

声明
本文章中所有内容仅供学习交流使用,不用于其他任何目的,不提供完整代码,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关!
本文章未经许可禁止转载,禁止任何修改后二次传播,擅自使用本文讲解的技术而导致的任何意外,作者均不负责,若有侵权,请在公众号【K哥爬虫】联系作者立即删除!
逆向目标
- 目标:某验深知 V2 业务风控逆向分析
- 主页:
aHR0cHM6Ly93d3cuZ2VldGVzdC5jb20vZGVtby9kay12Mi5odG1s
深知简介
某验深知通过无感采集客户端数据,对用户的环境、标识、行为操作等进行智能化分析,结合业务场景有效识别有潜在风险的用户。整个识别过程不干扰用户,不打断业务既有流程。完整通讯流程如下:
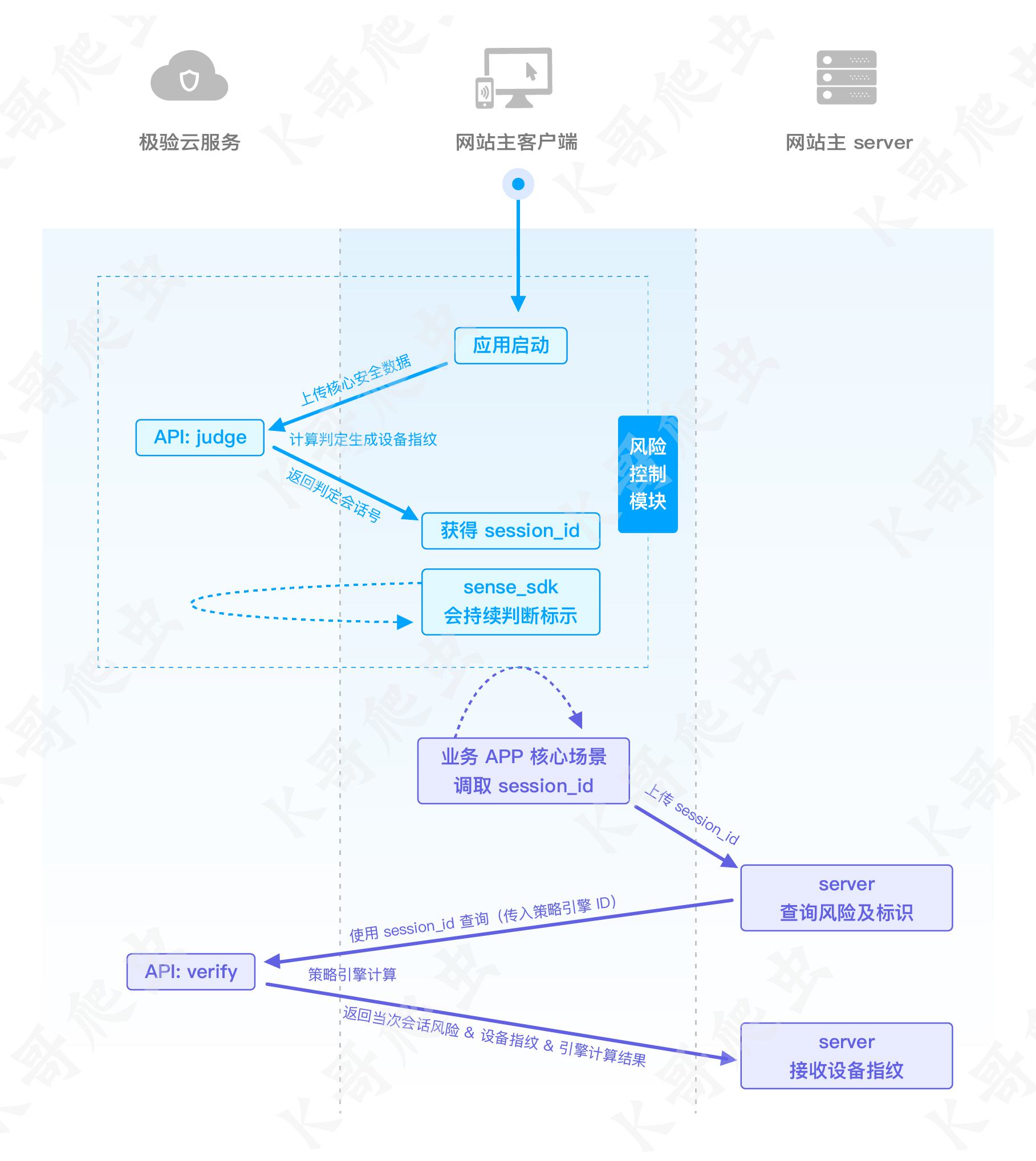
抓包分析
访问首页,会引入一个 v2.sense.js,后面接了个 id,需要将其提取出来,后续有用到,当然一般情况下,同一个业务这个 id 应该是一样的,直接复制下来写死也行。
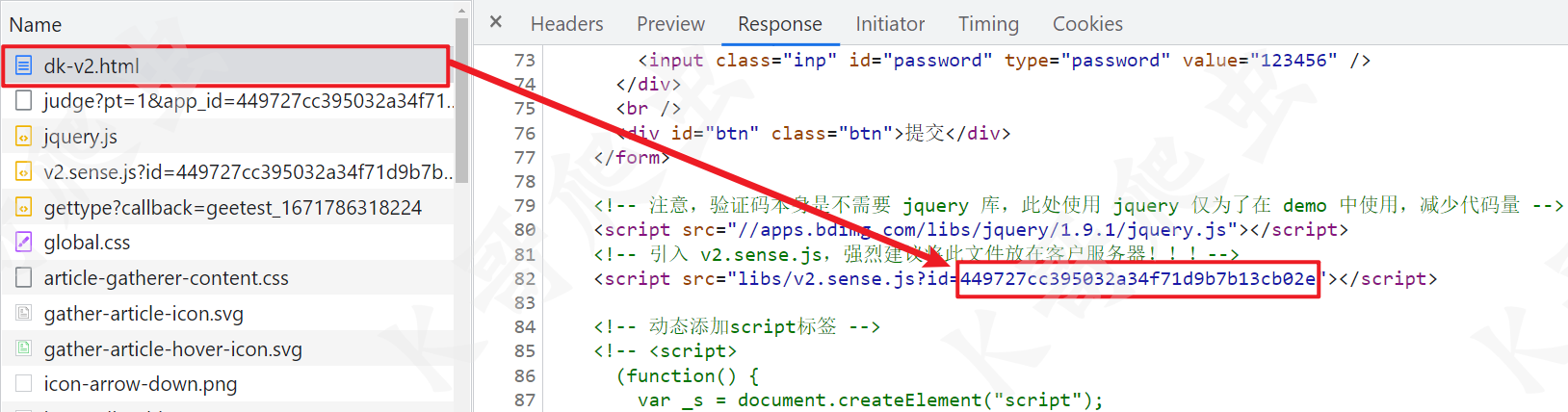
接着有个 gettype 的请求,这里主要返回一些资源路径,其中有个 gct.xxx.js,这个 JS 名称每隔一段时间就会变化,这个 JS 会生成一个键值对,例如 {'xnbw': '1158444372'},JS 变化,这个键值对也会变化,这个键值对参与了后面加密参数的生成,在某验系列产品中都有这个东西,少量测试将其固定发现也可以通过验证,盲猜大量请求或者某些校验严格的网站可能有影响,建议还是动态去请求这个 JS 来获取最新的键值对,这个后文具体再说。

然后是 judge 的请求,这个请求页面一加载就完成了,不需要手动点击请求,其中 Query String Parameters 里有个 app_id 就是我们前面提到的 id,Request Payload 就是一串超长的字符串,这个也是我们需要逆向的参数。该请求如果验证成功,会返回一个 session_id。
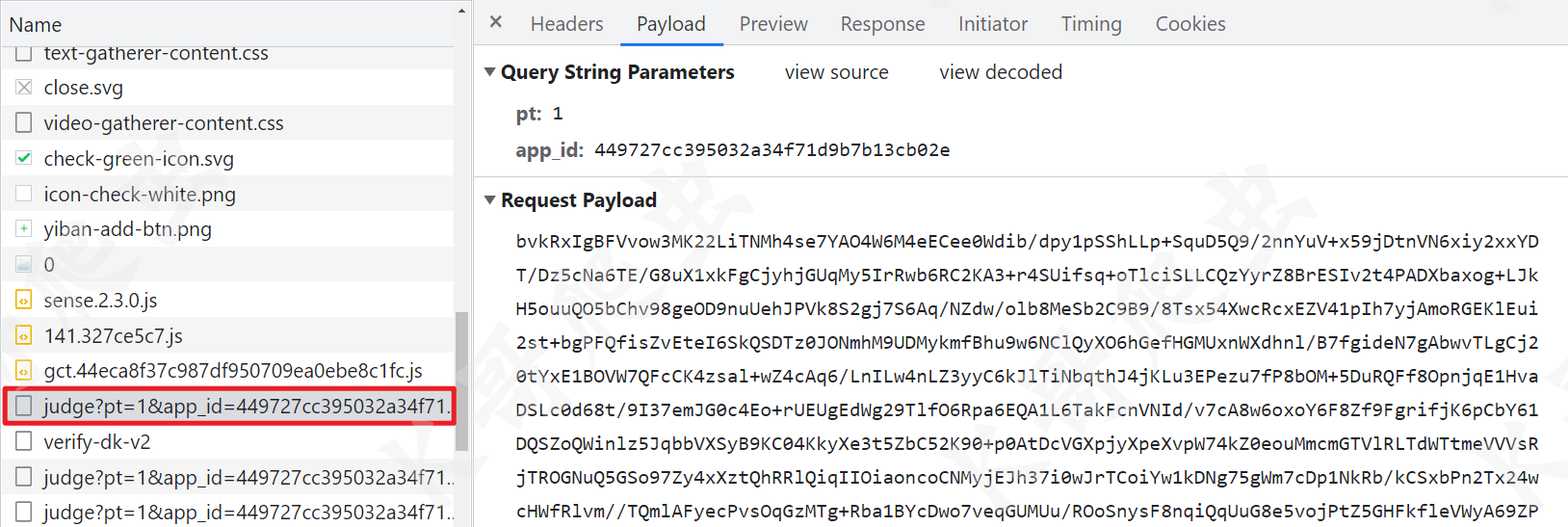

然后就是业务接口了,本例中业务接口是 verify-dk-v2,也就是一个登录接口,带上前面 judge 接口返回的 session_id 即可请求成功。


逆向分析
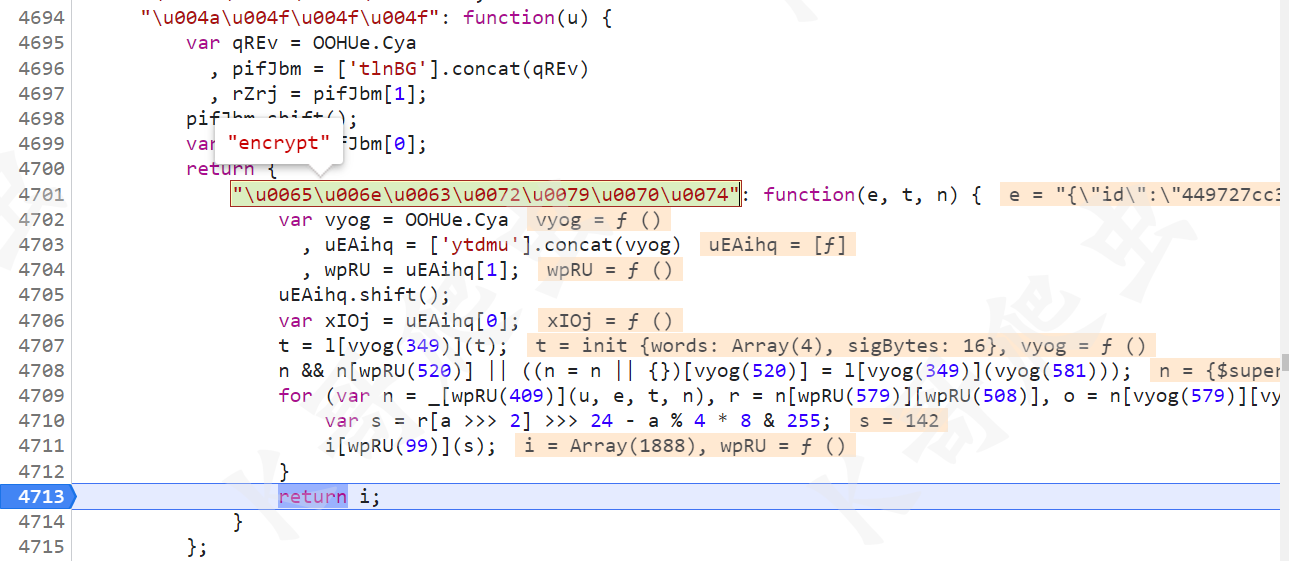
由于我们逆向的参数 Request Payload 没有键名导致不能直接搜索关键字,所以只能跟栈或者下个 XHR 断点,跟栈可以在 sense.2.3.0.js 第 6144 行找到一个 e + h[AUJ_(1173)],这个就是正确的 Request Payload 值。
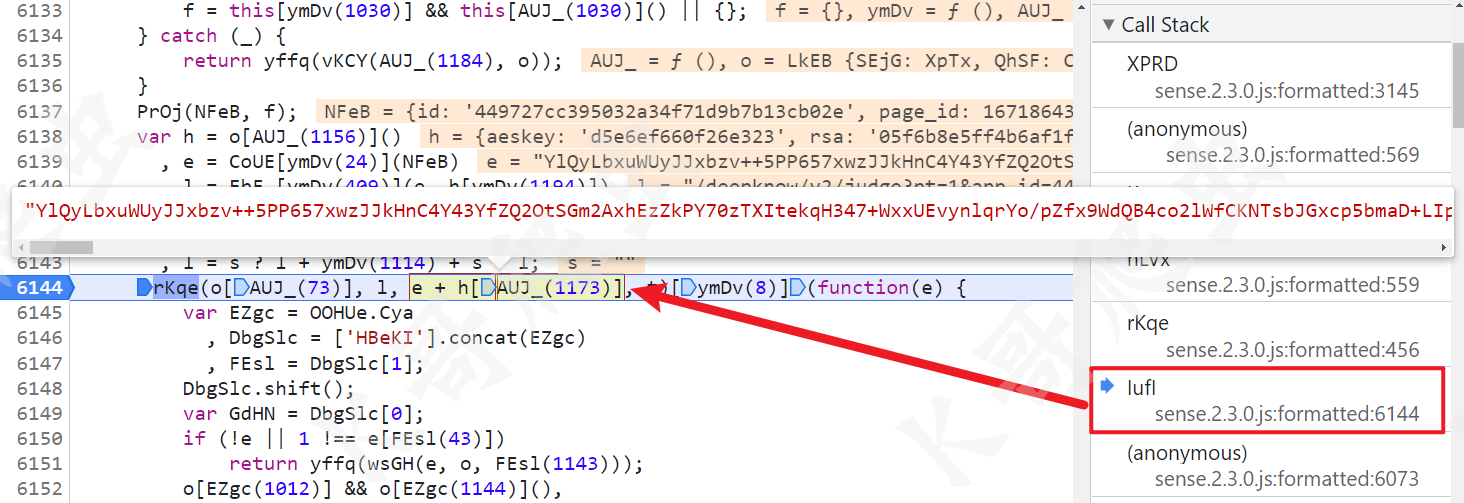
上图中其实核心代码就四行,后文也是围绕这四行代码来分析的:
var h = o[AUJ_(1156)]()
, e = CoUE[ymDv(24)](NFeB)
, l = EbF_[ymDv(409)](e, h[ymDv(1194)])
, e = DWYi[ymDv(1137)](l)
获取 h 值
先来看 h 的值,由一个方法生成一个对象,对象里面分别是 aeskey 和 rsa,每次也都是随机变化的。
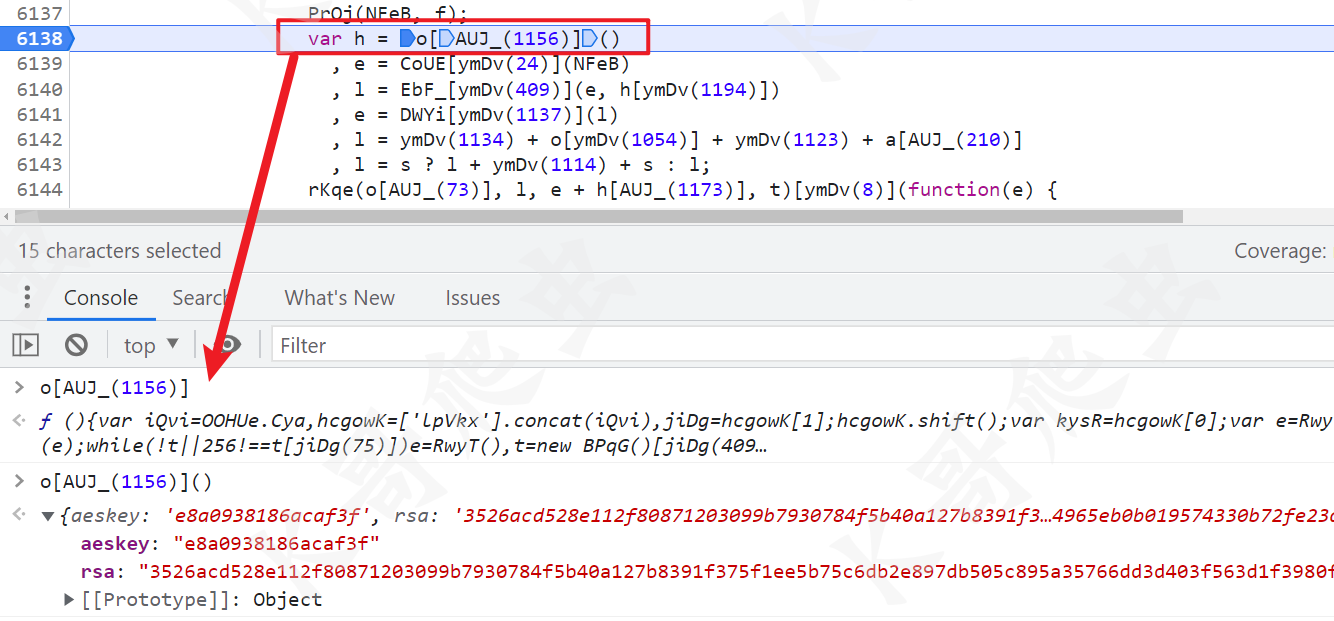
继续跟到这个方法里,重点在于 e 和 t 的值,最后返回的就是 {aeskey: e, rsa: t}。
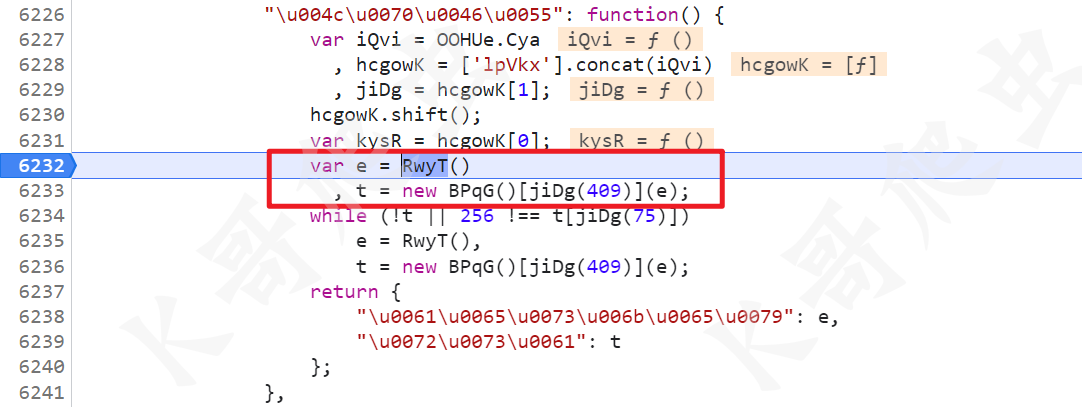
先看这个 e 的值,也就是 RwyT() 方法,搞过某验其他产品的就知道这里是 16 位随机值。
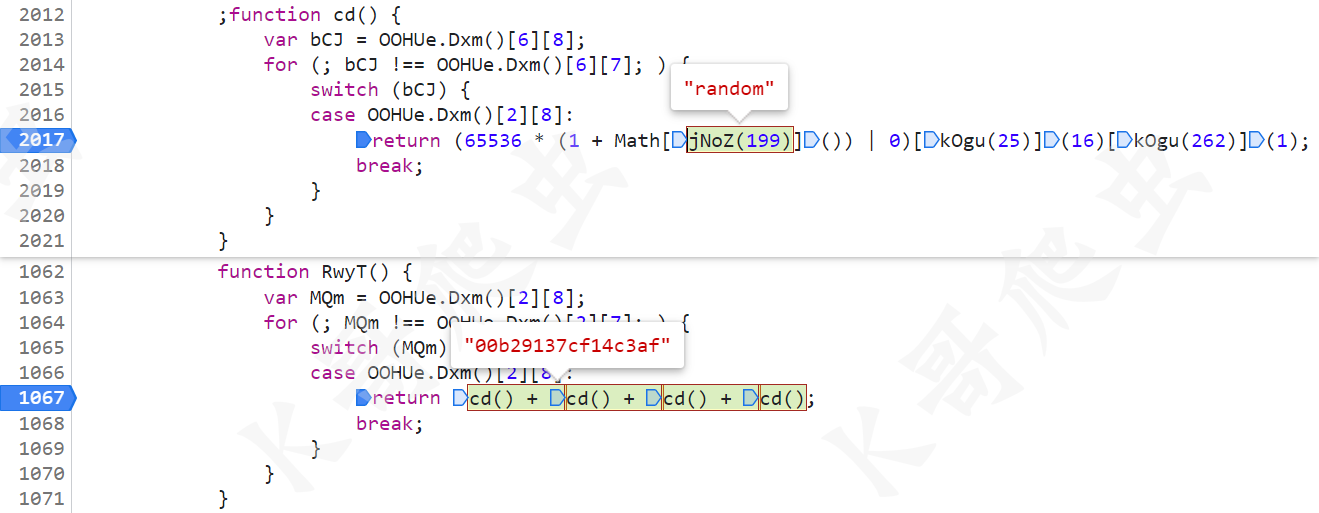
然后 t 的值,和某验其他系列产品一样,用到了 RSA 加密算法,这里图中 BPqG() 就是 RSA 算法,t 的值就是 RSA 加密后的结果,扣的时候注意找到算法开头的地方,将整个 BPqG() 方法扣下来即可。
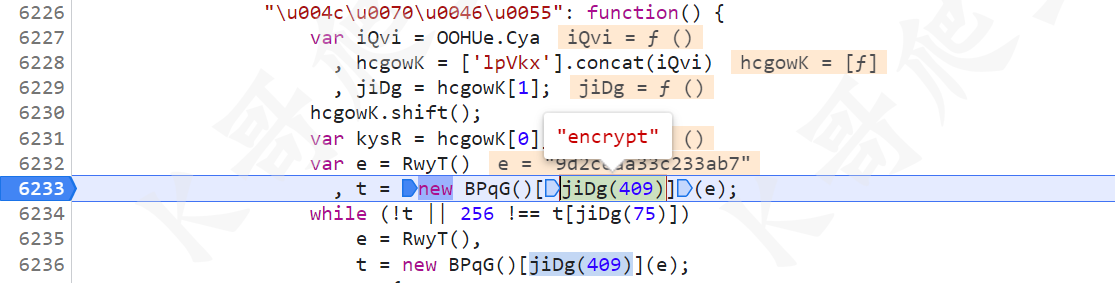
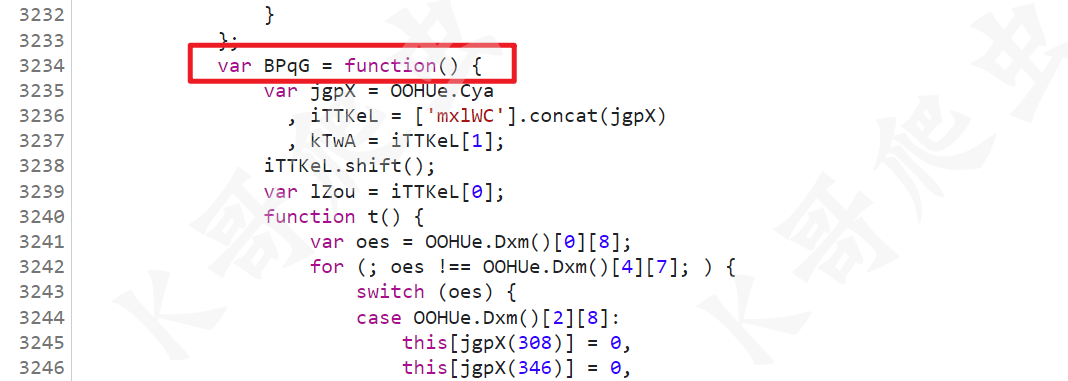
获取 e 值
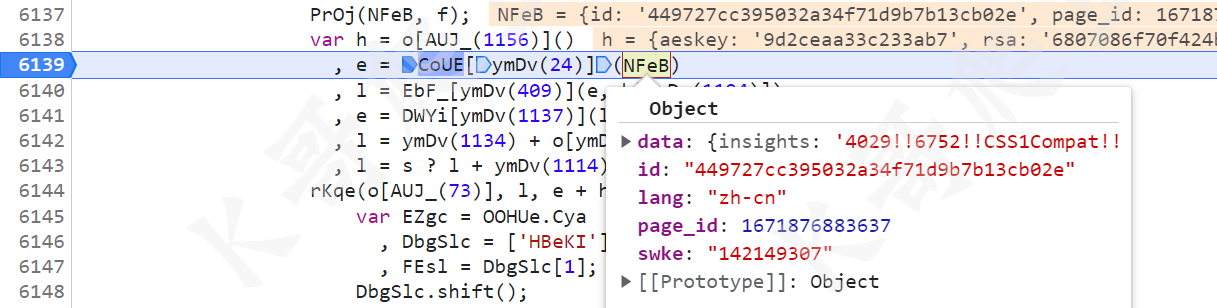
接下来是 e 的值,e = CoUE[ymDv(24)](NFeB),很明显是将 NFeB 的值进行了处理,NFeB 是个对象,里面有一些 data、id 等信息,如下图所示:
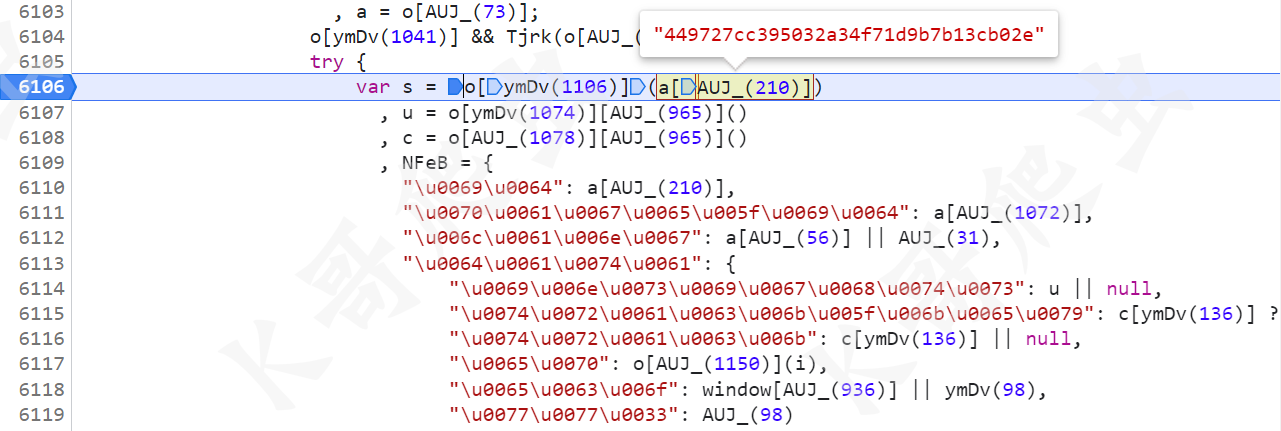
所以我们得先找一下 NFeB 这个值是怎么来的,直接搜索发现只有四个地方,在第 6109 行就是定义的地方,挨个看,首先有个 s 参数,将 id 传入到一个函数进行处理,函数没啥特别的,直接扣就行,通常经过处理后,s 的值为空,即 s=""。
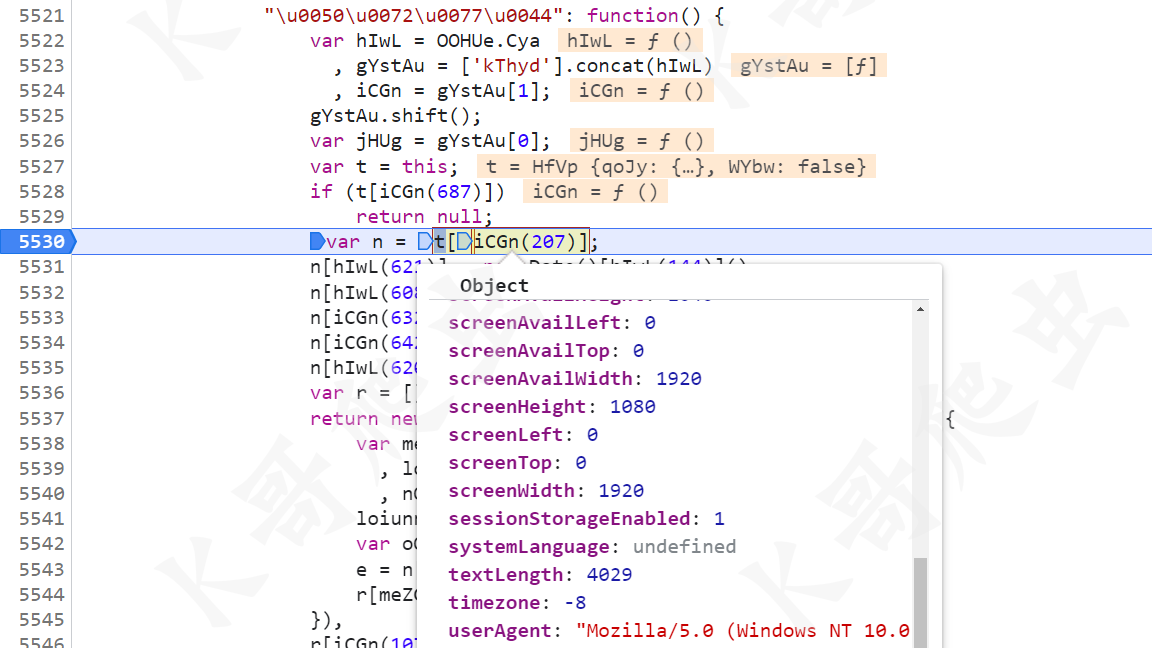
再来看有个 u 值,由一个方法生成了一大串包含很多感叹号的字符串,本案例实际测试中,直接将这个值置空也行,可能其他校验严格或者大批量请求的情况下,说不定也会校验的,所以我们最好也跟进去找一下生成逻辑。

跟进这个方法,里面是一些浏览器环境的值,比如屏幕高宽、canvas、ua、浏览器插件、时间、时区、语言等等,基本上都能写死,后续会将这些值以 !! 相连接最终生成 u 的值。
然后继续看,接下来是 c 值,是一个对象,值为 {"key":0,"value":[]},我这里直接写死了。
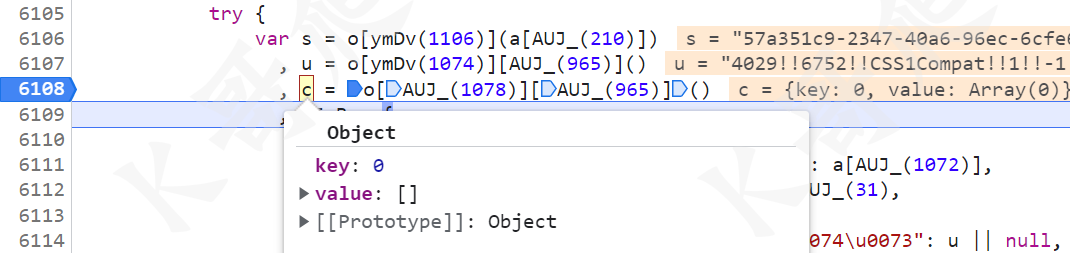
再往下就是 NFeB 了:
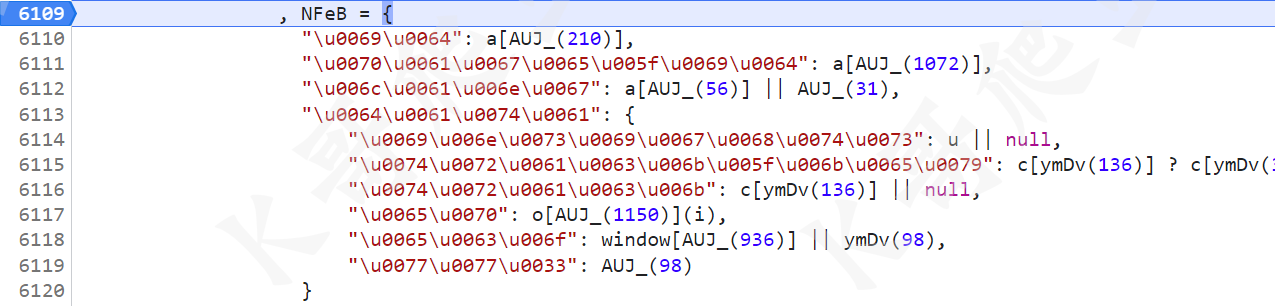
Unicode 转换一下,简单解一下混淆,就长下面这样:
NFeB = {
"id": a["id"],
"page_id": a["page_id"],
"lang": a["lang"] || AUJ_(31),
"data": {
"insights": u || null,
"track_key": c["value"] ? c["key"] : null,
"track": c["value"] || null,
"ep": o["KZrg"](i),
"eco": window["GEERANDOMTOKEN"] || "",
"ww3": ""
}
};
id 不用说,page_id 就是个时间戳,lang 中文就是 zh-cn,insights 是前面得到的 u 值,track_key、track 取 c 的键和值,ep 将 i 传入了一个函数进行处理,i 是固定的字符串 client,这个 KZrg 方法可以跟进去看看,里面其实有很多都是定值,唯一需要注意的是 t["tm"] 这个值,和某验其他系列一样,是 window.performance.timing 的值,自己获取一下时间戳随机加减伪造一下就行了。
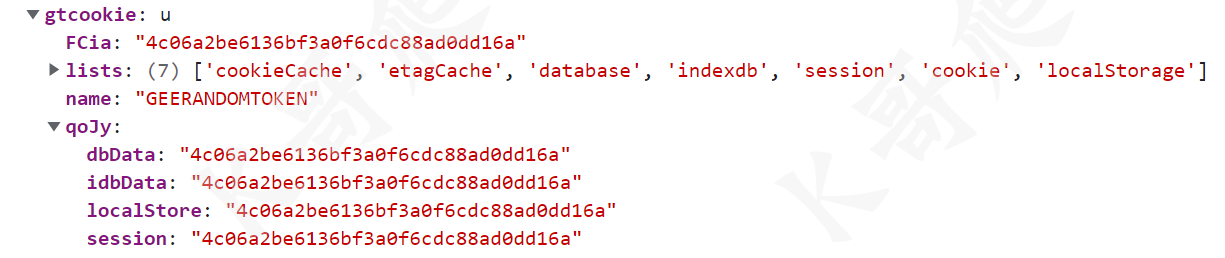
然后就是 eco 的值,取的 window.GEERANDOMTOKEN,打印一下 window,除了有这个 token 以外,还可以看到 localStore、session 里面也有这个值。
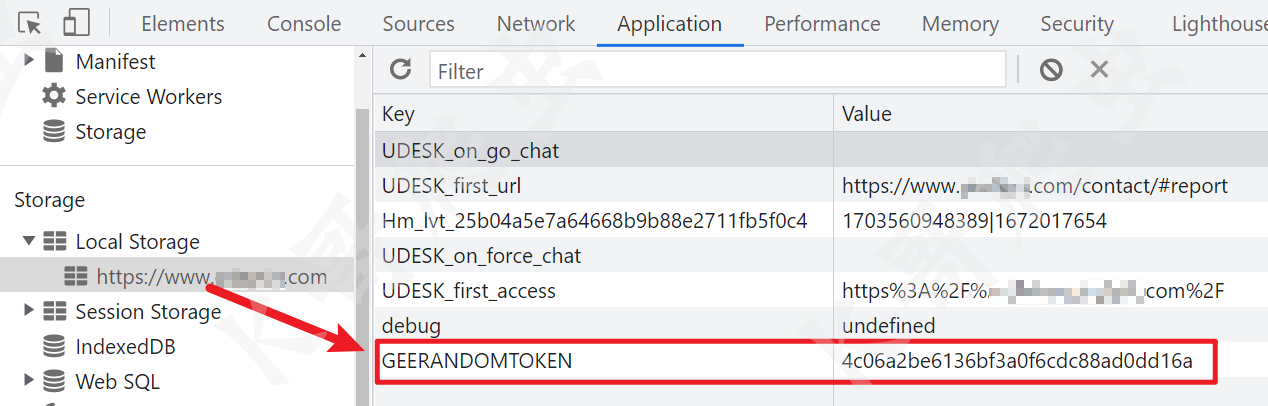
由于某验的 JS 都是混淆后的,不太好定位这个值生成的地方,所以拿出我们的 Hook 大法,先清除一下缓存,不然的话是 Hook 不到值的,Hook 代码如下:
(function() {
var token = "";
Object.defineProperty(window, 'GEERANDOMTOKEN', {
set: function(val) {
console.log('GEERANDOMTOKEN->', val);
debugger;
token = val;
return val;
},
get: function()
{
return token;
}
});
})();
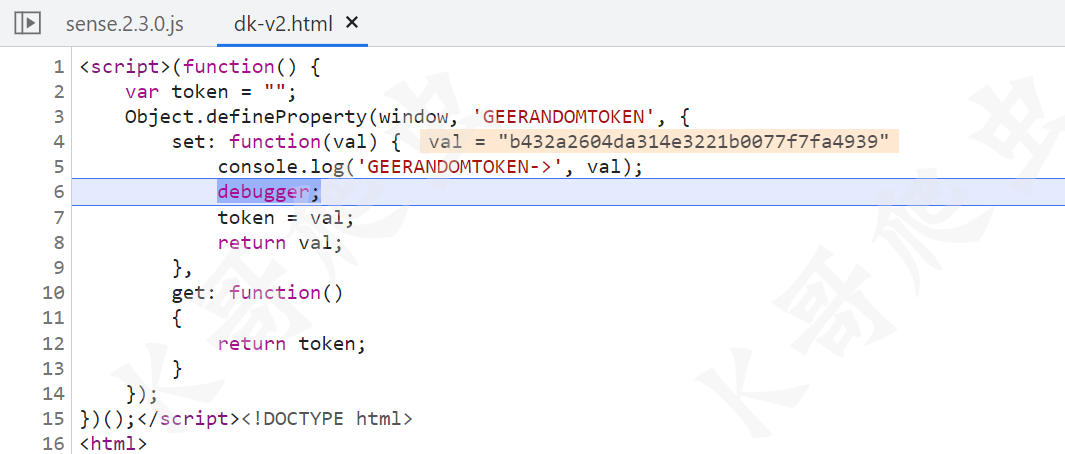
断下后往前跟栈,window[o] = t,o 就是 GEERANDOMTOKEN,t 就是我们想要的值。

往上就可以找到 t 的生成方法,核心就是生成一个 32 位的随机字符串,然后加上时间戳,再进行 MD5 加密得到最终值,生成位置以及实现的代码如下:
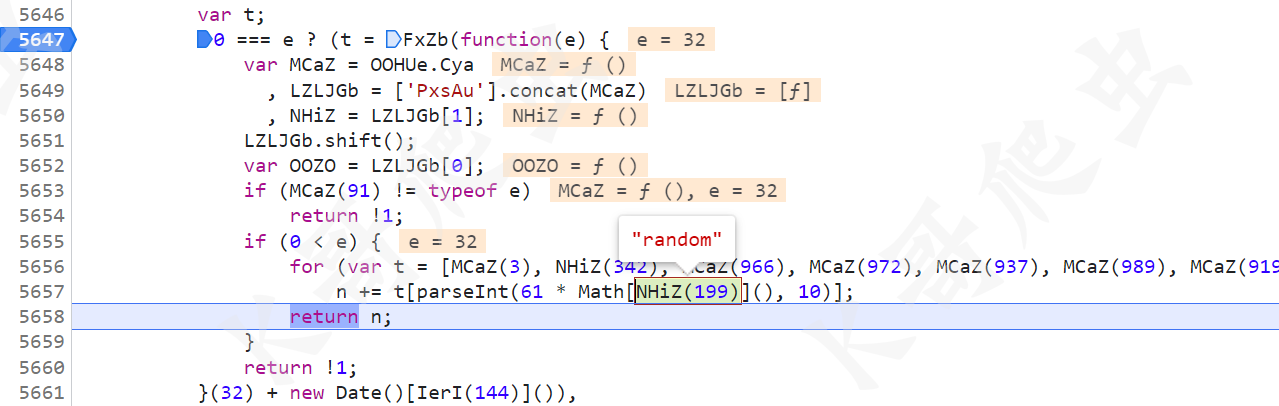
var MD5 = require("md5")
function getToken(){
var t = MD5(function(e) {
for (var t = ["0","1","2","3","4","5","6","7","8","9","A","B","C","D","E","F","G","H","I","J","K","L","M","N","O","P","Q","R","S","T","U","V","W","X","Y","Z","a","b","c","d","e","f","g","h","i","j","k","l","m","n","o","p","q","r","s","t","u","v","w","x","y","z"], n = "", r = 0; r < e; r++)
n += t[parseInt(61 * Math.random(), 10)];
return n;
}(32) + new Date().getTime());
return t;
}
当你把以上这些参数都搞完了,你可能认为都齐了,其实不然,后面接着还有一句 Yvwp(NFeB, r),将 r 的值增加到了 NFeB 里,这个 r 的值类似于 {olbo: "1588069361"},这个键值对都是每隔一段时间会变的,这个在某验系列其他文章里也提过。
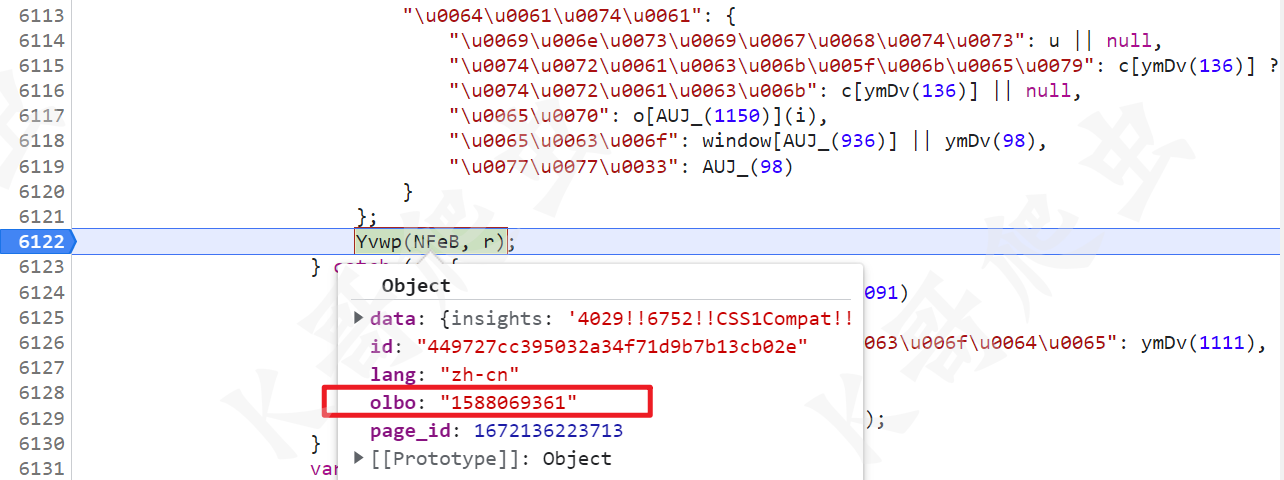
进一步分析,这个 r 是传进来的,所以往上跟栈,有个 r[psPG(1183)]() 方法就生成了这个对象:
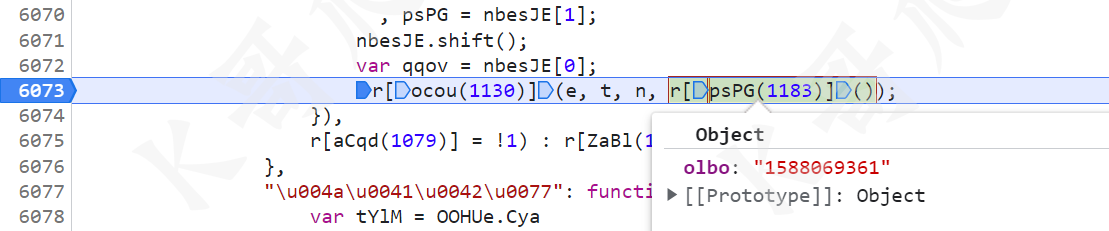
继续跟到这个方法里去,首先定义了 e 这个对象,然后赋值 e = {ep: "test data", lang: "zh"},然后经过 window[tYlM(1126)]() 方法处理后,e 里面就新增了 {olbo: "1588069361"},后续将 ep 和 lang 两个值删除后返回。
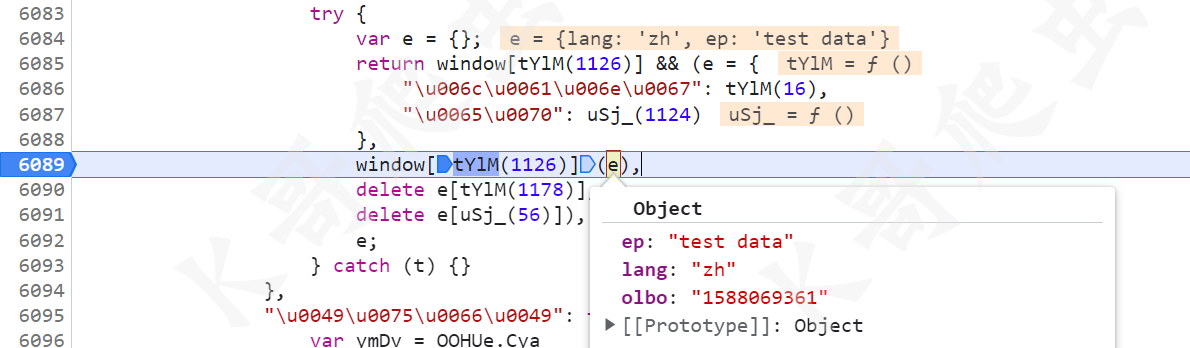
所以我们继续跟进 window[tYlM(1126)]() 方法,会跳转到 gct.xxxx.js 里,这个 JS 就是我们开头讲过的,他的名称会每隔一段时间变化,内容也会变,所以导致生成的键值对也会变化,继续跟,有个 t[e] = xxx 的语句,其中 e 和等号右边的值,就是我们需要的键值对。
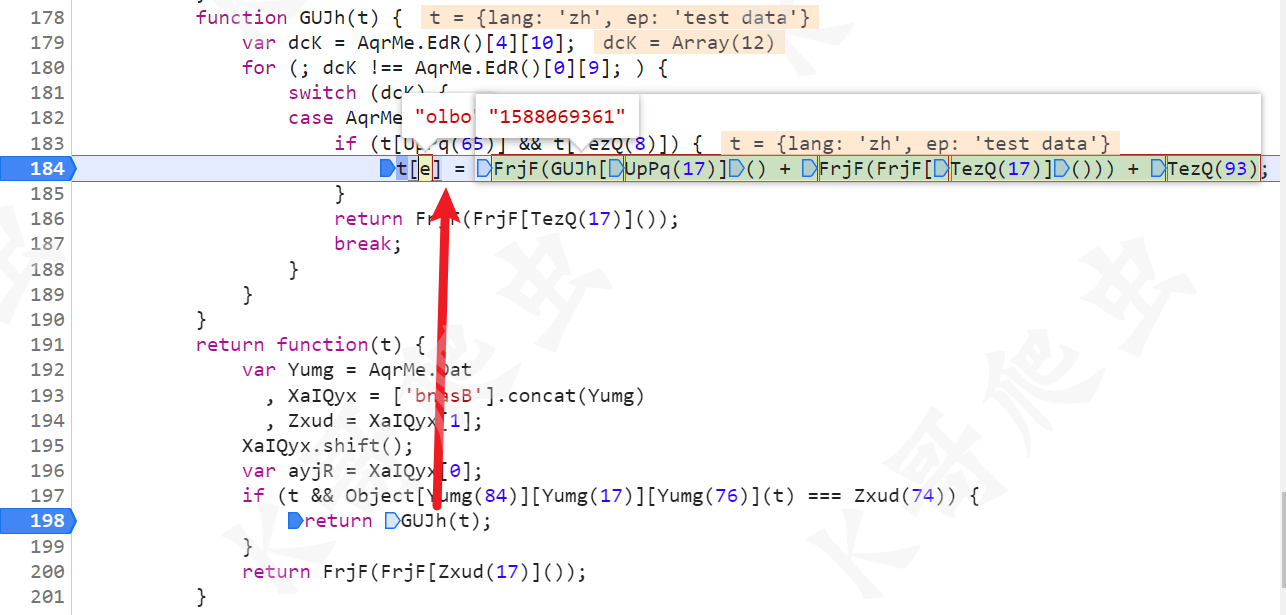
这个键值对在我们本地也可以动态获取,只需要请求正确的 JS 文件,将要调用的方法全局导出就行了,以下给一个我的处理方法示例(注意里面请求 url 已经脱敏处理,所以不可直接运行,自行抓包补上):
import re
import time
import json
import execjs
import requests
from loguru import logger
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36",
}
def get_gct():
url = "https://dkapi.脱敏处理.com/deepknow/v2/gettype"
params = {
"callback": "脱敏处理_" + str(int(time.time() * 1000))
}
response = requests.get(url, headers=headers, params=params).text
response = json.loads(re.findall(r"geetest_\d+\((.*?)\)", response)[0])
# gettype 接口返回的 gct.xxx.js 的地址
gct_path = "https://static.脱敏处理.com" + response["gct_path"]
logger.info("gct_path: %s" % gct_path)
gct_js = requests.get(gct_path, headers=headers).text
# 正则匹配需要调用的方法名称
function_name = re.findall(r"\)\)\{return (.*?)\(", gct_js)[0]
# 查找需要插入全局导出代码的位置
break_position = gct_js.find("return function(t){")
# window.gct 全局导出方法
gct_js_new = gct_js[:break_position] + "window.gct=" + function_name + ";" + gct_js[break_position:]
# 添加自定义方法调用 window.gct 获取键值对
gct_js_new = "window = global;" + gct_js_new + """
function getGct(){
var e = {"lang": "zh", "ep": "test data"};
window.gct(e);
delete e["lang"];
delete e["ep"];
return e;
}"""
gct = execjs.compile(gct_js_new).call("getGct")
logger.info("gct: %s" % gct)
return gct
到这里我们 NFeB 就生成完毕了,回到 e 的值,这里其实就是把 NFeB 转成字符串,直接 JSON.stringify() 即可。
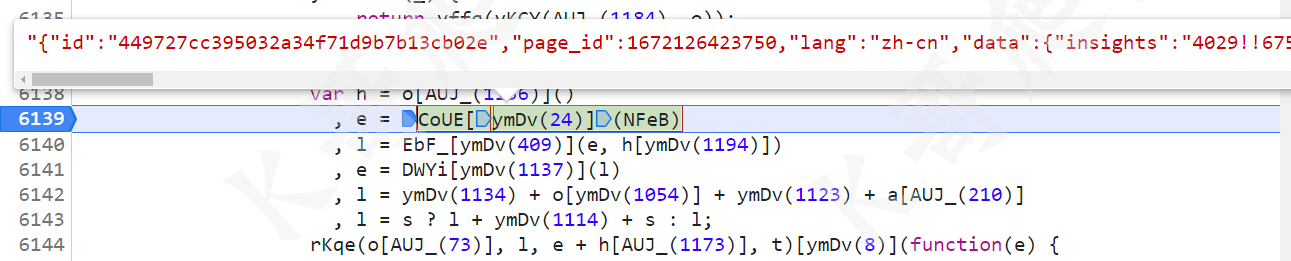
获取 l 值
l 的值比较简单,就是将前面生成的 h["aeskey"] 作为 key,e 作为待加密字符串,经过 AES 加密后即可得到 l 的值。
本地复现如下(有些变量名称不一样无影响,我是直接复用的某验其他产品的方法):
var CryptoJS = require("crypto-js")
function aesEncrypt(e, i) {
var key = CryptoJS.enc.Utf8.parse(i),
iv = CryptoJS.enc.Utf8.parse("0000000000000000"),
srcs = CryptoJS.enc.Utf8.parse(e),
encrypted = CryptoJS.AES.encrypt(srcs, key, {
iv: iv,
mode: CryptoJS.mode.CBC,
padding: CryptoJS.pad.Pkcs7
});
for (var r = encrypted, o = r.ciphertext.words, i = r.ciphertext.sigBytes, s = [], a = 0; a < i; a++) {
var c = o[a >>> 2] >>> 24 - a % 4 * 8 & 255;
s.push(c);
}
return s;
}
进一步处理 l
最后一步 e = DWYi[ymDv(1137)](l),将 l 的值经过了 tc_t 这个方法进行处理,就会得到最终 Request Payload 的一部分。
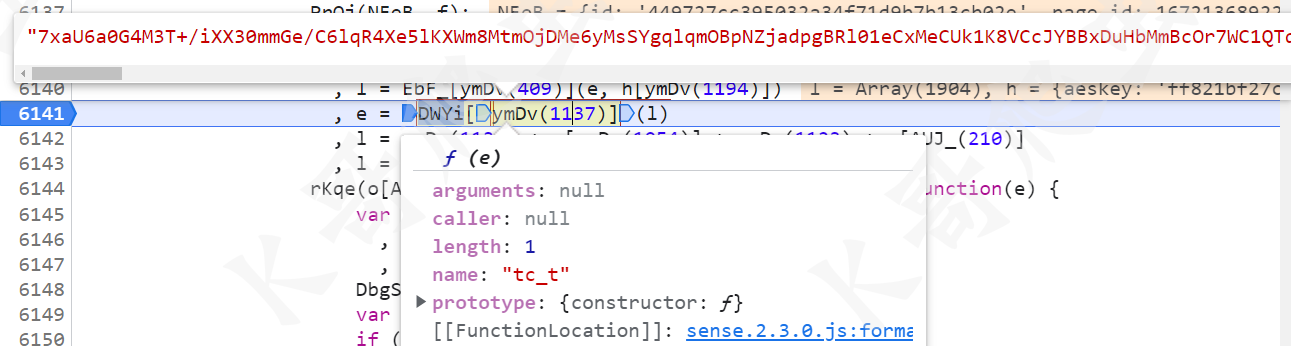
跟进这个 tc_t 方法,又是熟悉的 return e["res"] + e["end"],同样和某验其他产品一样的。

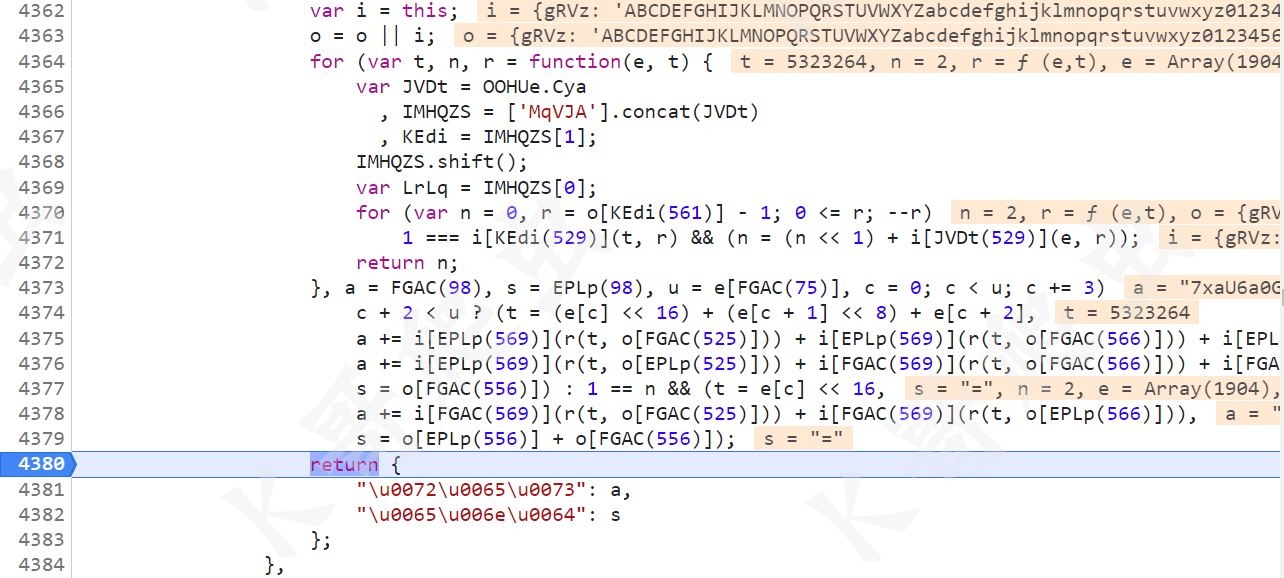
跟到处理 e 的这个方法里,最后返回的是 {"res": a, "end": s},没啥特别的,直接扣即可,这里注意和某验其他产品里的方法有些小区别,里面有些常量的值是不一样的,最开始我直接复用了其他产品的方法,发现结果是错的。
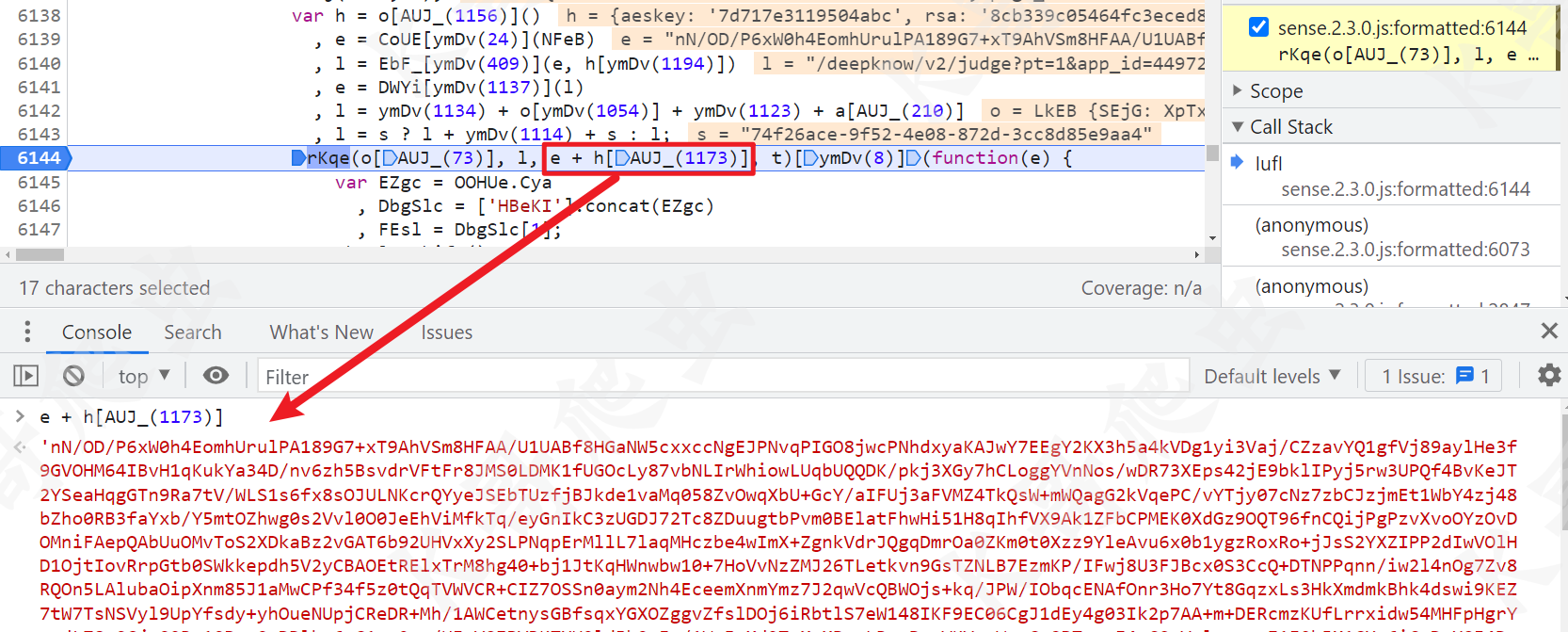
自此整个流程分析完毕,最终 e + h[AUJ_(1173)] 的值与 Request Payload 的值一致。
结果验证

原文链接:https://www.cnblogs.com/ikdl/p/17315308.html
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:【验证码逆向专栏】某验深知 V2 业务风控逆向分析 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 