数据库系统概论—基础篇(2)
三、关系数据库标准语言%ign%ignore_a_1%re_a_1%
1、数据定义
1.1基本表的定义、删除与修改
- 定义基本表
#建立学生表
CREATE TABLE Student(
Sno CHAR(9) PRIMARY KEY,
Sname CHAR(20) UNIQUE,
Ssex CHAR(2),
Sage SMALLINT,
Sdept CHAR(20)
);
- 修改基本表
ALTER TABLE 表名
ADD 列名 数据;#增
或
DROP 列名 CASCADE/RESTRICT;#删
或
ALTER 列名 类型 #改
- 删除基本表
DROP TABLE 表名 CASCADE/RESTRICT;
CASCADE:与其相关的全部删除,比如视图,索引等
RESTRICT:如果有依赖关系或是建立索引等,就不删除
但是不同的数据管理系统的执行不同
1.2索引的建立与删除
- 建立索引
CREATE UNIQUE/CLUSTER INDEX 索引名
ON 表名 (列名1 顺序1(ASC/DESC),列名2 顺序2...);
- 删除索引
DROP INDEX 索引名;
2、数据查询
- 基本结构
SELECT ALL/DISTINCT 列名/目标表达式
FROM 表名/视图名
WHERE 条件#选择的条件
GROUP BY 列名 HAVING 条件#分组后根据条件选择,分组:可以理解成大表分为好几个小表
ORDER BY 列名 顺序(ASC/DESC);#查询结构排序
2.1单表查询
利用上述的基本结构进行查.
注意:
- 字符型要加' '号
- Distinct可以消除重复的列
- 如果要显示一列字符,在SELECT后+’ ‘号
- 模糊查询中%表示任意长度,_表示一个字符
- ESCAPE后+'转义字符'
- 与空值有关要用IS NULL或是IS NOT NULL
- ORDER BY子查询不能使用
- WHERE中不能用聚集函数
- CROUP BY和HAVING同时出现
2.2连接查询
- 等值连接和非等值连接
运算符为 = 称为等值连接(列名不同),其余为非等值连接
取消重复列则为自然连接
eg:查询选修2号课程且成绩在90及分以上的所有学生的学号和姓名
Select S1.Sno,S1.Sname
From STUDENT S1,SC S2
Where S1.Sno = S2.Sno and S2.Cno = '2'and S2.Grade >= 90;
- 自身连接
两个相同的表自己连接,注意起别名
- 外连接
#外连接
From STUDENT OUTER SC join on(STUDENT.Sno = SC.Sno);
#左外连接
From STUDENT left OUTER SC join on(STUDENT.Sno = SC.Sno);
#右外连接
From STUDENT right OUTER SC join on(STUDENT.Sno = SC.Sno);
2.3嵌套查询
分为不相关查询(父查询和子查询无关)和相关查询(父查询和子查询有关)
- 带IN的子查询(不相关子查询)
子查询结果是一个属性的集合
eg:查询与"刘晨"所在同一个系的的学生的学号
Select Sno
Fron STUDENT
Where Sdept in(
Select Sdept
Fron STUDENT
Where Sname = '刘晨');
- 有比较运算符的子查询
查询顺序:先在父查询中选择第一个个元组的信息,将其传入子查询中计算结果,再进行比较
子查询的结果和父查询传入的数据有关
eg:查询每个学生超过自己选修课平均成绩的学号和课程号
Select Sno,Cno
From SC X
Where Grade >= (Select AVG(Grade)
From SC Y
Where Y.Sno = X.Sno);
也可以先建立一个新的表:学号、成绩,再查询这里就是基于派生表的查询
Select Sno,Cno
From SC,(Select Sno AVG_Sno,AVG(Crade) AVG_Grade
From SC
GROUP BY Sno) AS AVG_SG
Where SC.Sno = AVG_SG.AVG_Sno AND SC.Crade >=AVG_SG.AVG_Grade;
2.4带有EXISTS的查询
EXISTS代表存在量词,其子查询只返回“true”或是“false”
将父查询中的每一条记录代入到子查询中去试,要有一个连接的条件像,STUDENT.Sno = SC.Sno
- EXISTS
将父查询中的每一条记录代入到子查询中去试,满足则输出,不满足则查询下一条
使用EXISTS时子查询的Select后面的目标列使用*
eg:查询选择1号课程的学生
Select Sno
From STUDENT
Where EXISTE
(Select *
From SC
Where STUDENT.Sno = SC.Sno AND Cno = '1');
- NOT EXISTS
将父查询中的每一条记录代入到子查询中去试,满足则查询下一条;不满足则输出
eg:查询没用选择1号课程的学生
Select Sno
From STUDENT
Where NOT EXISTE
(Select *
From SC
Where STUDENT.Sno = SC.Sno AND Cno = '1');
- 不同形式查询的替换
并不是所有带有EXISTS的子查询都可以替换;带有IN,比较运算符,ANY和ALL的子查询可以被带有EXISTS的子查询替换
- 代替全称量词
eg:查询选修了全部课程的学生姓名
#等价于没有一门课程是他不选的
Select Name From STUDENT1
Where NOT EXISTS
(Select * From COURSE
Where NOT EXISTS
(Select * From SC
Where STUDENT1.Sno = SC.Sno and COURSE.Cno = SC.Cno));
相当于两个for循环,从学生表中取出第一个数据,然后遍历课程表并于SC表进行比较,若都可以对应上则经过两次取反后输出,否则从学生表中选取下一条记录
- 实现逻辑蕴含
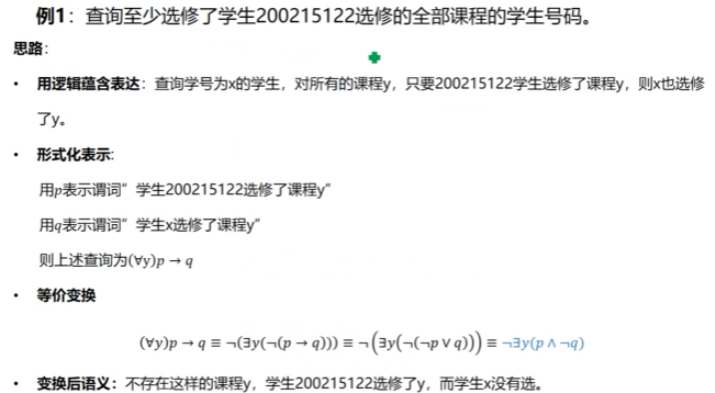
Select DISTINCT Sno
From SC S1
Where NOT EXISTS
(Select * From SC S2
Where S2.Sno = '201215122' AND NOT EXISTS
(Select * From SC S3
Where S3.Sno = S1.Sno and S2.Cno = S3.Cno));
2.5集合查询
-
交:INTERSECT
-
并:UN1ON
-
差:EXCEPT
3.数据更新
3.1插入数据
- 插入元组
INSERT INTO 表名 (列名1,列名2...)
VALUES (值1,值2...);
- 插入子查询结果
将子查询结果插入指定表中
INSERT INTO 表名 (列名1,列名2...)
子查询;
3.2修改数据
修改满足Where条件的元组
UPDATE 表名
SET (列名1 = 值1/表达式1,列名2 = 值2/表达式2...)
Where...;
- 带有子查询的修改语句
UPDATE 表名
SET (列名1 = 值1/表达式1,列名2 = 值2/表达式2...)
Where 条件 关系 子查询;
3.3删除数据
删除满足Where条件的元组,若无筛选条件,则删除全部数据,表还在
DELETE FROM 表名
Where 条件;
4.空值的处理
NULL:当前不知具体值;不该有值;不便填写。不清楚,不知道
注:
- 有NOT NULL / 加了UNIQUE / 码属性不能为空值
- NULL的算术运算结果为NULL
- NULL的比较运算结果为UNKNOWN
5.视图
- 是一个虚表
- 数据库中只存放视图的定义,而不存放视图对应的数据
- 基本表中数据变化,视图中数据也随之变化
5.1定义视图
CREAT VIEW 视图名(列名1,列名二...)
AS 子查询
WITH CHECK OPTION;#对于视图的操作都有上述子查询的Where约束
注:视图后的列名要不不写,要不全写
创建的结果是把视图的定义存在数据字典,不执行SELECT语句
基于一个表的视图叫做行列子集视图
5.2删除视图
DROP VIEW 视图名;
#CASCADE:强制删除,可选
5.3查询视图
和上面的数据查询差不多,将表名换成视图名即可
5.4更新视图
和上述的数据更新差不多...
不是所有的视图都可以更新,行列子集视图可以更新,其他视情况而定
5.5视图作用
-
视图能简化用户操作
-
视图使用户能以多种角度看待同同一数据
-
视图对重构数据库提供了一定程度的逻辑独立性
-
视图能够对机密数据提供安全保护
-
适当利用视图可以更清晰地表达查询
原文链接:https://www.cnblogs.com/wht-de-bk/p/17348816.html
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:数据库系统概论—标准语言SQL - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 