摘要:NumPy中包含大量的函数,这些函数的设计初衷是能更方便地使用,掌握解这些函数,可以提升自己的工作效率。这些函数包括数组元素的选取和多项式运算等。下面通过实例进行详细了解。
前述通过对某公司股票的收盘价的分析,了解了某些Numpy的一些函数。通常实际中,某公司的股价被另外一家公司的股价紧紧跟随,它们可能是同领域的竞争对手,也可能是同一公司下的不同的子公司。可能因两家公司经营的业务类型相同,面临同样的挑战,需要相同的原料和资源,并且争夺同类型的客户。
实际中,有很多这样的例子,如果要检验一下它们是否真的存在关联。一种方法就是看看两个公司股票收益率的相关性,强相关性意味着它们之间存在一定的关联性(特别是当所用的数据不够充足时,误差可能更大)
一、股票相关性分析
1、导出两个相关的股票数据,如下依次为:股票代码、日期、开盘价、最高价、最低价、收盘价、成交量。

2、分别从CSV文件中读入相关数据,即收盘价:
close = np.loadtxt('data036.csv',delimiter=',', usecols=(5,),converters={1:datestr2num},unpack=True) new_close = np.loadtxt('data999.csv',delimiter=',', usecols=(5,),converters={1:datestr2num},unpack=True)
3、协方差描述的是两个变量共同变化的趋势,其实就是归一化前的相关系数。使用 cov 函数计算股票收益率的协方差矩阵,完整代码如下:
import numpy as np from datetime import datetime import matplotlib.pyplot as plt def datestr2num(s): #定义一个函数 return datetime.strptime(s.decode('ascii'),"%Y-%m-%d").date().weekday() close=np.loadtxt('data036.csv',delimiter=',', usecols=(5,),converters={1:datestr2num},unpack=True) #导入data036.csv数据
new_close=np.loadtxt('data999.csv',delimiter=',', usecols=(5,),converters={1:datestr2num},unpack=True)#导入data999.csv数据
covariance = np.cov(close,new_close) #使用numpy.cov() 函数计算两个数列的协方差矩阵
print(close.mean()) #求close的平均值
print(new_close.mean())#求new_close的平均值
print('covariance:','n',covariance)
运行结果:
48.40690476190476 18.85157142857143 covariance: [[30.46934553 1.5201865 ] [ 1.5201865 8.96031113]]
1)用 diagonal 函数查看矩阵对角线上的元素
print ("对角元素:", covariance.diagonal()) # diagonal查看对角上的元素
运行结果:
对角元素: [30.46934553 8.96031113]
2)使用 trace 函数计算矩阵的迹,即对角线上元素之和
print("Covariance trace", covariance.trace()) #对角线上元素之和
3)两个向量的相关系数被定义为协方差除以各自标准差的乘积。计算向量 a 和 b 的相关系数的公式:corr(a,b)=cov(a,b)/(std(a)*std(b))
covar = covariance/ (np.std(close) * np.std(new_close)) print("相关系数矩阵:", covar)
运行结果:
相关系数矩阵: [[1.84843969 0.09222295]
[0.09222295 0.54358223]]
注意:由于covariance是一个矩阵,因而得到的covar也是一个矩阵
相关系数是两只股票的相关程度。相关系数的取值范围在 -1 到 1 之间。根据定义,一组数值与自身的相关系数等于 1 ,numpy中使用 corrcoef 函数计算相关系数
closecorr = np.corrcoef(close,new_close) print("相关系数:",'n', closecorr )
运行结果:
相关系数: [[1. 0.09200338] [0.09200338 1. ]]
对角线上的元素即close和new_close与自身的相关系数,因此均为1。相关系数矩阵是关于对角线对称的,因此另外两个元素的值相等,表示close和new_close的相关系数等于new_close和close的相关系数。
判断两只股票的价格走势是否同步的要点是,它们的差值偏离了平均差值2倍于标准差的距离,则认为这两只股票走势不同步。代码如下:
difference = close - new_close avg = np.mean(difference) dev = np.std(difference) print ("Out of sync:", np.abs(difference[-1]-avg)>2*dev)
运行结果:
Out of sync: False
二、多项式
微积分里有泰勒展开,也就是用一个无穷级数来表示一个可微的函数。实际上,任何可微的(从而也是连续的)函数都可以用一个N次多项式来估计,而比N次幂更高阶的部分为无穷小量可忽略不计。
NumPy中的 ployfit 函数可以用多项式去拟合一系列数据点,无论这些数据点是否来自连续函数都适用。
继续使用close和new_close的股票价格数据。用一个三次多项式去拟合两只股票收盘价的差价。
t = np.arange(len(close)) #得到close数列的长度 poly = np.polyfit(t, close - new_close, 3) #利用长度t和两只股票的价差,生成一个三项式,三项式有3个系数和一个常量
print("Polynomial fit", poly)
运行结果:
Polynomial fit: [ 1.61308827e-07 -4.34114354e-04 1.84480028e-01 1.33680483e+01]
用我们刚刚得到的多项式对象以及 polyval 函数,推断下一个差值:
print ("Next value:", np.polyval(poly, t[-1] + 1)) #用生成的多项式拟合求下一个差值
print(difference[-1]) #打印最后一个实际的差值
运行结果:
Next value: 26.222936287829654 26.21
在极限情况下,差值可以在某个点为0。使用 roots 函数找出拟合的多项式函数什么时候到达0值:
print( "Roots", np.roots(poly))#root返回多项式的根
运行结果:
Roots [2138.21411788 615.9134063 -62.92728874]
三、求极值的知识
极值是函数的最大值或最小值。在高等代数微积分中,这些极值点位于函数的导数为0的位置,然后再求导数函数的根,即找出原多项式函数的极值点。
1)使用 polyder 函数对多项式函数求导
der = np.polyder(poly) print("Derivative", der)
2)求出导数函数的根,即找出原多项式函数的极值点
print( "Extremas", np.roots(der))
运行后即得到如下:
Derivative: [ 4.83926482e-07 -8.68228709e-04 1.84480028e-01]
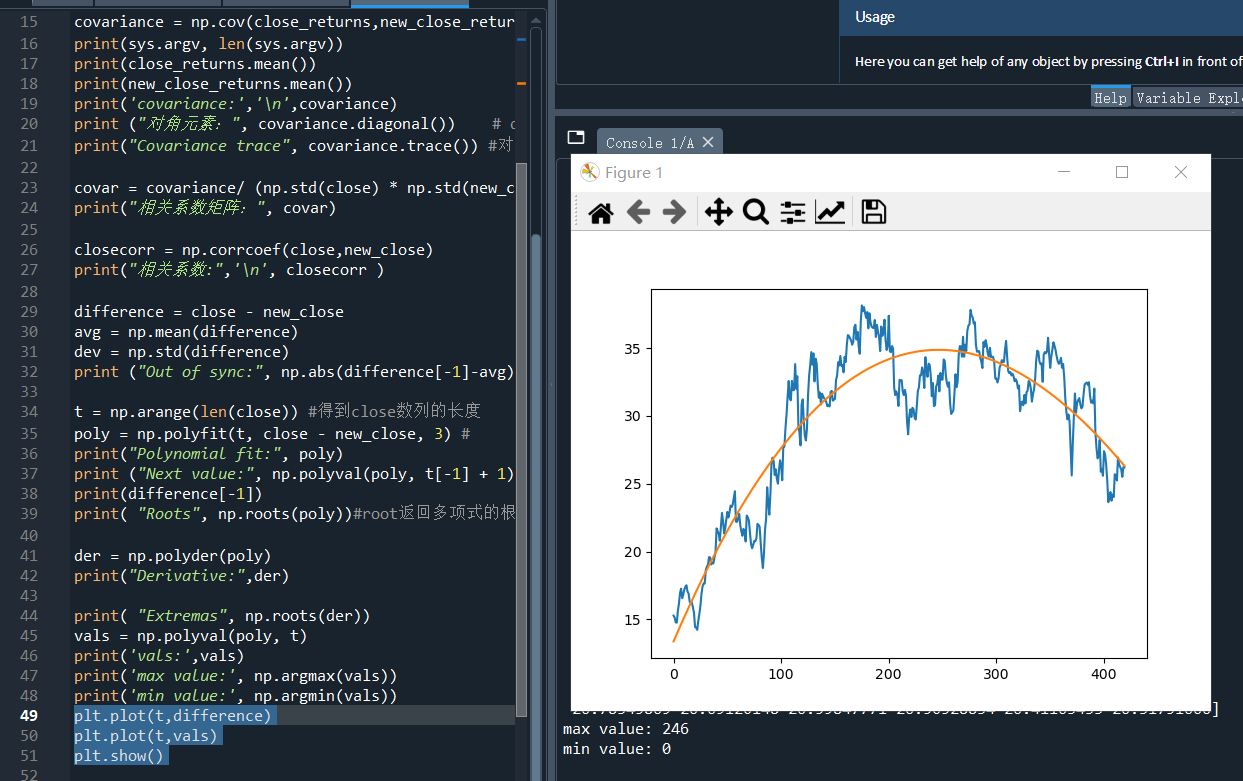
Extremas [1547.84609151 246.28739879]
3)用 polyval 计算多项式函数的值,并用matplotlib显示
vals = np.polyval(poly, t) print('vals:',vals) print('max value:', np.argmax(vals)) print('min value:', np.argmin(vals))
plt.plot(t,difference)
plt.plot(t,vals)
plt.show()
运行结果如下:
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:Python数据分析–Numpy常用函数介绍(5)–Numpy中的相关性函数 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 