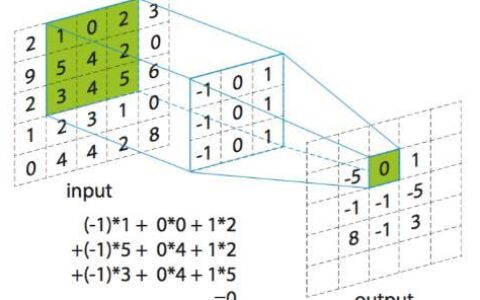
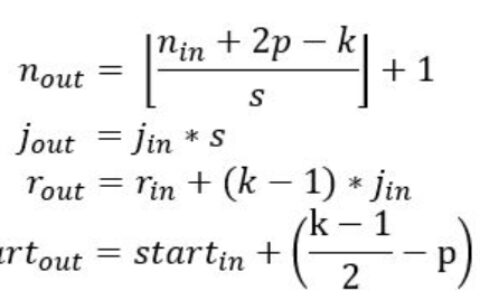现在的卷积实现无非是那么几种:直接卷积、im2col+gemm、局部gemm、wingrod、FFT。如果直接卷积的话,其实kernel函数是比较好实现。以下代码参考至《OpenCL Programing Guide》,主要是main函数各种构造比较麻烦,个人感觉,OpenCL为了追求平台的移植性,使用起来实在是太不方便了。(代码仅表示思路,未测试)
Convolution.cl:
//Convolution.cl __kernel void convolve(const __global uint * const input, __constant uint *const mask, __global uint * const output, const int inputWidth, const int maskWidth) { const int x = get_global_id(0); const int y = get_global_id(1); uint sum =0; for(int r =0;r<maskWidth;r++) { const int idxIntmp = (y +r) *inputWidth +x ; for(int c = 0; c<maskWidth;c++) { sum +=mask[(r*maskWidth) +c] * input[idxIntmp +c]; } } outpu[y* get_global_size(0) +x] = sum; }
//Convolution.cpp
//Convolution.cpp #include <iostream> #include <fstream> #include <sstream> #include <string> #include <CL/cl.h> //Constants const unsigned int inputSignalWidth = 8; const unsigned int inputSignalHeight= 8; cl_uint inputSignal[inputSignalWidth][inputSignalHeight] = { {3, 1, 1, 4, 8, 2, 1, 3 }, {3, 1, 1, 4, 8, 2, 1, 3 }, {3, 1, 1, 4, 8, 2, 1, 3 }, {3, 1, 1, 4, 8, 2, 1, 3 }, {3, 1, 1, 4, 8, 2, 1, 3 }, {3, 1, 1, 4, 8, 2, 1, 3 }, {3, 1, 1, 4, 8, 2, 1, 3 }, {3, 1, 1, 4, 8, 2, 1, 3 } }; const unsigned int outputSignalWidth = 6; const unsigned int outputSignalHeight= 6; cl_uint ouputSignal[outputSignalWidth][outputSignalHeight]; const unsigned int maskWidth = 3; const unsigned int maskHeight= 3; cl_uint mask[maskWidth][maskHeight] = { {1, 1, 1}, {1, 0, 1}, {1, 1, 1} }; inline void checkErr(cl_int err, const char* name) { if(err != CL_SUCCESS) { std::cerr <<"ERROR: "<< name <<" (" << err << ")"<<std::endl; exit(EXIT_FAILURE); } } void CL_CALLBACK contextCallback(const char * errInfo, const void * private_info, size_t cb, void * user_data) { std::cout << "Error occurred during context user: "<< errInfo << std::endl; exit(EXIT_FAILURE); } int main(int argc, char** argv) { cl_int errNum; cl_uint numPlatforms; cl_uint numDevices; cl_platform_id * platformIDs; cl_context context =NULL; cl_command_queue queue; cl_program program; cl_kernel kernel; cl_mem inputSignalBuffer; cl_mem outputSignalBuffer; cl_mem maskBuffer; errNum = clGetPlatformIDs(0, NULL, &numPlatforms); checkErr( (errNum != CL_SUCCESS )? errNum: (numPlatforms <= 0 ? -1: CL_SUCCESS),"clGetPlatformIDs"); deviceIDs = NULL; cl_uint i; for(i =0; i <numPlatforms; i++) { errNum = clGetDeviceIDs(platformIDs[i], CL_DEVICE_TYPE_CPU, 0, NULL, &numDevices); if(errNum != CL_SUCCESS && errNum !=CL_DEVICE_NOT_FOUND) { checkErr(errNum, "clGetDeviceIDs"); } else if(numDevices > 0) { deviceIDs = (cl_device_id *)alloca(sizeof(cl_device_id) * numDevices); break; } } cl_context_properties contextProperties[] = { CL_CONTEXT_PLATFORM, (cl_context_properties)platformIDs[i], 0 }; context = clCreateContext(contextProperties, numDevices, deviceIDs,&contextCallback, NULL, &errNum); checkErr(errNum, "clCreateContext"); std::ifstream srcFile("Convolution.cl"); std::string srcProg(std::istreambuf_iterator<char>(srcFile),(std::istreambuf_iterator<char>())); const char * src = srcProg.c_str(); size_t length = srcProg.length(); program = clCreateProgramWithSource(context, 1, &src, &length, &errNum); checkErr(errNum, "clCreateProgramWithSource"); errNum = clBuildProgram(program, numDevices, deviceIDs, NULL, NULL, NULL); checkErr(errNum, "clBuildProgram"); kernel = clCreateKernel(program, "convolve", &errNum); checkErr(errNum, "clCreateKernel"); inputSignalBuffer = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, sizeof(cl_uint) * inputSignalHeight * inputSignalWidth, static_cast<void*> (inputSignal), &errNum); checkErr(errNum, "clCreateBuffer(inputSignal)"); maskBuffer = clCreateBuffer(context,CL_MEM_READ_ONLY| CL_MEM_COPY_HOST_PTR, sizeof(cl_uint)* maskHeight *maskWidth, static_cast<void*>(mask), &errNum); checkErr(errNum, "clCreateBuffer(mask)"); outputSignalBuffer= clCreateBuffer(context,CL_MEM_WRITE_ONLY ,sizeof(cl_uint)* outputSignalHeight *outputSignalWidth, NULL, &errNum); checkErr(errNum, "clCreateBuffer(outputSignal)"); queue = clCreateCommandQueue(context, deviceIDs[0], 0, &errNum); checkErr(errNum, "clCreateCommandQueue"); errNum = clSetKernelArg(kernel, 0, sizeof(cl_mem), &inputSignalBuffer); errNum |=clSetKernelArg(kernel, 1, sizeof(cl_mem), &maskBuffer); errNum |=clSetKernelArg(kernel, 2, sizeof(cl_mem), &outputSignalBuffer); errNum |=clSetKernelArg(kernel, 3, sizeof(cl_uint),&inputSignalWidth); errNum |=clSetKernelArg(kernel, 4, sizeof(cl_uint),&maskWidth); checkErr(errNum, "clSetKernelArg"); const size_t globalWorkSize[1] = {outputSignalWidth *outputSignalHeight}; const size_t localWorkSize[1] = {1}; errNum = clEnqueueNDRangeKernel(queue,kernel, 1, NULL, globalWorkSize, localWorkSize, 0, NULL, NULL); checkErr(errNum, "clEnqueueNDRangeKernel"); errNum = clEnqueueReadBuffer(queue, outputSignalBuffer,CL_TRUE, 0, sizeof(cl_uint)*outputSignalHeight*outputSignalWidth, outputSignal, 0, NULL, NULL); checkErr(errNum, "clEnqueueReadBuffer"); return 0; }
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:OpenCl入门——实现简单卷积 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫