目录
目标检测数据集分析
平时我们经常需要对我们的数据集进行各种分析,以便我们找到更好的提高方式。所以我将我平时分析数据集的一些方法打包发布在了Github上,分享给大家,有什么错误和意见,请多多指教!
项目地址
图片数量、标注框数量、类别信息
这些信息会在终端打印出来,格式如下:
number of images: 6666
number of boxes: 19958
classes = ['4', '2', '1', '3']
所有图片宽度和高度的散点图
这里只有一个点,是因为所有的图片尺寸相同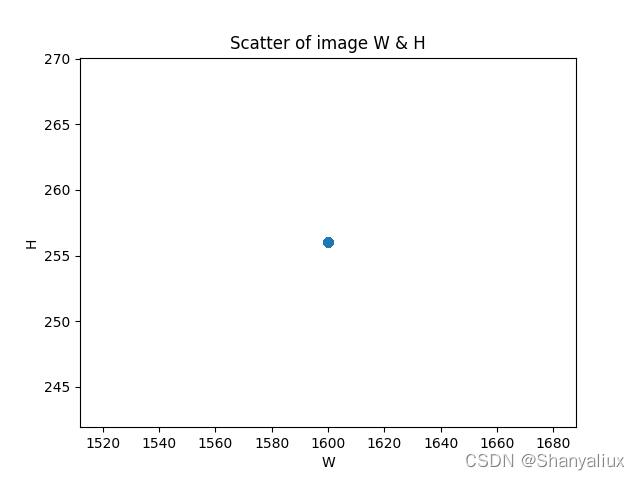

所有标注框宽度和高度的散点图
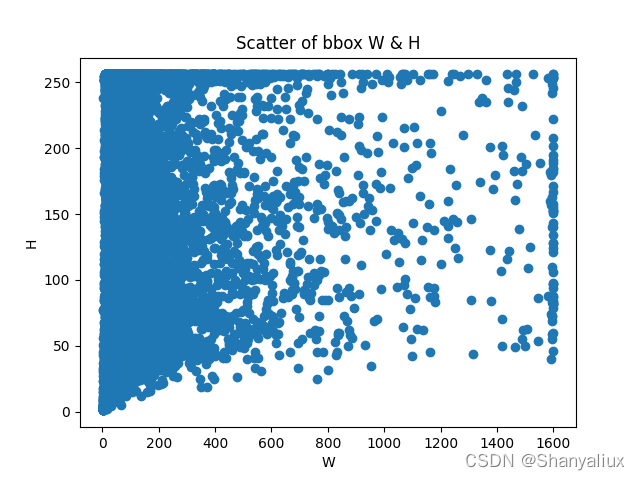
标注框宽度和高度之比
横坐标为比率,纵坐标为数量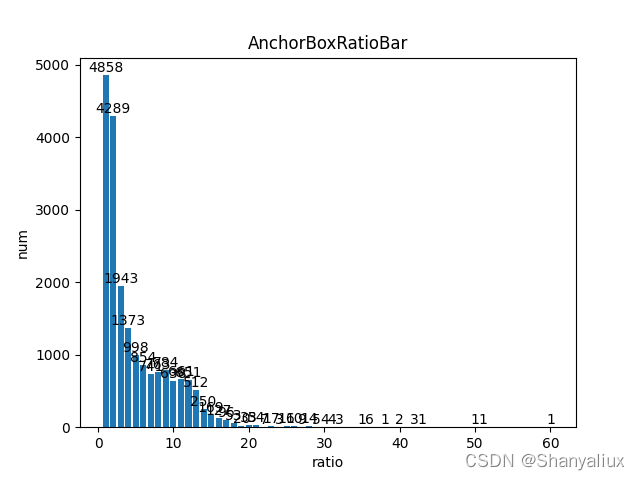
每一类的标注框数量
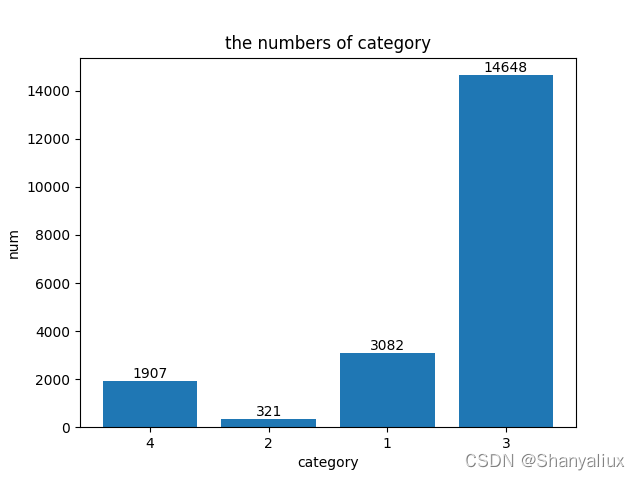
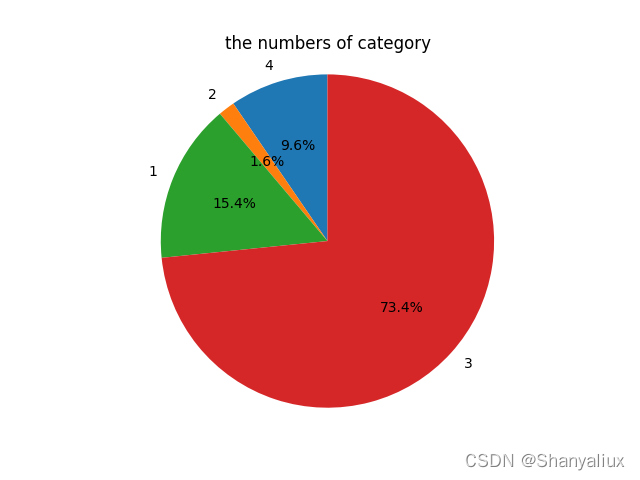
每一类图片数量
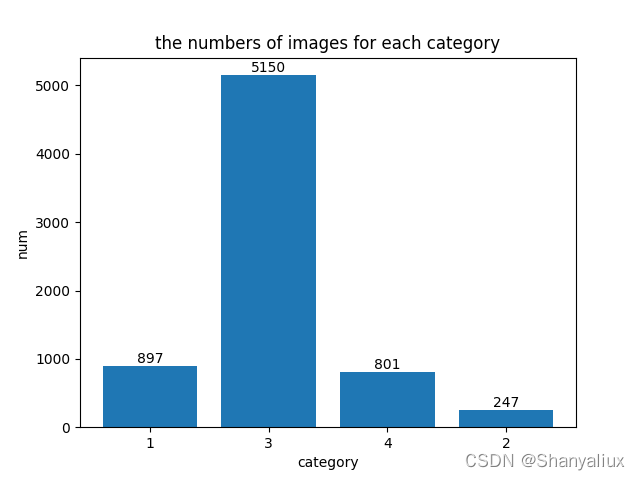
每一张图片上的标注框数量
横坐标为一张图片上的标注框数量,纵坐标为图片数量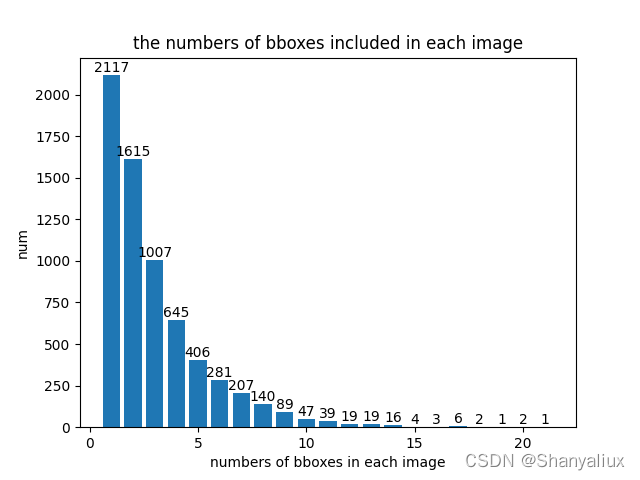
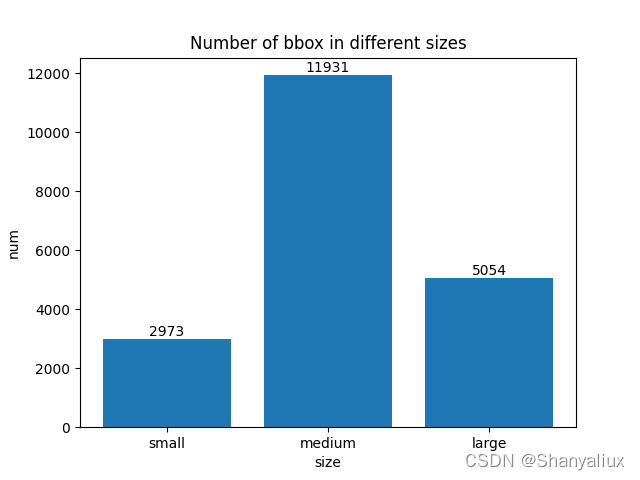
不同尺寸的图片数量
根据coco的划分规则计算
每一类标注框的宽度高度散点图
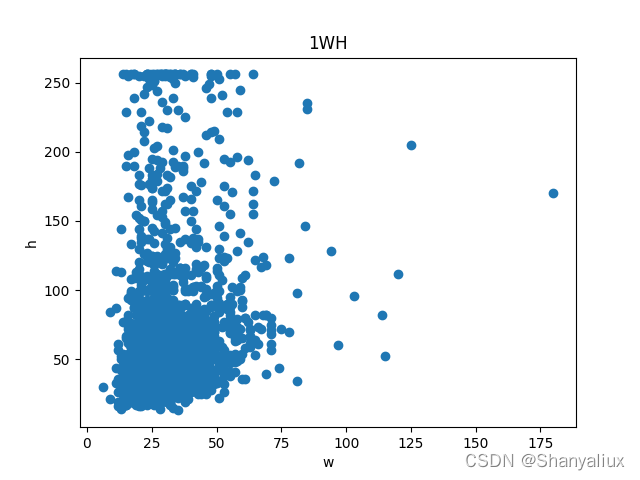
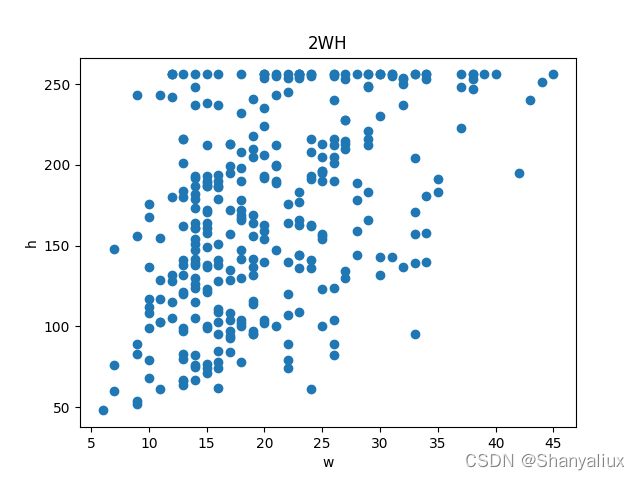
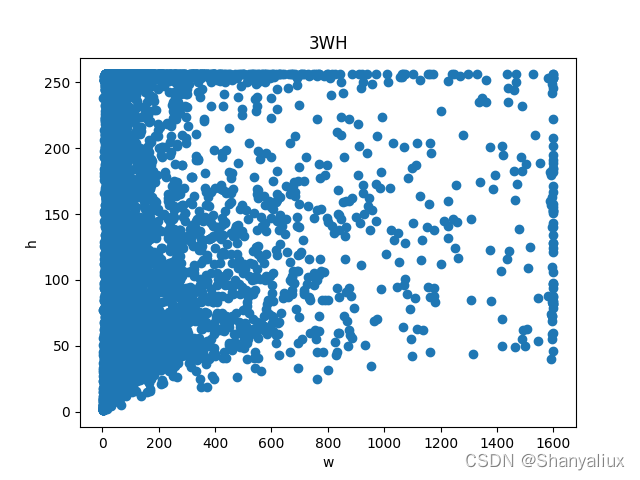
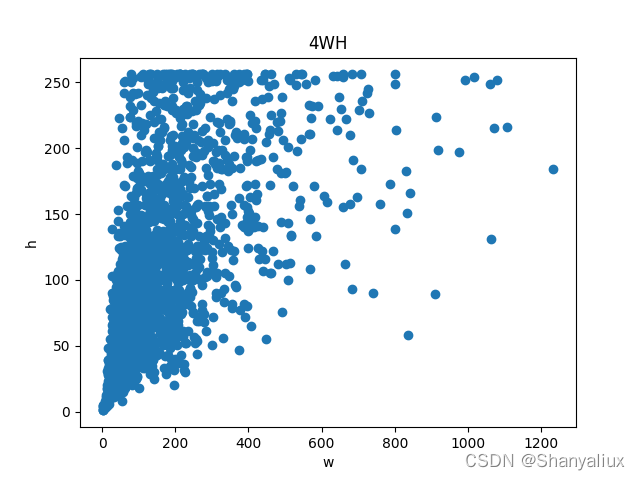
使用方法
Install
git clone https://github.com/Shanyaliux/DataAnalyze.git
cd DataAnalyze
pip install -r requirements.txt
Usage
python DataAnalyze.py ${type} ${path} [--out ${out}]
-
typeThe format of the dataset, optional 'coco' or 'voc'. -
pathThe path of dataset.
Iftypeis 'coco', thepathis the json file path.
Iftypeis 'voc', thepathis the path of the xml file directory. -
--outis the output directory, default is './out'
Example
python DataAnalyze.py coco ./tarin.json --out ./out/
python DataAnalyze.py voc ./xml/ --out ./out/
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:目标检测数据集分析 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 