1 介绍
在MySQL数据库查询过程中,索引覆盖和避免不必要的回表,是减少检索步骤,提高执行效率的有效手段。下面从这两个角度分析如何进行MySQL检索提效。
2 数据准备
模拟一个500w数据容量的部门表 emp,表结构如下,并通过工具模拟500w的数据:
CREATE TABLE `emp` (
`id` int unsigned NOT NULL AUTO_INCREMENT,
`empno` int unsigned DEFAULT NULL,
`empname` varchar(50) DEFAULT NULL,
`job` varchar(50) DEFAULT NULL,
`mgr` int DEFAULT 1,
`hiredate` datetime DEFAULT NULL ,
`sal` int DEFAULT 0,
`comn` int DEFAULT 0,
`depno` int DEFAULT 100,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2345 DEFAULT CHARSET=utf8;
3 分析一下回表
3.1 回表的概念
先来了解两个基本概念,一级索引和二级索引:
- 一级索引:索引和数据存储在一起,在同一个B+tree中的叶子节点中。一般主键索引都是一级索引。
- 二级索引:二级索引树的叶节点仅存储主键而没有数据。当找到索引后,拿到对应的主键,再回到一级索引中找主键对应的数据记录。
回表的本质就是:通过二级索引找到B+树中的叶子结点,但二级索引的叶子节点的内容并不完全,只有索引列的值和主键key值。
我们需要拿主键值再去主键(聚集)索引的叶子节点中去获取完整的数据,这样的查询等同于需要多扫描一棵索引树,这就是回表。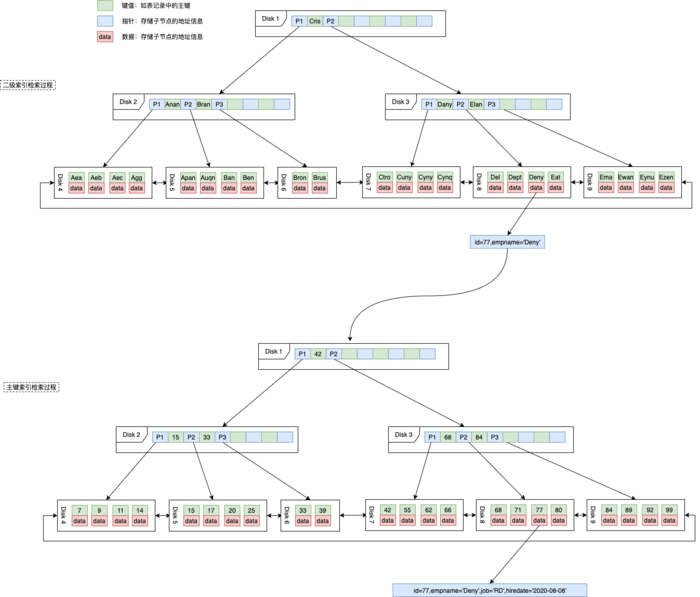

上图中我们以empname二级索引为例,先通过二级索引找到叶结点中的索引的主键Id,在通过回表检索以及索引树,通过该Id获得完整的记录信息。
图中『主键索引检索过程』,表示的就是回表的操作。
2.2 回表的性能代价
从上面那种图中可以看出,我们通过empname字段查找二级索引的叶子节点,再通过回表,最后拿到了我们的需要的数据。
我们来分析下这个的性能问题:
- 我们在empname字段上建立了索引,会通过索引定位数据,避免了全表扫描。
- 根据B+Tree的特性,叶子节点所在的Page,都是通过双向链表进行关的联,遍历检索的效率比较高;
- 同一个索引的叶子节点数据会在多Page磁盘空间中尽量相邻,避免随便IO或多次IO,带来性能损耗。
虽然MySQL做了优化,但是我们的二级索引检索完成之后还是需要拿着主键Id再去主键索引树中再检索一次。在进行回表的时候,也极有可能出现主键id所在的记录在聚簇索引叶子节点不断变化的情况,这样就会导致随机IO。而且如果数据内容不在内存中,还要从磁盘中加载。一个16kb的page,对性能的损耗还是比较大的。
所以,想报保证MySQL执行的效率,我们只能尽量地减少回表操作带来的性能消耗:
- 尽量避免回表
- 如果查询的字段比较多,必须回表,则应该尽量减少回表的次数
既然回表对性能有损,如何避免回表呢?就是查询的字段,通过索引可以直接全部拿到,不需要通过主键索引再次去取。
则该索引称之为索引覆盖,索引覆盖可以提高查询的效率,下面会详细说到。
3 关于索引覆盖
3.1 索引覆盖
什么是索引覆盖么,可以看一下官方的定义:
What is a covering index?
A covering index is a non-clustered index which includes all columns referenced in the query and therefore, the optimizer does not have to perform an additional lookup to the table in order to retrieve the data requested. As the data requested is all indexed by the covering index, it is a faster operation.
大意就是:只需在一棵索引树上就能获取SQL所需的所有数据元素,无需回表无需额外操作,单次轮询即可,速度更快。
结合我们的emp表来说,如果二级索引上的叶子节点上有我们想要的所有数据,那就不需要回表了。
比如我为empname和job 两个字段创建了一个组合索引,而我们检索的也恰好是这两个字段,这时候单次查找就可以达到目的,不需要回表。
如下图: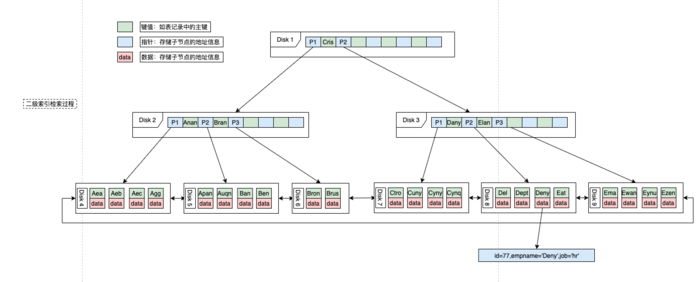
SELECT id, empname, job FROM emp WHERE empname = "Deny";
我们把索引中已经包含了所有需要获取的所有字段的查询方式称为覆盖索引(或索引覆盖)。
3.2 索引覆盖实践
- 建立索引
create index idx_emp_empname_job on emp(empname(5),job);
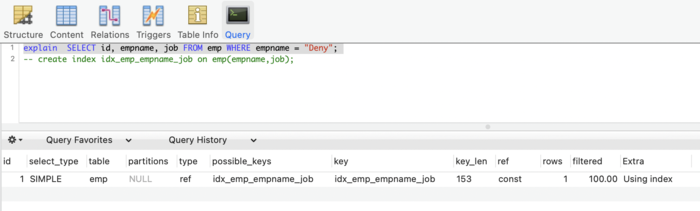
- Explain 执行计划分析
explain SELECT id, empname, job FROM emp WHERE empname = "Deny";
explain的输出结果Extra字段为Using index时,能够触发索引覆盖。如下图:
- 查询优化建议
在上面创建的索引前提下,如果通过empname进行数据检索:
select * from emp where empname = ?
需要需要在name索引中找到name对应的Id,然后通过获取的Id在主键索引中查到对应的行。整个过程需要扫描两次索引,一次empname,一次id。
如果我们查询只想查询id的值,就可以改写SQL为:
select id from emp where empname = ?
因为只需要id的值,通过name查询的时候,扫描完name索引,我们就能够获得id的值了,所以就不需要再去扫面id索引,就会直接返回,避免了回表。
当然,如果你同时需要获取hiredate的值:
select id,empname,hiredate from emp where empname = ?
这样就无法使用到覆盖索引了。
知道了覆盖索引,就知道了为什么sql中要求尽量不要使用select *,要写明具体要查询的字段。其中一个原因就是在使用到覆盖索引的情况下,不需要进入到数据区,数据就能直接返回,提升了查询效率。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:数据库系列:覆盖索引和规避回表 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 