Hadoop 起源于Google Lab开发的Google File System (GFS)存储系统和MapReduce数据处理框架。2008年,Hadoop成了Apache上的顶级项目,发展到今天,Hadoop已经成了主流的大数据处理平台,与Spark、HBase、Hive、Zookeeper等项目一同构成了大数据分析和处理的生态系统。Hadoop是一个由超过60个子系统构成的系统集合。实际使用的时候,企业通过定制Hadoop生态系统(即选择相应的子系统)完成其实际大数据管理需求。Hadoop生态系统由两大核心子系统构成∶HDFS分布式文件系统和MapReduce数据处理系统。
HDFS分布式文件系统
HDFS是一个可扩展的分布式文件系统,它为海量的数据提供可靠的存储。HDFS的架构是构建在一组特定的节点上,其中包括一个NameNode 节点和数个DataNode 节点。NameNode 主要负责管理文件系统名称空间和控制外部客户机的访问,它对整个分布式文件系统进行总控制,记录数据分布存储的状态信息。DataNode则使用本地文件系统来实现HDFS的读写操作。每个DataNode都保存整个系统数据中的一小部分,通过心跳协议定期向NameNode报告该节点存储的数据块的状况。为了保证系统的可靠性,在DataNode发生宕机时不致文件丢失,HDFS会为文件创建复制块, 用户可以指定复制块的数目, 默认情况下, 每个数据块拥有额外两个复制块, 其中一个存储在与该数据块同一机架的不同节点上, 而另一复制块存储在不同机架的某个节点上。
所有对HDFS文件系统的访问都需要先与NameNode通信来获取文件分布的状态信息,再与相应的DataNode节点通信来进行文件的读写。由于NameNode处于整个集群的中心地位,当NameNode节点发生故障时整个HDFS 集群都会崩溃,因此HDFS中还包含了一个Secondary NameNode,它与NameNode之间保持周期通信,定期保存NameNode上元数据的快照,当NameNode发生故障而变得不可用时,Secondary NameNode 可以作为备用节点顶替NameNode,使集群快速恢复正常工作状态。
NameNode的单点特性制约了HDFS的扩展性,当文件系统中保存的文件过多时NameNode会成为整个集群的性能瓶颈。因此在Hadoop 2.0 中,HDFS Federation被提出,它使用多个NameNode分管不同的目录,使得HDFS具有横向扩展的能力。
MapReduce 数据处理系统
MapReduce是位于HDFS文件系统上一层的计算引擎,它由JobTracker 和 TaskTracker 组成。JobTracker是运行在 Hadoop 集群主节点上的重要进程,负责MapReduce的整体任务调度。同NameNode 一样,JobTracker在集群中也具有唯一性。TaskTracker进程则运行在集群中的每个子节点上,负责管理各自节点上的任务分配。
当外部客户机向MapReduce引擎提交计算作业时,JobTracker将作业切分成一个个小的子任务,并根据就近原则,把每个子任务分配到保存了相应数据的子节点上,并由子节点上的TaskTracker负责各自子任务的执行,并定期向JobTracker发送心跳来汇报任务执行状态。
Hadoop 2.0对MapReduce的架构加以改造,对JobTracker所负担的任务分配和资源管理两大职责进行分离,在原本的底层HDFS文件系统和MapReduce计算框架之间加入了新一代架构设计——YARN。
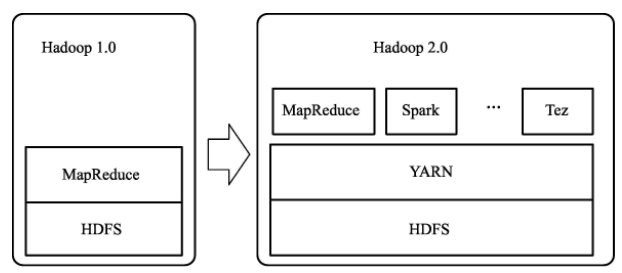

YARN 是一个通用的资源管理系统,为上层的计算框架提供统一的资源管理和调度。 NodeManager 运行于每个子节点上, 对不同的节点进行自管理,任务分配的职责也从原本的JobTracker中独立出来,由ApplicationMaster来负责,并在NodeManager控制的资源容器中运行。应用程序负责向资源管理器索要适当的资源容器, 运行任务以及跟踪应用程序执行状态。
YARN 新架构采用的责任下放思路使得 Hadoop 2.0拥有更高的扩展性,资源的动态分配也极大提升了集群资源利用率。不仅如此,ApplicationMaster的加入使得用户可以将自己的编程模型运行于Hadoop 集群上,加强了系统的兼容性和可用性,HDFS和MapReduce是Hadoop生态系统中的核心组件,提供基本的大数据存储和处理能力,以上述两个核心组件为基础,Hadoop 社区陆续开发出一系列子系统完成其他大数据管理需求,这些子系统和HDFS、MapReduce一起共同构成了Hadoop生态系统。下图显示了HortonWorks公司发布的Hadoop生态系统的系统架构。
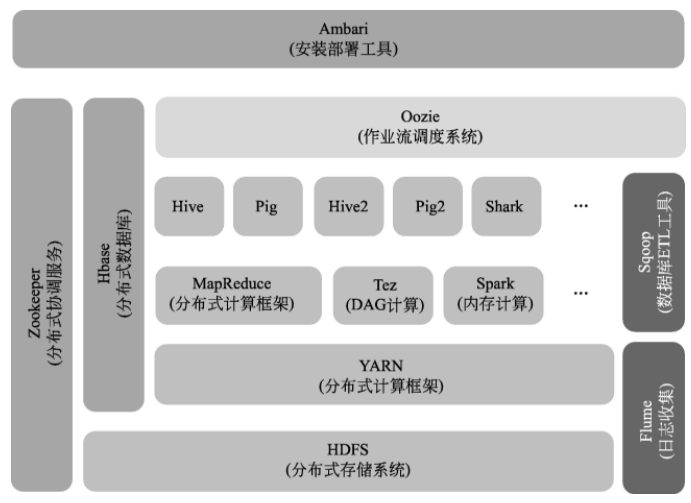
综上概括,Hadoop生态系统为用户提供的是一套可以用来组装自己的个性化数据管理系统的工具,用户根据自己的数据特征和应用需求,对一系列的部件进行有机地组装和部署,就能得到一个完整可用的管理平台。传统数据库软件采用的理念在大数据时代已经不再适用,大数据处理对系统架构的灵活性、数据处理伸缩性、数据处理效率提出了更高的要求。Hadoop 生态系统是开源社区对大数据挑战的解决方案,为大数据管理系统的后续发展奠定了良好的基础。

本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:大数据管理系统架构Hadoop - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 