春节电影听巳月说都还可以,我不信,我觉得还是要看看看过的观众怎么说,于是我点开了流浪地球2 …


看起来好像不错的样子,8.2的评分,三十多亿的票房
就是这评价也太多了,那我们今天就把网友对它的评论获取下来,做成可视化词云图看看大家讨论最多的是什么。
使用的环境
Python 3.8 解释器
Pycharm 编辑器
需要手动安装的模块
parsel 数据解析模块
requests 数据请求模块
在cmd直接pip安装即可
一、数据来源分析
1、明确需求()
- 采集的网站是什么?
- 采集的数据是什么?
2、抓包分析相关数据来源
通过浏览器自带开发者工具进行抓包分析
- 打开开发者工具: F12 或者 鼠标右键点击检查选择network
- 刷新网页: 让本网页的数据内容重新加载一遍
- 关键字搜索: 通过关键字<要的数据>, 搜索查询相对应的数据包
二. 代码实现步骤
基本四大步骤
-
发送请求:模拟浏览器对于url地址发送请求
-
获取数据:获取服务器返回响应数据
开发者工具 --> response -
解析数据:提取我们想要的数据内容
评论相关数据 -
保存数据:把数据内容保存表格文件里面
发送请求,模拟浏览器对于url地址发送请求
for page in range(0, 200, 20): # 请求链接 url = f'https://movie.douban.com/subject/35267208/comments?start={page}&limit=20&status=P&sort=new_score' # 伪装模拟 headers = { # User-Agent 用户代理, 表示浏览器基本身份标识 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36' } # 发送请求 response = requests.get(url=url, headers=headers) print(response)
获取数据, 获取服务器返回响应数据。
print(response.text)
解析数据,提取我们想要的数据内容。
把获取下来html字符串数据 <response.text>, 转成可解析对象
selector = parsel.Selector(response.text) # 第一次提取, 所有div标签 divs = selector.css('div.comment-item') # for循环遍历, 把列表里面元素一个一个提取出来 for div in divs: name = div.css('.comment-info a::text').get() # 昵称 rating = div.css('.rating::attr(title)').get() # 推荐 date = div.css('.comment-time::attr(title)').get() # 时间 area = div.css('.comment-location::text').get() # 地区 votes = div.css('.votes::text').get() # 有用 short = div.css('.short::text').get().replace('\n', '') # 评论 # 数据存字典里面 dit = { '昵称': name, '推荐': rating, '时间': date, '地区': area, '有用': votes, '评论': short, }
写入数据
csv_writer.writerow(dit) print(name, rating, date, area, votes, short) # 代码仅做参考,完整代码、详细视频讲解在这个q裙 708525271 自取即可
创建文件对象
f = open('data10.csv', mode='a', encoding='utf-8-sig', newline='') csv_writer = csv.DictWriter(f, fieldnames=[ '昵称', '推荐', '时间', '地区', '有用', '评论', ])
写入表头
csv_writer.writeheader()
import pandas as pd import jieba import wordcloud df = pd.read_csv('data10.csv') df.head() info_list = df['评论'].to_list() string = ' '.join(jieba.lcut(''.join(info_list))) string wc = wordcloud.WordCloud( width=1000, height=700, background_color='white', font_path='msyh.ttc', scale=15, ) wc.generate(string) wc.to_file('1.png') evaluate_num = df['推荐'].value_counts().to_list() evaluate_type = df['推荐'].value_counts().index.to_list()
import pyecharts.options as opts from pyecharts.charts import Pie data_pair = [list(z) for z in zip(evaluate_type, evaluate_num)] data_pair.sort(key=lambda x: x[1]) c = ( Pie(init_opts=opts.InitOpts(bg_color="#2c343c")) .add( series_name="豆瓣影评", data_pair=data_pair, rosetype="radius", radius="55%", center=["50%", "50%"], label_opts=opts.LabelOpts(is_show=False, position="center"), ) .set_global_opts( title_opts=opts.TitleOpts( title="推荐分布", pos_left="center", pos_top="20", title_textstyle_opts=opts.TextStyleOpts(color="#fff"), ), legend_opts=opts.LegendOpts(is_show=False), ) .set_series_opts( tooltip_opts=opts.TooltipOpts( trigger="item", formatter="{a} <br/>{b}: {c} ({d}%)" ), label_opts=opts.LabelOpts(color="rgba(255, 255, 255, 0.3)"), ) ) c.render_notebook()
效果展示

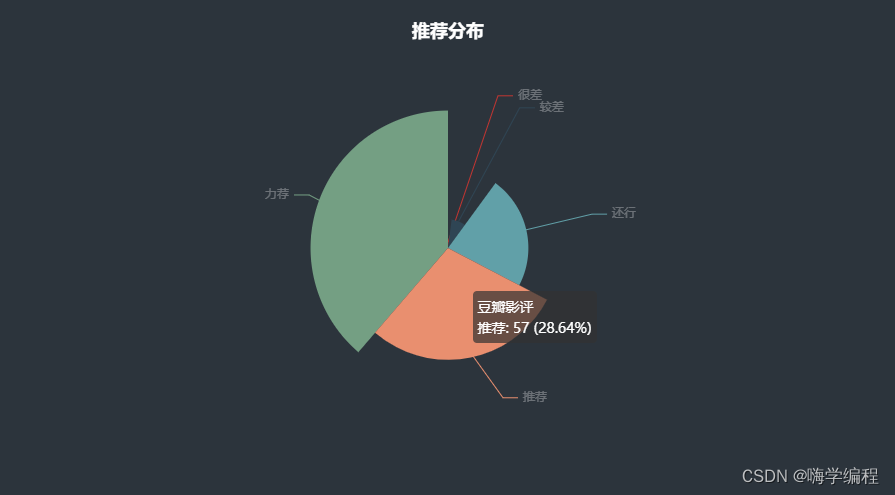
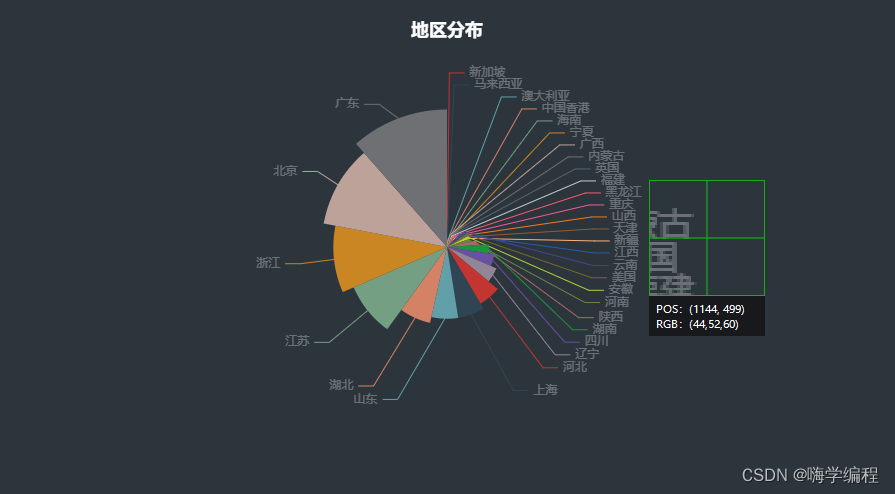
好了今天的分享就到这,大家快去试试吧,下次见!
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:使用Python获取春节档电影影评,制作可视化词云图 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
