知识图谱示意图。其中橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体,粉色节点代表“方剂”实体,绿色节点代表“中药”实体。联结“证候类型”实体和“治法”实体之间的边表示“证候类型”对应该“治法”,联结“治法”实体和“方剂”实体之间的边表示该“治法”推荐选择该“方剂”,联结“方剂”实体和“中药”实体之间的边表示该“方剂”由该“中药”组成。如图5所示,“气虚血瘀证”所对应的治法为“益气活血,补虚止痛”,该治法所对应的治疗手段中的中药方剂推荐“八珍汤加味”。方剂“八珍汤加味”的组成中药有“党参”、“白术”、“茯苓”、“甘草”、“当归”“红花”“赤芍”等11种。通过所构建的知识图谱,输入相应的证候类型,即可自动组合出对应的治法,推荐中药方剂,以及显示中药方剂所用的中药药味而图2为“临床表现”与“证候要素”知识图谱的示意图。其中蓝色节点代表“临床表现”实体、紫色节点代表“证候要素”实体,从“临床表现”实体指向“证候要素”实体的有向箭头代表二者之间的关联,即“临床表现”中提炼出该“证候要素”,如“神疲”、“乏力”等临床表现,能够相应的提炼出证候要素“气虚”。通过所构建的知识图谱,可输入相应的临床表现,即可自动提炼组合出对应的证候要素且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。多任务学习法。将嵌入模块和推荐模块设计成了相关又分离的任务,将图3为“证候要素”、“证候类型”和“治法”的知识图谱示意图。其中紫色节点代表“证候要素”实体,橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体。从“证候要素”实体指向“证候类型”实体的有向箭头代表二者之间的关联,即“证候要素”组成该“证候类型”。从“证候类型”实体指向“治法”实体的有向箭头代表二者之间的关联,即“证候类型”对应的治法为该“治法”。“气虚”和“阴虚”这2个证候要素,共同组成“气阴两虚证”这一证候类型,而“气阴两虚证”对应的治法为“益气养阴,活血通络”。通过所构建的知识图谱,输入相应的证候要素列表,即可自动组合出对应的证候类型这些任务放在同一个框架中进行交替学习,使用py2neo将诊疗指南中提取整理好的结构化数据导入到Neo4j数据库中,并进而完成基于中医诊疗指南的冠心病知识图谱构建。构建的知识图谱可通过py2neo或用Cypher语句进行查询和调用。因所构建的知识图谱节点较多,并且节点之间的关联复杂,难以在一张图上做清晰的显示,而诊疗指南中,“气虚”证候要素组合为证候类型的组合可能性较多,为了便于展示尽可能多的组合方式和节点关联,以“气虚”这一个证候要素相关的知识图谱为例(包含临床表现、证候要素、证候类型、治法、中成药、方剂和中药等节点及之间的关联),对所构建的知识图谱的节点和关联进行阐述Wang等人[43]提出了MKR模型,Cao等人[44]提出了KTUP模型。典型的例子就是MRK模型。该模型是由KGE模块和推荐模块组成的,将知识图谱以三元组的形式输入KGE模块,通过KGE模块预测出尾实体。用户和项目的特征表示作为推荐模块的输入,通过推荐模块得到项目点击率的估计值。在KGE模块和推荐模块中间有一个交叉特征共享单元,两个模块可以通过该共享单元进行数据交换,这样就可以得到用户的最终表示uL,如公式(6)所示。项目的最终表示vL,如公式(7)所示。其中vL是由L个交叉压缩单元提取的特征,CL是第L层的交叉特征矩阵,Sv表示的是项目v的相关实体集合。公式(8)为预测函数,目的是将用户的最终表示uL和项目的最终表示vL结合起来。知识图谱根据关系连接各实体并生成路径,用户能够通过路径去发现与实体具有关联性的潜在项目,从而获取更加准确的用户偏好。在表3中,汇总出了多领域知识图谱推荐系统基于路径的方法Hete-MF模型只是使用了项目之间的相似度,多方法推荐。不同的推荐方法都有各自的优缺点,当面对不同需求、不同上下文场景时应选择不同的推荐算法。不可能存在一个推荐算法在任何时候下都优于其他算法的情况。所以要充分运用不同推荐算法各自的优势,取长补短,相互融合形成一个强大的推荐框架,而且将多种推荐方法融合,可以有效的提高推荐效果。RippleNet模型、KGCN模型和KGAT模型都是典型的混合模型,它们将基于嵌入和基于路径的方法融合,充分利用了知识图谱中的实体信息和语义关系,实现更精确的推荐。但是多种方法结合也导致了计算量大,模型复杂,系统开销大,推荐速度慢等问题。如何在多方法融合的系统中,针对不同的情况系统可以快速做出推荐响应并尽量降低成本和开销,在未来推荐系统的发展中值得研究Luo等人[47]提出的Hete-CF模型是将用户之间的相似度、项目之间的相似度和用户项目之间的相似度都作为正则化来挖掘用户偏好。与上述模型思想相似的还有HeteRec[48]模型和HeteRec-p[49]模型。由Shi等人[50]提出的SemRec模型与上述的四类模型不同,SemRec模型根据知识图谱中的路径生成一个用户对项目评级的强度矩阵,评级强度矩阵就代表了用户的偏好,模型再根据相似用户的评分,预测推荐系统目标用户对项目的评分,根据评分进行排序,从高到低推荐给用户。公式(17)是用户之间相似度正则化目标函数该模型首先根据用户的交互历史训练出一个关系矩阵给路径中的各跳邻居分配权重,由于知识图谱是由三元组组成的,RippleNet模型根据三元组中的头实体、关系权重以及候选项得出尾实体的权重,计算出多跳邻居和候选项之间的相似度,路径中的每一层用户都会有一个用户表示,最后将每一层的用户表示结合生成用户的最终表示,反映出用户的偏好,计算得到用户的点击概率,根据点击概率给用户做推荐出于对安全性、可靠性等因素的考虑,大量消费者自然而然地流动到医美资源集聚的城市“求美”,“医美旅游”悄然兴起知识图谱是人工智能的重要研究领域,本质是构建和存储不同类型数据的关联性,用图网络来表示知识及其属性和关联,可在一定程度上表征复杂的知识结构和关联,尤其适宜中医领域的知识特点,如尹丹等[2]基于知识图谱,模拟了“方证对应”的诊疗过程。但目前知识图谱相关研究多基于网络爬虫技术批量格式化的爬取大量的医疗相关数据,并基于此数据构建知识图谱[3,4,5]。这类知识图谱普遍存在着数据一致性差,无效数据较多,以及数据缺失严重[6]等问题,生成的知识图谱冗余度[7]较大,对于医疗尤其是临床的实际意义和应用价值有限。中医药临床指南与共识推进了中医药标准化和规范化进程。中华中医药学会心血管病分会发布的《冠心病稳定型心绞痛中医诊疗指南》是基于大量具有独特疗效的中医诊治冠心病稳定型心绞痛临床诊疗经验制定的,能够规范中医诊疗过程和促进提升中医诊疗的整体水平[8],在冠心病稳定型心绞痛的诊疗中具有规范性和权威性。以此为模式实体是本体、实例和关系的整和。比如临床表现“乏力”是本体中的一个概念,“乏力”也是一个具体的临床表现个体,称为实例,其有对应的属性如“分值”和对应的“证候要素”—“气虚”,“乏力”以及本体“症状”和相关的属性,称为“实体”。本研究使用知识图谱常用的三元组数据模型来描述诊疗指南中的知识和知识之间的关系。三元组关系类似于“主谓宾”的关系,表征主语和宾语之间的关联特征。诊疗指南中的数据字段有“临床表现”、“证候要素”、“证候类型”、“治法”、“方剂”、“中成药”和“中药”等。他们之间的关联关系分别为:从“临床表现”提炼“证候要素”,由“证候要素”组成“证候类型”,“证候类型”对应相应的“治法”,依据“治法”选择“方剂”,依据“治法”选择“中成药”,“方剂”包含“中药”。基于上述抽取的本体之间的关系,可设计三元组结构表见表2构建中医冠心病诊疗的知识图谱,对于冠心病中医诊疗的标准化和规范化以及经验的传承具有重要意义。本研究基于知识图谱技术,以《冠心病稳定型心绞痛中医诊疗指南》为模式构建知识图谱,通过编程实现以临床表现的输入调用知识图谱,可视化展示冠心病稳定型心绞痛的中医规范化诊疗过程,以期为直观地展现中医诊疗过程提供了一种可参考的新的范式。1.1数据和知识来源本研究所用到的数据和知识来源于中本体是概念的集合和框架,类似于面相对象程序设计中的类,是知识图谱的架构,也是知识图谱结构化的基础逻辑,将本体整理成相应的结构表,有助于对知识图谱的理解。根据诊疗指南中的本体结构特征,本研究针对诊疗指南进行本体的提取,首先提取“临床表现”、“证候要素”、“证候类型”、“治法”、“方剂(方药)”和“中成药”等,其中“方剂”和“中成药”都可抽象为“治疗手段”,所以将“治疗手段”作为一级本体,而“方剂”和“中成药”作为二级本体。然后根据提取的本体,提取实例,分别为“胸闷痛”、“气虚”、“气滞血瘀”和“冠心2号方”[11]等,最后抽取本体之间的关系,即“临床表现”提炼“证候要素”、“证候要素”组成“证候类型”、“证候类型”对应“治法”等。据此本文设计本体的结构见表1华中医药学会心血管病分会发布的《冠心病稳定型心绞痛中医诊疗指南》[8]。1.2 软件工具本研究的知识图谱使用Neo4j (www.neo4j.com)社区版实现,Neo4j是一个开源的基于java的高性能的NoSQL的图数据库,不同于传图4为“证候类型”、“治法”、“中成药”和“方剂”的知识图谱示意图。其中橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体,深绿色节点代表“中成药”实体,粉色节点代表“方剂”实体。从“证候类型”实体指向“治法”实体的有向箭头代表二者之间的关联,即“证候类型”对应的治法为该“治法”。从“治法”实体指向8个“中成药”实体的有向箭头代表二者之间的关联,即该“治法”被选择后,推荐选择的中成药为8个“中成药”实体所对应的中成药。此外,从“治法”实体还有一个指向“方剂”实体的有向箭头,代表二者之间的关联为该“治法”被选择后,推荐选择的中药方剂为该“方剂”实体所对应的中药方剂。“气虚血瘀证”所对应的治法为“益气活血,补虚止痛”,该治法所对应的治疗手段有2种,第1种是中成药,第2种是中药方剂。该治法推荐选择的中成药有“通心络胶囊”、“通心舒胶囊”、“血栓心脉宁片”等8种,推荐的中药方剂为“八珍汤加味”。从诊疗指南可见,“八珍汤加味”的组成药味有“党参、白术、茯苓、甘草、当归、生地黄、赤芍、川芎、桃仁、红花、丹参”,根据《中华人民共和国药典》[12]和《中药学》[13]的药物功效分类和《方剂学》的内容,除了八珍汤的八味药组和使用具有气血双补的功效外,川芎、桃仁、红花和丹参为活血化瘀药具有活血化瘀的功效。王阶教授根据多年临床研究指出,补气强心为治疗冠心病的第一要义[14],冠心病因其发病率和危害已经成为全球重大公共卫生问题[19],给公共医疗带来很大负担[20]。临床指南作为综合当前最佳研究证据和指导临床实践的文件,是医疗水平稳定的重要保证。《冠心病稳定型心绞痛中医诊疗指南》是由中华中医药学会心血管病分会组织相关专家编撰的。编撰过程参照国际最新的临床指南的制订方法,并在相关法律法规和技术文件指导的框架下,通过辨证论治的数据和关系突出体现了传统中医辨证论治的思想。编撰过程深度结合循证医学原理,在古今文献的回顾分析、临床流行病学调查、中成药系统综述、名老中医经验总结、专家咨询等系统研究工作的基础上,对冠心病稳定型心绞痛的基本证候特点、辨证用药规律等进行了系统地梳理、归纳和总结。《冠心病稳定型心绞痛中医诊疗指南》为中医、中西医结合临床医师规范化开展冠心病的防治工作提供权威指导。选用八珍汤加味能够气血同补兼具活血通络,补气通络之法为王阶教授治疗冠心病的宝贵经验[15]。通过所构建的知识图谱,输入相应的证候类型,即可自动组合出对应的治法,推荐的中成药和中药方剂统数据库中使用的关系模型[9],它将结构化的数据存储在灵活的图网络中而不是表中,更适合表征具有复杂关联的数据及之间的关系,从而在各个行业中得到广泛应用。知识图谱构建和调用过程我们使用Python中的py2neo (https://github.com/py2neo-org/py2neo)来实现。Py2neo是一个Python库和工具包,用于从Python应用程序和命令行中调用或操作Neo4j。其中Node和Relationship这两个对象是py2neo的关键,它们都扩展了Subgraph类,提供了一套全面的图结构数据类型和操作支持,从而在如何调用和操作图数据方面提供了显著的灵活性。1.3 知识图谱概念知识图谱是使用图结构的数据模型或拓扑结构来集成和表示数据的知识库。知识图谱通常用于存储实体(对象、事件、情况或抽象概念)的相互关联的描述,同时还对所用术语背后的语义进行编码[10]。自语义网发展以来,知识图谱往往与关联的开放数据项目相关联,侧重于概念与实体之间的联系的存储和表示。利用知识图谱能够关联核心医学概念及医疗知识,从海量临床医案中对经验和知识进行提炼整理、录入标注和体系构建,以解决优质医疗资源短缺和医疗需求持续增加的矛盾。知识图谱的基本构建流程包括本体构建、实体配置、知识抽取和知识融合等。1.4 知识图谱设计1.4.1 流程设计本研究首先根据诊疗指南中的知识和信息,按照知识图谱构建的方法,从抽象的层面分别定义实体、关系和属性,然后将指南中本研究所需要的结构化数据、半结构化数本研究结合目前中医诊疗经验传承中存在的问题,针对冠心病稳定型心绞痛这个单一病种,提出了一种基于凝结了中医行业专家经验和循证证据所形成的诊疗指南,来构建知识图谱的方法。与一些相关的研究不同的是,该方法没有选择使用基于网络爬虫的大数据来构建知识图谱,而是选择使用规范化、规则化程度较高的中医诊疗指南中的医学知识和术语构建知识图谱并可视化的展示和描述中医诊治冠心病稳定型心绞痛的过程。而知识图谱通过描述实体及其关系来表示语义,知识图谱可以使用本体作为模式层,通过这样的设计,基于知识图谱设计的模型将不仅支持显示知识相关的查询,同时也支持与隐式知识相关的逻辑推理。该方法能够从患者的输入症状出发,经过知识图谱的查询和计算,得到患者可能的证候类型以及应该选择的治法和方剂。这是一种构建中医临床辅助决策系统的有益尝试据和非结构化数据,分别进行整理和提取,形成本研究所需要的数据(包含节点、属性与关系)。在此基础上,我们进行实体消歧、实体对齐等知识融合过程。随后本研究通过Python的py2neo库调用Neo4j,将知识数据导入Neo4j中构建知识图谱。然后通过Python编程将程序构建的基于中医诊疗指南的知识图谱,支持基于图数据库的查询功能。我们以诊疗指南中第一个证候对应的第一个临床表现(胸固定性痛)为例来说明。如查询“临床表现”为“胸固定性痛”,则展示如图6所示的知识图谱。蓝色节点为查询的症状“胸固定性痛”,其对应的“证候要素”为“血瘀”,“血瘀”能够组成“气虚血瘀证”、“气滞血瘀证”、“心血瘀阻证”“痰瘀互结证”4个证型。4个证型又分别对应治法和方剂以及中成药等。从而实现基于中医诊疗指南和专家经验的知识图谱可视化展示过程,为直观地展现中医诊疗过程提供一种新的方式。上述知识图谱的几个模块,即为依据中医诊疗指南进行辨证论治的过程。通过症状(临床表现)的组合文本,提炼出相应的证候要素,在证候要素的基础上组合出相应的证候类型,根据相应的证候类型即可推断相应的治法,确立治法后,即可推荐相应的中成药和中药方剂,并进一步可视化展示中药方剂所用的中药列表。这个过程即模拟了中医辨证论治冠心病稳定型心绞痛的过程,是诊疗指南的可视化和网络化的展示。下面我们将使用知识图谱的查询检索功能进行展示。图5为“证候类型”、“治法”、“中成药”、“方剂”和“中药”的知识图谱示意图。其中橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体,粉色节点代表“方剂”实体,绿色节点代表“中药”实体。联结“证候类型”实体和“治法”实体之间的边表示“证候类型”对应该“治法”,联结“治法”实体和“方剂”实体之间的边表示该“治法”推荐选择该“方剂”,联结“方剂”实体和“中药”实体之间的边表示该“方剂”由该“中药”组成。如图5所示,“气虚血瘀证”所对应的治法为“益气活血,补虚止痛”,该治法所对应的治疗手段中的中药方剂推荐“八珍汤加味”。方剂“八珍汤加味”的组成中药有“党参”、“白术”、“茯苓”、“甘草”、“当归”“红花”“赤芍”等11种。通过所构建的知识图谱,输入相应的证候类型,即可自动组合出对应的治法,推荐中药方剂,以及显示中药方剂所用的中药药味而图2为“临床表现”与“证候要素”知识图谱的示意图。其中蓝色节点代表“临床表现”实体、紫色节点代表“证候要素”实体,从“临床表现”实体指向“证候要素”实体的有向箭头代表二者之间的关联,即“临床表现”中提炼出该“证候要素”,如“神疲”、“乏力”等临床表现,能够相应的提炼出证候要素“气虚”。通过所构建的知识图谱,可输入相应的临床表现,即可自动提炼组合出对应的证候要素且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。多任务学习法。将嵌入模块和推荐模块设计成了相关又分离的任务,将图3为“证候要素”、“证候类型”和“治法”的知识图谱示意图。其中紫色节点代表“证候要素”实体,橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体。从“证候要素”实体指向“证候类型”实体的有向箭头代表二者之间的关联,即“证候要素”组成该“证候类型”。从“证候类型”实体指向“治法”实体的有向箭头代表二者之间的关联,即“证候类型”对应的治法为该“治法”。“气虚”和“阴虚”这2个证候要素,共同组成“气阴两虚证”这一证候类型,而“气阴两虚证”对应的治法为“益气养阴,活血通络”。通过所构建的知识图谱,输入相应的证候要素列表,即可自动组合出对应的证候类型这些任务放在同一个框架中进行交替学习,使用py2neo将诊疗指南中提取整理好的结构化数据导入到Neo4j数据库中,并进而完成基于中医诊疗指南的冠心病知识图谱构建。构建的知识图谱可通过py2neo或用Cypher语句进行查询和调用。因所构建的知识图谱节点较多,并且节点之间的关联复杂,难以在一张图上做清晰的显示,而诊疗指南中,“气虚”证候要素组合为证候类型的组合可能性较多,为了便于展示尽可能多的组合方式和节点关联,以“气虚”这一个证候要素相关的知识图谱为例(包含临床表现、证候要素、证候类型、治法、中成药、方剂和中药等节点及之间的关联),对所构建的知识图谱的节点和关联进行阐述Wang等人[43]提出了MKR模型,Cao等人[44]提出了KTUP模型。典型的例子就是MRK模型。该模型是由KGE模块和推荐模块组成的,将知识图谱以三元组的形式输入KGE模块,通过KGE模块预测出尾实体。用户和项目的特征表示作为推荐模块的输入,通过推荐模块得到项目点击率的估计值。在KGE模块和推荐模块中间有一个交叉特征共享单元,两个模块可以通过该共享单元进行数据交换,这样就可以得到用户的最终表示uL,如公式(6)所示。项目的最终表示vL,如公式(7)所示。其中vL是由L个交叉压缩单元提取的特征,CL是第L层的交叉特征矩阵,Sv表示的是项目v的相关实体集合。公式(8)为预测函数,目的是将用户的最终表示uL和项目的最终表示vL结合起来。知识图谱根据关系连接各实体并生成路径,用户能够通过路径去发现与实体具有关联性的潜在项目,从而获取更加准确的用户偏好。在表3中,汇总出了多领域知识图谱推荐系统基于路径的方法Hete-MF模型只是使用了项目之间的相似度,多方法推荐。不同的推荐方法都有各自的优缺点,当面对不同需求、不同上下文场景时应选择不同的推荐算法。不可能存在一个推荐算法在任何时候下都优于其他算法的情况。所以要充分运用不同推荐算法各自的优势,取长补短,相互融合形成一个强大的推荐框架,而且将多种推荐方法融合,可以有效的提高推荐效果。RippleNet模型、KGCN模型和KGAT模型都是典型的混合模型,它们将基于嵌入和基于路径的方法融合,充分利用了知识图谱中的实体信息和语义关系,实现更精确的推荐。但是多种方法结合也导致了计算量大,模型复杂,系统开销大,推荐速度慢等问题。如何在多方法融合的系统中,针对不同的情况系统可以快速做出推荐响应并尽量降低成本和开销,在未来推荐系统的发展中值得研究Luo等人[47]提出的Hete-CF模型是将用户之间的相似度、项目之间的相似度和用户项目之间的相似度都作为正则化来挖掘用户偏好。与上述模型思想相似的还有HeteRec[48]模型和HeteRec-p[49]模型。由Shi等人[50]提出的SemRec模型与上述的四类模型不同,SemRec模型根据知识图谱中的路径生成一个用户对项目评级的强度矩阵,评级强度矩阵就代表了用户的偏好,模型再根据相似用户的评分,预测推荐系统目标用户对项目的评分,根据评分进行排序,从高到低推荐给用户。公式(17)是用户之间相似度正则化目标函数该模型首先根据用户的交互历史训练出一个关系矩阵给路径中的各跳邻居分配权重,由于知识图谱是由三元组组成的,RippleNet模型根据三元组中的头实体、关系权重以及候选项得出尾实体的权重,计算出多跳邻居和候选项之间的相似度,路径中的每一层用户都会有一个用户表示,最后将每一层的用户表示结合生成用户的最终表示,反映出用户的偏好,计算得到用户的点击概率,根据点击概率给用户做推荐出于对安全性、可靠性等因素的考虑,大量消费者自然而然地流动到医美资源集聚的城市“求美”,“医美旅游”悄然兴起知识图谱是人工智能的重要研究领域,本质是构建和存储不同类型数据的关联性,用图网络来表示知识及其属性和关联,可在一定程度上表征复杂的知识结构和关联,尤其适宜中医领域的知识特点,如尹丹等[2]基于知识图谱,模拟了“方证对应”的诊疗过程。但目前知识图谱相关研究多基于网络爬虫技术批量格式化的爬取大量的医疗相关数据,并基于此数据构建知识图谱[3,4,5]。这类知识图谱普遍存在着数据一致性差,无效数据较多,以及数据缺失严重[6]等问题,生成的知识图谱冗余度[7]较大,对于医疗尤其是临床的实际意义和应用价值有限。中医药临床指南与共识推进了中医药标准化和规范化进程。中华中医药学会心血管病分会发布的《冠心病稳定型心绞痛中医诊疗指南》是基于大量具有独特疗效的中医诊治冠心病稳定型心绞痛临床诊疗经验制定的,能够规范中医诊疗过程和促进提升中医诊疗的整体水平[8],在冠心病稳定型心绞痛的诊疗中具有规范性和权威性。以此为模式实体是本体、实例和关系的整和。比如临床表现“乏力”是本体中的一个概念,“乏力”也是一个具体的临床表现个体,称为实例,其有对应的属性如“分值”和对应的“证候要素”—“气虚”,“乏力”以及本体“症状”和相关的属性,称为“实体”。本研究使用知识图谱常用的三元组数据模型来描述诊疗指南中的知识和知识之间的关系。三元组关系类似于“主谓宾”的关系,表征主语和宾语之间的关联特征。诊疗指南中的数据字段有“临床表现”、“证候要素”、“证候类型”、“治法”、“方剂”、“中成药”和“中药”等。他们之间的关联关系分别为:从“临床表现”提炼“证候要素”,由“证候要素”组成“证候类型”,“证候类型”对应相应的“治法”,依据“治法”选择“方剂”,依据“治法”选择“中成药”,“方剂”包含“中药”。基于上述抽取的本体之间的关系,可设计三元组结构表见表2构建中医冠心病诊疗的知识图谱,对于冠心病中医诊疗的标准化和规范化以及经验的传承具有重要意义。本研究基于知识图谱技术,以《冠心病稳定型心绞痛中医诊疗指南》为模式构建知识图谱,通过编程实现以临床表现的输入调用知识图谱,可视化展示冠心病稳定型心绞痛的中医规范化诊疗过程,以期为直观地展现中医诊疗过程提供了一种可参考的新的范式。1.1数据和知识来源本研究所用到的数据和知识来源于中本体是概念的集合和框架,类似于面相对象程序设计中的类,是知识图谱的架构,也是知识图谱结构化的基础逻辑,将本体整理成相应的结构表,有助于对知识图谱的理解。根据诊疗指南中的本体结构特征,本研究针对诊疗指南进行本体的提取,首先提取“临床表现”、“证候要素”、“证候类型”、“治法”、“方剂(方药)”和“中成药”等,其中“方剂”和“中成药”都可抽象为“治疗手段”,所以将“治疗手段”作为一级本体,而“方剂”和“中成药”作为二级本体。然后根据提取的本体,提取实例,分别为“胸闷痛”、“气虚”、“气滞血瘀”和“冠心2号方”[11]等,最后抽取本体之间的关系,即“临床表现”提炼“证候要素”、“证候要素”组成“证候类型”、“证候类型”对应“治法”等。据此本文设计本体的结构见表1华中医药学会心血管病分会发布的《冠心病稳定型心绞痛中医诊疗指南》[8]。1.2 软件工具本研究的知识图谱使用Neo4j (www.neo4j.com)社区版实现,Neo4j是一个开源的基于java的高性能的NoSQL的图数据库,不同于传图4为“证候类型”、“治法”、“中成药”和“方剂”的知识图谱示意图。其中橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体,深绿色节点代表“中成药”实体,粉色节点代表“方剂”实体。从“证候类型”实体指向“治法”实体的有向箭头代表二者之间的关联,即“证候类型”对应的治法为该“治法”。从“治法”实体指向8个“中成药”实体的有向箭头代表二者之间的关联,即该“治法”被选择后,推荐选择的中成药为8个“中成药”实体所对应的中成药。此外,从“治法”实体还有一个指向“方剂”实体的有向箭头,代表二者之间的关联为该“治法”被选择后,推荐选择的中药方剂为该“方剂”实体所对应的中药方剂。“气虚血瘀证”所对应的治法为“益气活血,补虚止痛”,该治法所对应的治疗手段有2种,第1种是中成药,第2种是中药方剂。该治法推荐选择的中成药有“通心络胶囊”、“通心舒胶囊”、“血栓心脉宁片”等8种,推荐的中药方剂为“八珍汤加味”。从诊疗指南可见,“八珍汤加味”的组成药味有“党参、白术、茯苓、甘草、当归、生地黄、赤芍、川芎、桃仁、红花、丹参”,根据《中华人民共和国药典》[12]和《中药学》[13]的药物功效分类和《方剂学》的内容,除了八珍汤的八味药组和使用具有气血双补的功效外,川芎、桃仁、红花和丹参为活血化瘀药具有活血化瘀的功效。王阶教授根据多年临床研究指出,补气强心为治疗冠心病的第一要义[14],选用八珍汤加味能够气血同补兼具活血通络,补气通络之法为王阶教授治疗冠心病的宝贵经验[15]。通过所构建的知识图谱,输入相应的证候类型,即可自动组合出对应的治法,推荐的中成药和中药方剂统数据库中使用的关系模型[9],它将结构化的数据存储在灵活的图网络中而不是表中,更适合表征具有复杂关联的数据及之间的关系,从而在各个行业中得到广泛应用。知识图谱构建和调用过程我们使用Python中的py2neo (https://github.com/py2neo-org/py2neo)来实现。Py2neo是一个Python库和工具包,用于从Python应用程序和命令行中调用或操作Neo4j。其中Node和Relationship这两个对象是py2neo的关键,它们都扩展了Subgraph类,提供了一套全面的图结构数据类型和操作支持,从而在如何调用和操作图数据方面提供了显著的灵活性。1.3 知识图谱概念知识图谱是使用图结构的数据模型或拓扑结构来集成和表示数据的知识库。知识图谱通常用于存储实体(对象、事件、情况或抽象概念)的相互关联的描述,同时还对所用术语背后的语义进行编码[10]。自语义网发展以来,知识图谱往往与关联的开放数据项目相关联,侧重于概念与实体之间的联系的存储和表示。利用知识图谱能够关联核心医学概念及医疗知识,从海量临床医案中对经验和知识进行提炼整理、录入标注和体系构建,以解决优质医疗资源短缺和医疗需求持续增加的矛盾。知识图谱的基本构建流程包括本体构建、实体配置、知识抽取和知识融合等。1.4 知识图谱设计1.4.1 流程设计本研究首先根据诊疗指南中的知识和信息,按照知识图谱构建的方法,从抽象的层面分别定义实体、关系和属性,然后将指南中本研究所需要的结构化数据、半结构化数据和非结构化数据,分别进行整理和提取,形成本研究所需要的数据(包含节点、属性与关系)。在此基础上,我们进行实体消歧、实体对齐等知识融合过程。随后本研究通过Python的py2neo库调用Neo4j,将知识数据导入Neo4j中构建知识图谱。然后通过Python编程将程序图5为“证候类型”、“治法”、“中成药”、“方剂”和“中药”的知识图谱示意图。其中橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体,粉色节点代表“方剂”实体,绿色节点代表“中药”实体。联结“证候类型”实体和“治法”实体之间的边表示“证候类型”对应该“治法”,联结“治法”实体和“方剂”实体之间的边表示该“治法”推荐选择该“方剂”,联结“方剂”实体和“中药”实体之间的边表示该“方剂”由该“中药”组成。如图5所示,“气虚血瘀证”所对应的治法为“益气活血,补虚止痛”,该治法所对应的治疗手段中的中药方剂推荐“八珍汤加味”。方剂“八珍汤加味”的组成中药有“党参”、“白术”、“茯苓”、“甘草”、“当归”“红花”“赤芍”等11种。通过所构建的知识图谱,输入相应的证候类型,即可自动组合出对应的治法,推荐中药方剂,以及显示中药方剂所用的中药药味而图2为“临床表现”与“证候要素”知识图谱的示意图。其中蓝色节点代表“临床表现”实体、紫色节点代表“证候要素”实体,从“临床表现”实体指向“证候要素”实体的有向箭头代表二者之间的关联,即“临床表现”中提炼出该“证候要素”,如“神疲”、“乏力”等临床表现,能够相应的提炼出证候要素“气虚”。通过所构建的知识图谱,可输入相应的临床表现,即可自动提炼组合出对应的证候要素且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。多任务学习法。将嵌入模块和推荐模块设计成了相关又分离的任务,将图3为“证候要素”、“证候类型”和“治法”的知识图谱示意图。其中紫色节点代表“证候要素”实体,橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体。从“证候要素”实体指向“证候类型”实体的有向箭头代表二者之间的关联,即“证候要素”组成该“证候类型”。从“证候类型”实体指向“治法”实体的有向箭头代表二者之间的关联,即“证候类型”对应的治法为该“治法”。“气虚”和“阴虚”这2个证候要素,共同组成“气阴两虚证”这一证候类型,而“气阴两虚证”对应的治法为“益气养阴,活血通络”。通过所构建的知识图谱,输入相应的证候要素列表,即可自动组合出对应的证候类型这些任务放在同一个框架中进行交替学习,使用py2neo将诊疗指南中提取整理好的结构化数据导入到Neo4j数据库中,并进而完成基于中医诊疗指南的冠心病知识图谱构建。构建的知识图谱可通过py2neo或用Cypher语句进行查询和调用。因所构建的知识图谱节点较多,并且节点之间的关联复杂,难以在一张图上做清晰的显示,而诊疗指南中,“气虚”证候要素组合为证候类型的组合可能性较多,为了便于展示尽可能多的组合方式和节点关联,以“气虚”这一个证候要素相关的知识图谱为例(包含临床表现、证候要素、证候类型、治法、中成药、方剂和中药等节点及之间的关联),对所构建的知识图谱的节点和关联进行阐述Wang等人[43]提出了MKR模型,Cao等人[44]提出了KTUP模型。典型的例子就是MRK模型。该模型是由KGE模块和推荐模块组成的,将知识图谱以三元组的形式输入KGE模块,通过KGE模块预测出尾实体。用户和项目的特征表示作为推荐模块的输入,通过推荐模块得到项目点击率的估计值。在KGE模块和推荐模块中间有一个交叉特征共享单元,两个模块可以通过该共享单元进行数据交换,这样就可以得到用户的最终表示uL,如公式(6)所示。项目的最终表示vL,如公式(7)所示。其中vL是由L个交叉压缩单元提取的特征,CL是第L层的交叉特征矩阵,Sv表示的是项目v的相关实体集合。公式(8)为预测函数,目的是将用户的最终表示uL和项目的最终表示vL结合起来。知识图谱根据关系连接各实体并生成路径,用户能够通过路径去发现与实体具有关联性的潜在项目,从而获取更加准确的用户偏好。在表3中,汇总出了多领域知识图谱推荐系统基于路径的方法Hete-MF模型只是使用了项目之间的相似度,多方法推荐。不同的推荐方法都有各自的优缺点,当面对不同需求、不同上下文场景时应选择不同的推荐算法。不可能存在一个推荐算法在任何时候下都优于其他算法的情况。所以要充分运用不同推荐算法各自的优势,取长补短,相互融合形成一个强大的推荐框架,而且将多种推荐方法融合,可以有效的提高推荐效果。RippleNet模型、KGCN模型和KGAT模型都是典型的混合模型,它们将基于嵌入和基于路径的方法融合,充分利用了知识图谱中的实体信息和语义关系,实现更精确的推荐。但是多种方法结合也导致了计算量大,模型复杂,系统开销大,推荐速度慢等问题。如何在多方法融合的系统中,针对不同的情况系统可以快速做出推荐响应并尽量降低成本和开销,在未来推荐系统的发展中值得研究Luo等人[47]提出的Hete-CF模型是将用户之间的相似度、项目之间的相似度和用户项目之间的相似度都作为正则化来挖掘用户偏好。与上述模型思想相似的还有HeteRec[48]模型和HeteRec-p[49]模型。由Shi等人[50]提出的SemRec模型与上述的四类模型不同,SemRec模型根据知识图谱中的路径生成一个用户对项目评级的强度矩阵,评级强度矩阵就代表了用户的偏好,模型再根据相似用户的评分,预测推荐系统目标用户对项目的评分,根据评分进行排序,从高到低推荐给用户。公式(17)是用户之间相似度正则化目标函数该模型首先根据用户的交互历史训练出一个关系矩阵给路径中的各跳邻居分配权重,由于知识图谱是由三元组组成的,RippleNet模型根据三元组中的头实体、关系权重以及候选项得出尾实体的权重,计算出多跳邻居和候选项之间的相似度,路径中的每一层用户都会有一个用户表示,最后将每一层的用户表示结合生成用户的最终表示,反映出用户的偏好,计算得到用户的点击概率,根据点击概率给用户做推荐出于对安全性、可靠性等因素的考虑,大量消费者自然而然地流动到医美资源集聚的城市“求美”,“医美旅游”悄然兴起知识图谱是人工智能的重要研究领域,本质是构建和存储不同类型数据的关联性,用图网络来表示知识及其属性和关联,可在一定程度上表征复杂的知识结构和关联,尤其适宜中医领域的知识特点,如尹丹等[2]基于知识图谱,模拟了“方证对应”的诊疗过程。但目前知识图谱相关研究多基于网络爬虫技术批量格式化的爬取大量的医疗相关数据,并基于此数据构建知识图谱[3,4,5]。这类知识图谱普遍存在着数据一致性差,无效数据较多,以及数据缺失严重[6]等问题,生成的知识图谱冗余度[7]较大,对于医疗尤其是临床的实际意义和应用价值有限。中医药临床指南与共识推进了中医药标准化和规范化进程。中华中医药学会心血管病分会发布的《冠心病稳定型心绞痛中医诊疗指南》是基于大量具有独特疗效的中医诊治冠心病稳定型心绞痛临床诊疗经验制定的,能够规范中医诊疗过程和促进提升中医诊疗的整体水平[8],在冠心病稳定型心绞痛的诊疗中具有规范性和权威性。以此为模式实体是本体、实例和关系的整和。比如临床表现“乏力”是本体中的一个概念,“乏力”也是一个具体的临床表现个体,称为实例,其有对应的属性如“分值”和对应的“证候要素”—“气虚”,“乏力”以及本体“症状”和相关的属性,称为“实体”。本研究使用知识图谱常用的三元组数据模型来描述诊疗指南中的知识和知识之间的关系。三元组关系类似于“主谓宾”的关系,表征主语和宾语之间的关联特征。诊疗指南中的数据字段有“临床表现”、“证候要素”、“证候类型”、“治法”、“方剂”、“中成药”和“中药”等。他们之间的关联关系分别为:从“临床表现”提炼“证候要素”,由“证候要素”组成“证候类型”,“证候类型”对应相应的“治法”,依据“治法”选择“方剂”,依据“治法”选择“中成药”,“方剂”包含“中药”。基于上述抽取的本体之间的关系,可设计三元组结构表见表2构建中医冠心病诊疗的知识图谱,对于冠心病中医诊疗的标准化和规范化以及经验的传承具有重要意义。本研究基于知识图谱技术,以《冠心病稳定型心绞痛中医诊疗指南》为模式构建知识图谱,通过编程实现以临床表现的输入调用知识图谱,可视化展示冠心病稳定型心绞痛的中医规范化诊疗过程,以期为直观地展现中医诊疗过程提供了一种可参考的新的范式。1.1数据和知识来源本研究所用到的数据和知识来源于中本体是概念的集合和框架,类似于面相对象程序设计中的类,是知识图谱的架构,也是知识图谱结构化的基础逻辑,将本体整理成相应的结构表,有助于对知识图谱的理解。根据诊疗指南中的本体结构特征,本研究针对诊疗指南进行本体的提取,首先提取“临床表现”、“证候要素”、“证候类型”、“治法”、“方剂(方药)”和“中成药”等,其中“方剂”和“中成药”都可抽象为“治疗手段”,所以将“治疗手段”作为一级本体,而“方剂”和“中成药”作为二级本体。然后根据提取的本体,提取实例,分别为“胸闷痛”、“气虚”、“气滞血瘀”和“冠心2号方”[11]等,最后抽取本体之间的关系,即“临床表现”提炼“证候要素”、“证候要素”组成“证候类型”、“证候类型”对应“治法”等。据此本文设计本体的结构见表1华中医药学会心血管病分会发布的《冠心病稳定型心绞痛中医诊疗指南》[8]。1.2 软件工具本研究的知识图谱使用Neo4j (www.neo4j.com)社区版实现,Neo4j是一个开源的基于java的高性能的NoSQL的图数据库,不同于传图4为“证候类型”、“治法”、“中成药”和“方剂”的知识图谱示意图。其中橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体,深绿色节点代表“中成药”实体,粉色节点代表“方剂”实体。从“证候类型”实体指向“治法”实体的有向箭头代表二者之间的关联,即“证候类型”对应的治法为该“治法”。从“治法”实体指向8个“中成药”实体的有向箭头代表二者之间的关联,即该“治法”被选择后,推荐选择的中成药为8个“中成药”实体所对应的中成药。此外,从“治法”实体还有一个指向“方剂”实体的有向箭头,代表二者之间的关联为该“治法”被选择后,推荐选择的中药方剂为该“方剂”实体所对应的中药方剂。“气虚血瘀证”所对应的治法为“益气活血,补虚止痛”,该治法所对应的治疗手段有2种,第1种是中成药,第2种是中药方剂。该治法推荐选择的中成药有“通心络胶囊”、“通心舒胶囊”、“血栓心脉宁片”等8种,推荐的中药方剂为“八珍汤加味”。从诊疗指南可见,“八珍汤加味”的组成药味有“党参、白术、茯苓、甘草、当归、生地黄、赤芍、川芎、桃仁、红花、丹参”,根据《中华人民共和国药典》[12]和《中药学》[13]的药物功效分类和《方剂学》的内容,除了八珍汤的八味药组和使用具有气血双补的功效外,川芎、桃仁、红花和丹参为活血化瘀药具有活血化瘀的功效。王阶教授根据多年临床研究指出,补气强心为治疗冠心病的第一要义[14],冠心病因其发病率和危害已经成为全球重大公共卫生问题[19],给公共医疗带来很大负担[20]。临床指南作为综合当前最佳研究证据和指导临床实践的文件,是医疗水平稳定的重要保证。《冠心病稳定型心绞痛中医诊疗指南》是由中华中医药学会心血管病分会组织相关专家编撰的。编撰过程参照国际最新的临床指南的制订方法,并在相关法律法规和技术文件指导的框架下,通过辨证论治的数据和关系突出体现了传统中医辨证论治的思想。编撰过程深度结合循证医学原理,在古今文献的回顾分析、临床流行病学调查、中成药系统综述、名老中医经验总结、专家咨询等系统研究工作的基础上,对冠心病稳定型心绞痛的基本证候特点、辨证用药规律等进行了系统地梳理、归纳和总结。《冠心病稳定型心绞痛中医诊疗指南》为中医、中西医结合临床医师规范化开展冠心病的防治工作提供权威指导。选用八珍汤加味能够气血同补兼具活血通络,补气通络之法为王阶教授治疗冠心病的宝贵经验[15]。通过所构建的知识图谱,输入相应的证候类型,即可自动组合出对应的治法,推荐的中成药和中药方剂统数据库中使用的关系模型[9],它将结构化的数据存储在灵活的图网络中而不是表中,更适合表征具有复杂关联的数据及之间的关系,从而在各个行业中得到广泛应用。知识图谱构建和调用过程我们使用Python中的py2neo (https://github.com/py2neo-org/py2neo)来实现。Py2neo是一个Python库和工具包,用于从Python应用程序和命令行中调用或操作Neo4j。其中Node和Relationship这两个对象是py2neo的关键,它们都扩展了Subgraph类,提供了一套全面的图结构数据类型和操作支持,从而在如何调用和操作图数据方面提供了显著的灵活性。1.3 知识图谱概念知识图谱是使用图结构的数据模型或拓扑结构来集成和表示数据的知识库。知识图谱通常用于存储实体(对象、事件、情况或抽象概念)的相互关联的描述,同时还对所用术语背后的语义进行编码[10]。自语义网发展以来,知识图谱往往与关联的开放数据项目相关联,侧重于概念与实体之间的联系的存储和表示。利用知识图谱能够关联核心医学概念及医疗知识,从海量临床医案中对经验和知识进行提炼整理、录入标注和体系构建,以解决优质医疗资源短缺和医疗需求持续增加的矛盾。知识图谱的基本构建流程包括本体构建、实体配置、知识抽取和知识融合等。1.4 知识图谱设计1.4.1 流程设计本研究首先根据诊疗指南中的知识和信息,按照知识图谱构建的方法,从抽象的层面分别定义实体、关系和属性,然后将指南中本研究所需要的结构化数据、半结构化数本研究结合目前中医诊疗经验传承中存在的问题,针对冠心病稳定型心绞痛这个单一病种,提出了一种基于凝结了中医行业专家经验和循证证据所形成的诊疗指南,来构建知识图谱的方法。与一些相关的研究不同的是,该方法没有选择使用基于网络爬虫的大数据来构建知识图谱,而是选择使用规范化、规则化程度较高的中医诊疗指南中的医学知识和术语构建知识图谱并可视化的展示和描述中医诊治冠心病稳定型心绞痛的过程。而知识图谱通过描述实体及其关系来表示语义,知识图谱可以使用本体作为模式层,通过这样的设计,基于知识图谱设计的模型将不仅支持显示知识相关的查询,同时也支持与隐式知识相关的逻辑推理。该方法能够从患者的输入症状出发,经过知识图谱的查询和计算,得到患者可能的证候类型以及应该选择的治法和方剂。这是一种构建中医临床辅助决策系统的有益尝试据和非结构化数据,分别进行整理和提取,形成本研究所需要的数据(包含节点、属性与关系)。在此基础上,我们进行实体消歧、实体对齐等知识融合过程。随后本研究通过Python的py2neo库调用Neo4j,将知识数据导入Neo4j中构建知识图谱。然后通过Python编程将程序构建的基于中医诊疗指南的知识图谱,支持基于图数据库的查询功能。我们以诊疗指南中第一个证候对应的第一个临床表现(胸固定性痛)为例来说明。如查询“临床表现”为“胸固定性痛”,则展示如图6所示的知识图谱。蓝色节点为查询的症状“胸固定性痛”,其对应的“证候要素”为“血瘀”,“血瘀”能够组成“气虚血瘀证”、“气滞血瘀证”、“心血瘀阻证”“痰瘀互结证”4个证型。4个证型又分别对应治法和方剂以及中成药等。从而实现基于中医诊疗指南和专家经验的知识图谱可视化展示过程,为直观地展现中医诊疗过程提供一种新的方式。上述知识图谱的几个模块,即为依据中医诊疗指南进行辨证论治的过程。通过症状(临床表现)的组合文本,提炼出相应的证候要素,在证候要素的基础上组合出相应的证候类型,根据相应的证候类型即可推断相应的治法,确立治法后,即可推荐相应的中成药和中药方剂,并进一步可视化展示中药方剂所用的中药列表。这个过程即模拟了中医辨证论治冠心病稳定型心绞痛的过程,是诊疗指南的可视化和网络化的展示。下面我们将使用知识图谱的查询检索功能进行展示。图5为“证候类型”、“治法”、“中成药”、“方剂”和“中药”的知识图谱示意图。其中橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体,粉色节点代表“方剂”实体,绿色节点代表“中药”实体。联结“证候类型”实体和“治法”实体之间的边表示“证候类型”对应该“治法”,联结“治法”实体和“方剂”实体之间的边表示该“治法”推荐选择该“方剂”,联结“方剂”实体和“中药”实体之间的边表示该“方剂”由该“中药”组成。如图5所示,“气虚血瘀证”所对应的治法为“益气活血,补虚止痛”,该治法所对应的治疗手段中的中药方剂推荐“八珍汤加味”。方剂“八珍汤加味”的组成中药有“党参”、“白术”、“茯苓”、“甘草”、“当归”“红花”“赤芍”等11种。通过所构建的知识图谱,输入相应的证候类型,即可自动组合出对应的治法,推荐中药方剂,以及显示中药方剂所用的中药药味而图2为“临床表现”与“证候要素”知识图谱的示意图。其中蓝色节点代表“临床表现”实体、紫色节点代表“证候要素”实体,从“临床表现”实体指向“证候要素”实体的有向箭头代表二者之间的关联,即“临床表现”中提炼出该“证候要素”,如“神疲”、“乏力”等临床表现,能够相应的提炼出证候要素“气虚”。通过所构建的知识图谱,可输入相应的临床表现,即可自动提炼组合出对应的证候要素且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。多任务学习法。将嵌入模块和推荐模块设计成了相关又分离的任务,将图3为“证候要素”、“证候类型”和“治法”的知识图谱示意图。其中紫色节点代表“证候要素”实体,橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体。从“证候要素”实体指向“证候类型”实体的有向箭头代表二者之间的关联,即“证候要素”组成该“证候类型”。从“证候类型”实体指向“治法”实体的有向箭头代表二者之间的关联,即“证候类型”对应的治法为该“治法”。“气虚”和“阴虚”这2个证候要素,共同组成“气阴两虚证”这一证候类型,而“气阴两虚证”对应的治法为“益气养阴,活血通络”。通过所构建的知识图谱,输入相应的证候要素列表,即可自动组合出对应的证候类型这些任务放在同一个框架中进行交替学习,使用py2neo将诊疗指南中提取整理好的结构化数据导入到Neo4j数据库中,并进而完成基于中医诊疗指南的冠心病知识图谱构建。构建的知识图谱可通过py2neo或用Cypher语句进行查询和调用。因所构建的知识图谱节点较多,并且节点之间的关联复杂,难以在一张图上做清晰的显示,而诊疗指南中,“气虚”证候要素组合为证候类型的组合可能性较多,为了便于展示尽可能多的组合方式和节点关联,以“气虚”这一个证候要素相关的知识图谱为例(包含临床表现、证候要素、证候类型、治法、中成药、方剂和中药等节点及之间的关联),对所构建的知识图谱的节点和关联进行阐述Wang等人[43]提出了MKR模型,Cao等人[44]提出了KTUP模型。典型的例子就是MRK模型。该模型是由KGE模块和推荐模块组成的,将知识图谱以三元组的形式输入KGE模块,通过KGE模块预测出尾实体。用户和项目的特征表示作为推荐模块的输入,通过推荐模块得到项目点击率的估计值。在KGE模块和推荐模块中间有一个交叉特征共享单元,两个模块可以通过该共享单元进行数据交换,这样就可以得到用户的最终表示uL,如公式(6)所示。项目的最终表示vL,如公式(7)所示。其中vL是由L个交叉压缩单元提取的特征,CL是第L层的交叉特征矩阵,Sv表示的是项目v的相关实体集合。公式(8)为预测函数,目的是将用户的最终表示uL和项目的最终表示vL结合起来。知识图谱根据关系连接各实体并生成路径,用户能够通过路径去发现与实体具有关联性的潜在项目,从而获取更加准确的用户偏好。在表3中,汇总出了多领域知识图谱推荐系统基于路径的方法Hete-MF模型只是使用了项目之间的相似度,多方法推荐。不同的推荐方法都有各自的优缺点,当面对不同需求、不同上下文场景时应选择不同的推荐算法。不可能存在一个推荐算法在任何时候下都优于其他算法的情况。所以要充分运用不同推荐算法各自的优势,取长补短,相互融合形成一个强大的推荐框架,而且将多种推荐方法融合,可以有效的提高推荐效果。RippleNet模型、KGCN模型和KGAT模型都是典型的混合模型,它们将基于嵌入和基于路径的方法融合,充分利用了知识图谱中的实体信息和语义关系,实现更精确的推荐。但是多种方法结合也导致了计算量大,模型复杂,系统开销大,推荐速度慢等问题。如何在多方法融合的系统中,针对不同的情况系统可以快速做出推荐响应并尽量降低成本和开销,在未来推荐系统的发展中值得研究Luo等人[47]提出的Hete-CF模型是将用户之间的相似度、项目之间的相似度和用户项目之间的相似度都作为正则化来挖掘用户偏好。与上述模型思想相似的还有HeteRec[48]模型和HeteRec-p[49]模型。由Shi等人[50]提出的SemRec模型与上述的四类模型不同,SemRec模型根据知识图谱中的路径生成一个用户对项目评级的强度矩阵,评级强度矩阵就代表了用户的偏好,模型再根据相似用户的评分,预测推荐系统目标用户对项目的评分,根据评分进行排序,从高到低推荐给用户。公式(17)是用户之间相似度正则化目标函数该模型首先根据用户的交互历史训练出一个关系矩阵给路径中的各跳邻居分配权重,由于知识图谱是由三元组组成的,RippleNet模型根据三元组中的头实体、关系权重以及候选项得出尾实体的权重,计算出多跳邻居和候选项之间的相似度,路径中的每一层用户都会有一个用户表示,最后将每一层的用户表示结合生成用户的最终表示,反映出用户的偏好,计算得到用户的点击概率,根据点击概率给用户做推荐出于对安全性、可靠性等因素的考虑,大量消费者自然而然地流动到医美资源集聚的城市“求美”,“医美旅游”悄然兴起知识图谱是人工智能的重要研究领域,本质是构建和存储不同类型数据的关联性,用图网络来表示知识及其属性和关联,可在一定程度上表征复杂的知识结构和关联,尤其适宜中医领域的知识特点,如尹丹等[2]基于知识图谱,模拟了“方证对应”的诊疗过程。但目前知识图谱相关研究多基于网络爬虫技术批量格式化的爬取大量的医疗相关数据,并基于此数据构建知识图谱[3,4,5]。这类知识图谱普遍存在着数据一致性差,无效数据较多,以及数据缺失严重[6]等问题,生成的知识图谱冗余度[7]较大,对于医疗尤其是临床的实际意义和应用价值有限。中医药临床指南与共识推进了中医药标准化和规范化进程。中华中医药学会心血管病分会发布的《冠心病稳定型心绞痛中医诊疗指南》是基于大量具有独特疗效的中医诊治冠心病稳定型心绞痛临床诊疗经验制定的,能够规范中医诊疗过程和促进提升中医诊疗的整体水平[8],在冠心病稳定型心绞痛的诊疗中具有规范性和权威性。以此为模式实体是本体、实例和关系的整和。比如临床表现“乏力”是本体中的一个概念,“乏力”也是一个具体的临床表现个体,称为实例,其有对应的属性如“分值”和对应的“证候要素”—“气虚”,“乏力”以及本体“症状”和相关的属性,称为“实体”。本研究使用知识图谱常用的三元组数据模型来描述诊疗指南中的知识和知识之间的关系。三元组关系类似于“主谓宾”的关系,表征主语和宾语之间的关联特征。诊疗指南中的数据字段有“临床表现”、“证候要素”、“证候类型”、“治法”、“方剂”、“中成药”和“中药”等。他们之间的关联关系分别为:从“临床表现”提炼“证候要素”,由“证候要素”组成“证候类型”,“证候类型”对应相应的“治法”,依据“治法”选择“方剂”,依据“治法”选择“中成药”,“方剂”包含“中药”。基于上述抽取的本体之间的关系,可设计三元组结构表见表2构建中医冠心病诊疗的知识图谱,对于冠心病中医诊疗的标准化和规范化以及经验的传承具有重要意义。本研究基于知识图谱技术,以《冠心病稳定型心绞痛中医诊疗指南》为模式构建知识图谱,通过编程实现以临床表现的输入调用知识图谱,可视化展示冠心病稳定型心绞痛的中医规范化诊疗过程,以期为直观地展现中医诊疗过程提供了一种可参考的新的范式。1.1数据和知识来源本研究所用到的数据和知识来源于中本体是概念的集合和框架,类似于面相对象程序设计中的类,是知识图谱的架构,也是知识图谱结构化的基础逻辑,将本体整理成相应的结构表,有助于对知识图谱的理解。根据诊疗指南中的本体结构特征,本研究针对诊疗指南进行本体的提取,首先提取“临床表现”、“证候要素”、“证候类型”、“治法”、“方剂(方药)”和“中成药”等,其中“方剂”和“中成药”都可抽象为“治疗手段”,所以将“治疗手段”作为一级本体,而“方剂”和“中成药”作为二级本体。然后根据提取的本体,提取实例,分别为“胸闷痛”、“气虚”、“气滞血瘀”和“冠心2号方”[11]等,最后抽取本体之间的关系,即“临床表现”提炼“证候要素”、“证候要素”组成“证候类型”、“证候类型”对应“治法”等。据此本文设计本体的结构见表1华中医药学会心血管病分会发布的《冠心病稳定型心绞痛中医诊疗指南》[8]。1.2 软件工具本研究的知识图谱使用Neo4j (www.neo4j.com)社区版实现,Neo4j是一个开源的基于java的高性能的NoSQL的图数据库,不同于传图4为“证候类型”、“治法”、“中成药”和“方剂”的知识图谱示意图。其中橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体,深绿色节点代表“中成药”实体,粉色节点代表“方剂”实体。从“证候类型”实体指向“治法”实体的有向箭头代表二者之间的关联,即“证候类型”对应的治法为该“治法”。从“治法”实体指向8个“中成药”实体的有向箭头代表二者之间的关联,即该“治法”被选择后,推荐选择的中成药为8个“中成药”实体所对应的中成药。此外,从“治法”实体还有一个指向“方剂”实体的有向箭头,代表二者之间的关联为该“治法”被选择后,推荐选择的中药方剂为该“方剂”实体所对应的中药方剂。“气虚血瘀证”所对应的治法为“益气活血,补虚止痛”,该治法所对应的治疗手段有2种,第1种是中成药,第2种是中药方剂。该治法推荐选择的中成药有“通心络胶囊”、“通心舒胶囊”、“血栓心脉宁片”等8种,推荐的中药方剂为“八珍汤加味”。从诊疗指南可见,“八珍汤加味”的组成药味有“党参、白术、茯苓、甘草、当归、生地黄、赤芍、川芎、桃仁、红花、丹参”,根据《中华人民共和国药典》[12]和《中药学》[13]的药物功效分类和《方剂学》的内容,除了八珍汤的八味药组和使用具有气血双补的功效外,川芎、桃仁、红花和丹参为活血化瘀药具有活血化瘀的功效。王阶教授根据多年临床研究指出,补气强心为治疗冠心病的第一要义[14],选用八珍汤加味能够气血同补兼具活血通络,补气通络之法为王阶教授治疗冠心病的宝贵经验[15]。通过所构建的知识图谱,输入相应的证候类型,即可自动组合出对应的治法,推荐的中成药和中药方剂统数据库中使用的关系模型[9],它将结构化的数据存储在灵活的图网络中而不是表中,更适合表征具有复杂关联的数据及之间的关系,从而在各个行业中得到广泛应用。知识图谱构建和调用过程我们使用Python中的py2neo (https://github.com/py2neo-org/py2neo)来实现。Py2neo是一个Python库和工具包,用于从Python应用程序和命令行中调用或操作Neo4j。其中Node和Relationship这两个对象是py2neo的关键,它们都扩展了Subgraph类,提供了一套全面的图结构数据类型和操作支持,从而在如何调用和操作图数据方面提供了显著的灵活性。1.3 知识图谱概念知识图谱是使用图结构的数据模型或拓扑结构来集成和表示数据的知识库。知识图谱通常用于存储实体(对象、事件、情况或抽象概念)的相互关联的描述,同时还对所用术语背后的语义进行编码[10]。自语义网发展以来,知识图谱往往与关联的开放数据项目相关联,侧重于概念与实体之间的联系的存储和表示。利用知识图谱能够关联核心医学概念及医疗知识,从海量临床医案中对经验和知识进行提炼整理、录入标注和体系构建,以解决优质医疗资源短缺和医疗需求持续增加的矛盾。知识图谱的基本构建流程包括本体构建、实体配置、知识抽取和知识融合等。1.4 知识图谱设计1.4.1 流程设计本研究首先根据诊疗指南中的知识和信息,按照知识图谱构建的方法,从抽象的层面分别定义实体、关系和属性,然后将指南中本研究所需要的结构化数据、半结构化数据和非结构化数据,分别进行整理和提取,形成本研究所需要的数据(包含节点、属性与关系)。在此基础上,我们进行实体消歧、实体对齐等知识融合过程。随后本研究通过Python的py2neo库调用Neo4j,将知识数据导入Neo4j中构建知识图谱。然后通过Python编程将程序图5为“证候类型”、“治法”、“中成药”、“方剂”和“中药”的知识图谱示意图。其中橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体,粉色节点代表“方剂”实体,绿色节点代表“中药”实体。联结“证候类型”实体和“治法”实体之间的边表示“证候类型”对应该“治法”,联结“治法”实体和“方剂”实体之间的边表示该“治法”推荐选择该“方剂”,联结“方剂”实体和“中药”实体之间的边表示该“方剂”由该“中药”组成。如图5所示,“气虚血瘀证”所对应的治法为“益气活血,补虚止痛”,该治法所对应的治疗手段中的中药方剂推荐“八珍汤加味”。方剂“八珍汤加味”的组成中药有“党参”、“白术”、“茯苓”、“甘草”、“当归”“红花”“赤芍”等11种。通过所构建的知识图谱,输入相应的证候类型,即可自动组合出对应的治法,推荐中药方剂,以及显示中药方剂所用的中药药味而图2为“临床表现”与“证候要素”知识图谱的示意图。其中蓝色节点代表“临床表现”实体、紫色节点代表“证候要素”实体,从“临床表现”实体指向“证候要素”实体的有向箭头代表二者之间的关联,即“临床表现”中提炼出该“证候要素”,如“神疲”、“乏力”等临床表现,能够相应的提炼出证候要素“气虚”。通过所构建的知识图谱,可输入相应的临床表现,即可自动提炼组合出对应的证候要素且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。多任务学习法。将嵌入模块和推荐模块设计成了相关又分离的任务,将图3为“证候要素”、“证候类型”和“治法”的知识图谱示意图。其中紫色节点代表“证候要素”实体,橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体。从“证候要素”实体指向“证候类型”实体的有向箭头代表二者之间的关联,即“证候要素”组成该“证候类型”。从“证候类型”实体指向“治法”实体的有向箭头代表二者之间的关联,即“证候类型”对应的治法为该“治法”。“气虚”和“阴虚”这2个证候要素,共同组成“气阴两虚证”这一证候类型,而“气阴两虚证”对应的治法为“益气养阴,活血通络”。通过所构建的知识图谱,输入相应的证候要素列表,即可自动组合出对应的证候类型这些任务放在同一个框架中进行交替学习,使用py2neo将诊疗指南中提取整理好的结构化数据导入到Neo4j数据库中,并进而完成基于中医诊疗指南的冠心病知识图谱构建。构建的知识图谱可通过py2neo或用Cypher语句进行查询和调用。因所构建的知识图谱节点较多,并且节点之间的关联复杂,难以在一张图上做清晰的显示,而诊疗指南中,“气虚”证候要素组合为证候类型的组合可能性较多,为了便于展示尽可能多的组合方式和节点关联,以“气虚”这一个证候要素相关的知识图谱为例(包含临床表现、证候要素、证候类型、治法、中成药、方剂和中药等节点及之间的关联),对所构建的知识图谱的节点和关联进行阐述Wang等人[43]提出了MKR模型,Cao等人[44]提出了KTUP模型。典型的例子就是MRK模型。该模型是由KGE模块和推荐模块组成的,将知识图谱以三元组的形式输入KGE模块,通过KGE模块预测出尾实体。用户和项目的特征表示作为推荐模块的输入,通过推荐模块得到项目点击率的估计值。在KGE模块和推荐模块中间有一个交叉特征共享单元,两个模块可以通过该共享单元进行数据交换,这样就可以得到用户的最终表示uL,如公式(6)所示。项目的最终表示vL,如公式(7)所示。其中vL是由L个交叉压缩单元提取的特征,CL是第L层的交叉特征矩阵,Sv表示的是项目v的相关实体集合。公式(8)为预测函数,目的是将用户的最终表示uL和项目的最终表示vL结合起来。知识图谱根据关系连接各实体并生成路径,用户能够通过路径去发现与实体具有关联性的潜在项目,从而获取更加准确的用户偏好。在表3中,汇总出了多领域知识图谱推荐系统基于路径的方法Hete-MF模型只是使用了项目之间的相似度,多方法推荐。不同的推荐方法都有各自的优缺点,当面对不同需求、不同上下文场景时应选择不同的推荐算法。不可能存在一个推荐算法在任何时候下都优于其他算法的情况。所以要充分运用不同推荐算法各自的优势,取长补短,相互融合形成一个强大的推荐框架,而且将多种推荐方法融合,可以有效的提高推荐效果。RippleNet模型、KGCN模型和KGAT模型都是典型的混合模型,它们将基于嵌入和基于路径的方法融合,充分利用了知识图谱中的实体信息和语义关系,实现更精确的推荐。但是多种方法结合也导致了计算量大,模型复杂,系统开销大,推荐速度慢等问题。如何在多方法融合的系统中,针对不同的情况系统可以快速做出推荐响应并尽量降低成本和开销,在未来推荐系统的发展中值得研究Luo等人[47]提出的Hete-CF模型是将用户之间的相似度、项目之间的相似度和用户项目之间的相似度都作为正则化来挖掘用户偏好。与上述模型思想相似的还有HeteRec[48]模型和HeteRec-p[49]模型。由Shi等人[50]提出的SemRec模型与上述的四类模型不同,SemRec模型根据知识图谱中的路径生成一个用户对项目评级的强度矩阵,评级强度矩阵就代表了用户的偏好,模型再根据相似用户的评分,预测推荐系统目标用户对项目的评分,根据评分进行排序,从高到低推荐给用户。公式(17)是用户之间相似度正则化目标函数该模型首先根据用户的交互历史训练出一个关系矩阵给路径中的各跳邻居分配权重,由于知识图谱是由三元组组成的,RippleNet模型根据三元组中的头实体、关系权重以及候选项得出尾实体的权重,计算出多跳邻居和候选项之间的相似度,路径中的每一层用户都会有一个用户表示,最后将每一层的用户表示结合生成用户的最终表示,反映出用户的偏好,计算得到用户的点击概率,根据点击概率给用户做推荐出于对安全性、可靠性等因素的考虑,大量消费者自然而然地流动到医美资源集聚的城市“求美”,“医美旅游”悄然兴起知识图谱是人工智能的重要研究领域,本质是构建和存储不同类型数据的关联性,用图网络来表示知识及其属性和关联,可在一定程度上表征复杂的知识结构和关联,尤其适宜中医领域的知识特点,如尹丹等[2]基于知识图谱,模拟了“方证对应”的诊疗过程。但目前知识图谱相关研究多基于网络爬虫技术批量格式化的爬取大量的医疗相关数据,并基于此数据构建知识图谱[3,4,5]。这类知识图谱普遍存在着数据一致性差,无效数据较多,以及数据缺失严重[6]等问题,生成的知识图谱冗余度[7]较大,对于医疗尤其是临床的实际意义和应用价值有限。中医药临床指南与共识推进了中医药标准化和规范化进程。中华中医药学会心血管病分会发布的《冠心病稳定型心绞痛中医诊疗指南》是基于大量具有独特疗效的中医诊治冠心病稳定型心绞痛临床诊疗经验制定的,能够规范中医诊疗过程和促进提升中医诊疗的整体水平[8],在冠心病稳定型心绞痛的诊疗中具有规范性和权威性。以此为模式实体是本体、实例和关系的整和。比如临床表现“乏力”是本体中的一个概念,“乏力”也是一个具体的临床表现个体,称为实例,其有对应的属性如“分值”和对应的“证候要素”—“气虚”,“乏力”以及本体“症状”和相关的属性,称为“实体”。本研究使用知识图谱常用的三元组数据模型来描述诊疗指南中的知识和知识之间的关系。三元组关系类似于“主谓宾”的关系,表征主语和宾语之间的关联特征。诊疗指南中的数据字段有“临床表现”、“证候要素”、“证候类型”、“治法”、“方剂”、“中成药”和“中药”等。他们之间的关联关系分别为:从“临床表现”提炼“证候要素”,由“证候要素”组成“证候类型”,“证候类型”对应相应的“治法”,依据“治法”选择“方剂”,依据“治法”选择“中成药”,“方剂”包含“中药”。基于上述抽取的本体之间的关系,可设计三元组结构表见表2构建中医冠心病诊疗的知识图谱,对于冠心病中医诊疗的标准化和规范化以及经验的传承具有重要意义。本研究基于知识图谱技术,以《冠心病稳定型心绞痛中医诊疗指南》为模式构建知识图谱,通过编程实现以临床表现的输入调用知识图谱,可视化展示冠心病稳定型心绞痛的中医规范化诊疗过程,以期为直观地展现中医诊疗过程提供了一种可参考的新的范式。1.1数据和知识来源本研究所用到的数据和知识来源于中本体是概念的集合和框架,类似于面相对象程序设计中的类,是知识图谱的架构,也是知识图谱结构化的基础逻辑,将本体整理成相应的结构表,有助于对知识图谱的理解。根据诊疗指南中的本体结构特征,本研究针对诊疗指南进行本体的提取,首先提取“临床表现”、“证候要素”、“证候类型”、“治法”、“方剂(方药)”和“中成药”等,其中“方剂”和“中成药”都可抽象为“治疗手段”,所以将“治疗手段”作为一级本体,而“方剂”和“中成药”作为二级本体。然后根据提取的本体,提取实例,分别为“胸闷痛”、“气虚”、“气滞血瘀”和“冠心2号方”[11]等,最后抽取本体之间的关系,即“临床表现”提炼“证候要素”、“证候要素”组成“证候类型”、“证候类型”对应“治法”等。据此本文设计本体的结构见表1华中医药学会心血管病分会发布的《冠心病稳定型心绞痛中医诊疗指南》[8]。1.2 软件工具本研究的知识图谱使用Neo4j (www.neo4j.com)社区版实现,Neo4j是一个开源的基于java的高性能的NoSQL的图数据库,不同于传图4为“证候类型”、“治法”、“中成药”和“方剂”的知识图谱示意图。其中橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体,深绿色节点代表“中成药”实体,粉色节点代表“方剂”实体。从“证候类型”实体指向“治法”实体的有向箭头代表二者之间的关联,即“证候类型”对应的治法为该“治法”。从“治法”实体指向8个“中成药”实体的有向箭头代表二者之间的关联,即该“治法”被选择后,推荐选择的中成药为8个“中成药”实体所对应的中成药。此外,从“治法”实体还有一个指向“方剂”实体的有向箭头,代表二者之间的关联为该“治法”被选择后,推荐选择的中药方剂为该“方剂”实体所对应的中药方剂。“气虚血瘀证”所对应的治法为“益气活血,补虚止痛”,该治法所对应的治疗手段有2种,第1种是中成药,第2种是中药方剂。该治法推荐选择的中成药有“通心络胶囊”、“通心舒胶囊”、“血栓心脉宁片”等8种,推荐的中药方剂为“八珍汤加味”。从诊疗指南可见,“八珍汤加味”的组成药味有“党参、白术、茯苓、甘草、当归、生地黄、赤芍、川芎、桃仁、红花、丹参”,根据《中华人民共和国药典》[12]和《中药学》[13]的药物功效分类和《方剂学》的内容,除了八珍汤的八味药组和使用具有气血双补的功效外,川芎、桃仁、红花和丹参为活血化瘀药具有活血化瘀的功效。王阶教授根据多年临床研究指出,补气强心为治疗冠心病的第一要义[14],冠心病因其发病率和危害已经成为全球重大公共卫生问题[19],给公共医疗带来很大负担[20]。临床指南作为综合当前最佳研究证据和指导临床实践的文件,是医疗水平稳定的重要保证。《冠心病稳定型心绞痛中医诊疗指南》是由中华中医药学会心血管病分会组织相关专家编撰的。编撰过程参照国际最新的临床指南的制订方法,并在相关法律法规和技术文件指导的框架下,通过辨证论治的数据和关系突出体现了传统中医辨证论治的思想。编撰过程深度结合循证医学原理,在古今文献的回顾分析、临床流行病学调查、中成药系统综述、名老中医经验总结、专家咨询等系统研究工作的基础上,对冠心病稳定型心绞痛的基本证候特点、辨证用药规律等进行了系统地梳理、归纳和总结。《冠心病稳定型心绞痛中医诊疗指南》为中医、中西医结合临床医师规范化开展冠心病的防治工作提供权威指导。选用八珍汤加味能够气血同补兼具活血通络,补气通络之法为王阶教授治疗冠心病的宝贵经验[15]。通过所构建的知识图谱,输入相应的证候类型,即可自动组合出对应的治法,推荐的中成药和中药方剂统数据库中使用的关系模型[9],它将结构化的数据存储在灵活的图网络中而不是表中,更适合表征具有复杂关联的数据及之间的关系,从而在各个行业中得到广泛应用。知识图谱构建和调用过程我们使用Python中的py2neo (https://github.com/py2neo-org/py2neo)来实现。Py2neo是一个Python库和工具包,用于从Python应用程序和命令行中调用或操作Neo4j。其中Node和Relationship这两个对象是py2neo的关键,它们都扩展了Subgraph类,提供了一套全面的图结构数据类型和操作支持,从而在如何调用和操作图数据方面提供了显著的灵活性。1.3 知识图谱概念知识图谱是使用图结构的数据模型或拓扑结构来集成和表示数据的知识库。知识图谱通常用于存储实体(对象、事件、情况或抽象概念)的相互关联的描述,同时还对所用术语背后的语义进行编码[10]。自语义网发展以来,知识图谱往往与关联的开放数据项目相关联,侧重于概念与实体之间的联系的存储和表示。利用知识图谱能够关联核心医学概念及医疗知识,从海量临床医案中对经验和知识进行提炼整理、录入标注和体系构建,以解决优质医疗资源短缺和医疗需求持续增加的矛盾。知识图谱技术在各行业事故故障智能化服务中已得到了广泛的研究和应用。在电力行业,李新鹏等人[7]通过构建调度自动化系统的知识图谱,实现系统故障的智能诊断和分析;郭榕等人[8]针对电网故障处置预案数据,构建电网故障处置知识图谱,提升了电网故障处置能力和智能化水平;在中石油领域,陈传刚等人[9]构建基于知识图谱的站场故障预警模型,实现现场事故预警;在铁路领域,杨连报等人[10]通过构建铁路设备事故故障部位知识图谱,实现了设备故障关联分析和原因推荐。基于各行业对知识图谱构建方法及应用模式的研究,本文在研究铁路运输设备安全保障体系的基础上,提出了铁路运输设备故障知识图谱构建与应用架构,以及设备故障知识图谱应用场景本研究也存在一些不足之处,一是因为诊疗指南是医学知识的高度凝练,能够抽取并用来构建知识图谱的知识的数量较为有限,后续将进一步扩充相关的高质量的知识来源,不断对本研究所构建的知识图谱进行丰富和扩展。二是因为目前诊疗指南中的部分数据和关联从知识图谱构建的角度而言存在一定的交叉重叠,为了解决这个问题,我们在数据收集、本体构建和知识融合等环节,需要临床医师根据知识图谱开发的要求,完成交叉知识的拆解和融合才能够更合理的构建知识图谱。三是目前本研究构建的知识图谱中使用的输入症状词语必须与临床指南中用语一致才能识别,还未能支持输入症状列表进行中医临床辅助决策,下一步应在此研究基础上实现自然语言处理功能,训练与指南数据和知识图谱适配的自然语言处理模型,实现从自然语言中自动抽取知识图谱能够识别的用语,并基于知识图谱实现症状列表输入功能。四是目前还未能支持证候的兼夹性和患者更加个体的信息,下一步将开发设置支持多证候显示的知识图谱,以支持兼夹证候的显示,并且从本体层设计纳入更多的体现患者个体差异的数据结构,将临床中患者的个体差异体现在知识图谱展示的诊疗过程中从而将模型整合成为功能更贴近真实临床的中医临床辅助决策系统。上述知识图谱的几个模块,即为依据中医诊疗指南进行辨证论治的过程。通过症状(临床表现)的组合文本,提炼出相应的证候要素,在证候要素的基础上组合出相应的证候类型,根据相应的证候类型即可推断相应的治法,确立治法后,即可推荐相应的中成药和中药方剂,并进一步可视化展示中药方剂所用的中药列表。这个过程即模拟了中医辨证论治冠心病稳定型心绞痛的过程,是诊疗指南的可视化和网络化的展示。下面我们将使用知识图谱的查询检索功能进行展示。图5为“证候类型”、“治法”、“中成药”、“方剂”和“中药”的知识图谱示意图。其中橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体,粉色节点代表“方剂”实体,绿色节点代表“中药”实体。联结“证候类型”实体和“治法”实体之间的边表示“证候类型”对应该“治法”,联结“治法”实体和“方剂”实体之间的边表示该“治法”推荐选择该“方剂”,联结“方剂”实体和“中药”实体之间的边表示该“方剂”由该“中药”组成。如图5所示,“气虚血瘀证”所对应的治法为“益气活血,补虚止痛”,该治法所对应的治疗手段中的中药方剂推荐“八珍汤加味”。方剂“八珍汤加味”的组成中药有“党参”、“白术”、“茯苓”、“甘草”、“当归”“红花”“赤芍”等11种。通过所构建的知识图谱,输入相应的证候类型,即可自动组合出对应的治法,推荐中药方剂,以及显示中药方剂所用的中药药味而图2为“临床表现”与“证候要素”知识图谱的示意图。其中蓝色节点代表“临床表现”实体、紫色节点代表“证候要素”实体,从“临床表现”实体指向“证候要素”实体的有向箭头代表二者之间的关联,即“临床表现”中提炼出该“证候要素”,如“神疲”、“乏力”等临床表现,能够相应的提炼出证候要素“气虚”。通过所构建的知识图谱,可输入相应的临床表现,即可自动提炼组合出对应的证候要素且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。多任务学习法。将嵌入模块和推荐模块设计成了相关又分离的任务,将图3为“证候要素”、“证候类型”和“治法”的知识图谱示意图。其中紫色节点代表“证候要素”实体,橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体。从“证候要素”实体指向“证候类型”实体的有向箭头代表二者之间的关联,即“证候要素”组成该“证候类型”。从“证候类型”实体指向“治法”实体的有向箭头代表二者之间的关联,即“证候类型”对应的治法为该“治法”。“气虚”和“阴虚”这2个证候要素,共同组成“气阴两虚证”这一证候类型,而“气阴两虚证”对应的治法为“益气养阴,活血通络”。通过所构建的知识图谱,输入相应的证候要素列表,即可自动组合出对应的证候类型这些任务放在同一个框架中进行交替学习,使用py2neo将诊疗指南中提取整理好的结构化数据导入到Neo4j数据库中,并进而完成基于中医诊疗指南的冠心病知识图谱构建。构建的知识图谱可通过py2neo或用Cypher语句进行查询和调用。因所构建的知识图谱节点较多,并且节点之间的关联复杂,难以在一张图上做清晰的显示,而诊疗指南中,“气虚”证候要素组合为证候类型的组合可能性较多,为了便于展示尽可能多的组合方式和节点关联,以“气虚”这一个证候要素相关的知识图谱为例(包含临床表现、证候要素、证候类型、治法、中成药、方剂和中药等节点及之间的关联),对所构建的知识图谱的节点和关联进行阐述Wang等人[43]提出了MKR模型,Cao等人[44]提出了KTUP模型。典型的例子就是MRK模型。该模型是由KGE模块和推荐模块组成的,将知识图谱以三元组的形式输入KGE模块,通过KGE模块预测出尾实体。用户和项目的特征表示作为推荐模块的输入,通过推荐模块得到项目点击率的估计值。在KGE模块和推荐模块中间有一个交叉特征共享单元,两个模块可以通过该共享单元进行数据交换,这样就可以得到用户的最终表示uL,如公式(6)所示。项目的最终表示vL,如公式(7)所示。其中vL是由L个交叉压缩单元提取的特征,CL是第L层的交叉特征矩阵,Sv表示的是项目v的相关实体集合。公式(8)为预测函数,目的是将用户的最终表示uL和项目的最终表示vL结合起来。知识图谱根据关系连接各实体并生成路径,用户能够通过路径去发现与实体具有关联性的潜在项目,从而获取更加准确的用户偏好。在表3中,汇总出了多领域知识图谱推荐系统基于路径的方法Hete-MF模型只是使用了项目之间的相似度,多方法推荐。不同的推荐方法都有各自的优缺点,当面对不同需求、不同上下文场景时应选择不同的推荐算法。不可能存在一个推荐算法在任何时候下都优于其他算法的情况。所以要充分运用不同推荐算法各自的优势,取长补短,相互融合形成一个强大的推荐框架,而且将多种推荐方法融合,可以有效的提高推荐效果。RippleNet模型、KGCN模型和KGAT模型都是典型的混合模型,它们将基于嵌入和基于路径的方法融合,充分利用了知识图谱中的实体信息和语义关系,实现更精确的推荐。但是多种方法结合也导致了计算量大,模型复杂,系统开销大,推荐速度慢等问题。如何在多方法融合的系统中,针对不同的情况系统可以快速做出推荐响应并尽量降低成本和开销,在未来推荐系统的发展中值得研究Luo等人[47]提出的Hete-CF模型是将用户之间的相似度、项目之间的相似度和用户项目之间的相似度都作为正则化来挖掘用户偏好。与上述模型思想相似的还有HeteRec[48]模型和HeteRec-p[49]模型。由Shi等人[50]提出的SemRec模型与上述的四类模型不同,SemRec模型根据知识图谱中的路径生成一个用户对项目评级的强度矩阵,评级强度矩阵就代表了用户的偏好,模型再根据相似用户的评分,预测推荐系统目标用户对项目的评分,根据评分进行排序,从高到低推荐给用户。公式(17)是用户之间相似度正则化目标函数该模型首先根据用户的交互历史训练出一个关系矩阵给路径中的各跳邻居分配权重,由于知识图谱是由三元组组成的,RippleNet模型根据三元组中的头实体、关系权重以及候选项得出尾实体的权重,计算出多跳邻居和候选项之间的相似度,路径中的每一层用户都会有一个用户表示,最后将每一层的用户表示结合生成用户的最终表示,反映出用户的偏好,计算得到用户的点击概率,根据点击概率给用户做推荐出于对安全性、可靠性等因素的考虑,大量消费者自然而然地流动到医美资源集聚的城市“求美”,“医美旅游”悄然兴起知识图谱是人工智能的重要研究领域,本质是构建和存储不同类型数据的关联性,用图网络来表示知识及其属性和关联,可在一定程度上表征复杂的知识结构和关联,尤其适宜中医领域的知识特点,如尹丹等[2]基于知识图谱,模拟了“方证对应”的诊疗过程。但目前知识图谱相关研究多基于网络爬虫技术批量格式化的爬取大量的医疗相关数据,并基于此数据构建知识图谱[3,4,5]。这类知识图谱普遍存在着数据一致性差,无效数据较多,以及数据缺失严重[6]等问题,生成的知识图谱冗余度[7]较大,对于医疗尤其是临床的实际意义和应用价值有限。中医药临床指南与共识推进了中医药标准化和规范化进程。中华中医药学会心血管病分会发布的《冠心病稳定型心绞痛中医诊疗指南》是基于大量具有独特疗效的中医诊治冠心病稳定型心绞痛临床诊疗经验制定的,能够规范中医诊疗过程和促进提升中医诊疗的整体水平[8],在冠心病稳定型心绞痛的诊疗中具有规范性和权威性。以此为模式实体是本体、实例和关系的整和。比如临床表现“乏力”是本体中的一个概念,“乏力”也是一个具体的临床表现个体,称为实例,其有对应的属性如“分值”和对应的“证候要素”—“气虚”,“乏力”以及本体“症状”和相关的属性,称为“实体”。本研究使用知识图谱常用的三元组数据模型来描述诊疗指南中的知识和知识之间的关系。三元组关系类似于“主谓宾”的关系,表征主语和宾语之间的关联特征。诊疗指南中的数据字段有“临床表现”、“证候要素”、“证候类型”、“治法”、“方剂”、“中成药”和“中药”等。他们之间的关联关系分别为:从“临床表现”提炼“证候要素”,由“证候要素”组成“证候类型”,“证候类型”对应相应的“治法”,依据“治法”选择“方剂”,依据“治法”选择“中成药”,“方剂”包含“中药”。基于上述抽取的本体之间的关系,可设计三元组结构表见表2构建中医冠心病诊疗的知识图谱,对于冠心病中医诊疗的标准化和规范化以及经验的传承具有重要意义。本研究基于知识图谱技术,以《冠心病稳定型心绞痛中医诊疗指南》为模式构建知识图谱,通过编程实现以临床表现的输入调用知识图谱,可视化展示冠心病稳定型心绞痛的中医规范化诊疗过程,以期为直观地展现中医诊疗过程提供了一种可参考的新的范式。1.1数据和知识来源本研究所用到的数据和知识来源于中本体是概念的集合和框架,类似于面相对象程序设计中的类,是知识图谱的架构,也是知识图谱结构化的基础逻辑,将本体整理成相应的结构表,有助于对知识图谱的理解。根据诊疗指南中的本体结构特征,本研究针对诊疗指南进行本体的提取,首先提取“临床表现”、“证候要素”、“证候类型”、“治法”、“方剂(方药)”和“中成药”等,其中“方剂”和“中成药”都可抽象为“治疗手段”,所以将“治疗手段”作为一级本体,而“方剂”和“中成药”作为二级本体。然后根据提取的本体,提取实例,分别为“胸闷痛”、“气虚”、“气滞血瘀”和“冠心2号方”[11]等,最后抽取本体之间的关系,即“临床表现”提炼“证候要素”、“证候要素”组成“证候类型”、“证候类型”对应“治法”等。据此本文设计本体的结构见表1华中医药学会心血管病分会发布的《冠心病稳定型心绞痛中医诊疗指南》[8]。1.2 软件工具本研究的知识图谱使用Neo4j (www.neo4j.com)社区版实现,Neo4j是一个开源的基于java的高性能的NoSQL的图数据库,不同于传图4为“证候类型”、“治法”、“中成药”和“方剂”的知识图谱示意图。其中橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体,深绿色节点代表“中成药”实体,粉色节点代表“方剂”实体。从“证候类型”实体指向“治法”实体的有向箭头代表二者之间的关联,即“证候类型”对应的治法为该“治法”。从“治法”实体指向8个“中成药”实体的有向箭头代表二者之间的关联,即该“治法”被选择后,推荐选择的中成药为8个“中成药”实体所对应的中成药。此外,从“治法”实体还有一个指向“方剂”实体的有向箭头,代表二者之间的关联为该“治法”被选择后,推荐选择的中药方剂为该“方剂”实体所对应的中药方剂。“气虚血瘀证”所对应的治法为“益气活血,补虚止痛”,该治法所对应的治疗手段有2种,第1种是中成药,第2种是中药方剂。该治法推荐选择的中成药有“通心络胶囊”、“通心舒胶囊”、“血栓心脉宁片”等8种,推荐的中药方剂为“八珍汤加味”。从诊疗指南可见,“八珍汤加味”的组成药味有“党参、白术、茯苓、甘草、当归、生地黄、赤芍、川芎、桃仁、红花、丹参”,根据《中华人民共和国药典》[12]和《中药学》[13]的药物功效分类和《方剂学》的内容,除了八珍汤的八味药组和使用具有气血双补的功效外,川芎、桃仁、红花和丹参为活血化瘀药具有活血化瘀的功效。王阶教授根据多年临床研究指出,补气强心为治疗冠心病的第一要义[14],选用八珍汤加味能够气血同补兼具活血通络,补气通络之法为王阶教授治疗冠心病的宝贵经验[15]。通过所构建的知识图谱,输入相应的证候类型,即可自动组合出对应的治法,推荐的中成药和中药方剂统数据库中使用的关系模型[9],它将结构化的数据存储在灵活的图网络中而不是表中,更适合表征具有复杂关联的数据及之间的关系,从而在各个行业中得到广泛应用。知识图谱构建和调用过程我们使用Python中的py2neo (https://github.com/py2neo-org/py2neo)来实现。Py2neo是一个Python库和工具包,用于从Python应用程序和命令行中调用或操作Neo4j。其中Node和Relationship这两个对象是py2neo的关键,它们都扩展了Subgraph类,提供了一套全面的图结构数据类型和操作支持,从而在如何调用和操作图数据方面提供了显著的灵活性。1.3 知识图谱概念知识图谱是使用图结构的数据模型或拓扑结构来集成和表示数据的知识库。知识图谱通常用于存储实体(对象、事件、情况或抽象概念)的相互关联的描述,同时还对所用术语背后的语义进行编码[10]。自语义网发展以来,知识图谱往往与关联的开放数据项目相关联,侧重于概念与实体之间的联系的存储和表示。利用知识图谱能够关联核心医学概念及医疗知识,从海量临床医案中对经验和知识进行提炼整理、录入标注和体系构建,以解决优质医疗资源短缺和医疗需求持续增加的矛盾。知识图谱的基本构建流程包括本体构建、实体配置、知识抽取和知识融合等。1.4 知识图谱设计1.4.1 流程设计本研究首先根据诊疗指南中的知识和信息,按照知识图谱构建的方法,从抽象的层面分别定义实体、关系和属性,然后将指南中本研究所需要的结构化数据、半结构化数据和非结构化数据,分别进行整理和提取,形成本研究所需要的数据(包含节点、属性与关系)。在此基础上,我们进行实体消歧、实体对齐等知识融合过程。随后本研究通过Python的py2neo库调用Neo4j,将知识数据导入Neo4j中构建知识图谱。然后通过Python编程将程序图5为“证候类型”、“治法”、“中成药”、“方剂”和“中药”的知识图谱示意图。其中橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体,粉色节点代表“方剂”实体,绿色节点代表“中药”实体。联结“证候类型”实体和“治法”实体之间的边表示“证候类型”对应该“治法”,联结“治法”实体和“方剂”实体之间的边表示该“治法”推荐选择该“方剂”,联结“方剂”实体和“中药”实体之间的边表示该“方剂”由该“中药”组成。如图5所示,“气虚血瘀证”所对应的治法为“益气活血,补虚止痛”,该治法所对应的治疗手段中的中药方剂推荐“八珍汤加味”。方剂“八珍汤加味”的组成中药有“党参”、“白术”、“茯苓”、“甘草”、“当归”“红花”“赤芍”等11种。通过所构建的知识图谱,输入相应的证候类型,即可自动组合出对应的治法,推荐中药方剂,以及显示中药方剂所用的中药药味而图2为“临床表现”与“证候要素”知识图谱的示意图。其中蓝色节点代表“临床表现”实体、紫色节点代表“证候要素”实体,从“临床表现”实体指向“证候要素”实体的有向箭头代表二者之间的关联,即“临床表现”中提炼出该“证候要素”,如“神疲”、“乏力”等临床表现,能够相应的提炼出证候要素“气虚”。通过所构建的知识图谱,可输入相应的临床表现,即可自动提炼组合出对应的证候要素且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。多任务学习法。将嵌入模块和推荐模块设计成了相关又分离的任务,将图3为“证候要素”、“证候类型”和“治法”的知识图谱示意图。其中紫色节点代表“证候要素”实体,橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体。从“证候要素”实体指向“证候类型”实体的有向箭头代表二者之间的关联,即“证候要素”组成该“证候类型”。从“证候类型”实体指向“治法”实体的有向箭头代表二者之间的关联,即“证候类型”对应的治法为该“治法”。“气虚”和“阴虚”这2个证候要素,共同组成“气阴两虚证”这一证候类型,而“气阴两虚证”对应的治法为“益气养阴,活血通络”。通过所构建的知识图谱,输入相应的证候要素列表,即可自动组合出对应的证候类型这些任务放在同一个框架中进行交替学习,使用py2neo将诊疗指南中提取整理好的结构化数据导入到Neo4j数据库中,并进而完成基于中医诊疗指南的冠心病知识图谱构建。构建的知识图谱可通过py2neo或用Cypher语句进行查询和调用。因所构建的知识图谱节点较多,并且节点之间的关联复杂,难以在一张图上做清晰的显示,而诊疗指南中,“气虚”证候要素组合为证候类型的组合可能性较多,为了便于展示尽可能多的组合方式和节点关联,以“气虚”这一个证候要素相关的知识图谱为例(包含临床表现、证候要素、证候类型、治法、中成药、方剂和中药等节点及之间的关联),对所构建的知识图谱的节点和关联进行阐述Wang等人[43]提出了MKR模型,Cao等人[44]提出了KTUP模型。典型的例子就是MRK模型。该模型是由KGE模块和推荐模块组成的,将知识图谱以三元组的形式输入KGE模块,通过KGE模块预测出尾实体。用户和项目的特征表示作为推荐模块的输入,通过推荐模块得到项目点击率的估计值。在KGE模块和推荐模块中间有一个交叉特征共享单元,两个模块可以通过该共享单元进行数据交换,这样就可以得到用户的最终表示uL,如公式(6)所示。项目的最终表示vL,如公式(7)所示。其中vL是由L个交叉压缩单元提取的特征,CL是第L层的交叉特征矩阵,Sv表示的是项目v的相关实体集合。公式(8)为预测函数,目的是将用户的最终表示uL和项目的最终表示vL结合起来。知识图谱根据关系连接各实体并生成路径,用户能够通过路径去发现与实体具有关联性的潜在项目,从而获取更加准确的用户偏好。在表3中,汇总出了多领域知识图谱推荐系统基于路径的方法Hete-MF模型只是使用了项目之间的相似度,多方法推荐。不同的推荐方法都有各自的优缺点,当面对不同需求、不同上下文场景时应选择不同的推荐算法。不可能存在一个推荐算法在任何时候下都优于其他算法的情况。所以要充分运用不同推荐算法各自的优势,取长补短,相互融合形成一个强大的推荐框架,而且将多种推荐方法融合,可以有效的提高推荐效果。RippleNet模型、KGCN模型和KGAT模型都是典型的混合模型,它们将基于嵌入和基于路径的方法融合,充分利用了知识图谱中的实体信息和语义关系,实现更精确的推荐。但是多种方法结合也导致了计算量大,模型复杂,系统开销大,推荐速度慢等问题。如何在多方法融合的系统中,针对不同的情况系统可以快速做出推荐响应并尽量降低成本和开销,在未来推荐系统的发展中值得研究Luo等人[47]提出的Hete-CF模型是将用户之间的相似度、项目之间的相似度和用户项目之间的相似度都作为正则化来挖掘用户偏好。与上述模型思想相似的还有HeteRec[48]模型和HeteRec-p[49]模型。由Shi等人[50]提出的SemRec模型与上述的四类模型不同,SemRec模型根据知识图谱中的路径生成一个用户对项目评级的强度矩阵,评级强度矩阵就代表了用户的偏好,模型再根据相似用户的评分,预测推荐系统目标用户对项目的评分,根据评分进行排序,从高到低推荐给用户。公式(17)是用户之间相似度正则化目标函数该模型首先根据用户的交互历史训练出一个关系矩阵给路径中的各跳邻居分配权重,由于知识图谱是由三元组组成的,RippleNet模型根据三元组中的头实体、关系权重以及候选项得出尾实体的权重,计算出多跳邻居和候选项之间的相似度,路径中的每一层用户都会有一个用户表示,最后将每一层的用户表示结合生成用户的最终表示,反映出用户的偏好,计算得到用户的点击概率,根据点击概率给用户做推荐出于对安全性、可靠性等因素的考虑,大量消费者自然而然地流动到医美资源集聚的城市“求美”,“医美旅游”悄然兴起知识图谱是人工智能的重要研究领域,本质是构建和存储不同类型数据的关联性,用图网络来表示知识及其属性和关联,可在一定程度上表征复杂的知识结构和关联,尤其适宜中医领域的知识特点,如尹丹等[2]基于知识图谱,模拟了“方证对应”的诊疗过程。但目前知识图谱相关研究多基于网络爬虫技术批量格式化的爬取大量的医疗相关数据,并基于此数据构建知识图谱[3,4,5]。这类知识图谱普遍存在着数据一致性差,无效数据较多,以及数据缺失严重[6]等问题,生成的知识图谱冗余度[7]较大,对于医疗尤其是临床的实际意义和应用价值有限。中医药临床指南与共识推进了中医药标准化和规范化进程。中华中医药学会心血管病分会发布的《冠心病稳定型心绞痛中医诊疗指南》是基于大量具有独特疗效的中医诊治冠心病稳定型心绞痛临床诊疗经验制定的,能够规范中医诊疗过程和促进提升中医诊疗的整体水平[8],在冠心病稳定型心绞痛的诊疗中具有规范性和权威性。以此为模式实体是本体、实例和关系的整和。比如临床表现“乏力”是本体中的一个概念,“乏力”也是一个具体的临床表现个体,称为实例,其有对应的属性如“分值”和对应的“证候要素”—“气虚”,“乏力”以及本体“症状”和相关的属性,称为“实体”。本研究使用知识图谱常用的三元组数据模型来描述诊疗指南中的知识和知识之间的关系。三元组关系类似于“主谓宾”的关系,表征主语和宾语之间的关联特征。诊疗指南中的数据字段有“临床表现”、“证候要素”、“证候类型”、“治法”、“方剂”、“中成药”和“中药”等。他们之间的关联关系分别为:从“临床表现”提炼“证候要素”,由“证候要素”组成“证候类型”,“证候类型”对应相应的“治法”,依据“治法”选择“方剂”,依据“治法”选择“中成药”,“方剂”包含“中药”。基于上述抽取的本体之间的关系,可设计三元组结构表见表2构建中医冠心病诊疗的知识图谱,对于冠心病中医诊疗的标准化和规范化以及经验的传承具有重要意义。本研究基于知识图谱技术,以《冠心病稳定型心绞痛中医诊疗指南》为模式构建知识图谱,通过编程实现以临床表现的输入调用知识图谱,可视化展示冠心病稳定型心绞痛的中医规范化诊疗过程,以期为直观地展现中医诊疗过程提供了一种可参考的新的范式。1.1数据和知识来源本研究所用到的数据和知识来源于中本体是概念的集合和框架,类似于面相对象程序设计中的类,是知识图谱的架构,也是知识图谱结构化的基础逻辑,将本体整理成相应的结构表,有助于对知识图谱的理解。根据诊疗指南中的本体结构特征,本研究针对诊疗指南进行本体的提取,首先提取“临床表现”、“证候要素”、“证候类型”、“治法”、“方剂(方药)”和“中成药”等,其中“方剂”和“中成药”都可抽象为“治疗手段”,所以将“治疗手段”作为一级本体,而“方剂”和“中成药”作为二级本体。然后根据提取的本体,提取实例,分别为“胸闷痛”、“气虚”、“气滞血瘀”和“冠心2号方”[11]等,最后抽取本体之间的关系,即“临床表现”提炼“证候要素”、“证候要素”组成“证候类型”、“证候类型”对应“治法”等。据此本文设计本体的结构见表1华中医药学会心血管病分会发布的《冠心病稳定型心绞痛中医诊疗指南》[8]。1.2 软件工具本研究的知识图谱使用Neo4j (www.neo4j.com)社区版实现,Neo4j是一个开源的基于java的高性能的NoSQL的图数据库,不同于传图4为“证候类型”、“治法”、“中成药”和“方剂”的知识图谱示意图。其中橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体,深绿色节点代表“中成药”实体,粉色节点代表“方剂”实体。从“证候类型”实体指向“治法”实体的有向箭头代表二者之间的关联,即“证候类型”对应的治法为该“治法”。从“治法”实体指向8个“中成药”实体的有向箭头代表二者之间的关联,即该“治法”被选择后,推荐选择的中成药为8个“中成药”实体所对应的中成药。此外,从“治法”实体还有一个指向“方剂”实体的有向箭头,代表二者之间的关联为该“治法”被选择后,推荐选择的中药方剂为该“方剂”实体所对应的中药方剂。“气虚血瘀证”所对应的治法为“益气活血,补虚止痛”,该治法所对应的治疗手段有2种,第1种是中成药,第2种是中药方剂。该治法推荐选择的中成药有“通心络胶囊”、“通心舒胶囊”、“血栓心脉宁片”等8种,推荐的中药方剂为“八珍汤加味”。从诊疗指南可见,“八珍汤加味”的组成药味有“党参、白术、茯苓、甘草、当归、生地黄、赤芍、川芎、桃仁、红花、丹参”,根据《中华人民共和国药典》[12]和《中药学》[13]的药物功效分类和《方剂学》的内容,除了八珍汤的八味药组和使用具有气血双补的功效外,川芎、桃仁、红花和丹参为活血化瘀药具有活血化瘀的功效。王阶教授根据多年临床研究指出,补气强心为治疗冠心病的第一要义[14],冠心病因其发病率和危害已经成为全球重大公共卫生问题[19],给公共医疗带来很大负担[20]。临床指南作为综合当前最佳研究证据和指导临床实践的文件,是医疗水平稳定的重要保证。《冠心病稳定型心绞痛中医诊疗指南》是由中华中医药学会心血管病分会组织相关专家编撰的。编撰过程参照国际最新的临床指南的制订方法,并在相关法律法规和技术文件指导的框架下,通过辨证论治的数据和关系突出体现了传统中医辨证论治的思想。编撰过程深度结合循证医学原理,在古今文献的回顾分析、临床流行病学调查、中成药系统综述、名老中医经验总结、专家咨询等系统研究工作的基础上,对冠心病稳定型心绞痛的基本证候特点、辨证用药规律等进行了系统地梳理、归纳和总结。《冠心病稳定型心绞痛中医诊疗指南》为中医、中西医结合临床医师规范化开展冠心病的防治工作提供权威指导。选用八珍汤加味能够气血同补兼具活血通络,补气通络之法为王阶教授治疗冠心病的宝贵经验[15]。通过所构建的知识图谱,输入相应的证候类型,即可自动组合出对应的治法,推荐的中成药和中药方剂统数据库中使用的关系模型[9],它将结构化的数据存储在灵活的图网络中而不是表中,更适合表征具有复杂关联的数据及之间的关系,从而在各个行业中得到广泛应用。知识图谱构建和调用过程我们使用Python中的py2neo (https://github.com/py2neo-org/py2neo)来实现。Py2neo是一个Python库和工具包,用于从Python应用程序和命令行中调用或操作Neo4j。其中Node和Relationship这两个对象是py2neo的关键,它们都扩展了Subgraph类,提供了一套全面的图结构数据类型和操作支持,从而在如何调用和操作图数据方面提供了显著的灵活性。1.3 知识图谱概念知识图谱是使用图结构的数据模型或拓扑结构来集成和表示数据的知识库。知识图谱通常用于存储实体(对象、事件、情况或抽象概念)的相互关联的描述,铁路运输设备状态是铁路安全运输的根本,良好的设备状态既是运输生产的物质基础,又是运输安全的重要保证[1]。随着铁路运营里程的积累和铁路设备的更新迭代,积累了大量的铁路运输设备故障数据。这些故障数据记录了故障发生的详细信息,包括故障的基础信息和对故障的人工分析数据,蕴含了铁路运输设备的重要价值信息。科学分析设备故障数据是将故障从消极转变为积极的有效途径,但由于这些故障数据存在存储分散、数据格式不同、存储形式各异的情况,给数据分析带来了困难[2]。知识图谱能够有效地将多源异构数据转化为基于深层语义的知识服务,基于知识图谱技术实现设备故障的深度挖掘和智能应用,是分析铁路运输设备故障数据的有效途径同时还对所用术语背后的语义进行编码[10]。自语义网发展以来,知识图谱往往与关联的开放数据项目相关联,侧重于概念与实体之间的联系的存储和表示。利用知识图谱能够关联核心医学概念及医疗知识,从海量临床医案中对经验和知识进行提炼整理、录入标注和体系构建,以解决优质医疗资源短缺和医疗需求持续增加的矛盾。知识图谱的基本构建流程包括本体构建、实体配置、知识抽取和知识融合等。1.4 知识图谱设计1.4.1 流程设计本研究首先根据诊疗指南中的知识和信息,按照知识图谱构建的方法,从抽象的层面分别定义实体、关系和属性,然后将指南中本研究所需要的结构化数据、半结构化数本研究结合目前中医诊疗经验传承中存在的问题,针对冠心病稳定型心绞痛这个单一病种,提出了一种基于凝结了中医行业专家经验和循证证据所形成的诊疗指南,来构建知识图谱的方法。与一些相关的研究不同的是,该方法没有选择使用基于网络爬虫的大数据来构建知识图谱,而是选择使用规范化、规则化程度较高的中医诊疗指南中的医学知识和术语构建知识图谱并可视化的展示和描述中医诊治冠心病稳定型心绞痛的过程。而知识图谱通过描述实体及其关系来表示语义,知识图谱可以使用本体作为模式层,通过这样的设计,基于知识图谱设计的模型将不仅支持显示知识相关的查询,同时也支持与隐式知识相关的逻辑推理。该方法能够从患者的输入症状出发,经过知识图谱的查询和计算,得到患者可能的证候类型以及应该选择的治法和方剂。这是一种构建中医临床辅助决策系统的有益尝试据和非结构化数据,分别进行整理和提取,形成本研究所需要的数据(包含节点、属性与关系)。在此基础上,我们进行实体消歧、实体对齐等知识融合过程。随后本研究通过Python的py2neo库调用Neo4j,将知识数据导入Neo4j中构建知识图谱。然后通过Python编程将程序构建的基于中医诊疗指南的知识图谱,支持基于图数据库的查询功能。我们以诊疗指南中第一个证候对应的第一个临床表现(胸固定性痛)为例来说明。如查询“临床表现”为“胸固定性痛”,则展示如图6所示的知识图谱。蓝色节点为查询的症状“胸固定性痛”,其对应的“证候要素”为“血瘀”,“血瘀”能够组成“气虚血瘀证”、“气滞血瘀证”、“心血瘀阻证”“痰瘀互结证”4个证型。4个证型又分别对应治法和方剂以及中成药等。从而实现基于中医诊疗指南和专家经验的知识图谱可视化展示过程,为直观地展现中医诊疗过程提供一种新的方式。上述知识图谱的几个模块,即为依据中医诊疗指南进行辨证论治的过程。通过症状(临床表现)的组合文本,提炼出相应的证候要素,在证候要素的基础上组合出相应的证候类型,根据相应的证候类型即可推断相应的治法,确立治法后,即可推荐相应的中成药和中药方剂,并进一步可视化展示中药方剂所用的中药列表。这个过程即模拟了中医辨证论治冠心病稳定型心绞痛的过程,是诊疗指南的可视化和网络化的展示。下面我们将使用知识图谱的查询检索功能进行展示。图5为“证候类型”、“治法”、“中成药”、“方剂”和“中药”的知识图谱示意图。其中橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体,粉色节点代表“方剂”实体,绿色节点代表“中药”实体。联结“证候类型”实体和“治法”实体之间的边表示“证候类型”对应该“治法”,联结“治法”实体和“方剂”实体之间的边表示该“治法”推荐选择该“方剂”,联结“方剂”实体和“中药”实体之间的边表示该“方剂”由该“中药”组成。如图5所示,“气虚血瘀证”所对应的治法为“益气活血,补虚止痛”,该治法所对应的治疗手段中的中药方剂推荐“八珍汤加味”。方剂“八珍汤加味”的组成中药有“党参”、“白术”、“茯苓”、“甘草”、“当归”“红花”“赤芍”等11种。通过所构建的知识图谱,输入相应的证候类型,即可自动组合出对应的治法,推荐中药方剂,以及显示中药方剂所用的中药药味而图2为“临床表现”与“证候要素”知识图谱的示意图。其中蓝色节点代表“临床表现”实体、紫色节点代表“证候要素”实体,从“临床表现”实体指向“证候要素”实体的有向箭头代表二者之间的关联,即“临床表现”中提炼出该“证候要素”,如“神疲”、“乏力”等临床表现,能够相应的提炼出证候要素“气虚”。通过所构建的知识图谱,可输入相应的临床表现,即可自动提炼组合出对应的证候要素且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。多任务学习法。将嵌入模块和推荐模块设计成了相关又分离的任务,将图3为“证候要素”、“证候类型”和“治法”的知识图谱示意图。其中紫色节点代表“证候要素”实体,橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体。从“证候要素”实体指向“证候类型”实体的有向箭头代表二者之间的关联,即“证候要素”组成该“证候类型”。从“证候类型”实体指向“治法”实体的有向箭头代表二者之间的关联,即“证候类型”对应的治法为该“治法”。“气虚”和“阴虚”这2个证候要素,共同组成“气阴两虚证”这一证候类型,而“气阴两虚证”对应的治法为“益气养阴,活血通络”。通过所构建的知识图谱,输入相应的证候要素列表,即可自动组合出对应的证候类型这些任务放在同一个框架中进行交替学习,使用py2neo将诊疗指南中提取整理好的结构化数据导入到Neo4j数据库中,并进而完成基于中医诊疗指南的冠心病知识图谱构建。构建的知识图谱可通过py2neo或用Cypher语句进行查询和调用。因所构建的知识图谱节点较多,并且节点之间的关联复杂,难以在一张图上做清晰的显示,而诊疗指南中,“气虚”证候要素组合为证候类型的组合可能性较多,为了便于展示尽可能多的组合方式和节点关联,以“气虚”这一个证候要素相关的知识图谱为例(包含临床表现、证候要素、证候类型、治法、中成药、方剂和中药等节点及之间的关联),对所构建的知识图谱的节点和关联进行阐述Wang等人[43]提出了MKR模型,Cao等人[44]提出了KTUP模型。典型的例子就是MRK模型。该模型是由KGE模块和推荐模块组成的,将知识图谱以三元组的形式输入KGE模块,通过KGE模块预测出尾实体。用户和项目的特征表示作为推荐模块的输入,通过推荐模块得到项目点击率的估计值。在KGE模块和推荐模块中间有一个交叉特征共享单元,两个模块可以通过该共享单元进行数据交换,这样就可以得到用户的最终表示uL,如公式(6)所示。项目的最终表示vL,如公式(7)所示。其中vL是由L个交叉压缩单元提取的特征,CL是第L层的交叉特征矩阵,Sv表示的是项目v的相关实体集合。公式(8)为预测函数,目的是将用户的最终表示uL和项目的最终表示vL结合起来。知识图谱根据关系连接各实体并生成路径,用户能够通过路径去发现与实体具有关联性的潜在项目,从而获取更加准确的用户偏好。在表3中,汇总出了多领域知识图谱推荐系统基于路径的方法Hete-MF模型只是使用了项目之间的相似度,多方法推荐。不同的推荐方法都有各自的优缺点,当面对不同需求、不同上下文场景时应选择不同的推荐算法。不可能存在一个推荐算法在任何时候下都优于其他算法的情况。所以要充分运用不同推荐算法各自的优势,取长补短,相互融合形成一个强大的推荐框架,而且将多种推荐方法融合,可以有效的提高推荐效果。RippleNet模型、KGCN模型和KGAT模型都是典型的混合模型,它们将基于嵌入和基于路径的方法融合,充分利用了知识图谱中的实体信息和语义关系,实现更精确的推荐。但是多种方法结合也导致了计算量大,模型复杂,系统开销大,推荐速度慢等问题。如何在多方法融合的系统中,针对不同的情况系统可以快速做出推荐响应并尽量降低成本和开销,在未来推荐系统的发展中值得研究Luo等人[47]提出的Hete-CF模型是将用户之间的相似度、项目之间的相似度和用户项目之间的相似度都作为正则化来挖掘用户偏好。与上述模型思想相似的还有HeteRec[48]模型和HeteRec-p[49]模型。由Shi等人[50]提出的SemRec模型与上述的四类模型不同,SemRec模型根据知识图谱中的路径生成一个用户对项目评级的强度矩阵,评级强度矩阵就代表了用户的偏好,模型再根据相似用户的评分,预测推荐系统目标用户对项目的评分,根据评分进行排序,从高到低推荐给用户。公式(17)是用户之间相似度正则化目标函数该模型首先根据用户的交互历史训练出一个关系矩阵给路径中的各跳邻居分配权重,由于知识图谱是由三元组组成的,RippleNet模型根据三元组中的头实体、关系权重以及候选项得出尾实体的权重,计算出多跳邻居和候选项之间的相似度,路径中的每一层用户都会有一个用户表示,最后将每一层的用户表示结合生成用户的最终表示,反映出用户的偏好,计算得到用户的点击概率,根据点击概率给用户做推荐出于对安全性、可靠性等因素的考虑,大量消费者自然而然地流动到医美资源集聚的城市“求美”,“医美旅游”悄然兴起知识图谱是人工智能的重要研究领域,本质是构建和存储不同类型数据的关联性,用图网络来表示知识及其属性和关联,可在一定程度上表征复杂的知识结构和关联,尤其适宜中医领域的知识特点,如尹丹等[2]基于知识图谱,模拟了“方证对应”的诊疗过程。但目前知识图谱相关研究多基于网络爬虫技术批量格式化的爬取大量的医疗相关数据,并基于此数据构建知识图谱[3,4,5]。这类知识图谱普遍存在着数据一致性差,无效数据较多,以及数据缺失严重[6]等问题,生成的知识图谱冗余度[7]较大,对于医疗尤其是临床的实际意义和应用价值有限。中医药临床指南与共识推进了中医药标准化和规范化进程。中华中医药学会心血管病分会发布的《冠心病稳定型心绞痛中医诊疗指南》是基于大量具有独特疗效的中医诊治冠心病稳定型心绞痛临床诊疗经验制定的,能够规范中医诊疗过程和促进提升中医诊疗的整体水平[8],在冠心病稳定型心绞痛的诊疗中具有规范性和权威性。以此为模式实体是本体、实例和关系的整和。比如临床表现“乏力”是本体中的一个概念,“乏力”也是一个具体的临床表现个体,称为实例,其有对应的属性如“分值”和对应的“证候要素”—“气虚”,“乏力”以及本体“症状”和相关的属性,称为“实体”。本研究使用知识图谱常用的三元组数据模型来描述诊疗指南中的知识和知识之间的关系。三元组关系类似于“主谓宾”的关系,表征主语和宾语之间的关联特征。诊疗指南中的数据字段有“临床表现”、“证候要素”、“证候类型”、“治法”、“方剂”、“中成药”和“中药”等。他们之间的关联关系分别为:从“临床表现”提炼“证候要素”,由“证候要素”组成“证候类型”,“证候类型”对应相应的“治法”,依据“治法”选择“方剂”,依据“治法”选择“中成药”,“方剂”包含“中药”。基于上述抽取的本体之间的关系,可设计三元组结构表见表2构建中医冠心病诊疗的知识图谱,对于冠心病中医诊疗的标准化和规范化以及经验的传承具有重要意义。本研究基于知识图谱技术,以《冠心病稳定型心绞痛中医诊疗指南》为模式构建知识图谱,通过编程实现以临床表现的输入调用知识图谱,可视化展示冠心病稳定型心绞痛的中医规范化诊疗过程,以期为直观地展现中医诊疗过程提供了一种可参考的新的范式。1.1数据和知识来源本研究所用到的数据和知识来源于中本体是概念的集合和框架,类似于面相对象程序设计中的类,是知识图谱的架构,也是知识图谱结构化的基础逻辑,将本体整理成相应的结构表,有助于对知识图谱的理解。根据诊疗指南中的本体结构特征,本研究针对诊疗指南进行本体的提取,首先提取“临床表现”、“证候要素”、“证候类型”、“治法”、“方剂(方药)”和“中成药”等,其中“方剂”和“中成药”都可抽象为“治疗手段”,所以将“治疗手段”作为一级本体,而“方剂”和“中成药”作为二级本体。然后根据提取的本体,提取实例,分别为“胸闷痛”、“气虚”、“气滞血瘀”和“冠心2号方”[11]等,最后抽取本体之间的关系,即“临床表现”提炼“证候要素”、“证候要素”组成“证候类型”、“证候类型”对应“治法”等。据此本文设计本体的结构见表1华中医药学会心血管病分会发布的《冠心病稳定型心绞痛中医诊疗指南》[8]。1.2 软件工具本研究的知识图谱使用Neo4j (www.neo4j.com)社区版实现,Neo4j是一个开源的基于java的高性能的NoSQL的图数据库,不同于传图4为“证候类型”、“治法”、“中成药”和“方剂”的知识图谱示意图。其中橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体,深绿色节点代表“中成药”实体,粉色节点代表“方剂”实体。从“证候类型”实体指向“治法”实体的有向箭头代表二者之间的关联,即“证候类型”对应的治法为该“治法”。从“治法”实体指向8个“中成药”实体的有向箭头代表二者之间的关联,即该“治法”被选择后,推荐选择的中成药为8个“中成药”实体所对应的中成药。此外,从“治法”实体还有一个指向“方剂”实体的有向箭头,代表二者之间的关联为该“治法”被选择后,推荐选择的中药方剂为该“方剂”实体所对应的中药方剂。“气虚血瘀证”所对应的治法为“益气活血,补虚止痛”,该治法所对应的治疗手段有2种,第1种是中成药,第2种是中药方剂。该治法推荐选择的中成药有“通心络胶囊”、“通心舒胶囊”、“血栓心脉宁片”等8种,推荐的中药方剂为“八珍汤加味”。从诊疗指南可见,“八珍汤加味”的组成药味有“党参、白术、茯苓、甘草、当归、生地黄、赤芍、川芎、桃仁、红花、丹参”,根据《中华人民共和国药典》[12]和《中药学》[13]的药物功效分类和《方剂学》的内容,除了八珍汤的八味药组和使用具有气血双补的功效外,川芎、桃仁、红花和丹参为活血化瘀药具有活血化瘀的功效。王阶教授根据多年临床研究指出,补气强心为治疗冠心病的第一要义[14],选用八珍汤加味能够气血同补兼具活血通络,补气通络之法为王阶教授治疗冠心病的宝贵经验[15]。通过所构建的知识图谱,输入相应的证候类型,即可自动组合出对应的治法,推荐的中成药和中药方剂统数据库中使用的关系模型[9],它将结构化的数据存储在灵活的图网络中而不是表中,更适合表征具有复杂关联的数据及之间的关系,从而在各个行业中得到广泛应用。知识图谱构建和调用过程我们使用Python中的py2neo (https://github.com/py2neo-org/py2neo)来实现。Py2neo是一个Python库和工具包,用于从Python应用程序和命令行中调用或操作Neo4j。其中Node和Relationship这两个对象是py2neo的关键,它们都扩展了Subgraph类,提供了一套全面的图结构数据类型和操作支持,从而在如何调用和操作图数据方面提供了显著的灵活性。1.3 知识图谱概念知识图谱是使用图结构的数据模型或拓扑结构来集成和表示数据的知识库。知识图谱通常用于存储实体(对象、事件、情况或抽象概念)的相互关联的描述,同时还对所用术语背后的语义进行编码[10]。自语义网发展以来,知识图谱往往与关联的开放数据项目相关联,侧重于概念与实体之间的联系的存储和表示。利用知识图谱能够关联核心医学概念及医疗知识,从海量临床医案中对经验和知识进行提炼整理、录入标注和体系构建,以解决优质医疗资源短缺和医疗需求持续增加的矛盾。知识图谱的基本构建流程包括本体构建、实体配置、知识抽取和知识融合等。1.4 知识图谱设计1.4.1 流程设计本研究首先根据诊疗指南中的知识和信息,按照知识图谱构建的方法,从抽象的层面分别定义实体、关系和属性,然后将指南中本研究所需要的结构化数据、半结构化数据和非结构化数据,分别进行整理和提取,形成本研究所需要的数据(包含节点、属性与关系)。在此基础上,我们进行实体消歧、实体对齐等知识融合过程。随后本研究通过Python的py2neo库调用Neo4j,将知识数据导入Neo4j中构建知识图谱。然后通过Python编程将程序图5为“证候类型”、“治法”、“中成药”、“方剂”和“中药”的知识图谱示意图。其中橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体,粉色节点代表“方剂”实体,绿色节点代表“中药”实体。联结“证候类型”实体和“治法”实体之间的边表示“证候类型”对应该“治法”,联结“治法”实体和“方剂”实体之间的边表示该“治法”推荐选择该“方剂”,联结“方剂”实体和“中药”实体之间的边表示该“方剂”由该“中药”组成。如图5所示,“气虚血瘀证”所对应的治法为“益气活血,补虚止痛”,该治法所对应的治疗手段中的中药方剂推荐“八珍汤加味”。方剂“八珍汤加味”的组成中药有“党参”、“白术”、“茯苓”、“甘草”、“当归”“红花”“赤芍”等11种。通过所构建的知识图谱,输入相应的证候类型,即可自动组合出对应的治法,推荐中药方剂,以及显示中药方剂所用的中药药味而图2为“临床表现”与“证候要素”知识图谱的示意图。其中蓝色节点代表“临床表现”实体、紫色节点代表“证候要素”实体,从“临床表现”实体指向“证候要素”实体的有向箭头代表二者之间的关联,即“临床表现”中提炼出该“证候要素”,如“神疲”、“乏力”等临床表现,能够相应的提炼出证候要素“气虚”。通过所构建的知识图谱,可输入相应的临床表现,即可自动提炼组合出对应的证候要素且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。多任务学习法。将嵌入模块和推荐模块设计成了相关又分离的任务,将图3为“证候要素”、“证候类型”和“治法”的知识图谱示意图。其中紫色节点代表“证候要素”实体,橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体。从“证候要素”实体指向“证候类型”实体的有向箭头代表二者之间的关联,即“证候要素”组成该“证候类型”。从“证候类型”实体指向“治法”实体的有向箭头代表二者之间的关联,即“证候类型”对应的治法为该“治法”。“气虚”和“阴虚”这2个证候要素,共同组成“气阴两虚证”这一证候类型,而“气阴两虚证”对应的治法为“益气养阴,活血通络”。通过所构建的知识图谱,输入相应的证候要素列表,即可自动组合出对应的证候类型这些任务放在同一个框架中进行交替学习,使用py2neo将诊疗指南中提取整理好的结构化数据导入到Neo4j数据库中,并进而完成基于中医诊疗指南的冠心病知识图谱构建。构建的知识图谱可通过py2neo或用Cypher语句进行查询和调用。因所构建的知识图谱节点较多,并且节点之间的关联复杂,难以在一张图上做清晰的显示,而诊疗指南中,“气虚”证候要素组合为证候类型的组合可能性较多,为了便于展示尽可能多的组合方式和节点关联,以“气虚”这一个证候要素相关的知识图谱为例(包含临床表现、证候要素、证候类型、治法、中成药、方剂和中药等节点及之间的关联),对所构建的知识图谱的节点和关联进行阐述Wang等人[43]提出了MKR模型,Cao等人[44]提出了KTUP模型。典型的例子就是MRK模型。该模型是由KGE模块和推荐模块组成的,将知识图谱以三元组的形式输入KGE模块,通过KGE模块预测出尾实体。用户和项目的特征表示作为推荐模块的输入,通过推荐模块得到项目点击率的估计值。在KGE模块和推荐模块中间有一个交叉特征共享单元,两个模块可以通过该共享单元进行数据交换,这样就可以得到用户的最终表示uL,如公式(6)所示。项目的最终表示vL,如公式(7)所示。其中vL是由L个交叉压缩单元提取的特征,CL是第L层的交叉特征矩阵,Sv表示的是项目v的相关实体集合。公式(8)为预测函数,目的是将用户的最终表示uL和项目的最终表示vL结合起来。知识图谱根据关系连接各实体并生成路径,用户能够通过路径去发现与实体具有关联性的潜在项目,从而获取更加准确的用户偏好。在表3中,汇总出了多领域知识图谱推荐系统基于路径的方法Hete-MF模型只是使用了项目之间的相似度,多方法推荐。不同的推荐方法都有各自的优缺点,当面对不同需求、不同上下文场景时应选择不同的推荐算法。不可能存在一个推荐算法在任何时候下都优于其他算法的情况。所以要充分运用不同推荐算法各自的优势,取长补短,相互融合形成一个强大的推荐框架,而且将多种推荐方法融合,可以有效的提高推荐效果。RippleNet模型、KGCN模型和KGAT模型都是典型的混合模型,它们将基于嵌入和基于路径的方法融合,充分利用了知识图谱中的实体信息和语义关系,实现更精确的推荐。但是多种方法结合也导致了计算量大,模型复杂,系统开销大,推荐速度慢等问题。如何在多方法融合的系统中,针对不同的情况系统可以快速做出推荐响应并尽量降低成本和开销,在未来推荐系统的发展中值得研究Luo等人[47]提出的Hete-CF模型是将用户之间的相似度、项目之间的相似度和用户项目之间的相似度都作为正则化来挖掘用户偏好。与上述模型思想相似的还有HeteRec[48]模型和HeteRec-p[49]模型。由Shi等人[50]提出的SemRec模型与上述的四类模型不同,SemRec模型根据知识图谱中的路径生成一个用户对项目评级的强度矩阵,评级强度矩阵就代表了用户的偏好,模型再根据相似用户的评分,预测推荐系统目标用户对项目的评分,根据评分进行排序,从高到低推荐给用户。公式(17)是用户之间相似度正则化目标函数该模型首先根据用户的交互历史训练出一个关系矩阵给路径中的各跳邻居分配权重,由于知识图谱是由三元组组成的,RippleNet模型根据三元组中的头实体、关系权重以及候选项得出尾实体的权重,计算出多跳邻居和候选项之间的相似度,路径中的每一层用户都会有一个用户表示,最后将每一层的用户表示结合生成用户的最终表示,反映出用户的偏好,计算得到用户的点击概率,根据点击概率给用户做推荐出于对安全性、可靠性等因素的考虑,大量消费者自然而然地流动到医美资源集聚的城市“求美”,“医美旅游”悄然兴起知识图谱是人工智能的重要研究领域,本质是构建和存储不同类型数据的关联性,用图网络来表示知识及其属性和关联,可在一定程度上表征复杂的知识结构和关联,尤其适宜中医领域的知识特点,如尹丹等[2]基于知识图谱,模拟了“方证对应”的诊疗过程。但目前知识图谱相关研究多基于网络爬虫技术批量格式化的爬取大量的医疗相关数据,并基于此数据构建知识图谱[3,4,5]。这类知识图谱普遍存在着数据一致性差,无效数据较多,以及数据缺失严重[6]等问题,生成的知识图谱冗余度[7]较大,对于医疗尤其是临床的实际意义和应用价值有限。中医药临床指南与共识推进了中医药标准化和规范化进程。中华中医药学会心血管病分会发布的《冠心病稳定型心绞痛中医诊疗指南》是基于大量具有独特疗效的中医诊治冠心病稳定型心绞痛临床诊疗经验制定的,能够规范中医诊疗过程和促进提升中医诊疗的整体水平[8],在冠心病稳定型心绞痛的诊疗中具有规范性和权威性。以此为模式实体是本体、实例和关系的整和。比如临床表现“乏力”是本体中的一个概念,“乏力”也是一个具体的临床表现个体,称为实例,其有对应的属性如“分值”和对应的“证候要素”—“气虚”,“乏力”以及本体“症状”和相关的属性,称为“实体”。本研究使用知识图谱常用的三元组数据模型来描述诊疗指南中的知识和知识之间的关系。三元组关系类似于“主谓宾”的关系,表征主语和宾语之间的关联特征。诊疗指南中的数据字段有“临床表现”、“证候要素”、“证候类型”、“治法”、“方剂”、“中成药”和“中药”等。他们之间的关联关系分别为:从“临床表现”提炼“证候要素”,由“证候要素”组成“证候类型”,“证候类型”对应相应的“治法”,依据“治法”选择“方剂”,依据“治法”选择“中成药”,“方剂”包含“中药”。基于上述抽取的本体之间的关系,可设计三元组结构表见表2构建中医冠心病诊疗的知识图谱,对于冠心病中医诊疗的标准化和规范化以及经验的传承具有重要意义。本研究基于知识图谱技术,以《冠心病稳定型心绞痛中医诊疗指南》为模式构建知识图谱,通过编程实现以临床表现的输入调用知识图谱,可视化展示冠心病稳定型心绞痛的中医规范化诊疗过程,以期为直观地展现中医诊疗过程提供了一种可参考的新的范式。1.1数据和知识来源本研究所用到的数据和知识来源于中本体是概念的集合和框架,类似于面相对象程序设计中的类,是知识图谱的架构,也是知识图谱结构化的基础逻辑,将本体整理成相应的结构表,有助于对知识图谱的理解。根据诊疗指南中的本体结构特征,本研究针对诊疗指南进行本体的提取,首先提取“临床表现”、“证候要素”、“证候类型”、“治法”、“方剂(方药)”和“中成药”等,其中“方剂”和“中成药”都可抽象为“治疗手段”,所以将“治疗手段”作为一级本体,而“方剂”和“中成药”作为二级本体。然后根据提取的本体,提取实例,分别为“胸闷痛”、“气虚”、“气滞血瘀”和“冠心2号方”[11]等,最后抽取本体之间的关系,即“临床表现”提炼“证候要素”、“证候要素”组成“证候类型”、“证候类型”对应“治法”等。据此本文设计本体的结构见表1华中医药学会心血管病分会发布的《冠心病稳定型心绞痛中医诊疗指南》[8]。1.2 软件工具本研究的知识图谱使用Neo4j (www.neo4j.com)社区版实现,Neo4j是一个开源的基于java的高性能的NoSQL的图数据库,不同于传图4为“证候类型”、“治法”、“中成药”和“方剂”的知识图谱示意图。其中橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体,深绿色节点代表“中成药”实体,粉色节点代表“方剂”实体。从“证候类型”实体指向“治法”实体的有向箭头代表二者之间的关联,即“证候类型”对应的治法为该“治法”。从“治法”实体指向8个“中成药”实体的有向箭头代表二者之间的关联,即该“治法”被选择后,推荐选择的中成药为8个“中成药”实体所对应的中成药。此外,从“治法”实体还有一个指向“方剂”实体的有向箭头,代表二者之间的关联为该“治法”被选择后,推荐选择的中药方剂为该“方剂”实体所对应的中药方剂。“气虚血瘀证”所对应的治法为“益气活血,补虚止痛”,该治法所对应的治疗手段有2种,第1种是中成药,第2种是中药方剂。该治法推荐选择的中成药有“通心络胶囊”、“通心舒胶囊”、“血栓心脉宁片”等8种,推荐的中药方剂为“八珍汤加味”。从诊疗指南可见,“八珍汤加味”的组成药味有“党参、白术、茯苓、甘草、当归、生地黄、赤芍、川芎、桃仁、红花、丹参”,根据《中华人民共和国药典》[12]和《中药学》[13]的药物功效分类和《方剂学》的内容,除了八珍汤的八味药组和使用具有气血双补的功效外,川芎、桃仁、红花和丹参为活血化瘀药具有活血化瘀的功效。王阶教授根据多年临床研究指出,补气强心为治疗冠心病的第一要义[14],冠心病因其发病率和危害已经成为全球重大公共卫生问题[19],给公共医疗带来很大负担[20]。临床指南作为综合当前最佳研究证据和指导临床实践的文件,是医疗水平稳定的重要保证。《冠心病稳定型心绞痛中医诊疗指南》是由中华中医药学会心血管病分会组织相关专家编撰的。编撰过程参照国际最新的临床指南的制订方法,并在相关法律法规和技术文件指导的框架下,通过辨证论治的数据和关系突出体现了传统中医辨证论治的思想。编撰过程深度结合循证医学原理,在古今文献的回顾分析、临床流行病学调查、中成药系统综述、名老中医经验总结、专家咨询等系统研究工作的基础上,对冠心病稳定型心绞痛的基本证候特点、辨证用药规律等进行了系统地梳理、归纳和总结。《冠心病稳定型心绞痛中医诊疗指南》为中医、中西医结合临床医师规范化开展冠心病的防治工作提供权威指导。选用八珍汤加味能够气血同补兼具活血通络,补气通络之法为王阶教授治疗冠心病的宝贵经验[15]。通过所构建的知识图谱,输入相应的证候类型,即可自动组合出对应的治法,推荐的中成药和中药方剂统数据库中使用的关系模型[9],它将结构化的数据存储在灵活的图网络中而不是表中,更适合表征具有复杂关联的数据及之间的关系,从而在各个行业中得到广泛应用。知识图谱构建和调用过程我们使用Python中的py2neo (https://github.com/py2neo-org/py2neo)来实现。Py2neo是一个Python库和工具包,用于从Python应用程序和命令行中调用或操作Neo4j。其中Node和Relationship这两个对象是py2neo的关键,它们都扩展了Subgraph类,提供了一套全面的图结构数据类型和操作支持,从而在如何调用和操作图数据方面提供了显著的灵活性。1.3 知识图谱概念知识图谱是使用图结构的数据模型或拓扑结构来集成和表示数据的知识库。知识图谱通常用于存储实体(对象、事件、情况或抽象概念)的相互关联的描述,同时还对所用术语背后的语义进行编码[10]。自语义网发展以来,知识图谱往往与关联的开放数据项目相关联,侧重于概念与实体之间的联系的存储和表示。利用知识图谱能够关联核心医学概念及医疗知识,从海量临床医案中对经验和知识进行提炼整理、录入标注和体系构建,以解决优质医疗资源短缺和医疗需求持续增加的矛盾。知识图谱的基本构建流程包括本体构建、实体配置、知识抽取和知识融合等。1.4 知识图谱设计1.4.1 流程设计本研究首先根据诊疗指南中的知识和信息,按照知识图谱构建的方法,从抽象的层面分别定义实体、关系和属性,然后将指南中本研究所需要的结构化数据、半结构化数本研究结合目前中医诊疗经验传承中存在的问题,针对冠心病稳定型心绞痛这个单一病种,提出了一种基于凝结了中医行业专家经验和循证证据所形成的诊疗指南,来构建知识图谱的方法。与一些相关的研究不同的是,该方法没有选择使用基于网络爬虫的大数据来构建知识图谱,而是选择使用规范化、规则化程度较高的中医诊疗指南中的医学知识和术语构建知识图谱并可视化的展示和描述中医诊治冠心病稳定型心绞痛的过程。而知识图谱通过描述实体及其关系来表示语义,知识图谱可以使用本体作为模式层,通过这样的设计,基于知识图谱设计的模型将不仅支持显示知识相关的查询,同时也支持与隐式知识相关的逻辑推理。该方法能够从患者的输入症状出发,经过知识图谱的查询和计算,得到患者可能的证候类型以及应该选择的治法和方剂。这是一种构建中医临床辅助决策系统的有益尝试据和非结构化数据,分别进行整理和提取,形成本研究所需要的数据(包含节点、属性与关系)。在此基础上,我们进行实体消歧、实体对齐等知识融合过程。随后本研究通过Python的py2neo库调用Neo4j,将知识数据导入Neo4j中构建知识图谱。然后通过Python编程将程序构建的基于中医诊疗指南的知识图谱,支持基于图数据库的查询功能。我们以诊疗指南中第一个证候对应的第一个临床表现(胸固定性痛)为例来说明。如查询“临床表现”为“胸固定性痛”,则展示如图6所示的知识图谱。蓝色节点为查询的症状“胸固定性痛”,其对应的“证候要素”为“血瘀”,“血瘀”能够组成“气虚血瘀证”、“气滞血瘀证”、“心血瘀阻证”“痰瘀互结证”4个证型。4个证型又分别对应治法和方剂以及中成药等。从而实现基于中医诊疗指南和专家经验的知识图谱可视化展示过程,为直观地展现中医诊疗过程提供一种新的方式。上述知识图谱的几个模块,即为依据中医诊疗指南进行辨证论治的过程。通过症状(临床表现)的组合文本,提炼出相应的证候要素,在证候要素的基础上组合出相应的证候类型,根据相应的证候类型即可推断相应的治法,确立治法后,即可推荐相应的中成药和中药方剂,并进一步可视化展示中药方剂所用的中药列表。这个过程即模拟了中医辨证论治冠心病稳定型心绞痛的过程,是诊疗指南的可视化和网络化的展示。下面我们将使用知识图谱的查询检索功能进行展示。图5为“证候类型”、“治法”、“中成药”、“方剂”和“中药”的知识图谱示意图。其中橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体,粉色节点代表“方剂”实体,绿色节点代表“中药”实体。联结“证候类型”实体和“治法”实体之间的边表示“证候类型”对应该“治法”,联结“治法”实体和“方剂”实体之间的边表示该“治法”推荐选择该“方剂”,联结“方剂”实体和“中药”实体之间的边表示该“方剂”由该“中药”组成。如图5所示,“气虚血瘀证”所对应的治法为“益气活血,补虚止痛”,该治法所对应的治疗手段中的中药方剂推荐“八珍汤加味”。方剂“八珍汤加味”的组成中药有“党参”、“白术”、“茯苓”、“甘草”、“当归”“红花”“赤芍”等11种。通过所构建的知识图谱,输入相应的证候类型,即可自动组合出对应的治法,推荐中药方剂,以及显示中药方剂所用的中药药味而图2为“临床表现”与“证候要素”知识图谱的示意图。其中蓝色节点代表“临床表现”实体、紫色节点代表“证候要素”实体,从“临床表现”实体指向“证候要素”实体的有向箭头代表二者之间的关联,即“临床表现”中提炼出该“证候要素”,如“神疲”、“乏力”等临床表现,能够相应的提炼出证候要素“气虚”。通过所构建的知识图谱,可输入相应的临床表现,即可自动提炼组合出对应的证候要素且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。多任务学习法。将嵌入模块和推荐模块设计成了相关又分离的任务,将图3为“证候要素”、“证候类型”和“治法”的知识图谱示意图。其中紫色节点代表“证候要素”实体,橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体。从“证候要素”实体指向“证候类型”实体的有向箭头代表二者之间的关联,即“证候要素”组成该“证候类型”。从“证候类型”实体指向“治法”实体的有向箭头代表二者之间的关联,即“证候类型”对应的治法为该“治法”。“气虚”和“阴虚”这2个证候要素,共同组成“气阴两虚证”这一证候类型,而“气阴两虚证”对应的治法为“益气养阴,活血通络”。通过所构建的知识图谱,输入相应的证候要素列表,即可自动组合出对应的证候类型这些任务放在同一个框架中进行交替学习,使用py2neo将诊疗指南中提取整理好的结构化数据导入到Neo4j数据库中,并进而完成基于中医诊疗指南的冠心病知识图谱构建。构建的知识图谱可通过py2neo或用Cypher语句进行查询和调用。因所构建的知识图谱节点较多,并且节点之间的关联复杂,难以在一张图上做清晰的显示,而诊疗指南中,“气虚”证候要素组合为证候类型的组合可能性较多,为了便于展示尽可能多的组合方式和节点关联,以“气虚”这一个证候要素相关的知识图谱为例(包含临床表现、证候要素、证候类型、治法、中成药、方剂和中药等节点及之间的关联),对所构建的知识图谱的节点和关联进行阐述Wang等人[43]提出了MKR模型,Cao等人[44]提出了KTUP模型。典型的例子就是MRK模型。该模型是由KGE模块和推荐模块组成的,将知识图谱以三元组的形式输入KGE模块,通过KGE模块预测出尾实体。用户和项目的特征表示作为推荐模块的输入,通过推荐模块得到项目点击率的估计值。在KGE模块和推荐模块中间有一个交叉特征共享单元,两个模块可以通过该共享单元进行数据交换,这样就可以得到用户的最终表示uL,如公式(6)所示。项目的最终表示vL,如公式(7)所示。其中vL是由L个交叉压缩单元提取的特征,CL是第L层的交叉特征矩阵,Sv表示的是项目v的相关实体集合。公式(8)为预测函数,目的是将用户的最终表示uL和项目的最终表示vL结合起来。知识图谱根据关系连接各实体并生成路径,用户能够通过路径去发现与实体具有关联性的潜在项目,从而获取更加准确的用户偏好。在表3中,汇总出了多领域知识图谱推荐系统基于路径的方法Hete-MF模型只是使用了项目之间的相似度,多方法推荐。不同的推荐方法都有各自的优缺点,当面对不同需求、不同上下文场景时应选择不同的推荐算法。不可能存在一个推荐算法在任何时候下都优于其他算法的情况。所以要充分运用不同推荐算法各自的优势,取长补短,相互融合形成一个强大的推荐框架,而且将多种推荐方法融合,可以有效的提高推荐效果。RippleNet模型、KGCN模型和KGAT模型都是典型的混合模型,它们将基于嵌入和基于路径的方法融合,充分利用了知识图谱中的实体信息和语义关系,实现更精确的推荐。但是多种方法结合也导致了计算量大,模型复杂,系统开销大,推荐速度慢等问题。如何在多方法融合的系统中,针对不同的情况系统可以快速做出推荐响应并尽量降低成本和开销,在未来推荐系统的发展中值得研究Luo等人[47]提出的Hete-CF模型是将用户之间的相似度、项目之间的相似度和用户项目之间的相似度都作为正则化来挖掘用户偏好。与上述模型思想相似的还有HeteRec[48]模型和HeteRec-p[49]模型。由Shi等人[50]提出的SemRec模型与上述的四类模型不同,SemRec模型根据知识图谱中的路径生成一个用户对项目评级的强度矩阵,评级强度矩阵就代表了用户的偏好,模型再根据相似用户的评分,预测推荐系统目标用户对项目的评分,根据评分进行排序,从高到低推荐给用户。公式(17)是用户之间相似度正则化目标函数该模型首先根据用户的交互历史训练出一个关系矩阵给路径中的各跳邻居分配权重,由于知识图谱是由三元组组成的,RippleNet模型根据三元组中的头实体、关系权重以及候选项得出尾实体的权重,计算出多跳邻居和候选项之间的相似度,路径中的每一层用户都会有一个用户表示,最后将每一层的用户表示结合生成用户的最终表示,反映出用户的偏好,计算得到用户的点击概率,根据点击概率给用户做推荐出于对安全性、可靠性等因素的考虑,大量消费者自然而然地流动到医美资源集聚的城市“求美”,“医美旅游”悄然兴起知识图谱是人工智能的重要研究领域,本质是构建和存储不同类型数据的关联性,用图网络来表示知识及其属性和关联,可在一定程度上表征复杂的知识结构和关联,尤其适宜中医领域的知识特点,如尹丹等[2]基于知识图谱,模拟了“方证对应”的诊疗过程。但目前知识图谱相关研究多基于网络爬虫技术批量格式化的爬取大量的医疗相关数据,并基于此数据构建知识图谱[3,4,5]。这类知识图谱普遍存在着数据一致性差,无效数据较多,以及数据缺失严重[6]等问题,生成的知识图谱冗余度[7]较大,对于医疗尤其是临床的实际意义和应用价值有限。中医药临床指南与共识推进了中医药标准化和规范化进程。中华中医药学会心血管病分会发布的《冠心病稳定型心绞痛中医诊疗指南》是基于大量具有独特疗效的中医诊治冠心病稳定型心绞痛临床诊疗经验制定的,能够规范中医诊疗过程和促进提升中医诊疗的整体水平[8],在冠心病稳定型心绞痛的诊疗中具有规范性和权威性。以此为模式实体是本体、实例和关系的整和。比如临床表现“乏力”是本体中的一个概念,“乏力”也是一个具体的临床表现个体,称为实例,其有对应的属性如“分值”和对应的“证候要素”—“气虚”,“乏力”以及本体“症状”和相关的属性,称为“实体”。本研究使用知识图谱常用的三元组数据模型来描述诊疗指南中的知识和知识之间的关系。三元组关系类似于“主谓宾”的关系,表征主语和宾语之间的关联特征。诊疗指南中的数据字段有“临床表现”、“证候要素”、“证候类型”、“治法”、“方剂”、“中成药”和“中药”等。他们之间的关联关系分别为:从“临床表现”提炼“证候要素”,由“证候要素”组成“证候类型”,“证候类型”对应相应的“治法”,依据“治法”选择“方剂”,依据“治法”选择“中成药”,“方剂”包含“中药”。基于上述抽取的本体之间的关系,可设计三元组结构表见表2构建中医冠心病诊疗的知识图谱,对于冠心病中医诊疗的标准化和规范化以及经验的传承具有重要意义。本研究基于知识图谱技术,以《冠心病稳定型心绞痛中医诊疗指南》为模式构建知识图谱,通过编程实现以临床表现的输入调用知识图谱,可视化展示冠心病稳定型心绞痛的中医规范化诊疗过程,以期为直观地展现中医诊疗过程提供了一种可参考的新的范式。1.1数据和知识来源本研究所用到的数据和知识来源于中本体是概念的集合和框架,类似于面相对象程序设计中的类,是知识图谱的架构,也是知识图谱结构化的基础逻辑,将本体整理成相应的结构表,有助于对知识图谱的理解。根据诊疗指南中的本体结构特征,本研究针对诊疗指南进行本体的提取,首先提取“临床表现”、“证候要素”、“证候类型”、“治法”、“方剂(方药)”和“中成药”等,其中“方剂”和“中成药”都可抽象为“治疗手段”,所以将“治疗手段”作为一级本体,而“方剂”和“中成药”作为二级本体。然后根据提取的本体,提取实例,分别为“胸闷痛”、“气虚”、“气滞血瘀”和“冠心2号方”[11]等,最后抽取本体之间的关系,即“临床表现”提炼“证候要素”、“证候要素”组成“证候类型”、“证候类型”对应“治法”等。据此本文设计本体的结构见表1华中医药学会心血管病分会发布的《冠心病稳定型心绞痛中医诊疗指南》[8]。1.2 软件工具本研究的知识图谱使用Neo4j (www.neo4j.com)社区版实现,Neo4j是一个开源的基于java的高性能的NoSQL的图数据库,不同于传图4为“证候类型”、“治法”、“中成药”和“方剂”的知识图谱示意图。其中橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体,深绿色节点代表“中成药”实体,粉色节点代表“方剂”实体。从“证候类型”实体指向“治法”实体的有向箭头代表二者之间的关联,即“证候类型”对应的治法为该“治法”。从“治法”实体指向8个“中成药”实体的有向箭头代表二者之间的关联,即该“治法”被选择后,推荐选择的中成药为8个“中成药”实体所对应的中成药。此外,从“治法”实体还有一个指向“方剂”实体的有向箭头,代表二者之间的关联为该“治法”被选择后,推荐选择的中药方剂为该“方剂”实体所对应的中药方剂。“气虚血瘀证”所对应的治法为“益气活血,补虚止痛”,该治法所对应的治疗手段有2种,第1种是中成药,第2种是中药方剂。该治法推荐选择的中成药有“通心络胶囊”、“通心舒胶囊”、“血栓心脉宁片”等8种,推荐的中药方剂为“八珍汤加味”。从诊疗指南可见,“八珍汤加味”的组成药味有“党参、白术、茯苓、甘草、当归、生地黄、赤芍、川芎、桃仁、红花、丹参”,根据《中华人民共和国药典》[12]和《中药学》[13]的药物功效分类和《方剂学》的内容,除了八珍汤的八味药组和使用具有气血双补的功效外,川芎、桃仁、红花和丹参为活血化瘀药具有活血化瘀的功效。王阶教授根据多年临床研究指出,补气强心为治疗冠心病的第一要义[14],选用八珍汤加味能够气血同补兼具活血通络,补气通络之法为王阶教授治疗冠心病的宝贵经验[15]。通过所构建的知识图谱,输入相应的证候类型,即可自动组合出对应的治法,推荐的中成药和中药方剂统数据库中使用的关系模型[9],它将结构化的数据存储在灵活的图网络中而不是表中,更适合表征具有复杂关联的数据及之间的关系,从而在各个行业中得到广泛应用。知识图谱构建和调用过程我们使用Python中的py2neo (https://github.com/py2neo-org/py2neo)来实现。Py2neo是一个Python库和工具包,用于从Python应用程序和命令行中调用或操作Neo4j。其中Node和Relationship这两个对象是py2neo的关键,它们都扩展了Subgraph类,提供了一套全面的图结构数据类型和操作支持,从而在如何调用和操作图数据方面提供了显著的灵活性。1.3 知识图谱概念知识图谱是使用图结构的数据模型或拓扑结构来集成和表示数据的知识库。知识图谱通常用于存储实体(对象、事件、情况或抽象概念)的相互关联的描述,同时还对所用术语背后的语义进行编码[10]。自语义网发展以来,知识图谱往往与关联的开放数据项目相关联,侧重于概念与实体之间的联系的存储和表示。利用知识图谱能够关联核心医学概念及医疗知识,从海量临床医案中对经验和知识进行提炼整理、录入标注和体系构建,以解决优质医疗资源短缺和医疗需求持续增加的矛盾。知识图谱的基本构建流程包括本体构建、实体配置、知识抽取和知识融合等。1.4 知识图谱设计1.4.1 流程设计本研究首先根据诊疗指南中的知识和信息,按照知识图谱构建的方法,从抽象的层面分别定义实体、关系和属性,然后将指南中本研究所需要的结构化数据、半结构化数据和非结构化数据,分别进行整理和提取,形成本研究所需要的数据(包含节点、属性与关系)。在此基础上,我们进行实体消歧、实体对齐等知识融合过程。随后本研究通过Python的py2neo库调用Neo4j,将知识数据导入Neo4j中构建知识图谱。然后通过Python编程将程序图5为“证候类型”、“治法”、“中成药”、“方剂”和“中药”的知识图谱示意图。其中橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体,粉色节点代表“方剂”实体,绿色节点代表“中药”实体。联结“证候类型”实体和“治法”实体之间的边表示“证候类型”对应该“治法”,联结“治法”实体和“方剂”实体之间的边表示该“治法”推荐选择该“方剂”,联结“方剂”实体和“中药”实体之间的边表示该“方剂”由该“中药”组成。如图5所示,“气虚血瘀证”所对应的治法为“益气活血,补虚止痛”,该治法所对应的治疗手段中的中药方剂推荐“八珍汤加味”。方剂“八珍汤加味”的组成中药有“党参”、“白术”、“茯苓”、“甘草”、“当归”“红花”“赤芍”等11种。通过所构建的知识图谱,输入相应的证候类型,即可自动组合出对应的治法,推荐中药方剂,以及显示中药方剂所用的中药药味而图2为“临床表现”与“证候要素”知识图谱的示意图。其中蓝色节点代表“临床表现”实体、紫色节点代表“证候要素”实体,从“临床表现”实体指向“证候要素”实体的有向箭头代表二者之间的关联,即“临床表现”中提炼出该“证候要素”,如“神疲”、“乏力”等临床表现,能够相应的提炼出证候要素“气虚”。通过所构建的知识图谱,可输入相应的临床表现,即可自动提炼组合出对应的证候要素且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。多任务学习法。将嵌入模块和推荐模块设计成了相关又分离的任务,将图3为“证候要素”、“证候类型”和“治法”的知识图谱示意图。其中紫色节点代表“证候要素”实体,橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体。从“证候要素”实体指向“证候类型”实体的有向箭头代表二者之间的关联,即“证候要素”组成该“证候类型”。从“证候类型”实体指向“治法”实体的有向箭头代表二者之间的关联,即“证候类型”对应的治法为该“治法”。“气虚”和“阴虚”这2个证候要素,共同组成“气阴两虚证”这一证候类型,而“气阴两虚证”对应的治法为“益气养阴,活血通络”。通过所构建的知识图谱,输入相应的证候要素列表,即可自动组合出对应的证候类型这些任务放在同一个框架中进行交替学习,使用py2neo将诊疗指南中提取整理好的结构化数据导入到Neo4j数据库中,并进而完成基于中医诊疗指南的冠心病知识图谱构建。构建的知识图谱可通过py2neo或用Cypher语句进行查询和调用。因所构建的知识图谱节点较多,并且节点之间的关联复杂,难以在一张图上做清晰的显示,而诊疗指南中,“气虚”证候要素组合为证候类型的组合可能性较多,为了便于展示尽可能多的组合方式和节点关联,以“气虚”这一个证候要素相关的知识图谱为例(包含临床表现、证候要素、证候类型、治法、中成药、方剂和中药等节点及之间的关联),对所构建的知识图谱的节点和关联进行阐述Wang等人[43]提出了MKR模型,Cao等人[44]提出了KTUP模型。典型的例子就是MRK模型。该模型是由KGE模块和推荐模块组成的,将知识图谱以三元组的形式输入KGE模块,通过KGE模块预测出尾实体。用户和项目的特征表示作为推荐模块的输入,通过推荐模块得到项目点击率的估计值。在KGE模块和推荐模块中间有一个交叉特征共享单元,两个模块可以通过该共享单元进行数据交换,这样就可以得到用户的最终表示uL,如公式(6)所示。项目的最终表示vL,如公式(7)所示。其中vL是由L个交叉压缩单元提取的特征,CL是第L层的交叉特征矩阵,Sv表示的是项目v的相关实体集合。公式(8)为预测函数,目的是将用户的最终表示uL和项目的最终表示vL结合起来。知识图谱根据关系连接各实体并生成路径,用户能够通过路径去发现与实体具有关联性的潜在项目,从而获取更加准确的用户偏好。在表3中,汇总出了多领域知识图谱推荐系统基于路径的方法Hete-MF模型只是使用了项目之间的相似度,多方法推荐。不同的推荐方法都有各自的优缺点,当面对不同需求、不同上下文场景时应选择不同的推荐算法。不可能存在一个推荐算法在任何时候下都优于其他算法的情况。所以要充分运用不同推荐算法各自的优势,取长补短,相互融合形成一个强大的推荐框架,而且将多种推荐方法融合,可以有效的提高推荐效果。RippleNet模型、KGCN模型和KGAT模型都是典型的混合模型,它们将基于嵌入和基于路径的方法融合,充分利用了知识图谱中的实体信息和语义关系,实现更精确的推荐。但是多种方法结合也导致了计算量大,模型复杂,系统开销大,推荐速度慢等问题。如何在多方法融合的系统中,针对不同的情况系统可以快速做出推荐响应并尽量降低成本和开销,在未来推荐系统的发展中值得研究Luo等人[47]提出的Hete-CF模型是将用户之间的相似度、项目之间的相似度和用户项目之间的相似度都作为正则化来挖掘用户偏好。与上述模型思想相似的还有HeteRec[48]模型和HeteRec-p[49]模型。由Shi等人[50]提出的SemRec模型与上述的四类模型不同,SemRec模型根据知识图谱中的路径生成一个用户对项目评级的强度矩阵,评级强度矩阵就代表了用户的偏好,模型再根据相似用户的评分,预测推荐系统目标用户对项目的评分,根据评分进行排序,从高到低推荐给用户。公式(17)是用户之间相似度正则化目标函数该模型首先根据用户的交互历史训练出一个关系矩阵给路径中的各跳邻居分配权重,由于知识图谱是由三元组组成的,RippleNet模型根据三元组中的头实体、关系权重以及候选项得出尾实体的权重,计算出多跳邻居和候选项之间的相似度,路径中的每一层用户都会有一个用户表示,最后将每一层的用户表示结合生成用户的最终表示,反映出用户的偏好,计算得到用户的点击概率,根据点击概率给用户做推荐出于对安全性、可靠性等因素的考虑,大量消费者自然而然地流动到医美资源集聚的城市“求美”,“医美旅游”悄然兴起知识图谱是人工智能的重要研究领域,本质是构建和存储不同类型数据的关联性,用图网络来表示知识及其属性和关联,可在一定程度上表征复杂的知识结构和关联,尤其适宜中医领域的知识特点,如尹丹等[2]基于知识图谱,模拟了“方证对应”的诊疗过程。但目前知识图谱相关研究多基于网络爬虫技术批量格式化的爬取大量的医疗相关数据,并基于此数据构建知识图谱[3,4,5]。这类知识图谱普遍存在着数据一致性差,无效数据较多,以及数据缺失严重[6]等问题,生成的知识图谱冗余度[7]较大,对于医疗尤其是临床的实际意义和应用价值有限。中医药临床指南与共识推进了中医药标准化和规范化进程。中华中医药学会心血管病分会发布的《冠心病稳定型心绞痛中医诊疗指南》是基于大量具有独特疗效的中医诊治冠心病稳定型心绞痛临床诊疗经验制定的,能够规范中医诊疗过程和促进提升中医诊疗的整体水平[8],在冠心病稳定型心绞痛的诊疗中具有规范性和权威性。以此为模式实体是本体、实例和关系的整和。比如临床表现“乏力”是本体中的一个概念,“乏力”也是一个具体的临床表现个体,称为实例,其有对应的属性如“分值”和对应的“证候要素”—“气虚”,“乏力”以及本体“症状”和相关的属性,称为“实体”。本研究使用知识图谱常用的三元组数据模型来描述诊疗指南中的知识和知识之间的关系。三元组关系类似于“主谓宾”的关系,表征主语和宾语之间的关联特征。诊疗指南中的数据字段有“临床表现”、“证候要素”、“证候类型”、“治法”、“方剂”、“中成药”和“中药”等。他们之间的关联关系分别为:从“临床表现”提炼“证候要素”,由“证候要素”组成“证候类型”,“证候类型”对应相应的“治法”,依据“治法”选择“方剂”,依据“治法”选择“中成药”,“方剂”包含“中药”。基于上述抽取的本体之间的关系,可设计三元组结构表见表2构建中医冠心病诊疗的知识图谱,对于冠心病中医诊疗的标准化和规范化以及经验的传承具有重要意义。本研究基于知识图谱技术,以《冠心病稳定型心绞痛中医诊疗指南》为模式构建知识图谱,通过编程实现以临床表现的输入调用知识图谱,可视化展示冠心病稳定型心绞痛的中医规范化诊疗过程,以期为直观地展现中医诊疗过程提供了一种可参考的新的范式。1.1数据和知识来源本研究所用到的数据和知识来源于中本体是概念的集合和框架,类似于面相对象程序设计中的类,是知识图谱的架构,也是知识图谱结构化的基础逻辑,将本体整理成相应的结构表,有助于对知识图谱的理解。根据诊疗指南中的本体结构特征,本研究针对诊疗指南进行本体的提取,首先提取“临床表现”、“证候要素”、“证候类型”、“治法”、“方剂(方药)”和“中成药”等,其中“方剂”和“中成药”都可抽象为“治疗手段”,所以将“治疗手段”作为一级本体,而“方剂”和“中成药”作为二级本体。然后根据提取的本体,提取实例,分别为“胸闷痛”、“气虚”、“气滞血瘀”和“冠心2号方”[11]等,最后抽取本体之间的关系,即“临床表现”提炼“证候要素”、“证候要素”组成“证候类型”、“证候类型”对应“治法”等。据此本文设计本体的结构见表1华中医药学会心血管病分会发布的《冠心病稳定型心绞痛中医诊疗指南》[8]。1.2 软件工具本研究的知识图谱使用Neo4j (www.neo4j.com)社区版实现,Neo4j是一个开源的基于java的高性能的NoSQL的图数据库,不同于传图4为“证候类型”、“治法”、“中成药”和“方剂”的知识图谱示意图。其中橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体,深绿色节点代表“中成药”实体,粉色节点代表“方剂”实体。从“证候类型”实体指向“治法”实体的有向箭头代表二者之间的关联,即“证候类型”对应的治法为该“治法”。从“治法”实体指向8个“中成药”实体的有向箭头代表二者之间的关联,即该“治法”被选择后,推荐选择的中成药为8个“中成药”实体所对应的中成药。此外,从“治法”实体还有一个指向“方剂”实体的有向箭头,代表二者之间的关联为该“治法”被选择后,推荐选择的中药方剂为该“方剂”实体所对应的中药方剂。“气虚血瘀证”所对应的治法为“益气活血,补虚止痛”,该治法所对应的治疗手段有2种,第1种是中成药,第2种是中药方剂。该治法推荐选择的中成药有“通心络胶囊”、“通心舒胶囊”、“血栓心脉宁片”等8种,推荐的中药方剂为“八珍汤加味”。从诊疗指南可见,“八珍汤加味”的组成药味有“党参、白术、茯苓、甘草、当归、生地黄、赤芍、川芎、桃仁、红花、丹参”,根据《中华人民共和国药典》[12]和《中药学》[13]的药物功效分类和《方剂学》的内容,除了八珍汤的八味药组和使用具有气血双补的功效外,川芎、桃仁、红花和丹参为活血化瘀药具有活血化瘀的功效。王阶教授根据多年临床研究指出,补气强心为治疗冠心病的第一要义[14],冠心病因其发病率和危害已经成为全球重大公共卫生问题[19],给公共医疗带来很大负担[20]。临床指南作为综合当前最佳研究证据和指导临床实践的文件,是医疗水平稳定的重要保证。《冠心病稳定型心绞痛中医诊疗指南》是由中华中医药学会心血管病分会组织相关专家编撰的。编撰过程参照国际最新的临床指南的制订方法,并在相关法律法规和技术文件指导的框架下,通过辨证论治的数据和关系突出体现了传统中医辨证论治的思想。编撰过程深度结合循证医学原理,在古今文献的回顾分析、临床流行病学调查、中成药系统综述、名老中医经验总结、专家咨询等系统研究工作的基础上,对冠心病稳定型心绞痛的基本证候特点、辨证用药规律等进行了系统地梳理、归纳和总结。《冠心病稳定型心绞痛中医诊疗指南》为中医、中西医结合临床医师规范化开展冠心病的防治工作提供权威指导。选用八珍汤加味能够气血同补兼具活血通络,补气通络之法为王阶教授治疗冠心病的宝贵经验[15]。通过所构建的知识图谱,输入相应的证候类型,即可自动组合出对应的治法,推荐的中成药和中药方剂统数据库中使用的关系模型[9],它将结构化的数据存储在灵活的图网络中而不是表中,更适合表征具有复杂关联的数据及之间的关系,从而在各个行业中得到广泛应用。知识图谱构建和调用过程我们使用Python中的py2neo (https://github.com/py2neo-org/py2neo)来实现。Py2neo是一个Python库和工具包,用于从Python应用程序和命令行中调用或操作Neo4j。其中Node和Relationship这两个对象是py2neo的关键,它们都扩展了Subgraph类,提供了一套全面的图结构数据类型和操作支持,从而在如何调用和操作图数据方面提供了显著的灵活性。1.3 知识图谱概念知识图谱是使用图结构的数据模型或拓扑结构来集成和表示数据的知识库。知识图谱通常用于存储实体(对象、事件、情况或抽象概念)的相互关联的描述,同时还对所用术语背后的语义进行编码[10]。自语义网发展以来,知识图谱往往与关联的开放数据项目相关联,侧重于概念与实体之间的联系的存储和表示。利用知识图谱能够关联核心医学概念及医疗知识,从海量临床医案中对经验和知识进行提炼整理、录入标注和体系构建,以解决优质医疗资源短缺和医疗需求持续增加的矛盾。知识图谱的基本构建流程包括本体构建、实体配置、知识抽取和知识融合等。1.4 知识图谱设计1.4.1 流程设计本研究首先根据诊疗指南中的知识和信息,按照知识图谱构建的方法,从抽象的层面分别定义实体、关系和属性,然后将指南中本研究所需要的结构化数据、半结构化数本研究结合目前中医诊疗经验传承中存在的问题,针对冠心病稳定型心绞痛这个单一病种,提出了一种基于凝结了中医行业专家经验和循证证据所形成的诊疗指南,来构建知识图谱的方法。与一些相关的研究不同的是,该方法没有选择使用基于网络爬虫的大数据来构建知识图谱,而是选择使用规范化、规则化程度较高的中医诊疗指南中的医学知识和术语构建知识图谱并可视化的展示和描述中医诊治冠心病稳定型心绞痛的过程。而知识图谱通过描述实体及其关系来表示语义,知识图谱可以使用本体作为模式层,通过这样的设计,基于知识图谱设计的模型将不仅支持显示知识相关的查询,同时也支持与隐式知识相关的逻辑推理。该方法能够从患者的输入症状出发,经过知识图谱的查询和计算,得到患者可能的证候类型以及应该选择的治法和方剂。这是一种构建中医临床辅助决策系统的有益尝试据和非结构化数据,分别进行整理和提取,形成本研究所需要的数据(包含节点、属性与关系)。在此基础上,我们进行实体消歧、实体对齐等知识融合过程。随后本研究通过Python的py2neo库调用Neo4j,将知识数据导入Neo4j中构建知识图谱。然后通过Python编程将程序构建的基于中医诊疗指南的知识图谱,支持基于图数据库的查询功能。我们以诊疗指南中第一个证候对应的第一个临床表现(胸固定性痛)为例来说明。如查询“临床表现”为“胸固定性痛”,则展示如图6所示的知识图谱。蓝色节点为查询的症状“胸固定性痛”,其对应的“证候要素”为“血瘀”,“血瘀”能够组成“气虚血瘀证”、“气滞血瘀证”、“心血瘀阻证”“痰瘀互结证”4个证型。4个证型又分别对应治法和方剂以及中成药等。从而实现基于中医诊疗指南和专家经验的知识图谱可视化展示过程,为直观地展现中医诊疗过程提供一种新的方式。上述知识图谱的几个模块,即为依据中医诊疗指南进行辨证论治的过程。通过症状(临床表现)的组合文本,提炼出相应的证候要素,在证候要素的基础上组合出相应的证候类型,根据相应的证候类型即可推断相应的治法,确立治法后,即可推荐相应的中成药和中药方剂,并进一步可视化展示中药方剂所用的中药列表。这个过程即模拟了中医辨证论治冠心病稳定型心绞痛的过程,是诊疗指南的可视化和网络化的展示。下面我们将使用知识图谱的查询检索功能进行展示。图5为“证候类型”、“治法”、“中成药”、“方剂”和“中药”的知识图谱示意图。其中橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体,粉色节点代表“方剂”实体,绿色节点代表“中药”实体。联结“证候类型”实体和“治法”实体之间的边表示“证候类型”对应该“治法”,联结“治法”实体和“方剂”实体之间的边表示该“治法”推荐选择该“方剂”,联结“方剂”实体和“中药”实体之间的边表示该“方剂”由该“中药”组成。如图5所示,“气虚血瘀证”所对应的治法为“益气活血,补虚止痛”,该治法所对应的治疗手段中的中药方剂推荐“八珍汤加味”。方剂“八珍汤加味”的组成中药有“党参”、“白术”、“茯苓”、“甘草”、“当归”“红花”“赤芍”等11种。通过所构建的知识图谱,输入相应的证候类型,即可自动组合出对应的治法,推荐中药方剂,以及显示中药方剂所用的中药药味而图2为“临床表现”与“证候要素”知识图谱的示意图。其中蓝色节点代表“临床表现”实体、紫色节点代表“证候要素”实体,从“临床表现”实体指向“证候要素”实体的有向箭头代表二者之间的关联,即“临床表现”中提炼出该“证候要素”,如“神疲”、“乏力”等临床表现,能够相应的提炼出证候要素“气虚”。通过所构建的知识图谱,可输入相应的临床表现,即可自动提炼组合出对应的证候要素且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。多任务学习法。将嵌入模块和推荐模块设计成了相关又分离的任务,将图3为“证候要素”、“证候类型”和“治法”的知识图谱示意图。其中紫色节点代表“证候要素”实体,橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体。从“证候要素”实体指向“证候类型”实体的有向箭头代表二者之间的关联,即“证候要素”组成该“证候类型”。从“证候类型”实体指向“治法”实体的有向箭头代表二者之间的关联,即“证候类型”对应的治法为该“治法”。“气虚”和“阴虚”这2个证候要素,共同组成“气阴两虚证”这一证候类型,而“气阴两虚证”对应的治法为“益气养阴,活血通络”。通过所构建的知识图谱,输入相应的证候要素列表,即可自动组合出对应的证候类型这些任务放在同一个框架中进行交替学习,使用py2neo将诊疗指南中提取整理好的结构化数据导入到Neo4j数据库中,并进而完成基于中医诊疗指南的冠心病知识图谱构建。构建的知识图谱可通过py2neo或用Cypher语句进行查询和调用。因所构建的知识图谱节点较多,并且节点之间的关联复杂,难以在一张图上做清晰的显示,而诊疗指南中,“气虚”证候要素组合为证候类型的组合可能性较多,为了便于展示尽可能多的组合方式和节点关联,以“气虚”这一个证候要素相关的知识图谱为例(包含临床表现、证候要素、证候类型、治法、中成药、方剂和中药等节点及之间的关联),对所构建的知识图谱的节点和关联进行阐述Wang等人[43]提出了MKR模型,Cao等人[44]提出了KTUP模型。典型的例子就是MRK模型。该模型是由KGE模块和推荐模块组成的,将知识图谱以三元组的形式输入KGE模块,通过KGE模块预测出尾实体。用户和项目的特征表示作为推荐模块的输入,通过推荐模块得到项目点击率的估计值。在KGE模块和推荐模块中间有一个交叉特征共享单元,两个模块可以通过该共享单元进行数据交换,这样就可以得到用户的最终表示uL,如公式(6)所示。项目的最终表示vL,如公式(7)所示。其中vL是由L个交叉压缩单元提取的特征,CL是第L层的交叉特征矩阵,Sv表示的是项目v的相关实体集合。公式(8)为预测函数,目的是将用户的最终表示uL和项目的最终表示vL结合起来。知识图谱根据关系连接各实体并生成路径,用户能够通过路径去发现与实体具有关联性的潜在项目,从而获取更加准确的用户偏好。在表3中,汇总出了多领域知识图谱推荐系统基于路径的方法Hete-MF模型只是使用了项目之间的相似度,多方法推荐。不同的推荐方法都有各自的优缺点,当面对不同需求、不同上下文场景时应选择不同的推荐算法。不可能存在一个推荐算法在任何时候下都优于其他算法的情况。所以要充分运用不同推荐算法各自的优势,取长补短,相互融合形成一个强大的推荐框架,而且将多种推荐方法融合,可以有效的提高推荐效果。RippleNet模型、KGCN模型和KGAT模型都是典型的混合模型,它们将基于嵌入和基于路径的方法融合,充分利用了知识图谱中的实体信息和语义关系,实现更精确的推荐。但是多种方法结合也导致了计算量大,模型复杂,系统开销大,推荐速度慢等问题。如何在多方法融合的系统中,针对不同的情况系统可以快速做出推荐响应并尽量降低成本和开销,在未来推荐系统的发展中值得研究Luo等人[47]提出的Hete-CF模型是将用户之间的相似度、项目之间的相似度和用户项目之间的相似度都作为正则化来挖掘用户偏好。与上述模型思想相似的还有HeteRec[48]模型和HeteRec-p[49]模型。由Shi等人[50]提出的SemRec模型与上述的四类模型不同,SemRec模型根据知识图谱中的路径生成一个用户对项目评级的强度矩阵,评级强度矩阵就代表了用户的偏好,模型再根据相似用户的评分,预测推荐系统目标用户对项目的评分,根据评分进行排序,从高到低推荐给用户。公式(17)是用户之间相似度正则化目标函数该模型首先根据用户的交互历史训练出一个关系矩阵给路径中的各跳邻居分配权重,由于知识图谱是由三元组组成的,RippleNet模型根据三元组中的头实体、关系权重以及候选项得出尾实体的权重,计算出多跳邻居和候选项之间的相似度,路径中的每一层用户都会有一个用户表示,最后将每一层的用户表示结合生成用户的最终表示,反映出用户的偏好,计算得到用户的点击概率,根据点击概率给用户做推荐出于对安全性、可靠性等因素的考虑,大量消费者自然而然地流动到医美资源集聚的城市“求美”,“医美旅游”悄然兴起知识图谱是人工智能的重要研究领域,本质是构建和存储不同类型数据的关联性,用图网络来表示知识及其属性和关联,可在一定程度上表征复杂的知识结构和关联,尤其适宜中医领域的知识特点,如尹丹等[2]基于知识图谱,模拟了“方证对应”的诊疗过程。但目前知识图谱相关研究多基于网络爬虫技术批量格式化的爬取大量的医疗相关数据,并基于此数据构建知识图谱[3,4,5]。这类知识图谱普遍存在着数据一致性差,无效数据较多,以及数据缺失严重[6]等问题,生成的知识图谱冗余度[7]较大,对于医疗尤其是临床的实际意义和应用价值有限。中医药临床指南与共识推进了中医药标准化和规范化进程。中华中医药学会心血管病分会发布的《冠心病稳定型心绞痛中医诊疗指南》是基于大量具有独特疗效的中医诊治冠心病稳定型心绞痛临床诊疗经验制定的,能够规范中医诊疗过程和促进提升中医诊疗的整体水平[8],在冠心病稳定型心绞痛的诊疗中具有规范性和权威性。以此为模式实体是本体、实例和关系的整和。比如临床表现“乏力”是本体中的一个概念,“乏力”也是一个具体的临床表现个体,称为实例,其有对应的属性如“分值”和对应的“证候要素”—“气虚”,“乏力”以及本体“症状”和相关的属性,称为“实体”。本研究使用知识图谱常用的三元组数据模型来描述诊疗指南中的知识和知识之间的关系。三元组关系类似于“主谓宾”的关系,表征主语和宾语之间的关联特征。诊疗指南中的数据字段有“临床表现”、“证候要素”、“证候类型”、“治法”、“方剂”、“中成药”和“中药”等。他们之间的关联关系分别为:从“临床表现”提炼“证候要素”,由“证候要素”组成“证候类型”,“证候类型”对应相应的“治法”,依据“治法”选择“方剂”,依据“治法”选择“中成药”,“方剂”包含“中药”。基于上述抽取的本体之间的关系,可设计三元组结构表见表2构建中医冠心病诊疗的知识图谱,对于冠心病中医诊疗的标准化和规范化以及经验的传承具有重要意义。本研究基于知识图谱技术,以《冠心病稳定型心绞痛中医诊疗指南》为模式构建知识图谱,通过编程实现以临床表现的输入调用知识图谱,可视化展示冠心病稳定型心绞痛的中医规范化诊疗过程,以期为直观地展现中医诊疗过程提供了一种可参考的新的范式。1.1数据和知识来源本研究所用到的数据和知识来源于中本体是概念的集合和框架,类似于面相对象程序设计中的类,是知识图谱的架构,也是知识图谱结构化的基础逻辑,将本体整理成相应的结构表,有助于对知识图谱的理解。根据诊疗指南中的本体结构特征,本研究针对诊疗指南进行本体的提取,首先提取“临床表现”、“证候要素”、“证候类型”、“治法”、“方剂(方药)”和“中成药”等,其中“方剂”和“中成药”都可抽象为“治疗手段”,所以将“治疗手段”作为一级本体,而“方剂”和“中成药”作为二级本体。然后根据提取的本体,提取实例,分别为“胸闷痛”、“气虚”、“气滞血瘀”和“冠心2号方”[11]等,最后抽取本体之间的关系,即“临床表现”提炼“证候要素”、“证候要素”组成“证候类型”、“证候类型”对应“治法”等。据此本文设计本体的结构见表1华中医药学会心血管病分会发布的《冠心病稳定型心绞痛中医诊疗指南》[8]。1.2 软件工具本研究的知识图谱使用Neo4j (www.neo4j.com)社区版实现,Neo4j是一个开源的基于java的高性能的NoSQL的图数据库,不同于传图4为“证候类型”、“治法”、“中成药”和“方剂”的知识图谱示意图。其中橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体,深绿色节点代表“中成药”实体,粉色节点代表“方剂”实体。从“证候类型”实体指向“治法”实体的有向箭头代表二者之间的关联,即“证候类型”对应的治法为该“治法”。从“治法”实体指向8个“中成药”实体的有向箭头代表二者之间的关联,即该“治法”被选择后,推荐选择的中成药为8个“中成药”实体所对应的中成药。此外,从“治法”实体还有一个指向“方剂”实体的有向箭头,代表二者之间的关联为该“治法”被选择后,推荐选择的中药方剂为该“方剂”实体所对应的中药方剂。“气虚血瘀证”所对应的治法为“益气活血,补虚止痛”,该治法所对应的治疗手段有2种,第1种是中成药,第2种是中药方剂。该治法推荐选择的中成药有“通心络胶囊”、“通心舒胶囊”、“血栓心脉宁片”等8种,推荐的中药方剂为“八珍汤加味”。从诊疗指南可见,“八珍汤加味”的组成药味有“党参、白术、茯苓、甘草、当归、生地黄、赤芍、川芎、桃仁、红花、丹参”,根据《中华人民共和国药典》[12]和《中药学》[13]的药物功效分类和《方剂学》的内容,除了八珍汤的八味药组和使用具有气血双补的功效外,川芎、桃仁、红花和丹参为活血化瘀药具有活血化瘀的功效。王阶教授根据多年临床研究指出,补气强心为治疗冠心病的第一要义[14],选用八珍汤加味能够气血同补兼具活血通络,补气通络之法为王阶教授治疗冠心病的宝贵经验[15]。通过所构建的知识图谱,输入相应的证候类型,即可自动组合出对应的治法,推荐的中成药和中药方剂统数据库中使用的关系模型[9],它将结构化的数据存储在灵活的图网络中而不是表中,更适合表征具有复杂关联的数据及之间的关系,从而在各个行业中得到广泛应用。知识图谱构建和调用过程我们使用Python中的py2neo (https://github.com/py2neo-org/py2neo)来实现。Py2neo是一个Python库和工具包,用于从Python应用程序和命令行中调用或操作Neo4j。其中Node和Relationship这两个对象是py2neo的关键,它们都扩展了Subgraph类,提供了一套全面的图结构数据类型和操作支持,从而在如何调用和操作图数据方面提供了显著的灵活性。1.3 知识图谱概念知识图谱是使用图结构的数据模型或拓扑结构来集成和表示数据的知识库。知识图谱通常用于存储实体(对象、事件、情况或抽象概念)的相互关联的描述,同时还对所用术语背后的语义进行编码[10]。自语义网发展以来,知识图谱往往与关联的开放数据项目相关联,侧重于概念与实体之间的联系的存储和表示。利用知识图谱能够关联核心医学概念及医疗知识,从海量临床医案中对经验和知识进行提炼整理、录入标注和体系构建,以解决优质医疗资源短缺和医疗需求持续增加的矛盾。知识图谱的基本构建流程包括本体构建、实体配置、知识抽取和知识融合等。1.4 知识图谱设计1.4.1 流程设计本研究首先根据诊疗指南中的知识和信息,按照知识图谱构建的方法,从抽象的层面分别定义实体、关系和属性,然后将指南中本研究所需要的结构化数据、半结构化数据和非结构化数据,分别进行整理和提取,形成本研究所需要的数据(包含节点、属性与关系)。在此基础上,我们进行实体消歧、实体对齐等知识融合过程。随后本研究通过Python的py2neo库调用Neo4j,将知识数据导入Neo4j中构建知识图谱。然后通过Python编程将程序图5为“证候类型”、“治法”、“中成药”、“方剂”和“中药”的知识图谱示意图。其中橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体,粉色节点代表“方剂”实体,绿色节点代表“中药”实体。联结“证候类型”实体和“治法”实体之间的边表示“证候类型”对应该“治法”,联结“治法”实体和“方剂”实体之间的边表示该“治法”推荐选择该“方剂”,联结“方剂”实体和“中药”实体之间的边表示该“方剂”由该“中药”组成。如图5所示,“气虚血瘀证”所对应的治法为“益气活血,补虚止痛”,该治法所对应的治疗手段中的中药方剂推荐“八珍汤加味”。方剂“八珍汤加味”的组成中药有“党参”、“白术”、“茯苓”、“甘草”、“当归”“红花”“赤芍”等11种。通过所构建的知识图谱,输入相应的证候类型,即可自动组合出对应的治法,推荐中药方剂,以及显示中药方剂所用的中药药味而图2为“临床表现”与“证候要素”知识图谱的示意图。其中蓝色节点代表“临床表现”实体、紫色节点代表“证候要素”实体,从“临床表现”实体指向“证候要素”实体的有向箭头代表二者之间的关联,即“临床表现”中提炼出该“证候要素”,如“神疲”、“乏力”等临床表现,能够相应的提炼出证候要素“气虚”。通过所构建的知识图谱,可输入相应的临床表现,即可自动提炼组合出对应的证候要素且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。多任务学习法。将嵌入模块和推荐模块设计成了相关又分离的任务,将图3为“证候要素”、“证候类型”和“治法”的知识图谱示意图。其中紫色节点代表“证候要素”实体,橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体。从“证候要素”实体指向“证候类型”实体的有向箭头代表二者之间的关联,即“证候要素”组成该“证候类型”。从“证候类型”实体指向“治法”实体的有向箭头代表二者之间的关联,即“证候类型”对应的治法为该“治法”。“气虚”和“阴虚”这2个证候要素,共同组成“气阴两虚证”这一证候类型,而“气阴两虚证”对应的治法为“益气养阴,活血通络”。通过所构建的知识图谱,输入相应的证候要素列表,即可自动组合出对应的证候类型这些任务放在同一个框架中进行交替学习,使用py2neo将诊疗指南中提取整理好的结构化数据导入到Neo4j数据库中,并进而完成基于中医诊疗指南的冠心病知识图谱构建。构建的知识图谱可通过py2neo或用Cypher语句进行查询和调用。因所构建的知识图谱节点较多,并且节点之间的关联复杂,难以在一张图上做清晰的显示,而诊疗指南中,“气虚”证候要素组合为证候类型的组合可能性较多,为了便于展示尽可能多的组合方式和节点关联,以“气虚”这一个证候要素相关的知识图谱为例(包含临床表现、证候要素、证候类型、治法、中成药、方剂和中药等节点及之间的关联),对所构建的知识图谱的节点和关联进行阐述Wang等人[43]提出了MKR模型,Cao等人[44]提出了KTUP模型。典型的例子就是MRK模型。该模型是由KGE模块和推荐模块组成的,将知识图谱以三元组的形式输入KGE模块,通过KGE模块预测出尾实体。用户和项目的特征表示作为推荐模块的输入,通过推荐模块得到项目点击率的估计值。在KGE模块和推荐模块中间有一个交叉特征共享单元,两个模块可以通过该共享单元进行数据交换,这样就可以得到用户的最终表示uL,如公式(6)所示。项目的最终表示vL,如公式(7)所示。其中vL是由L个交叉压缩单元提取的特征,CL是第L层的交叉特征矩阵,Sv表示的是项目v的相关实体集合。公式(8)为预测函数,目的是将用户的最终表示uL和项目的最终表示vL结合起来。知识图谱根据关系连接各实体并生成路径,用户能够通过路径去发现与实体具有关联性的潜在项目,从而获取更加准确的用户偏好。在表3中,汇总出了多领域知识图谱推荐系统基于路径的方法Hete-MF模型只是使用了项目之间的相似度,多方法推荐。不同的推荐方法都有各自的优缺点,当面对不同需求、不同上下文场景时应选择不同的推荐算法。不可能存在一个推荐算法在任何时候下都优于其他算法的情况。所以要充分运用不同推荐算法各自的优势,取长补短,相互融合形成一个强大的推荐框架,而且将多种推荐方法融合,可以有效的提高推荐效果。RippleNet模型、KGCN模型和KGAT模型都是典型的混合模型,它们将基于嵌入和基于路径的方法融合,充分利用了知识图谱中的实体信息和语义关系,实现更精确的推荐。但是多种方法结合也导致了计算量大,模型复杂,系统开销大,推荐速度慢等问题。如何在多方法融合的系统中,针对不同的情况系统可以快速做出推荐响应并尽量降低成本和开销,在未来推荐系统的发展中值得研究Luo等人[47]提出的Hete-CF模型是将用户之间的相似度、项目之间的相似度和用户项目之间的相似度都作为正则化来挖掘用户偏好。与上述模型思想相似的还有HeteRec[48]模型和HeteRec-p[49]模型。由Shi等人[50]提出的SemRec模型与上述的四类模型不同,SemRec模型根据知识图谱中的路径生成一个用户对项目评级的强度矩阵,评级强度矩阵就代表了用户的偏好,模型再根据相似用户的评分,预测推荐系统目标用户对项目的评分,根据评分进行排序,从高到低推荐给用户。公式(17)是用户之间相似度正则化目标函数该模型首先根据用户的交互历史训练出一个关系矩阵给路径中的各跳邻居分配权重,由于知识图谱是由三元组组成的,RippleNet模型根据三元组中的头实体、关系权重以及候选项得出尾实体的权重,计算出多跳邻居和候选项之间的相似度,路径中的每一层用户都会有一个用户表示,最后将每一层的用户表示结合生成用户的最终表示,反映出用户的偏好,计算得到用户的点击概率,根据点击概率给用户做推荐出于对安全性、可靠性等因素的考虑,大量消费者自然而然地流动到医美资源集聚的城市“求美”,“医美旅游”悄然兴起知识图谱是人工智能的重要研究领域,本质是构建和存储不同类型数据的关联性,用图网络来表示知识及其属性和关联,可在一定程度上表征复杂的知识结构和关联,尤其适宜中医领域的知识特点,如尹丹等[2]基于知识图谱,模拟了“方证对应”的诊疗过程。但目前知识图谱相关研究多基于网络爬虫技术批量格式化的爬取大量的医疗相关数据,并基于此数据构建知识图谱[3,4,5]。这类知识图谱普遍存在着数据一致性差,无效数据较多,以及数据缺失严重[6]等问题,生成的知识图谱冗余度[7]较大,对于医疗尤其是临床的实际意义和应用价值有限。中医药临床指南与共识推进了中医药标准化和规范化进程。中华中医药学会心血管病分会发布的《冠心病稳定型心绞痛中医诊疗指南》是基于大量具有独特疗效的中医诊治冠心病稳定型心绞痛临床诊疗经验制定的,能够规范中医诊疗过程和促进提升中医诊疗的整体水平[8],在冠心病稳定型心绞痛的诊疗中具有规范性和权威性。以此为模式实体是本体、实例和关系的整和。比如临床表现“乏力”是本体中的一个概念,“乏力”也是一个具体的临床表现个体,称为实例,其有对应的属性如“分值”和对应的“证候要素”—“气虚”,“乏力”以及本体“症状”和相关的属性,称为“实体”。本研究使用知识图谱常用的三元组数据模型来描述诊疗指南中的知识和知识之间的关系。三元组关系类似于“主谓宾”的关系,表征主语和宾语之间的关联特征。诊疗指南中的数据字段有“临床表现”、“证候要素”、“证候类型”、“治法”、“方剂”、“中成药”和“中药”等。他们之间的关联关系分别为:从“临床表现”提炼“证候要素”,由“证候要素”组成“证候类型”,“证候类型”对应相应的“治法”,依据“治法”选择“方剂”,依据“治法”选择“中成药”,“方剂”包含“中药”。基于上述抽取的本体之间的关系,可设计三元组结构表见表2构建中医冠心病诊疗的知识图谱,对于冠心病中医诊疗的标准化和规范化以及经验的传承具有重要意义。本研究基于知识图谱技术,以《冠心病稳定型心绞痛中医诊疗指南》为模式构建知识图谱,通过编程实现以临床表现的输入调用知识图谱,可视化展示冠心病稳定型心绞痛的中医规范化诊疗过程,以期为直观地展现中医诊疗过程提供了一种可参考的新的范式。1.1数据和知识来源本研究所用到的数据和知识来源于中本体是概念的集合和框架,类似于面相对象程序设计中的类,是知识图谱的架构,也是知识图谱结构化的基础逻辑,将本体整理成相应的结构表,有助于对知识图谱的理解。根据诊疗指南中的本体结构特征,本研究针对诊疗指南进行本体的提取,首先提取“临床表现”、“证候要素”、“证候类型”、“治法”、“方剂(方药)”和“中成药”等,其中“方剂”和“中成药”都可抽象为“治疗手段”,所以将“治疗手段”作为一级本体,而“方剂”和“中成药”作为二级本体。然后根据提取的本体,提取实例,分别为“胸闷痛”、“气虚”、“气滞血瘀”和“冠心2号方”[11]等,最后抽取本体之间的关系,即“临床表现”提炼“证候要素”、“证候要素”组成“证候类型”、“证候类型”对应“治法”等。据此本文设计本体的结构见表1华中医药学会心血管病分会发布的《冠心病稳定型心绞痛中医诊疗指南》[8]。1.2 软件工具本研究的知识图谱使用Neo4j (www.neo4j.com)社区版实现,Neo4j是一个开源的基于java的高性能的NoSQL的图数据库,不同于传图4为“证候类型”、“治法”、“中成药”和“方剂”的知识图谱示意图。其中橘黄色节点代表“证候类型”实体,灰色节点代表“治法”实体,深绿色节点代表“中成药”实体,粉色节点代表“方剂”实体。从“证候类型”实体指向“治法”实体的有向箭头代表二者之间的关联,即“证候类型”对应的治法为该“治法”。从“治法”实体指向8个“中成药”实体的有向箭头代表二者之间的关联,即该“治法”被选择后,推荐选择的中成药为8个“中成药”实体所对应的中成药。此外,从“治法”实体还有一个指向“方剂”实体的有向箭头,代表二者之间的关联为该“治法”被选择后,推荐选择的中药方剂为该“方剂”实体所对应的中药方剂。“气虚血瘀证”所对应的治法为“益气活血,补虚止痛”,该治法所对应的治疗手段有2种,第1种是中成药,第2种是中药方剂。该治法推荐选择的中成药有“通心络胶囊”、“通心舒胶囊”、“血栓心脉宁片”等8种,推荐的中药方剂为“八珍汤加味”。从诊疗指南可见,“八珍汤加味”的组成药味有“党参、白术、茯苓、甘草、当归、生地黄、赤芍、川芎、桃仁、红花、丹参”,根据《中华人民共和国药典》[12]和《中药学》[13]的药物功效分类和《方剂学》的内容,除了八珍汤的八味药组和使用具有气血双补的功效外,川芎、桃仁、红花和丹参为活血化瘀药具有活血化瘀的功效。王阶教授根据多年临床研究指出,补气强心为治疗冠心病的第一要义[14],冠心病因其发病率和危害已经成为全球重大公共卫生问题[19],给公共医疗带来很大负担[20]。临床指南作为综合当前最佳研究证据和指导临床实践的文件,是医疗水平稳定的重要保证。《冠心病稳定型心绞痛中医诊疗指南》是由中华中医药学会心血管病分会组织相关专家编撰的。编撰过程参照国际最新的临床指南的制订方法,并在相关法律法规和技术文件指导的框架下,通过辨证论治的数据和关系突出体现了传统中医辨证论治的思想。编撰过程深度结合循证医学原理,在古今文献的回顾分析、临床流行病学调查、中成药系统综述、名老中医经验总结、专家咨询等系统研究工作的基础上,对冠心病稳定型心绞痛的基本证候特点、辨证用药规律等进行了系统地梳理、归纳和总结。《冠心病稳定型心绞痛中医诊疗指南》为中医、中西医结合临床医师规范化开展冠心病的防治工作提供权威指导。选用八珍汤加味能够气血同补兼具活血通络,补气通络之法为王阶教授治疗冠心病的宝贵经验[15]。通过所构建的知识图谱,输入相应的证候类型,即可自动组合出对应的治法,推荐的中成药和中药方剂统数据库中使用的关系模型[9],它将结构化的数据存储在灵活的图网络中而不是表中,更适合表征具有复杂关联的数据及之间的关系,从而在各个行业中得到广泛应用。知识图谱构建和调用过程我们使用Python中的py2neo (https://github.com/py2neo-org/py2neo)来实现。Py2neo是一个Python库和工具包,用于从Python应用程序和命令行中调用或操作Neo4j。其中Node和Relationship这两个对象是py2neo的关键,它们都扩展了Subgraph类,提供了一套全面的图结构数据类型和操作支持,从而在如何调用和操作图数据方面提供了显著的灵活性。1.3 知识图谱概念知识图谱是使用图结构的数据模型或拓扑结构来集成和表示数据的知识库。知识图谱通常用于存储实体(对象、事件、情况或抽象概念)的相互关联的描述,同时还对所用术语背后的语义进行编码[10]。自语义网发展以来,知识图谱往往与关联的开放数据项目相关联,侧重于概念与实体之间的联系的存储和表示。利用知识图谱能够关联核心医学概念及医疗知识,从海量临床医案中对经验和知识进行提炼整理、录入标注和体系构建,以解决优质医疗资源短缺和医疗需求持续增加的矛盾。知识图谱的基本构建流程包括本体构建、实体配置、知识抽取和知识融合等。1.4 知识图谱设计1.4.1 流程设计本研究首先根据诊疗指南中的知识和信息,按照知识图谱构建的方法,从抽象的层面分别定义实体、关系和属性,然后将指南中本研究所需要的结构化数据、半结构化数本研究结合目前中医诊疗经验传承中存在的问题,针对冠心病稳定型心绞痛这个单一病种,提出了一种基于凝结了中医行业专家经验和循证证据所形成的诊疗指南,来构建知识图谱的方法。与一些相关的研究不同的是,该方法没有选择使用基于网络爬虫的大数据来构建知识图谱,而是选择使用规范化、规则化程度较高的中医诊疗指南中的医学知识和术语构建知识图谱并可视化的展示和描述中医诊治冠心病稳定型心绞痛的过程。而知识图谱通过描述实体及其关系来表示语义,知识图谱可以使用本体作为模式层,通过这样的设计,基于知识图谱设计的模型将不仅支持显示知识相关的查询,同时也支持与隐式知识相关的逻辑推理。该方法能够从患者的输入症状出发,经过知识图谱的查询和计算,得到患者可能的证候类型以及应该选择的治法和方剂。这是一种构建中医临床辅助决策系统的有益尝试据和非结构化数据,分别进行整理和提取,形成本研究所需要的数据(包含节点、属性与关系)。在此基础上,我们进行实体消歧、实体对齐等知识融合过程。随后本研究通过Python的py2neo库调用Neo4j,将知识数据导入Neo4j中构建知识图谱。然后通过Python编程将程序构建的基于中医诊疗指南的知识图谱,支持基于图数据库的查询功能。我们以诊疗指南中第一个证候对应的第一个临床表现(胸固定性痛)为例来说明。如查询“临床表现”为“胸固定性痛”,则展示如图6所示的知识图谱。蓝色节点为查询的症状“胸固定性痛”,其对应的“证候要素”为“血瘀”,“血瘀”能够组成“气虚血瘀证”、“气滞血瘀证”、“心血瘀阻证”“痰瘀互结证”4个证型。4个证型又分别对应治法和方剂以及中成药等。从而实现基于中医诊疗指南和专家经验的知识图谱可视化展示过程,为直观地展现中医诊疗过程提供一种新的方式。本研究将冠心病稳定型心绞痛中医诊疗指南中所规定的分条罗列的知识模式,通过知识图谱可视化的方式实现,这有助于将凝结了专家经验和循证证据所形成的医学模式和诊疗过程直观的展示给中医医师,系统精确的展示指南中的医学模式和医疗知识之间的相互关联和模式之间先前隐含的潜在联系,有助于中医、中西医结合诊疗经验的规范化传承和共享,为构建中医临床辅助决策系统提供研究基础。此外,该研究方法作为一种技术框架,不局限于这一项诊疗指南的知识图谱构建和研究,二是可以作为基础框架推广到其他诊疗指南,为诊疗指南的推广和指南中的标准化诊疗规范的普及提供参考范式为保障铁路运输安全,面向铁路运输系统构建了健全的铁路运输设备安全保障体系。在该体系下,可对运输设备的基础信息、运行维护(简称:运维)信息及故障数据进行有效管理。铁路运输设备安全保障体系包含针对铁路基础设施设备构建的铁路运输设备监测检测系统、铁路运输设备信息管理系统及铁路运营集成化平台,可实现铁路运输设备的全生命周期管理、设备故障信息管理,以及设备故障数据一体化分析。铁路运输安全保障体系架构如图1所示知识图谱的基本构建流程包括本体构建、实体配置、知识抽取和知识融合等。1.4 知识图谱设计1.4.1 流程设计本研究首先根据诊疗指南中的知识和信息,按照知识图谱构建的方法,从抽象的层面分别定义实体、关系和属性,然后将指南中本研究所需要的结构化数据、半结构化数本研究结合目前中医诊疗经验传承中存在的问题,针对冠心病稳定型心绞痛这个单一病种,提出了一种基于凝结了中医行业专家经验和循证证据所形成的诊疗指南,来构建知识图谱的方法。与一些相关的研究不同的是,该方法没有选择使用基于网络爬虫的大数据来构建知识图谱,而是选择使用规范化、规则化程度较高的中医诊疗指南中的医学知识和术语构建知识图谱并可视化的展示和描述中医诊治冠心病稳定型心绞痛的过程。而知识图谱通过描述实体及其关系来表示语义,知识图谱可以使用本体作为模式层,通过这样的设计,基于知识图谱设计的模型将不仅支持显示知识相关的查询,同时也支持与隐式知识相关的逻辑推理。该方法能够从患者的输入症状出发,经过知识图谱的查询和计算,得到患者可能的证候类型以及应该选择的治法和方剂。这是一种构建中医临床辅助决策系统的有益尝试据和非结构化数据,分别进行整理和提取,形成本研究所需要的数据(包含节点、属性与关系)。在此基础上,我们进行实体消歧、实体对齐等知识融合过程。随后本研究通过Python的py2neo库调用Neo4j,将知识数据导入Neo4j中构建知识图谱。然后通过Python编程将程序构建的基于中医诊疗指南的知识图谱,支持基于图数据库的查询功能。我们以诊疗指南中第一个证候对应的第一个临床表现(胸固定性痛)为例来说明。如查询“临床表现”为“胸固定性痛”,则展示如图6所示的知识图谱。蓝色节点为查询的症状“胸固定性痛”,其对应的“证候要素”为“血瘀”,“血瘀”能够组成“气虚血瘀证”、“气滞血瘀证”、“心血瘀阻证”“痰瘀互结证”4个证型。4个证型又分别对应治法和方剂以及中成药等。从而实现基于中医诊疗指南和专家经验的知识图谱可视化展示过程,为直观地展现中医诊疗过程提供一种新的方式。本研究将冠心病稳定型心绞痛中医诊疗指南中所规定的分条罗列的知识模式,通过知识图谱可视化的方式实现,这有助于将凝结了专家经验和循证证据所形成的医学模式和诊疗过程直观的展示给中医医师,系统精确的展示指南中的医学模式和医疗知识之间的相互关联和模式之间先前隐含的潜在联系,有助于中医、中西医结合诊疗经验的规范化传承和共享,为构建中医临床辅助决策系统提供研究基础。此外,该研究方法作为一种技术框架,不局限于这一项诊疗指南的知识图谱构建和研究,二是可以作为基础框架推广到其他诊疗指南,为诊疗指南的推广和指南中的标准化诊疗规范的普及提供参考范式为保障铁路运输安全,面向铁路运输系统构建了健全的铁路运输设备安全保障体系。在该体系下,可对运输设备的基础信息、运行维护(简称:运维)信息及故障数据进行有效管理。铁路运输设备安全保障体系包含针对铁路基础设施设备构建的铁路运输设备监测检测系统、铁路运输设备信息管理系统及铁路运营集成化平台,可实现铁路运输设备的全生命周期管理、设备故障信息管理,以及设备故障数据一体化分析。铁路运输安全保障体系架构如图1所示可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。多任务学习法。将嵌入模块和推荐模块设计成了相关又分离的任务,将这些任务放在同一个框架中进行交替学习,Wang等人[43]提出了MKR模型,Cao等人[44]提出了KTUP模型。典型的例子就是MRK模型。该模型是由KGE模块和推荐模块组成的,将知识图谱以三元组的形式输入KGE模块,通过KGE模块预测出尾实体。用户和项目的特征表示作为推荐模块的输入,通过推荐模块得到项目点击率的估计值。在KGE模块和推荐模块中间有一个交叉特征共享单元,两个模块可以通过该共享单元进行数据交换,这样就可以得到用户的最终表示uL,如公式(6)所示。项目的最终表示vL,如公式(7)所示。其中vL是由L个交叉压缩单元提取的特征,CL是第L层的交叉特征矩阵,Sv表示的是项目v的相关实体集合。公式(8)为预测函数,目的是将用户的最终表示uL和项目的最终表示vL结合起来。其中公式(4)中的Ρ(vj∣∣ui)表示用户ui首先选择项目vj的概率。公式(3)中pθ(vj∣∣ui,r)表示推荐系统中的评分函数pture(vj∣∣ui,r)表示用户真实偏好。Ye等人[38]提出了BEM边界元模型,BEM模型要学习两类知识图,用TransE模型学习项目属性知识图谱,该知识图谱包含着项目的属性信息,用GraphSAGE[39]模型学习用户行为知识图谱,该知识图谱包含了用户行为信息,如用户之间的关联信息、用户的共同购买信息和共同收藏信息等。BEM通过对两类知识图谱的学习得到初始嵌入表示,再通过贝叶斯模型对嵌入表示进行细化,推荐系统会根据用户之间的共同行为,在行为知识图谱中找到最相关的项目进行推荐。两阶段学习法非常易于实现,更加适合大规模的数据。但是它的推荐模块和KGE[40]模块结构性松散,相互依赖程度较低。b) 联合学习法。将知识图谱的特征学习和推荐系统的函数部分进行结合,推荐系统可以指导知识图谱的学习表征过程,实现端到端的联合学习。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。多任务学习法。将嵌入模块和推荐模块设计成了相关又分离的任务,将这些任务放在同一个框架中进行交替学习,Wang等人[43]提出了MKR模型,Cao等人[44]提出了KTUP模型。典型的例子就是MRK模型。该模型是由KGE模块和推荐模块组成的,将知识图谱以三元组的形式输入KGE模块,通过KGE模块预测出尾实体。用户和项目的特征表示作为推荐模块的输入,通过推荐模块得到项目点击率的估计值。在KGE模块和推荐模块中间有一个交叉特征共享单元,两个模块可以通过该共享单元进行数据交换,这样就可以得到用户的最终表示uL,如公式(6)所示。项目的最终表示vL,如公式(7)所示。其中vL是由L个交叉压缩单元提取的特征,CL是第L层的交叉特征矩阵,Sv表示的是项目v的相关实体集合。公式(8)为预测函数,目的是将用户的最终表示uL和项目的最终表示vL结合起来。知识图谱根据关系连接各实体并生成路径,用户能够通过路径去发现与实体具有关联性的潜在项目,从而获取更加准确的用户偏好。在表3中,汇总出了多领域知识图谱推荐系统基于路径的方法实际上,随着“颜值经济”不断走热,医美逐渐成为部分当代中国人的“刚需”,其中恢复期短、风险较低的轻医美最受欢迎。',
'基于传播的方法。基于元结构的方法大多数需要人工定义元结构生成路径,基于路径嵌入的方法虽然可以不需要人工定义路径,可以枚举出可能的路径,但是模型较为复杂,系统计算量大。基于传播的方法将知识图谱各条路径中多跳邻居嵌入表示,利用传播的思想来预测用户偏好。Wang等人[57]在2018年提出了RippleNet模型,基于路径的方法可以分成基于元结构的方法、基于路径嵌入的方法和基于传播的方法。在基于嵌入的方法中各模型常用评价指标为Recall、MAE、RMSE、AUC、ACC、Precision等。具体评价指标对比如表4所示。表4中MAE的最大值是SemRec-P在Yelp数据集上的实验结果1.176。RMSE的最大值为FMG模型在Amazon数据集上的结果1.186。MCRec模型的Precision指标在Last.FM数据集上达到了0.480。KPRE模型的Recall指标在KKBOX数据集上达到了0.881。KGCN模型的AUC指标在MovieLens-20M上的结果为0.979。KNI模型的ACC指标在MovieLens-20M上的结果为0.970基于嵌入的方法可以将知识图谱中的图数据通过一些表征学习方法得到特征的低维向量表示而且还能保留知识图谱中实体和项目之间的语义信息,知识图谱通过嵌入的方式将更加全面的数据信息提供给推荐系统。但此类方法会忽略掉知识图谱中路径的设计以及多跳实体之间的关联信息,导致基于嵌入的方法可解释性不强其中公式(4)中的Ρ(vj∣∣ui)表示用户ui首先选择项目vj的概率。公式(3)中pθ(vj∣∣ui,r)表示推荐系统中的评分函数pture(vj∣∣ui,r)表示用户真实偏好。Ye等人[38]提出了BEM边界元模型,BEM模型要学习两类知识图,用TransE模型学习项目属性知识图谱,该知识图谱包含着项目的属性信息,用GraphSAGE[39]模型学习用户行为知识图谱,该知识图谱包含了用户行为信息,如用户之间的关联信息、用户的共同购买信息和共同收藏信息等。BEM通过对两类知识图谱的学习得到初始嵌入表示,再通过贝叶斯模型对嵌入表示进行细化,推荐系统会根据用户之间的共同行为,在行为知识图谱中找到最相关的项目进行推荐。两阶段学习法非常易于实现,更加适合大规模的数据。但是它的推荐模块和KGE[40]模块结构性松散,相互依赖程度较低。b) 联合学习法。将知识图谱的特征学习和推荐系统的函数部分进行结合,推荐系统可以指导知识图谱的学习表征过程,实现端到端的联合学习。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。多任务学习法。将嵌入模块和推荐模块设计成了相关又分离的任务,将这些任务放在同一个框架中进行交替学习,Wang等人[43]提出了MKR模型,Cao等人[44]提出了KTUP模型。典型的例子就是MRK模型。该模型是由KGE模块和推荐模块组成的,将知识图谱以三元组的形式输入KGE模块,通过KGE模块预测出尾实体。用户和项目的特征表示作为推荐模块的输入,通过推荐模块得到项目点击率的估计值。在KGE模块和推荐模块中间有一个交叉特征共享单元,两个模块可以通过该共享单元进行数据交换,这样就可以得到用户的最终表示uL,如公式(6)所示。项目的最终表示vL,如公式(7)所示。其中vL是由L个交叉压缩单元提取的特征,CL是第L层的交叉特征矩阵,Sv表示的是项目v的相关实体集合。公式(8)为预测函数,目的是将用户的最终表示uL和项目的最终表示vL结合起来。其中公式(4)中的Ρ(vj∣∣ui)表示用户ui首先选择项目vj的概率。公式(3)中pθ(vj∣∣ui,r)表示推荐系统中的评分函数pture(vj∣∣ui,r)表示用户真实偏好。Ye等人[38]提出了BEM边界元模型,BEM模型要学习两类知识图,用TransE模型学习项目属性知识图谱,该知识图谱包含着项目的属性信息,用GraphSAGE[39]模型学习用户行为知识图谱,该知识图谱包含了用户行为信息,如用户之间的关联信息、用户的共同购买信息和共同收藏信息等。BEM通过对两类知识图谱的学习得到初始嵌入表示,再通过贝叶斯模型对嵌入表示进行细化,推荐系统会根据用户之间的共同行为,在行为知识图谱中找到最相关的项目进行推荐。两阶段学习法非常易于实现,更加适合大规模的数据。但是它的推荐模块和KGE[40]模块结构性松散,相互依赖程度较低。b) 联合学习法。将知识图谱的特征学习和推荐系统的函数部分进行结合,推荐系统可以指导知识图谱的学习表征过程,实现端到端的联合学习。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。多任务学习法。将嵌入模块和推荐模块设计成了相关又分离的任务,将这些任务放在同一个框架中进行交替学习,Wang等人[43]提出了MKR模型,Cao等人[44]提出了KTUP模型。典型的例子就是MRK模型。该模型是由KGE模块和推荐模块组成的,将知识图谱以三元组的形式输入KGE模块,通过KGE模块预测出尾实体。用户和项目的特征表示作为推荐模块的输入,通过推荐模块得到项目点击率的估计值。在KGE模块和推荐模块中间有一个交叉特征共享单元,两个模块可以通过该共享单元进行数据交换,这样就可以得到用户的最终表示uL,如公式(6)所示。项目的最终表示vL,如公式(7)所示。其中vL是由L个交叉压缩单元提取的特征,CL是第L层的交叉特征矩阵,Sv表示的是项目v的相关实体集合。公式(8)为预测函数,目的是将用户的最终表示uL和项目的最终表示vL结合起来。知识图谱根据关系连接各实体并生成路径,用户能够通过路径去发现与实体具有关联性的潜在项目,从而获取更加准确的用户偏好。在表3中,汇总出了多领域知识图谱推荐系统基于路径的方法Hete-MF模型只是使用了项目之间的相似度,Luo等人[47]提出的Hete-CF模型是将用户之间的相似度、项目之间的相似度和用户项目之间的相似度都作为正则化来挖掘用户偏好。与上述模型思想相似的还有HeteRec[48]模型和HeteRec-p[49]模型。由Shi等人[50]提出的SemRec模型与上述的四类模型不同,SemRec模型根据知识图谱中的路径生成一个用户对项目评级的强度矩阵,评级强度矩阵就代表了用户的偏好,模型再根据相似用户的评分,预测推荐系统目标用户对项目的评分,根据评分进行排序,从高到低推荐给用户。公式(17)是用户之间相似度正则化目标函数基于路径的方法可以分成基于元结构的方法、基于路径嵌入的方法和基于传播的方法。在基于嵌入的方法中各模型常用评价指标为Recall、MAE、RMSE、AUC、ACC、Precision等。具体评价指标对比如表4所示。表4中MAE的最大值是SemRec-P在Yelp数据集上的实验结果1.176。RMSE的最大值为FMG模型在Amazon数据集上的结果1.186。MCRec模型的Precision指标在Last.FM数据集上达到了0.480。KPRE模型的Recall指标在KKBOX数据集上达到了0.881。KGCN模型的AUC指标在MovieLens-20M上的结果为0.979。KNI模型的ACC指标在MovieLens-20M上的结果为0.970基于嵌入的方法可以将知识图谱中的图数据通过一些表征学习方法得到特征的低维向量表示而且还能保留知识图谱中实体和项目之间的语义信息,知识图谱通过嵌入的方式将更加全面的数据信息提供给推荐系统。但此类方法会忽略掉知识图谱中路径的设计以及多跳实体之间的关联信息,导致基于嵌入的方法可解释性不强其中公式(4)中的Ρ(vj∣∣ui)表示用户ui首先选择项目vj的概率。公式(3)中pθ(vj∣∣ui,r)表示推荐系统中的评分函数pture(vj∣∣ui,r)表示用户真实偏好。Ye等人[38]提出了BEM边界元模型,BEM模型要学习两类知识图,用TransE模型学习项目属性知识图谱,该知识图谱包含着项目的属性信息,用GraphSAGE[39]模型学习用户行为知识图谱,该知识图谱包含了用户行为信息,如用户之间的关联信息、用户的共同购买信息和共同收藏信息等。BEM通过对两类知识图谱的学习得到初始嵌入表示,再通过贝叶斯模型对嵌入表示进行细化,推荐系统会根据用户之间的共同行为,在行为知识图谱中找到最相关的项目进行推荐。两阶段学习法非常易于实现,更加适合大规模的数据。但是它的推荐模块和KGE[40]模块结构性松散,相互依赖程度较低。b) 联合学习法。将知识图谱的特征学习和推荐系统的函数部分进行结合,推荐系统可以指导知识图谱的学习表征过程,实现端到端的联合学习。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。多任务学习法。将嵌入模块和推荐模块设计成了相关又分离的任务,将这些任务放在同一个框架中进行交替学习,Wang等人[43]提出了MKR模型,Cao等人[44]提出了KTUP模型。典型的例子就是MRK模型。该模型是由KGE模块和推荐模块组成的,将知识图谱以三元组的形式输入KGE模块,通过KGE模块预测出尾实体。用户和项目的特征表示作为推荐模块的输入,通过推荐模块得到项目点击率的估计值。在KGE模块和推荐模块中间有一个交叉特征共享单元,两个模块可以通过该共享单元进行数据交换,这样就可以得到用户的最终表示uL,如公式(6)所示。项目的最终表示vL,如公式(7)所示。其中vL是由L个交叉压缩单元提取的特征,CL是第L层的交叉特征矩阵,Sv表示的是项目v的相关实体集合。公式(8)为预测函数,目的是将用户的最终表示uL和项目的最终表示vL结合起来。其中公式(4)中的Ρ(vj∣∣ui)表示用户ui首先选择项目vj的概率。公式(3)中pθ(vj∣∣ui,r)表示推荐系统中的评分函数pture(vj∣∣ui,r)表示用户真实偏好。Ye等人[38]提出了BEM边界元模型,BEM模型要学习两类知识图,用TransE模型学习项目属性知识图谱,该知识图谱包含着项目的属性信息,用GraphSAGE[39]模型学习用户行为知识图谱,该知识图谱包含了用户行为信息,如用户之间的关联信息、用户的共同购买信息和共同收藏信息等。BEM通过对两类知识图谱的学习得到初始嵌入表示,再通过贝叶斯模型对嵌入表示进行细化,推荐系统会根据用户之间的共同行为,在行为知识图谱中找到最相关的项目进行推荐。两阶段学习法非常易于实现,更加适合大规模的数据。但是它的推荐模块和KGE[40]模块结构性松散,相互依赖程度较低。b) 联合学习法。将知识图谱的特征学习和推荐系统的函数部分进行结合,推荐系统可以指导知识图谱的学习表征过程,实现端到端的联合学习。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。互联网快速地发展以及数据量不断增加,使得在海量数据中获取到用户所需的有效信息成为当前推荐系统研究的主要目标。推荐系统作为一种信息过滤的方法,能够根据用户的需求、行为和偏好,为用户推荐感兴趣的数据内容。推荐系统的核心是进行个性化推荐,传统的推荐系统可以分成三类,分别是基于内容的推荐系统[1]、基于协同过滤的推荐系统[2]和混合推荐系统[3]。基于内容的推荐系统目的是找到与目标用户相似的用户,将相似用户的偏好项目作为推荐结果。其方法简单、系统可解释性强,但不适合处理复杂信息,存在冷启动问题,而且该方法在处理大规模复杂数据时耗时久、效率较低。基于协同过滤的推荐系统根据用户历史行为信息,利用聚类方法实现推荐。基于协同过滤的推荐是当前应用最为广泛的推荐方法,但其也存在着新用户或新项目的冷启动以及数据稀疏等问题。针对上述两种方法中出现的问题,研究者进一步提出了混合推荐系统。混合推荐系统结合上述两种方法的优点,可以有效缓解上述两种方法中的不足,增加推荐的准确性。但是,混合推荐系统不能彻底解决冷启动[4]和数据稀疏[5]问题,知识图谱的出现有效缓解了上述问题。根据以上三条路径可以推断出用户A可能喜欢《简单爱》这首歌,推荐系统会把这一结果推荐给用户。该实例反应了知识图谱能够有效地挖掘出用户和项目之间潜在的关系,不但缓解了冷启动和数据稀疏问题,而且还使得推荐结果具有可解释性。知识图谱辅助推荐系统已经成为推荐系统研究领域的热点。Chang等人[6]根据推荐生成方法将知识图谱推荐方法分为基于本体的推荐生成方法、基于开放链接数据的推荐生成方法和图嵌入的推荐生成方法。Qin[7]等人基于知识图谱与推荐系统信息结合的不同方式,将知识图谱与推荐系统的结合方法分成基于嵌入的知识图谱信息挖掘方法和基于路径的知识图谱信息挖掘方法。Guo等人[8]细化了基于路径的知识图谱信息挖掘方法,将其进一步分为基于路径的知识图谱信息挖掘方法和基于传播的知识图谱信息挖掘方法。Zhu[9]等人按照算法思想差异性将知识图谱推荐算法分为基于连接的推荐、基于嵌入的推荐和基于混合的推荐。但上述研究中均没有从知识图谱推荐系统应用领域的视角,对现有的方法进行分类分析。由于不同应用领域的数据集具有不同的特性,将不同的知识图谱推荐方法应用于不同数据集产生的推荐效果可能各不相同。因此论文综合分析当前知识图谱推荐统,将其分为多领域知识图谱推荐系统和特定领域知识图谱推荐系统,如图2所示。多领域知识图谱推荐系统应用范围广泛,在多个领域中均可使用。多领域知识图谱推荐系统又可分为基于嵌入的多领域知识图谱推荐系统和基于路径的多领域知识图谱推荐系统。特定领域知识图谱推荐系统是根据某个领域的数据特点提出的仅限于该领域使用的推荐方法。该类方法在其它领域使用效果一般,其特点为针对性强、应用领域较为单一。知识图谱推荐系统根据用户历史行为数据快速发掘用户和项目相关的实体、关系,使得推荐系统能够获取更加丰富的用户、项目背景信息,实现更精准、有效地推荐。知识图谱本质上是具有实体间关系的语义网络,由三元组组成。三元组包含实体、关系和属性(属性值)三个要素,这三个要素是构成知识图谱的基础。知识图谱作为一种辅助信息融入推荐系统能够提高系统的可解释性,如图1所示。在原有的数据中只能看出用户A喜欢《青花瓷》这首歌,但是无法将用户A和《简单爱》这首歌相关联。通过构建知识图谱可以将信息关联到一起,并利用知识推理推断出用户的喜好。这种由用户和项目之间的交互信息构成的知识图谱是一种异质信息网。推荐系统可以通过异质信息网中的不同路径寻找推荐项目,从而提高推荐的准确度。在图1中可以看出从用户A到《简单爱》有三条路径。另外,论文还基于应用领域分类进一步介绍知识图谱推荐系统中常用的数据集,并在最后对基于知识图谱推荐系统现有的研究工作进行总结,同时展望未来的研究工作。论文第一节将介绍相关研究背景,其包含传统推荐系统和知识图谱的基本概念与定义;第二节从应用领域的角度详细分析有关基于知识图谱推荐系统的相关研究;第三节对各领域使用的数据集进行分析;第四节对研究方向进行展望;第五节对论文总结。推荐系统对用户和项目具有主动性,其不需要用户提出明确的需求,推荐算法可以自主分析用户历史行为以及用户、项目之间的关系,分析出用户的偏好,并基于此偏好,为用户提供个性化推荐服务,满足用户个性化需求[10]。推荐系统的目标就是给用户推荐一个或者多个项目,其推荐过程大致分为以下几步:第一步,定义用户集合为U,ui为系统目标用户,项目集合为V,vj为候选推荐项目;第二步,定义一个系统评分函数f:ui×vj→ŷi,j,该评分函数表示目标用户ui对候选推荐项目vj的喜爱程度;第三步,对评分函数得出的用户偏好值进行排序,生成推荐列表,最终实现用户个性化推荐。随着推荐技术的成熟,推荐系统广泛应用于电子商务、电影、音乐、新闻、社交、招聘等多个领域[11]。传统推荐系统通常被分为三类,分别是基于内容的推荐系统、基于协同过滤的推荐系统、混合推荐系统。基于内容的推荐系统是最早出现且最基础的推荐算法,一开始被应用于信息检索系统,许多信息过滤和信息检索的方法都可以应用于此。但基于内容的推荐系统在内容特征提取时过度依赖内容标签,仅关注用户自身数据,并没有考虑用户之间的行为数据。基于此不足,基于协同过滤的推荐系统被提出。该种系统利用了用户之间的行为数据和内容之间的关联数据,提高了推荐效率。但其仍然存在冷启动和稀疏性等问题。由于上述两种推荐系统均存在不足,混合推荐系统被提出。1.1.1 基于内容的推荐系统基于内容的推荐系统的核心是在候选项目集中找到与用户偏好项目相似的项目。整个推荐过程首先要提取用户的内容特征,内容特征包括用户评分、评价、点赞等显性反馈行为和浏览、搜索等隐性反馈行为。其次对用户的内容特征进行建模,计算出项目之间的相似度。最后通过相似度排序,生成推荐结果。基于内容的推荐系统优点是模型简单、直观,具有可解释性,不存在新项目的冷启动问题和数据稀疏问题。缺点是对复杂项目的内容特征提取不全面,会影响推荐结果。并且,由于系统新用户没有内容特征,系统很难发现新用户的偏好特征,动态推荐系统也是一样,在针对实时性较高的数据时,比如音频数据,新闻数据等,这些信息更新较快,基于静态偏好建模的推荐系统不能解决用户实时兴趣,当用户做出行为时,如何根据当前的行为快速获取用户当前偏好产生推荐结果也值得探索,动态图网络可能是个很好的解决办法,Song[89]等人提出了通过动态图注意力网络进行基于会话的社交推荐,动态图注意力网络由RNN的隐藏表示捕获用户当前的兴趣,用图注意力网络捕获用户影响。将用户的短期偏好与长期偏好分开来,根据用户当前的兴趣,使用注意力机制自动确定每个用户的影响力。使用这种方法可以实现动态推荐系统存在新用户的冷启动问题。1.1.2 基于协同过滤的推荐系统基于协同过滤的推荐系统是推荐系统中应用最成功、最广泛的推荐方法[12]。基于协同过滤的方法通过不同的聚类方式被分成3类,分别是基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。基于用户的协同过滤基本思想是目标用户与其相似用户之间的偏好可能相同,这就需要根据用户历史行为记录计算出用户之间的相似度,通过相似用户的喜爱项目,给目标用户做出推荐。该类方法的优点是逻辑简单,可解释性强,缺点是存在新用户的冷启动问题,随着用户数量增加,推荐算法效率会降低,不适合处理大规模数据。基于项目的协同过滤基本思想是如果大多数用户对推荐项目的评分相近,目标用户对该推荐项目的评分也可能相近。该方法与基于用户的协同过滤方法相似,不同的是要根据多数用户对推荐项目的评分,找到评分高的项目,根据评分高低进行排序,将高评分项目推荐给目标用户。其优点是可以处理复杂的推荐对象,有利于发掘用户兴趣爱好。缺点是当用户评分量增加的时候会出现评分差异大的情况,导致数据稀疏问题。而且该方法需要有大量的用户数据才会有较好的推荐效果。基于模型的协同过滤的基本思想是根据用户偏好训练推荐模型。其根据用户历史行为记录通过机器学习方法训练出数学模型。该方法相比于前两种方法更加适合大规模数据。1.1.3 混合推荐系统针对上述推荐系统中的不足,混合推荐系统被提出,并将多种推荐技术进行融合,目的是通过多个推荐算法协同合作,避免单个算法存在的问题,更好地为用户做推荐,提升推荐质量和用户体验。其中,基于内容的推荐跨领域融合。根据分析可以看出针对特定领域知识图谱推荐系统提出的方法较少,这种方式针对性更强,推荐效果更好,但是应用成本高,应用范围受限。大多数知识图谱推荐系统都可以应用在多个领域,应用范围广泛,但是各领域的数据类型不同,同一方法的推荐效果也不同,如何将不同领域信息融合,实现对实体的多维描述,补全实体信息实现跨领域推荐值得深度探索。跨领域融合尝试将同一实体的多领域信息整合,由于同一用户在不同领域的偏好可能会出现偏差,就可以考虑迁移学习的方法[90],Zhu[91]等人提出了PTUPCDR模型,该模型首次提出了个性化迁移用户兴趣偏好这个概念,将用户特征嵌入表示输入一个元网络来生成个性化的偏好桥来达到个性化偏好迁移。未来可以尝试用迁移学习的方法将用户在辅助域中的偏好转移到目标域,不仅能实现推荐的跨领域融合,而且还能缓解冷启动的问题和基于协同过滤的推荐组合的方式是最常见的。混合推荐系统融合方式种类多样,最常见的有推荐结果融合和推荐算法融合两种方式。推荐结果融合是将各推荐方法得到的结果进行混合计算。推荐算法融合使用某一推荐技术作为框架,将其它推荐技术加入到框架中。混合推荐系统通过多种方法结合,有效地缓解了系统中冷启动和数据稀疏问题,并且还能够针对特定领域选择合适的模型进行推荐,通过多种信息结合,提升推荐系统性能[12]。1.2 基于图神经网络的推荐系统近些年,由于深度学习技术的广泛使用,研究人员开始尝试在图谱中引入深度学习方法,出现了基于图神经网络推荐系统研究热潮[13]。借鉴了循环神经网络[14]、卷积神经网络[15]和自动编码器的基本思想,将图数据和神经网络相结合,形成图神经网络[16]。图神经网络分成图卷积网络、图注意力网络、图自编码器、图生成网络和图时空网络五类。图卷积神经网络是推荐中最常用到的图神经网络,其基本思想是将卷积运算应用到图数据中,常见的模型有NGCF[17]、KGCN-PN[18]、NIA-GCN[19]。有些推荐系统会将图神经网络和注意力机制相结合,可以在序列推荐任务中将注意力放到最重要的数据上,常见的模型有GAT[20]、BGANR[21]。GCN-ONCF[22]模型是将图神经网络设计成为一个编码器。图神经网络可以学习到深度学习算法学习不到的用户和项目之间的关联关系。利用图神经网络学习知识图谱的表示,可以打破实体之间的孤立性,有助于学到更完整更丰富的实体、关系表示。而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。多任务学习法。将嵌入模块和推荐模块设计成了相关又分离的任务,将这些任务放在同一个框架中进行交替学习,Wang等人[43]提出了MKR模型,Cao等人[44]提出了KTUP模型。典型的例子就是MRK模型。该模型是由KGE模块和推荐模块组成的,将知识图谱以三元组的形式输入KGE模块,通过KGE模块预测出尾实体。用户和项目的特征表示作为推荐模块的输入,通过推荐模块得到项目点击率的估计值。在KGE模块和推荐模块中间有一个交叉特征共享单元,两个模块可以通过该共享单元进行数据交换,这样就可以得到用户的最终表示uL,如公式(6)所示。项目的最终表示vL,如公式(7)所示。其中vL是由L个交叉压缩单元提取的特征,CL是第L层的交叉特征矩阵,Sv表示的是项目v的相关实体集合。公式(8)为预测函数,目的是将用户的最终表示uL和项目的最终表示vL结合起来。知识图谱根据关系连接各实体并生成路径,用户能够通过路径去发现与实体具有关联性的潜在项目,从而获取更加准确的用户偏好。在表3中,汇总出了多领域知识图谱推荐系统基于路径的方法Hete-MF模型只是使用了项目之间的相似度,多方法推荐。不同的推荐方法都有各自的优缺点,当面对不同需求、不同上下文场景时应选择不同的推荐算法。不可能存在一个推荐算法在任何时候下都优于其他算法的情况。所以要充分运用不同推荐算法各自的优势,取长补短,相互融合形成一个强大的推荐框架,而且将多种推荐方法融合,可以有效的提高推荐效果。RippleNet模型、KGCN模型和KGAT模型都是典型的混合模型,它们将基于嵌入和基于路径的方法融合,充分利用了知识图谱中的实体信息和语义关系,实现更精确的推荐。但是多种方法结合也导致了计算量大,模型复杂,系统开销大,推荐速度慢等问题。如何在多方法融合的系统中,针对不同的情况系统可以快速做出推荐响应并尽量降低成本和开销,在未来推荐系统的发展中值得研究Luo等人[47]提出的Hete-CF模型是将用户之间的相似度、项目之间的相似度和用户项目之间的相似度都作为正则化来挖掘用户偏好。与上述模型思想相似的还有HeteRec[48]模型和HeteRec-p[49]模型。由Shi等人[50]提出的SemRec模型与上述的四类模型不同,SemRec模型根据知识图谱中的路径生成一个用户对项目评级的强度矩阵,评级强度矩阵就代表了用户的偏好,模型再根据相似用户的评分,预测推荐系统目标用户对项目的评分,根据评分进行排序,从高到低推荐给用户。公式(17)是用户之间相似度正则化目标函数该模型首先根据用户的交互历史训练出一个关系矩阵给路径中的各跳邻居分配权重,由于知识图谱是由三元组组成的,RippleNet模型根据三元组中的头实体、关系权重以及候选项得出尾实体的权重,计算出多跳邻居和候选项之间的相似度,路径中的每一层用户都会有一个用户表示,最后将每一层的用户表示结合生成用户的最终表示,反映出用户的偏好,计算得到用户的点击概率,根据点击概率给用户做推荐出于对安全性、可靠性等因素的考虑,大量消费者自然而然地流动到医美资源集聚的城市“求美”,“医美旅游”悄然兴起。',
'基于路径的推荐系统考虑到嵌入而且图神经网络在学习节点、边表示上具有很大的优势,可以更好地学习知识图谱实体、关系的嵌入表示,改善关系抽取等,帮助构建知识图谱。但对比于知识图谱推荐系统,图神经网络推荐系统的可解释性不强,无法解释推理过程和推理依据,并且深度图神经网络的训练过程非常艰难。1.3 知识图谱知识图谱这一概念最早于2012年由谷歌公司提出,最初的目的是为了提高信息检索速度,增加用户搜索体验。根据谷歌公司对知识图谱的描述可以知道知识图谱是一种利用图模型来描述知识和建模世界万物之间关联关系的技术。它可以将现实世界中的各种实体或者概念以及它们之间的关系都放在一张网络图谱中,形成关系语义网络。由于数据信息的多样化,可以将数据信息分为非结构化数据、半结构化数据、结构化数据三类,非结构化数据和半结构化数据很难体现出实体之间的关联关系,不利于信息检索,而知识图谱可以将非结构化数据和半结构化数据转换成结构化数据。多任务学习法。将嵌入模块和推荐模块设计成了相关又分离的任务,将这些任务放在同一个框架中进行交替学习,Wang等人[43]提出了MKR模型,Cao等人[44]提出了KTUP模型。典型的例子就是MRK模型。该模型是由KGE模块和推荐模块组成的,将知识图谱以三元组的形式输入KGE模块,通过KGE模块预测出尾实体。用户和项目的特征表示作为推荐模块的输入,通过推荐模块得到项目点击率的估计值。在KGE模块和推荐模块中间有一个交叉特征共享单元,两个模块可以通过该共享单元进行数据交换,这样就可以得到用户的最终表示uL,如公式(6)所示。项目的最终表示vL,如公式(7)所示。其中vL是由L个交叉压缩单元提取的特征,CL是第L层的交叉特征矩阵,Sv表示的是项目v的相关实体集合。公式(8)为预测函数,目的是将用户的最终表示uL和项目的最终表示vL结合起来。知识图谱根据关系连接各实体并生成路径,用户能够通过路径去发现与实体具有关联性的潜在项目,从而获取更加准确的用户偏好。在表3中,汇总出了多领域知识图谱推荐系统基于路径的方法Hete-MF模型只是使用了项目之间的相似度,多方法推荐。不同的推荐方法都有各自的优缺点,当面对不同需求、不同上下文场景时应选择不同的推荐算法。不可能存在一个推荐算法在任何时候下都优于其他算法的情况。所以要充分运用不同推荐算法各自的优势,取长补短,相互融合形成一个强大的推荐框架,而且将多种推荐方法融合,可以有效的提高推荐效果。RippleNet模型、KGCN模型和KGAT模型都是典型的混合模型,它们将基于嵌入和基于路径的方法融合,充分利用了知识图谱中的实体信息和语义关系,实现更精确的推荐。但是多种方法结合也导致了计算量大,模型复杂,系统开销大,推荐速度慢等问题。如何在多方法融合的系统中,针对不同的情况系统可以快速做出推荐响应并尽量降低成本和开销,在未来推荐系统的发展中值得研究Luo等人[47]提出的Hete-CF模型是将用户之间的相似度、项目之间的相似度和用户项目之间的相似度都作为正则化来挖掘用户偏好。与上述模型思想相似的还有HeteRec[48]模型和HeteRec-p[49]模型。由Shi等人[50]提出的SemRec模型与上述的四类模型不同,SemRec模型根据知识图谱中的路径生成一个用户对项目评级的强度矩阵,评级强度矩阵就代表了用户的偏好,模型再根据相似用户的评分,预测推荐系统目标用户对项目的评分,根据评分进行排序,从高到低推荐给用户。公式(17)是用户之间相似度正则化目标函数该模型首先根据用户的交互历史训练出一个关系矩阵给路径中的各跳邻居分配权重,由于知识图谱是由三元组组成的,RippleNet模型根据三元组中的头实体、关系权重以及候选项得出尾实体的权重,计算出多跳邻居和候选项之间的相似度,路径中的每一层用户都会有一个用户表示,最后将每一层的用户表示结合生成用户的最终表示,反映出用户的偏好,计算得到用户的点击概率,根据点击概率给用户做推荐出于对安全性、可靠性等因素的考虑,大量消费者自然而然地流动到医美资源集聚的城市“求美”,“医美旅游”悄然兴起方法的缺点,根据知识图谱中路径表达的语义关系进行推荐。在基于路径的推荐中元路径方法需要手动设计元路径,工作量大,由于各领域数据元结构不同,导致该方法的应用领域有限。基于路径嵌入的方法不需要手动设计,融合了语义信息,但是路径过多导致模型复杂、计算量大、系统开销也大在针对多领域的模型中,基于嵌入的推荐系统通过对知识图谱的学习表征,使相关实体得到了低维表征,减少了模型的复杂度和工作量。但是在知识图谱中除了有大量实体外还有丰富的实体关系,表达了实体间的语义关系。基于嵌入的方法没有考虑到知识图谱中信息间的连接关系,导致推荐系统的可解释性不强,用户信任度不高将知识图谱和推荐系统进行融合,利用知识图谱中大量的实体和语义关系,可以使相关推荐项目的信息更加丰富,有效缓解了传统推荐系统存在的冷启动和数据稀疏问题,极大提高了推荐的个性化和精确度。研究人员对推荐系统进行深入研究,越来越多推荐模型被提出,推荐的效果也逐步提升,不同模型针对解决的问题也不同,都有各自的优缺点。推荐系统应该根据推荐项目的应用领域,数据集以及数据规模适时地选择合适的模型。表7列举了基于知识图谱推荐系统中各类方法中的经典模型,并对各类模型优缺点进行总结。在表8中还将传统推荐系统和知识图谱推荐系统评价指标进行对比,推荐系统常见的评价指标为Acc、AUC、Recall、Precision、RMSE等,根据表8的对比可以看出通常情况下知识图谱推荐系统优于传统推荐系统CFKG模型通过定义一个用户-商品知识图谱对传统的协同过滤算法进行扩展。在用户-商品的知识图谱中将用户、项目及其相关属性作为实体,用户的一些历史行为,如购买、点击等被作为实体之间的关系,还包含了各种商品的辅助信息,如用户评价、商品品牌、品类、购买组合等。CFKG模型利用结构化的数据深度挖掘用户的喜好,根据历史行为数据为用户提供了符合个性化的推荐。通过知识图谱中的信息弥补了传统协同过滤推荐存在的冷启动和数据稀疏问题。但CFKG模型使用了联合学习法,模型的训练周期较长,当目标函数不同时需要进行调整大多数知识图谱推荐系统均可以通用到多个领域,通用的推荐模型也能够适用于多种数据集。其优点为适用范围广泛、使用方便,但其也存在针对性不强等问题,相同的推荐系统模型在不同的领域推荐效果有时差异较大。尤其面向某些特定领域,通用的推荐模型无法满足用户的个性化需求,因此研究者为了提高推荐效率,提出了针对特定领域的特定知识图谱推荐模型,从而有效地提高推荐准确性,更好地满足用户需求基于传播的方法结合了基于元结构和基于路径嵌入方法的优点,通过路径中的传播思想更加细化用户和项目的表示,在推荐系统中可以得到更加精确的结果。但是相比于其它两种方法,利用传播思想的模型计算量较大,参数优化复杂,系统能源消耗大。如何解决这些问题,使复杂的模型有更加精确、高效的推荐结果值得进一步研究成都头部医美机构之一、四川华美紫馨医学美容医院2020年整体营收约6亿元。该院总经理薛红介绍,医院每年治疗人数中约20%都是专程前来的外地消费者。',
'“尤其最近几年,这部分消费者数量增长很快,来自甘肃、青海、云南、贵州等各个省份的都有。多任务学习法。将嵌入模块和推荐模块设计成了相关又分离的任务,将这些任务放在同一个框架中进行交替学习,Wang等人[43]提出了MKR模型,Cao等人[44]提出了KTUP模型。典型的例子就是MRK模型。该模型是由KGE模块和推荐模块组成的,将知识图谱以三元组的形式输入KGE模块,通过KGE模块预测出尾实体。用户和项目的特征表示作为推荐模块的输入,通过推荐模块得到项目点击率的估计值。在KGE模块和推荐模块中间有一个交叉特征共享单元,两个模块可以通过该共享单元进行数据交换,这样就可以得到用户的最终表示uL,如公式(6)所示。项目的最终表示vL,如公式(7)所示。其中vL是由L个交叉压缩单元提取的特征,CL是第L层的交叉特征矩阵,Sv表示的是项目v的相关实体集合。公式(8)为预测函数,目的是将用户的最终表示uL和项目的最终表示vL结合起来。”',
'动态知识图谱[87]和动态推荐系统[88]。随着图神经网络和图卷积网络技术的成熟发展知识图谱推荐系统已经有了良好的性能。但现在信息的更新速度快,实时性强,目前已有的知识图谱都是在一定时间内创建的,信息更新不及时。搭建动态知识图谱,可以考虑在知识图谱数据中加入时间信息,利用时序分析技术和图相似性技术,分析图谱结构随时间的变化和趋势,从而掌握到关键信息。知识图谱构建的工程量较大,如何在短时间内将信息导入知识图谱,实现知识图谱的实时更新值得进一步研究基于上述分析,可以得出知识图谱推荐系统提高了推荐准确性、应用广泛、缓解了传统推荐系统存在的冷启动问题和数据稀疏问题。但由于信息量持续膨胀,信息时效性增强,如何利用时效信息快速推荐,并且实现跨领域和多方法推荐使知识图谱推荐系统能够适应不同的应用需求,还存在着很多有待研究、解决的问题。本节针对知识图谱推荐系统的时效性和融合性对未来研究问题进行展望电子商务:由于网购的普及和发展,针对电子商务推荐的研究也逐渐增多[84]。和其它的推荐任务相比,电子商务推荐的数据量很大,常用的数据集是从豆瓣收集来的。也有些论文使用了Taobao数据集。Douban[85]数据集中包含了服装、电子产品、音乐、电影等多个子数据集,数据集中不仅有用户和商品的属性,还有用户的评价和用户的交互历史信息,这些数据使用户和项目的表示更加丰富,有助于提高推荐效果。特定领域知识图谱推荐系统中的CFKG模型使用了Amazon电子商务数据集,CFKG模型选取了Amazon数据集中的CDs & Vinyl、Clothing、Cell Phone和Beauty五个子数据集,每个子数据集中到包含了大量的用户和项目以及交互数据,其中每个用户或产品只会有5个相关的评论信息,所以数据集中用户、项目和实体之间的交互是十分稀疏的电影:在传统的推荐系统中电影推荐和图书推荐一样,是最常见的推荐任务之一。电影推荐任务和图书推荐不同之处在于,电影中包含大量视频信息和音频信息[77]。在电影推荐中常用的数据集是MovieLens[78]数据集和DoubanMovie[79]数据集。MovieLens数据集分为MovieLens-20M、MovieLens-1M和MovieLens-100K数据集。常用的是MovieLens-1M和MovieLens-100K数据集。MovieLens-1M中有三份数据集,ratings中是用户对电影的评分数据,users中是用户的相关数据信息,movies中是电影的相关数据信息。MovieLens-100K数据集是最小的,和MovieLens-1M不同的是各个用户都有独立的文件。MovieLen数据集中的数据是显式反馈数据,使用该数据集时要将显式反馈数据转换为隐式反馈数据,其中每个条目都标记为1,每个用户会设置一个未观看集,未观看集中的数据被标记为0。MovieLens的评级阈值为4。DoubanMovie数据集包含31441条电影的相关记录,每条记录中都有电影ID、电影名称、电影上映年份、电影类型等相关信息基于路径的推荐系统考虑到嵌入方法的缺点,根据知识图谱中路径表达的语义关系进行推荐。在基于路径的推荐中元路径方法需要手动设计元路径,工作量大,由于各领域数据元结构不同,导致该方法的应用领域有限。基于路径嵌入的方法不需要手动设计,融合了语义信息,但是路径过多导致模型复杂、计算量大、系统开销也大',
]
# 加载停用词表
stopwords = get_stop_words()
sentences_cut = cut_words(sentences_list, stopwords, save_path='第2题/data.txt')
print(sentences_cut)
model = train_word2vec(words_file='第2题/data.txt')
print("相似度计算:", model.wv.most_similar(['知识', '辅助']))
3.模型训练以及保存和测试
import gensim
from gensim.models import Word2Vec, word2vec
# 加载语料库
#sentences = [["cat", "say", "meow"], ["dog", "say", "woof"]]
# 训练模型
words_file='data.txt'
#words_file是词语文件的名称,其中包含一行一个词语的文本。
#word2vec.LineSentence是gensim库中的语料生成器,它可以将一个文件转换为词语列表。
sentences = list(word2vec.LineSentence(words_file)) # 加载分词后的文件
#sentences是训练语料库,是一个列表,每一个元素是一个词列表,表示一个句子
#size参数指定词向量的维数。
#window参数指定在一个句子中,一个词的上下文词的数量
#min_count参数指定在训练模型时,词频低于指定数量的词将被忽略
#workers参数指定训练模型时使用的工作线程数
model = gensim.models.Word2Vec(sentences, size=100, window=5, min_count=1, workers=4)
# 保存模型
model.save("word2vec.model")
# 加载模型
model = gensim.models.Word2Vec.load("word2vec.model")
# 测试五组词的相似度
test_words = ["数据", "领域", "规模", "融合", "模型"]
for word in test_words:
similar_words = model.wv.most_similar(word)
print("Word:", word)
print("Similar words:", similar_words)
运行结果图
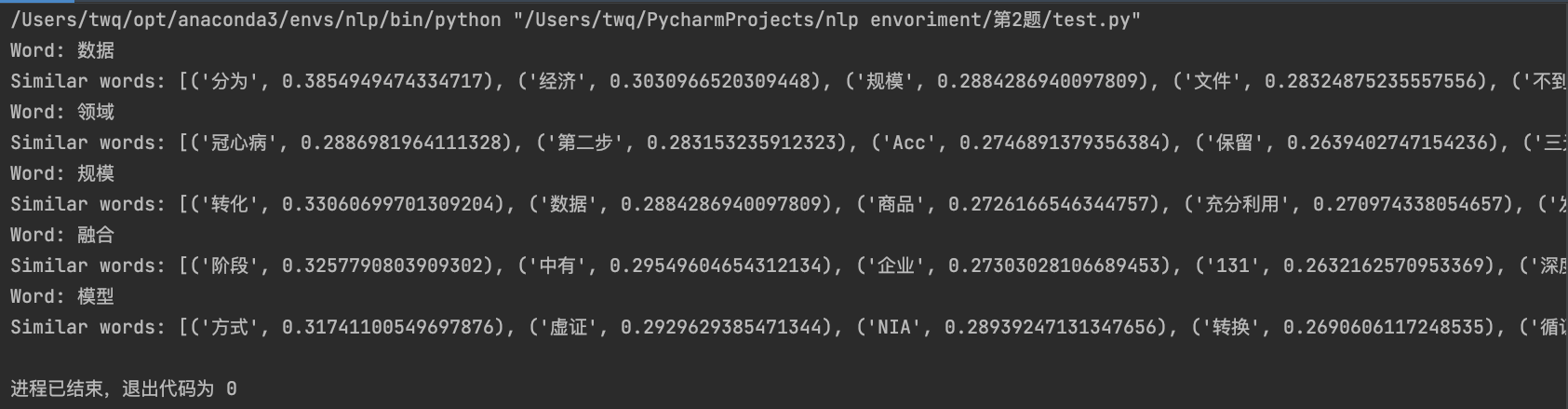
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:使用gensim框架和随机文本训练Word2Vector模型 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 