在各种python的项目中,我们时常要持久化的在系统中存储各式各样的python的数据结构,常用的比如字典等。尤其是在云服务类型中的python项目中,要持久化或者临时的在缓存中储存一些用户认证信息和日志信息等,最典型的比如在数据库中存储用户的token信息。在本文中我们将针对三种类型的python持久化存储方案进行介绍,分别是json、pickle和python自带的数据库sqlite3。
使用json存储字典对象
json格式的数据存储也是云服务项目中常用的类型,具备十分轻量级和易使用的特性,这里我们展示一个案例:如何使用json格式存储一个用python产生的斐波那契数列。斐波那契数列中的每一个元素,都等于前一个数和前前一个数的和,即: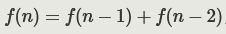

,而最常见的斐波那契数列的前两位数都是1。如下是一个产生斐波那契数列的python代码:
import json
number = {1:1, 2:1}
for i in range(3, 11):
number[i] = number[i - 1] + number[i - 2]
print (number)
代码的执行结果如下:
[dechin@dechin-manjaro store_class]$ python3 json_dic.py
{1: 1, 2: 1, 3: 2, 4: 3, 5: 5, 6: 8, 7: 13, 8: 21, 9: 34, 10: 55}
我们可以从结果中看到,第10个斐波那契数是55。接下来我们来看看这样的一个字典,如何持久化的存储到json格式的文件中,以下是一个使用的示例:
import json
number = {1:1, 2:1}
for i in range(3, 11):
number[i] = number[i - 1] + number[i - 2]
with open('number.json', 'w') as file:
json.dump(number, file)
with open('number.json', 'r') as file:
data = json.load(file)
print (data)
执行这个python文件,我们可以获得如下所示的输出:
[dechin@dechin-manjaro store_class]$ python3 json_dic.py
{'1': 1, '2': 1, '3': 2, '4': 3, '5': 5, '6': 8, '7': 13, '8': 21, '9': 34, '10': 55}
这里我们发现在当前目录下产生了一个json的文件:
[dechin@dechin-manjaro store_class]$ ll
总用量 8
-rw-r--r-- 1 dechin dechin 265 3月 20 12:32 json_dic.py
-rw-r--r-- 1 dechin dechin 85 3月 20 12:32 number.json
我们可以看一下这个json文件中存储了什么样的数据:
[dechin@dechin-manjaro store_class]$ cat number.json
{"1": 1, "2": 1, "3": 2, "4": 3, "5": 5, "6": 8, "7": 13, "8": 21, "9": 34, "10": 55}
在验证了相关的数据已经被持久化存储了之后,同时我们也注意到一个问题,我们产生斐波那契数列的时候,索引1,2,3...
使用的是整型变量,但是存储到json格式之后,变成了字符串格式。我们可以使用如下的案例来说明这其中的区别:
import json
number = {1:1, 2:1}
for i in range(3, 11):
number[i] = number[i - 1] + number[i - 2]
with open('number.json', 'w') as file:
json.dump(number, file)
with open('number.json', 'r') as file:
data = json.load(file)
print (data)
print (number[10])
print (data['10'])
print (data[10])
执行的输出如下:
[dechin@dechin-manjaro store_class]$ python3 json_dic.py
{'1': 1, '2': 1, '3': 2, '4': 3, '5': 5, '6': 8, '7': 13, '8': 21, '9': 34, '10': 55}
55
55
Traceback (most recent call last):
File "json_dic.py", line 16, in <module>
print (data[10])
KeyError: 10
这里的输出就有一个报错信息,这是因为我们使用了整型索引变量来寻找json存储的字典对象中对应的值,但是因为前面存储的时候这些整型的索引已经被转换成了字符串的索引,因此实际上在存储的对象中已经不存在整型的键值,所以执行结果会报错,而如果输入的是字符串类型的键值,则成功的找到了第10个斐波那契数。
使用pickle存储字典对象
关于斐波那契数列的信息,在上一章节中已经介绍,这里我们直接进入pickle的使用案例:
import pickle
number = {1:1, 2:1}
for i in range(3, 11):
number[i] = number[i - 1] + number[i - 2]
with open('number.pickle', 'wb') as file:
pickle.dump(number, file)
with open('number.pickle', 'rb') as file:
data = pickle.load(file)
print (data)
这里注意一个细节,在json格式的存储中我们使用的文件打开格式是w,而在pickle这里我们使用的存储文件打开格式是wb,pickle的读取也是用的rb的二进制的读取格式。上述代码的执行输出结果如下:
[dechin@dechin-manjaro store_class]$ python3 pickle_dic.py
{1: 1, 2: 1, 3: 2, 4: 3, 5: 5, 6: 8, 7: 13, 8: 21, 9: 34, 10: 55}
这里我们可以发现,由pickle所存储的字典格式中的整型的索引也被成功的存储起来,在当前目录下产生了一个名为number.pickle的文件就是持久化存储的对象。
[dechin@dechin-manjaro store_class]$ ll
总用量 12
-rw-r--r-- 1 dechin dechin 320 3月 20 12:45 json_dic.py
-rw-r--r-- 1 dechin dechin 85 3月 20 12:46 number.json
-rw-r--r-- 1 dechin dechin 56 3月 20 12:44 number.pickle
-rw-r--r-- 1 dechin dechin 279 3月 20 12:44 pickle_dic.py
类似于json格式中的持久化读取验证,我们也可以简单修改一个类似的pickle的案例:
import pickle
number = {1:1, 2:1}
for i in range(3, 11):
number[i] = number[i - 1] + number[i - 2]
with open('number.pickle', 'wb') as file:
pickle.dump(number, file)
with open('number.pickle', 'rb') as file:
data = pickle.load(file)
print (data)
print (number[10])
print (data[10])
执行结果如下所示:
{1: 1, 2: 1, 3: 2, 4: 3, 5: 5, 6: 8, 7: 13, 8: 21, 9: 34, 10: 55}
55
55
从结果中我们发现存储后的对象用一样的读取格式被成功读取。
使用sqlite3存储字典对象
在常用的Linux操作系统中都会自带sqlite3数据库,如果是windows和Mac的操作系统,可以按照这个教程中给的方案进行安装。
SQLite是一个进程内的库,实现了自给自足的、无服务器的、零配置的、事务性的 SQL 数据库引擎。它是一个零配置的数据库,这意味着与其他数据库不一样,您不需要在系统中配置。
就像其他数据库,SQLite引擎不是一个独立的进程,可以按应用程序需求进行静态或动态连接。SQLite直接访问其存储文件。
同时在python3的库中一般也自带了sqlite3,不需要自己安装,下面我们用ipython演示一下如何在python中使用sqlite3数据库:
[dechin@dechin-manjaro store_class]$ ipython
Python 3.8.5 (default, Sep 4 2020, 07:30:14)
Type 'copyright', 'credits' or 'license' for more information
IPython 7.19.0 -- An enhanced Interactive Python. Type '?' for help.
In [1]: import sqlite3
In [2]: conn = sqlite3.connect('test_sqlite3.db') # 如果有db文件就读取,没有就创建
In [3]: cur = conn.cursor()
In [8]: sql_test_1 = '''CREATE TABLE number
...: (i NUMBER,
...: n NUMBER);''' # 创建一个名为number的表,有两列数据i和n作为键值对
In [9]: cur.execute(sql_test_1) # 执行字符串指令
Out[9]: <sqlite3.Cursor at 0x7f6fb14acc70>
In [10]: sql_test_2 = "INSERT INTO number VALUES(1,1)" # 插入新的数据
In [11]: cur.execute(sql_test_2)
Out[11]: <sqlite3.Cursor at 0x7f6fb14acc70>
In [12]: sql_test_2 = "INSERT INTO number VALUES(2,1)"
In [13]: sql_test_3 = "INSERT INTO number VALUES(2,1)"
In [14]: cur.execute(sql_test_3)
Out[14]: <sqlite3.Cursor at 0x7f6fb14acc70>
In [15]: sql_test_4 = "SELECT * FROM number WHERE i=1" # 检索数据
In [16]: cur.execute(sql_test_4)
Out[16]: <sqlite3.Cursor at 0x7f6fb14acc70>
In [17]: cur.fetchall()
Out[17]: [(1, 1)]
In [18]: sql_test_5 = "SELECT * FROM number WHERE i>=1"
In [19]: cur.execute(sql_test_5)
Out[19]: <sqlite3.Cursor at 0x7f6fb14acc70>
In [20]: cur.fetchall() # 读取检索返回值
Out[20]: [(1, 1), (2, 1)]
In [21]: for i in range(3, 11):
...: sql_test_6 = "SELECT * FROM number WHERE i={}".format(i-1)
...: cur.execute(sql_test_6)
...: select_result1 = cur.fetchall()[0][1]
...: sql_test_7 = "SELECT * FROM number WHERE i={}".format(i-2)
...: cur.execute(sql_test_7)
...: select_result2 = cur.fetchall()[0][1]
...: cur.execute("INSERT INTO number VALUES({},{})".format(i, select_result1+select_res
...: ult2))
...:
In [22]: sql_test_8 = "SELECT * FROM number WHERE i>=1"
In [23]: cur.execute(sql_test_8)
Out[23]: <sqlite3.Cursor at 0x7f6fb14acc70>
In [24]: cur.fetchall()
Out[24]:
[(1, 1),
(2, 1),
(3, 2),
(4, 3),
(5, 5),
(6, 8),
(7, 13),
(8, 21),
(9, 34),
(10, 55)]
In [25]: exit() # 退出ipython
在上述示例中我们演示了如何使用sqlite3创建数据库和表,以及对表的内容的一些常用操作。在执行完上述示例后,会在当前目录下产生一个新的db文件:
[dechin@dechin-manjaro store_class]$ ll
总用量 24
-rw-r--r-- 1 dechin dechin 320 3月 20 12:45 json_dic.py
-rw-r--r-- 1 dechin dechin 85 3月 20 12:46 number.json
-rw-r--r-- 1 dechin dechin 56 3月 20 12:47 number.pickle
-rw-r--r-- 1 dechin dechin 315 3月 20 12:47 pickle_dic.py
-rw-r--r-- 1 dechin dechin 8192 3月 20 13:05 test_sqlite3.db
如果在运行过程中出现如下所示的报错,就代表有其他的进程正在占用这个db文件,因此会有进程将这个数据库进行锁定:
Traceback (most recent call last):
File "sqlite3_dic.py", line 15, in <module>
cur.execute("INSERT INTO number VALUES(1,1)")
sqlite3.OperationalError: database is locked
解决的办法是,首先用fuser查看这个db文件被哪个用户所占用:
[dechin@dechin-manjaro store_class]$ fuser test_sqlite3.db
/home/dechin/projects/2021-python/store_class/test_sqlite3.db: 5120
我们查看到是5120这个进程占用了数据库文件,也是这个进程将数据库锁定了。通常这种情况出现的原因是,在python中执行的数据库操作指令未成功完成,导致数据库的进程没有结束,而我们也无法再通过这个进程向数据库中输入新的指令。因此我们只能通过将该进程杀死的方案来解决这个问题:
[dechin@dechin-manjaro store_class]$ kill -9 5120
还有一个需要注意的点是,上面所用到的数据库操作实际上并未真正的被保存到数据库文件中,需要经过commit之后才会被保存到数据库文件中。接下来我们还是用斐波那契数列的例子来演示数据库操作的使用:
import sqlite3
from tqdm import trange
conn = sqlite3.connect('test_sqlite3.db')
cur = conn.cursor()
try:
sql_test_1 = '''CREATE TABLE number
(i NUMBER,
n NUMBER);'''
cur.execute(sql_test_1)
except:
pass
cur.execute("INSERT INTO number VALUES(1,1)")
cur.execute("INSERT INTO number VALUES(2,1)")
for i in trange(3, 11):
sql_test_6 = "SELECT * FROM number WHERE i={}".format(i - 1)
cur.execute(sql_test_6)
select_result1 = cur.fetchall()[0][1]
sql_test_7 = "SELECT * FROM number WHERE i={}".format(i - 2)
cur.execute(sql_test_7)
select_result2 = cur.fetchall()[0][1]
cur.execute("INSERT INTO number VALUES({},{})".format(i, select_result1 + select_result2))
cur.execute("SELECT * FROM number WHERE i=10")
print (cur.fetchall())
conn.commit()
cur.close()
conn.close()
在上述用例中我们补充了commit操作和close操作,一方面持久化的保存了数据,另一方面也避免因为程序中其他地方的问题而导致了前面所提到的数据库被锁定的问题。我们看一下这个用例的执行输出情况:
[dechin@dechin-manjaro store_class]$ python3 sqlite3_dic.py
100%|█████████████████████████████████████████████████████████| 8/8 [00:00<00:00, 31775.03it/s]
[(10, 55)]
第10个斐波那契数被成功输出,在数据库的输出中,使用的格式是一个列表包含多个元组的形式。其中每一个元组代表一个满足检索条件的键值对,每一个元组中的元素代表每一列的值。
前面提到了持久化保存的问题,我们也用一个简单示例来验证刚才经过commit之后是否被成功的保存起来了:
'''
学习中遇到问题没人解答?小编创建了一个Python学习交流群:153708845
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
import sqlite3
from tqdm import trange
conn = sqlite3.connect('test_sqlite3.db')
cur = conn.cursor()
cur.execute("SELECT * FROM number WHERE i=10")
print (cur.fetchall())
conn.commit()
cur.close()
conn.close()
执行输出如下:
[dechin@dechin-manjaro store_class]$ python3 test_recall_sqlite3.py
[(10, 55)]
这个结果表明前面存储下来的斐波那契数列已经被持久化的保存到了数据库文件中,我们只要链接上该数据库就可以随时的读取该数据。
总结
本文介绍了三种python的字典对象持久化存储方案,包含json、pickle和数据库sqlite,并且配合一个实际案例斐波那契数列来演示了不同解决方案的使用方法。这里三种方案实际上各有优劣,推荐的使用场景为:在轻量级、日常使用中可以重点使用json格式进行对象的存储,我们也可以很方便的在系统上直接查看json格式的文件内容;在多用户或多进程使用的案例中,推荐使用pickle的方案,可以更高性能、更低开销的持久化存储python对象;如果是需要对外提供服务的,我们推荐可以直接使用sqlite,对外可以提供一个数据库查询的解决方案,便不需要在本地存储大量的数据或者可以更方便的对大规模数据进行处理。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:python3教程:json、pickle和sqlite3持久化存储字典对象 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 