一、序
移动互联网时代,我们的身边,无处不见的二维码,在商店买东西可以用微信或支付宝的付款码、在电影院可以使用二维码在自助取票机上取票,朋友聚会时使用微信二维码互相加好友。移动终端设备的普及,出门只需要携带一步手机,极大方便了人们的日常生活。从技术的角度观察,很多场景下,二维码包含的都是一个 HTTP 链接,手机扫码识别出二维码的内容,然后跳转到对应的网站。就好比 PC 终端上,访问一个网站,一般的流程是,用户在浏览器 “地址栏” 输入一个网址,然后回车确认,浏览器就会跳到对应的网站。而二维码的流行,改变了这个交互流程,由手机 “扫一扫” 拍摄二维码照片,然后手机内部解码照片,提取二维码包含的 HTTP 链接,最后跳转对应的网站。简言之,通过手机扫码代替了用户手动输入网址的过程。
二、浅析二维码原理
维基百科:二维码也称为二维条码,是指在一维条码的基础上扩展出另一维具有可读性的条码,使用黑白矩形图案表示二进制数据,被设备扫描后可获取其中所包含的信息。
一个普通二维码的基本结构:
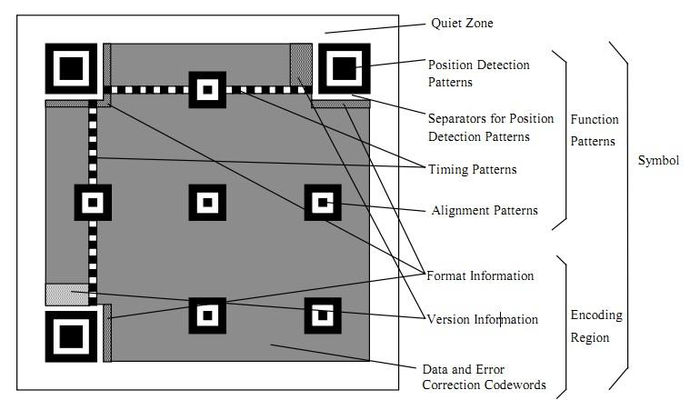

- Position Detection Pattern:位置探测图形(这样无论二维码旋转任意角度,都可以通过定位图案识别出来);
- Separators for Postion Detection Patterns:位置探测图形分割符;
- Timing Patterns:定位图形,原因是二维码有40种尺寸,尺寸过大了后需要有根标准线,不然扫描的时候可能会扫歪了;
- Alignment Patterns:校正图形,规格确定,校正图形的数量和位置也就确定了;
- Format Information:格式信息,存在于所有的尺寸中,用于存放一些格式化数据的;
- Version Information:即二维码的规格,QR 码符号共有40种规格的矩阵;
- Data and Error Correction Codewords:实际保存的二维码信息,和纠错码字(用于修正二维码损坏带来的错误)。
有了这个基本结构之后,画二维码图,就是使用一定的编码格式对数据进行编码,然后填充到相应的网格区域,最后输出二维码图片。详细的二维码生成细节和原理,可以看耗子叔这篇文章:https://coolshell.cn/articles/10590.html
三、二维码识别
一般场景下,移动端 APP 扫码的解析工作都在移动端设备上完成,在 Android 中二维码扫描的最常用库是 zxing 和 zbar。
如果想在 Python 中编写识别二维码的程序,同样也可以 zxing 库:
# 安装依赖库
pip3 install zxing
下面的试验,左图是一张没有背景干扰的图片,右图是一张有背景干扰的图片,同样使用 zxing 库来检测二维码:
具体的代码实现:
import zxing
reader = zxing.BarCodeRead
barcode = reader.decode("/User/xxx/origin.jpg")
print(barcode.parsed) # output: 二维码内容
其中,左图识别输出 https://cli.im/ ,右图识别输出:https://github.com
上面的识别的结果都是对的,但是速度很慢,在 “双核四线程” 机器上,耗时都在 2 ~ 3s 之间。那么,该如何提升二维码探测的速度?
OpenCV
通过查资料,找到了 OpenCV 库,在对象检测模块中QRCodeDetector 有两个相关 API 分别实现二维码检测与二维码解析。
# 安装依赖
pip3 install opencv-contrib-python
具体的 Python 代码实现:
import cv2
import sys
import time
img = cv2.imread(infile)
qr = cv2.QRCodeDetector()
result, points, code = qr.detectAndDecode(img)
print("The result: ", result) # result 是二维码内容
print("The points: ", points) # points 是二维码在图片中的坐标
同样使用上面的两张图片进行测试:

在同样的开发设备上,可以看到二维码的探测速度 OpenCV 比 zxing 快了 2 个数量级,但是,当解析有背景干扰的图片时,无法探测出二维码内容。
这里引起了一个问题,如何在有复杂背景下的图片中识别出二维码?比如下面这样的图片:

四、目标检测模型
目标检测,object detection,就是在给定的图片中精确找到物体所在位置,并标注出物体的类别。

图片来自:https://github.com/aloyschen/tensorflow-yolo3
在这里,我没有深入研究 ”目标检测模型“ ,只是简单使用了 yolov3 图像识别框架跑了 demo。
yolov3 检测分两步:
- 确定检测对象位置
- 对检测对象分类(是什么东西)
即在识别图片是什么的基础上,还需定位识别对象的位置,并框出。
下面是 darknet + yolov3 的环境安装流程:
- 安装 darknet
git clone https://github.com/pjreddie/darknet.git
cd darknet
make
- 使用预先训练模型测试
# 下载预训练权重
wget https://pjreddie.com/media/files/yolov3.weights
# 运行命令检测,没有使用gpu所以时间有点长
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
yolov3 预训练模型,仅支持识别图像中一部分物品,不能识别出图像中的 ”二维码“。如果想要识别出二维码,需要制作训练数据集然后训练模型。
- 制作训练数据集
- 收集图片
- 深度网络训练的数据集做标注,makesense.ai 是可免费使用的用于为照片加标签的在线工具。
- 视频教程 P9:https://www.bilibili.com/video/BV1Hp4y1y788?p=9
- 训练集
- 测试集
- 验证集
- 训练目标检测模型
- 准备数据集(标注数据)
- 下载预训练权重:wget https://pjreddie.com/media/files/yolov3.weights
- 配置 YOLO
- 训练模型
- 使用模型
另一方面,如果采用 yolov3 进行图片中二维码探测,将需要大量的数据集,人工手动的二维码标注,还需要具备 GPU 的机器来跑训练集,这将是一个工作量巨大且耗时漫长的过程。该如何解决训练模型的问题?
微信二维码引擎 OpenCV 开源
开源世界总会给人惊喜,微信二维码引擎居然也开源,文档地址:https://mp.weixin.qq.com/s/pphBiEX099ZkDV0hWwnbhw

按照文章的代码实现:
import cv2
# 探测二维码
detect_obj = cv2.wechat_qrcode_WeChatQRCode('detect.prototxt', 'detect.caffemodel', 'sr.prototxt', 'sr.caffemodel')
img = cv2.imread(infile)
res, points = detect_obj.detectAndDecode(img)
# 绘制框线
for pos in points:
color = (0, 0, 255)
thick = 3
for p in [(0, 1), (1, 2), (2, 3), (3, 0)]:
start = int(pos[p[0]][0]), int(pos[p[0]][1])
end = int(pos[p[1]][0]), int(pos[p[1]][1])
cv2.line(img, start, end, color, thick)
cv2.imshow('img', img)
cv2.imwrite('wechat-qrcode-detect.jpg', img)
二维码探测,输出结果:

上述图片的二维码探测,结果是准确的,耗时却是惊人的(注意:这是没有绘制框线的耗时)
基于 CNN 的二维码检测
“一图多码” 是扫码支付经常遇到的线下场景。早在2016年,微信扫码引擎在业内率先支持远距离二维码检测、自动调焦定位、多码检测识别。然而,传统方法需要牺牲40%以上的性能来支持多码的检测与识别。伴随着深度学习技术的成熟和移动端计算能力的提升,微信扫码引擎引入基于 CNN 的二维码检测器解决上述问题。
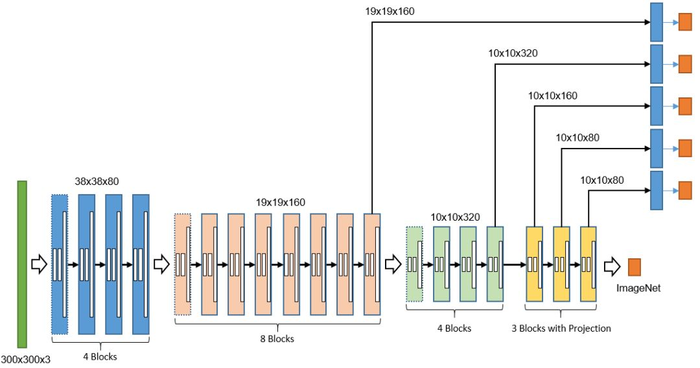
以 SSD 框架为基础,构造了短小精干的二维码检测器,采用残差连接(Residual Concat)、深度卷积(Depthwise Convolution)、空洞卷积(Dilated Convolution)、卷积投影(Convolution Projection)等技术进行了针对性的优化。整个模型大小仅943KB,iPhone7(A10)单 CPU 的推理时间仅需20ms,很好地满足“低延时、小体积、高召回”的业务需求。
五、识别一图多码
上面提到,开源的微信二维码引擎 OpenCV 很好的解决了复杂背景图的二维码识别问题,而且同时具备超高的性能,极短的耗时。
针对文章提到的一图多码的场景,我们进行验证,发现在验证过程中,一图多码的识别效果并没有预期的那么理想。

使用 微信二维码引擎 OpenCV 探测一张包含多个二维码的图片时,会出现二维码识别不全的问题。通过试验,将图片切割成多个小图片,每张切片包含若干个二维码时,验证后发现识别效果最好的是一张图片包含一个二维码。因此产生下列的 ”滑动窗口单图多二维码” 探测方案。
滑动窗口一图多码方案

窗口滑动原理:
-
第一次滑动:检测不到二维码,左边界不动右边界右移动,扩大窗口

-
第二次滑动:检测不到二维码,左边界不动右边界右移动,扩大窗口

-
第三次滑动:检测到二维码,左边界移动到右边界重合,窗口大小归 0

-
第四次滑动:检测不到二维码,左边界不动右边界右移动,扩大窗口

-
第五次滑动:检测到二维码,左边界移动到右边界重合,窗口大小归 0

后续的步骤同理,直到将右边界移动到了图片的最右端,代表探测结束。
最后,采用 ”滑动窗口一图多码探测” 方案的效果图,准确度还是非常高的:

当然,这里只是简单的演示,里面还有很多问题,比如:这种方案仅适合二维码横向排列的场景,如果同一个列有多张二维码,就可能被裁剪掉。
have fun!
六、参考文献
- 二维码的生成细节和原理:https://coolshell.cn/articles/10590.html
- OpenCV QR Code Scanner ( C++ and Python ):https://learnopencv.com/opencv-qr-code-scanner-c-and-python/
- Python识别复杂背景下的二维码:https://www.jianshu.com/p/743326c41b64
- 微信二维码引擎 OpenCV 开源:https://mp.weixin.qq.com/s/pphBiEX099ZkDV0hWwnbhw
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:目标检测:二维码检测方案 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 