一、爬取目标
您好,我是@马哥python说,今天继续分享爬虫案例。
爬取网站:雪球网的沪深股市行情数据
具体菜单:雪球网 > 行情中心 > 沪深股市 > 沪深一览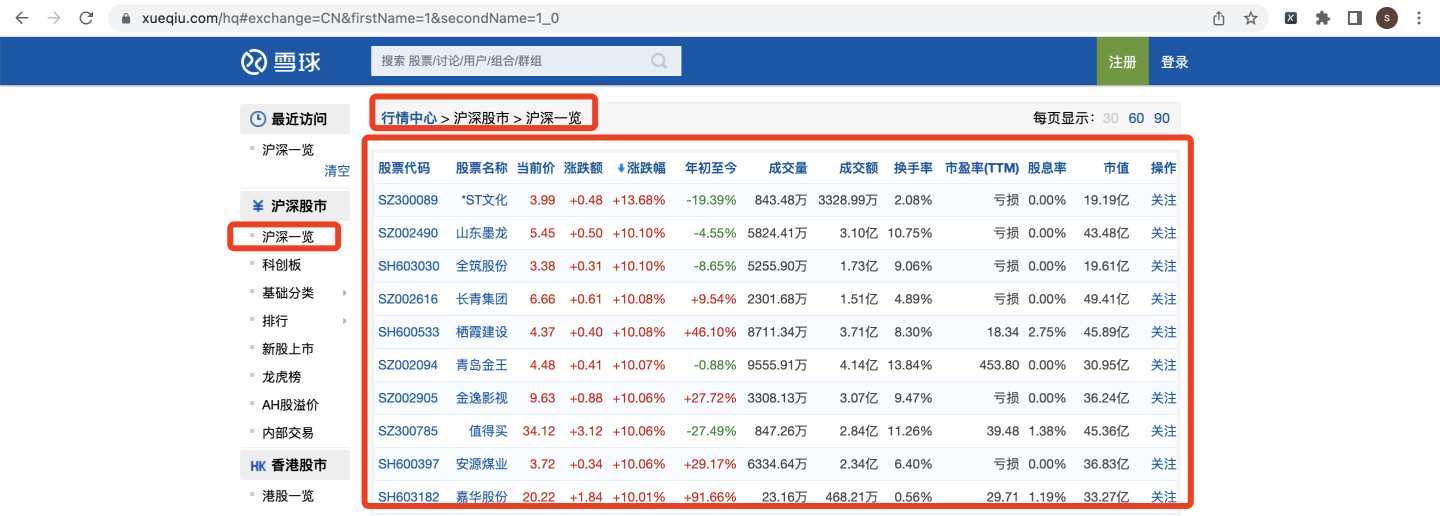

爬取字段,含:
股票代码,股票名称,当前价,涨跌额,涨跌幅,年初至今,成交量,成交额,换手率,市盈率,股息率,市值。
二、分析网页
在网页中,我们注意到,默认每页显示30条: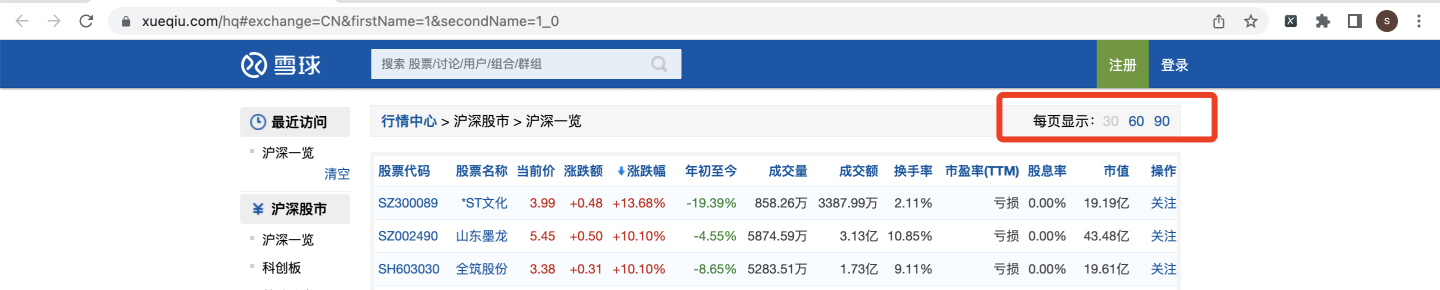
一共163页: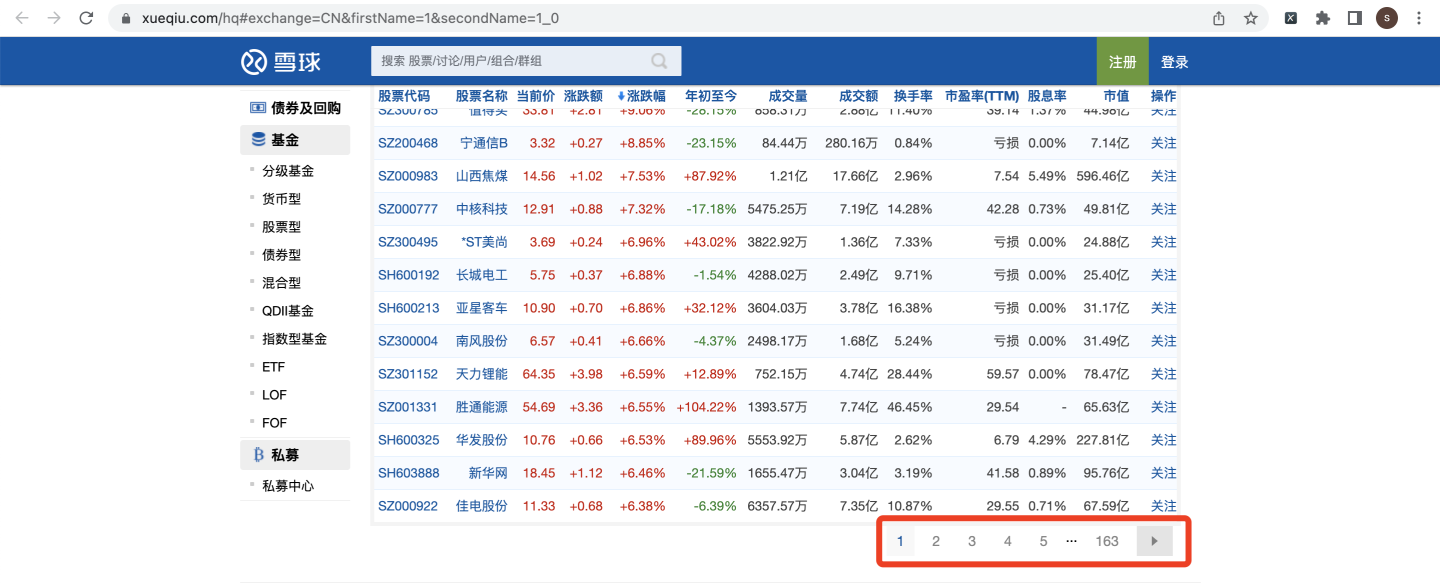
如果切换到每页90条,总页数就会变成55页: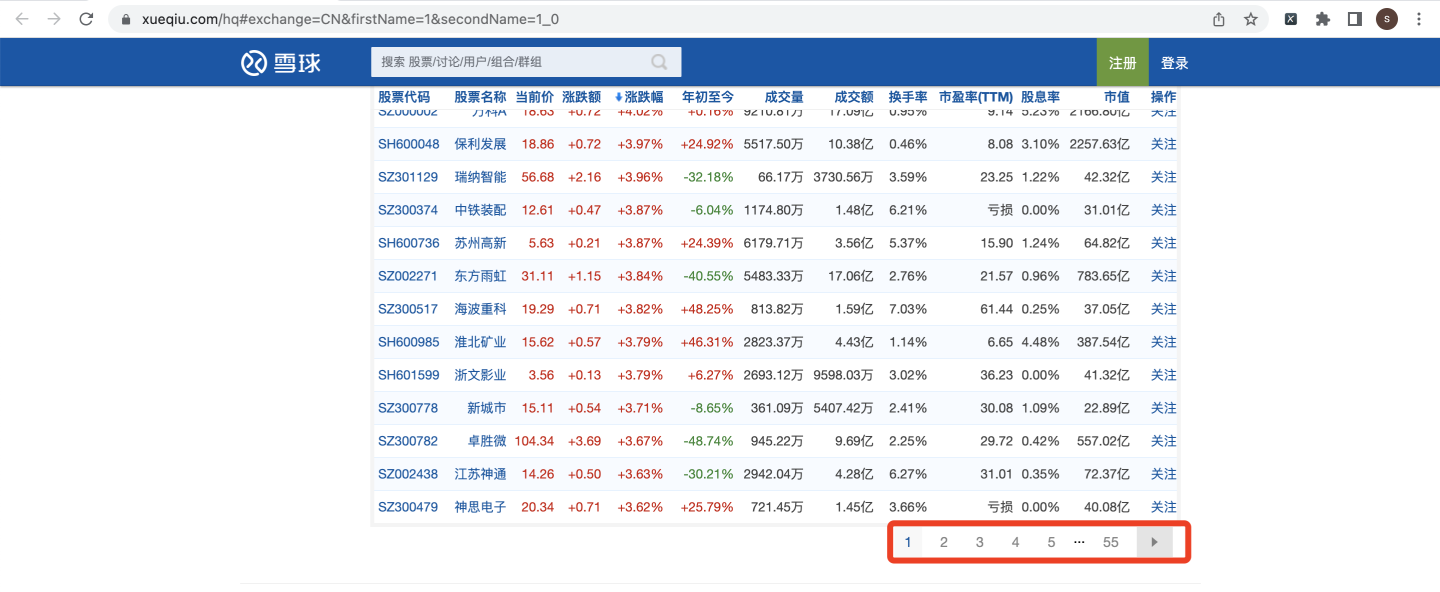
基于尽量少的向页面发送请求,防止反爬的考虑,选择每页90条。
下面,开始分析网页接口。
按F12,打开chrome浏览器的开发者模式,重新刷新网页,并翻页3次,发现3个网页请求: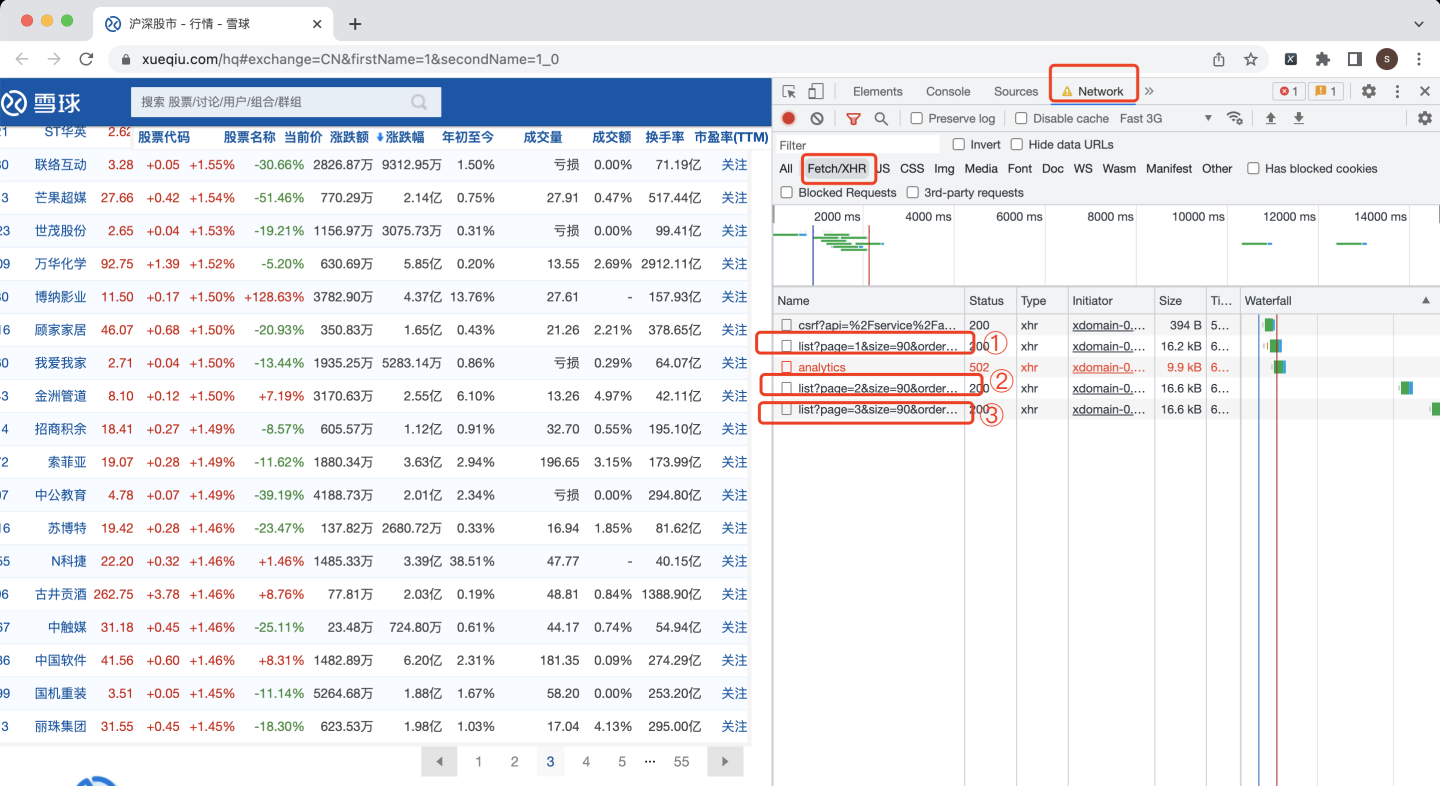
由此推测,这就是目标股票数据。
为了验证此猜测,打开预览页面,展开json数据,找到第0只股票: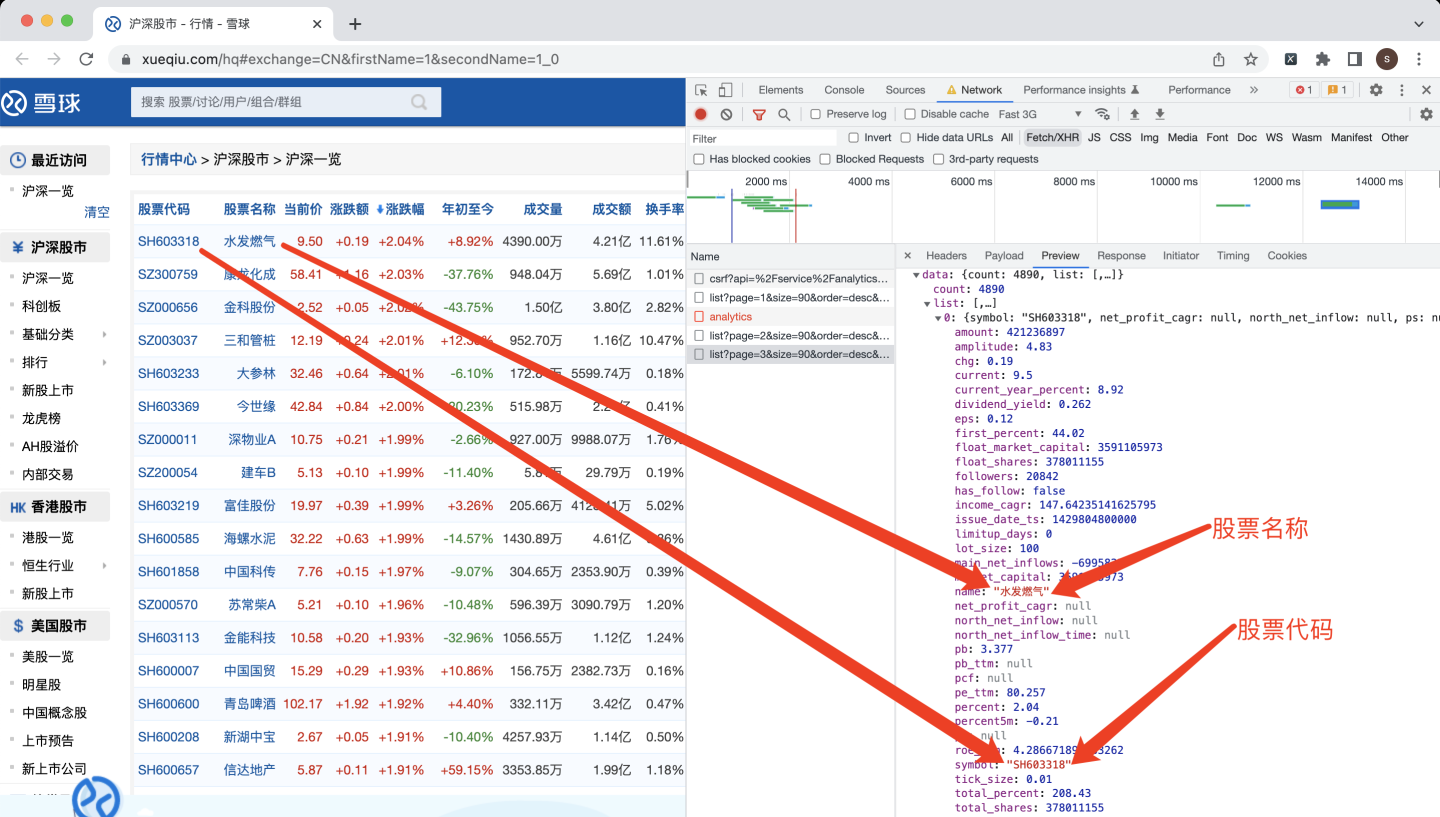
经过和页面对比,发现数据一致。
下面继续看网页请求参数: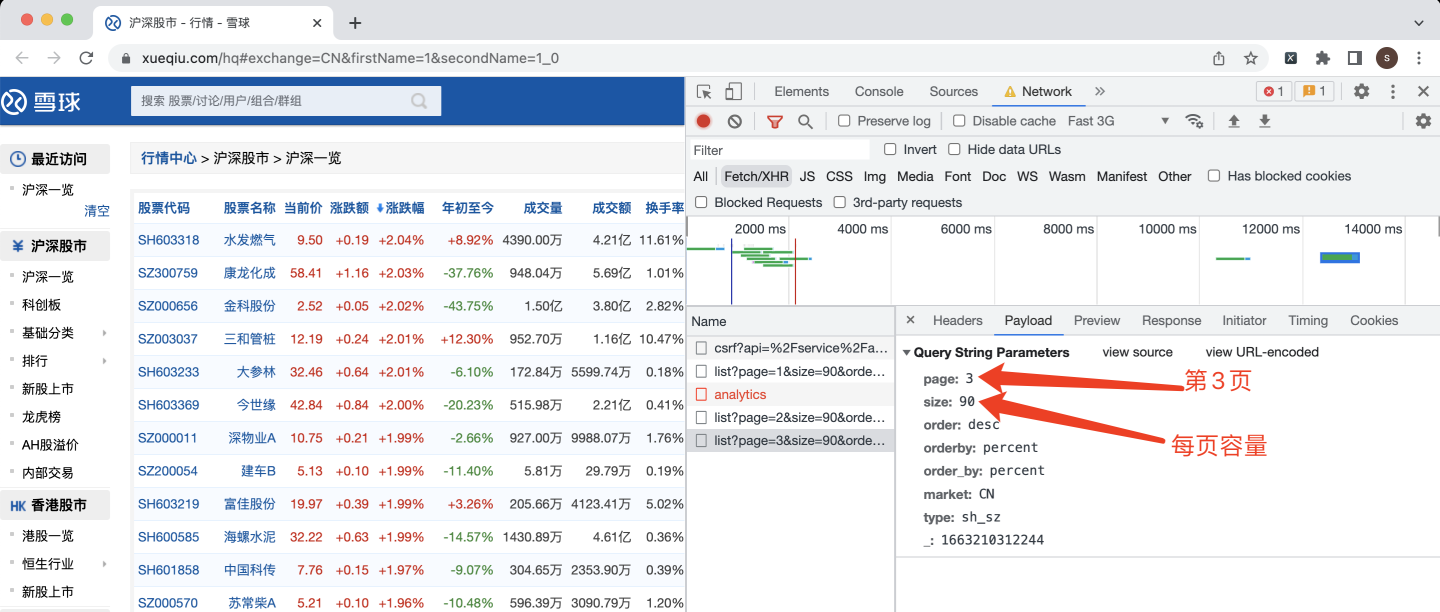
这里每页容量是90条数据,大胆猜测一下,如果每页容量指定为5000,只爬取1页,是不是更省事儿。
虽然大胆猜测,但要小心求证,毕竟一名合格的接口开发者不会这么做。
一般情况下,如果发现用户请求大于每页容量,会返回一个exceed max size或者invalid request之类的error给用户,但我们不妨试试。。
下面开始开发爬虫代码:
三、爬虫代码
首先,定义一个请求头,直接从开发者模式里copy过来:
# 定义字符串请求头
header1 = """
Accept: */*
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7
cache-control: no-cache
Connection: keep-alive
Cookie: 换成自己的
Host: xueqiu.com
Referer: https://xueqiu.com/hq
sec-ch-ua: "Google Chrome";v="105", "Not)A;Brand";v="8", "Chromium";v="105"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "macOS"
Sec-Fetch-Dest: empty
Sec-Fetch-Mode: cors
Sec-Fetch-Site: same-origin
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36
X-Requested-With: XMLHttpRequest
"""
通过copy_headers_dict转换成dict格式:
# 转换成dict格式请求头
header2 = copy_headers_dict(header1)
如此方便!
下面开始发送请求,如上所讲,大胆尝试请求第1页,页容量5000条:
# 请求地址
url = "https://xueqiu.com/service/v5/stock/screener/quote/list?page=1&size=5000&order=desc&orderby=percent&order_by=percent&market=CN&type=sh_sz&_=1663203107799"
# 发送请求
resp = requests.get(url, headers=header2)
查看响应码及响应数据,真的请求到了!
估计过不了多久,雪球网的程序员小哥哥该被领导请去喝茶了~
下面开始解析json数据:
# 解析json数据
json_data = resp.json()
data_list = json_data['data']['list']
先定义一些空列表用于存储数据:
# 定义空列表用于存储数据
symbol_list = [] # 股票代码
name_list = [] # 股票名称
current_list = [] # 当前价
chg_list = [] # 涨跌额
percent_list = [] # 涨跌幅
current_year_percent_list = [] # 年初至今
volume_list = [] # 成交量
amount_list = [] # 成交额
turnover_rate_list = [] # 换手率
pe_ttm_list = [] # 市盈率
dividend_yield_list = [] # 股息率
market_capital_list = [] # 市值
其实,接口里还有更多字段,这里我只爬取了网页上有的字段。
把解析好的字段数据append到空列表中,以股票代码和股票名称为例:
for data in data_list:
symbol_list.append(data['symbol'])
name_list.append(data['name'])
print('已爬取第{}只股票,股票代码:{},股票名称:{}'.format(count, data['symbol'], data['name']))
其他字段同理,不再演示。
最后,把列表数据存入DataFrame数据中:
df = pd.DataFrame(
{
'股票代码': symbol_list,
'股票名称': name_list,
'当前价': current_list,
'涨跌额': chg_list,
'涨跌幅': percent_list,
'年初至今': current_year_percent_list,
'成交量': volume_list,
'成交额': amount_list,
'换手率': turnover_rate_list,
'市盈率': pe_ttm_list,
'股息率': dividend_yield_list,
'市值': market_capital_list,
}
)
最后,用to_csv把最终数据落地成csv文件,大功告成!
四、同步视频
演示视频:
https://www.zhihu.com/zvideo/1553775083570802688
五、get完整源码
附完整源码:点击这里完整源码
我是 马哥python说,感谢阅读!
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:【股票爬虫教程】我用100行Python代码,爬了雪球网5000只股票,还发现一个网站bug! - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 