饼图常用于统计学模块,画饼图用到的方法为:pie( )
一、pie()函数用来绘制饼图
pie(x, explode=None, labels=None, colors=None, autopct=None, pctdistance=0.6, shadow=False, labeldistance=1.1, startangle=0, radius=1, counterclock=True, wedgeprops=None, textprops=None, center=0, 0, frame=False, rotatelabels=False, *, normalize=None, data=None)
pie()函数参数较多,需要我们调整的常见为以下几个
x: 每个扇形的占比的序列或数组
explode :如果不是None,则是一个len(x)长度的数组,指定每一块的突出程度;突出显示,设置每一块分割出来的间隙大小
labels:为每个扇形提供标签的字符串序列
colors:为每个扇形提供颜色的字符串序列
autopct :如果是一个格式字符串,标签将是fmt % pct。如果是一个函数,它将被调用。
shadow:阴影
startangle:从x轴逆时针旋转,饼的旋转角度 参数用法,可以去官网查询,并自己多去偿试。
二、一个简单的例子:统计每天休息、工作、娱乐等时间的百分比
import matplotlib.pyplot as plt slices = [7,2,9,3,3] activities = ['sleeping','eating','working','studing','playing'] cols = ['r','m','y','c','b'] plt.pie(slices, labels=activities, colors=cols, #自定义的颜色序列,对比slices,可多可少,少时自动补充,如没有,则默认不同颜色。 startangle=90, shadow= True, explode=(0,0.1,0,0,0.2),#占比突出程度, autopct='%1.1f%%' #百分比的显示格式 ) plt.title('Time statistics') plt.show()
实际运行结果:
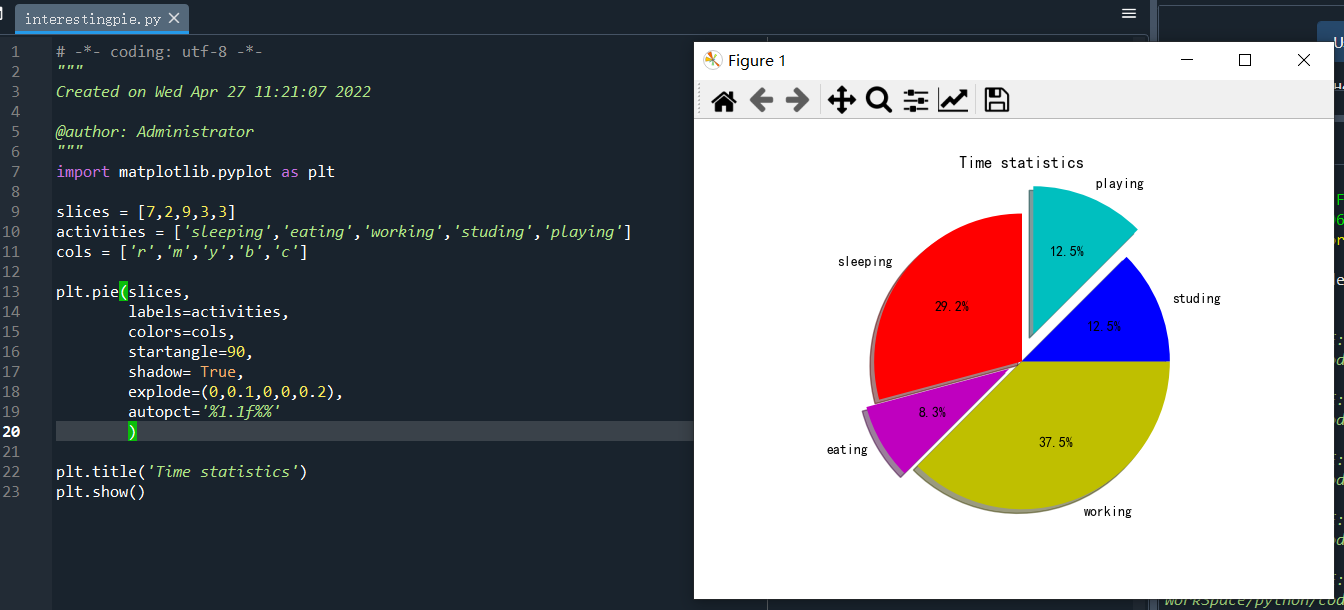

注意:startangle=90时的开始位置。整个饼图是从0度(圆心向右方向)逆时针分布的。
那继续用上篇创建的2个色子,来实现一个饼图。
思考:上述饼图代码中最能决定饼图形状的参数是slices = [7,2,9,3,3],在不考虑每个占比名称、美观等的情况下,先确定如何实现slices中的各数值。
比如,当投掷2粒色子(一个8个面,一个6个面)时,1000000次时,分别统计出现点1、2、3、4、5……14的总次数,保存到slices中即可。用数列中的统计方法 list.count()即可。
主要就是增加两行代码:
new_slices=[] # 新建一个数列 while side <= max_result: side += 1 new_bins.append(side) #这是之前做柱状图需要用到的 new_slices.append( results.count(int(side)) ) #将保存两色子之和的数列,直接进行统计,results.count(int(side))就是在results的数列中统计出现side的次数。
运行结果,一样也是显示出点数之和7,8,9的出现的次数最多,然后逐渐减小:
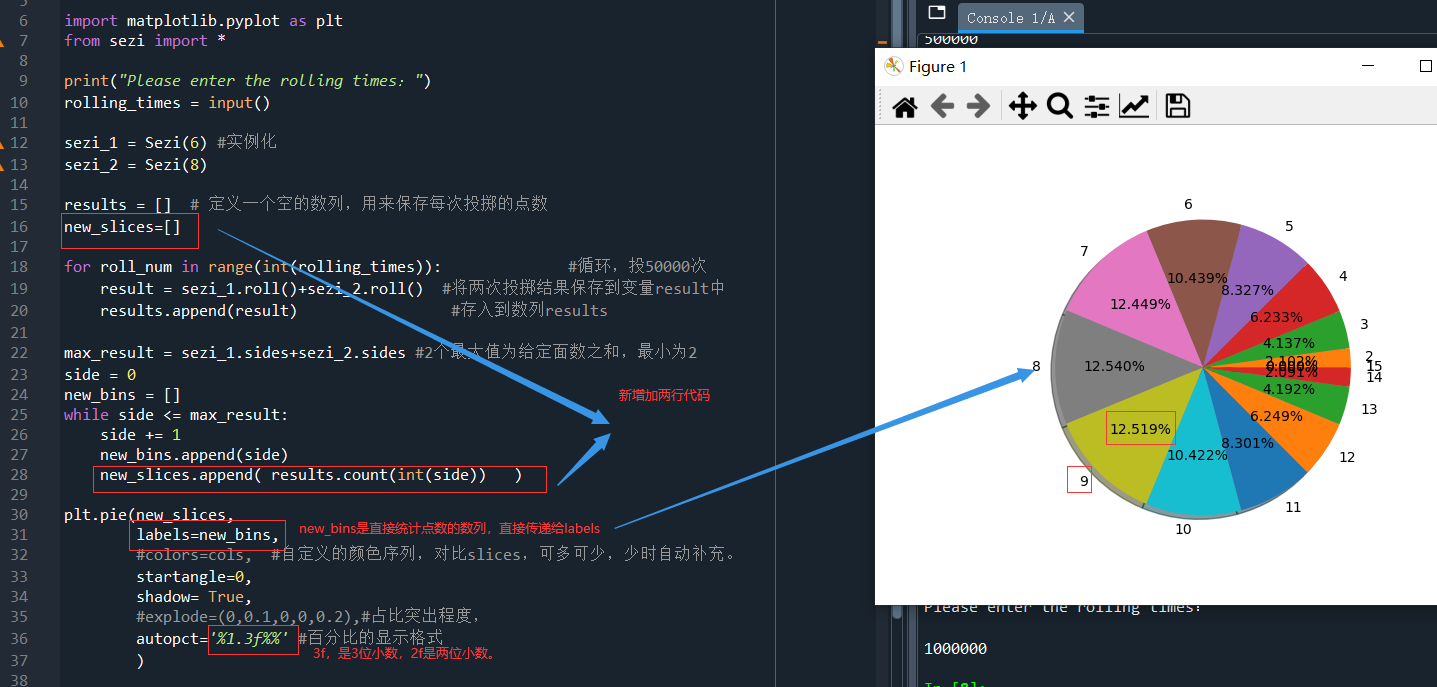
总之,饼图通过将一个圆按照分类的占比划分成多个区块,整个圆饼代表数据的总量,每个区块表示该分类占总体的比例大小,所有区块的加和等于100%。
三、 堆叠图
使用matplotlib中的stackplot()函数可以快速绘制堆积图,stackplot()函数的语法格式如下所示
stackplot(x, y, labels=(), baseling='zero', data=None, *args, **kwargs)
该函数常用参数的含义如下
x:表示x轴的数据,可以是一维数组。
y:表示y轴的数据,可以是二维数组或一维数组序列。
labels:表示每组折线及填充区域的标签。
baseline:表示计算基线的方法,包括'zero'、'sym'、'wiggle'和'weighted_wiggle'。
其中,'zero'表示恒定零基线,即简单的堆积图;
'sym'表示对称于零基线;
'wiggle'表示最小化平方斜率的总和;
'weighted_wiggle'表示执行相同的操作,但权重用于说明每层的大小。
用同一个例子来看一下堆叠图的效果,代码如下:
import matplotlib.pyplot as plt days = [1,2,3,4,5,6,7] sleeping =[7,8,6,8,7,8,6] eating = [2,3,3,3,2,2,2] working = [7,7,7,8,10,3,4] studing = [6,4,4,4,3,8,11] playing = [2,2,4,1,2,3,1] labellist = ['sleeping','eating','working','studing','playing'] colorlist = ['c','y','b','r','g'] plt.stackplot(days, sleeping,eating,working,studing,playing,labels=labellist,colors=colorlist) plt.xlabel('x') plt.ylabel('y') plt.legend(loc=(0.07, 0.05)) plt.title('Stack Plots') plt.show()
运行结果如下:
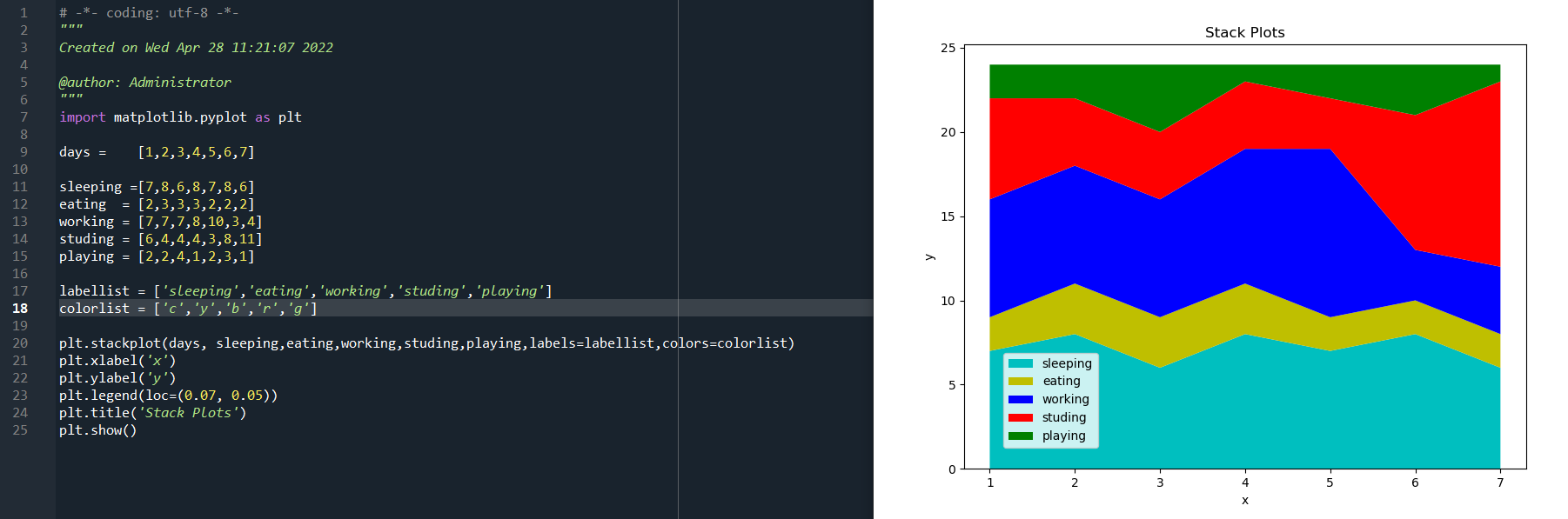
plt.legend()是显示左下角的标签。而语句plt.stackplot()函数中的sleeping,eating,working,studing,playing是一维数组序列,即stackplot(x,y……)中的y值,是一系列一维数据。
很明显,通过上述饼图与堆叠图的对比,它们的区别:饼图只能展示一段时间里,某个项目所花时间占总时间的比,而堆叠图可以展示这一段时间里,每天各项所花费时间。
既然sleeping,eating,working,studing,playing形成的一维数组,感觉参数比较多,那直接形成一个二维数组如何?做如下修改:
days = [1,2,3,4,5,6,7] """ sleeping =[7,8,6,8,7,8,6] eating = [2,3,3,3,2,2,2] working = [7,7,7,8,10,3,4] studing = [6,4,4,4,3,8,11] playing = [2,2,4,1,2,3,1] """ times =[ # 二维数组,以数列作为元素的数列。 [7,8,6,8,7,8,6], #上述sleeping数列 [2,3,3,3,2,2,2], [7,7,7,8,10,3,4], [6,4,4,4,3,8,11], [2,2,4,1,2,3,1] ]
plt.stackplot(days, times,labels=labellist,colors=colorlist)
运行结果如图:
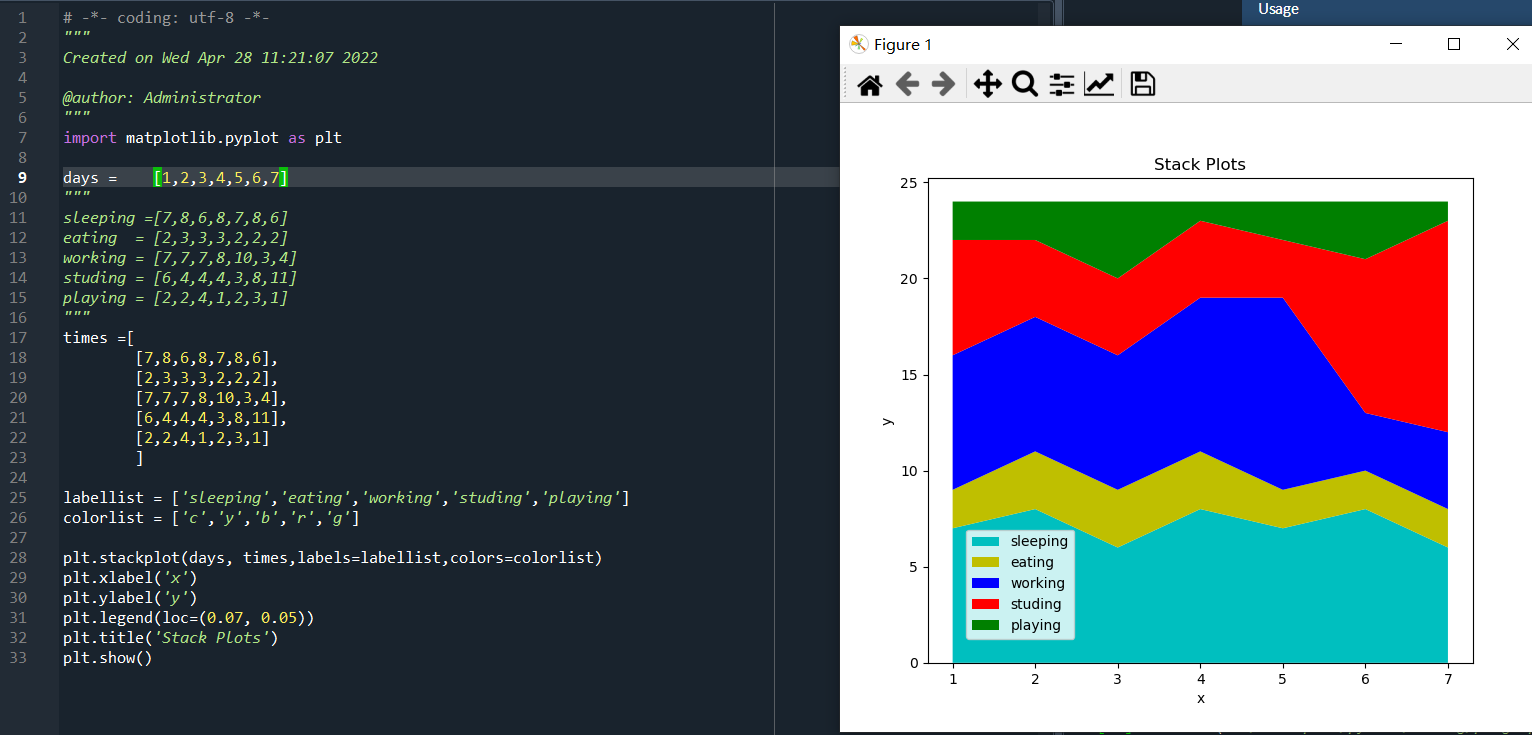
效果与原来的一维数组一样。
但手工这样编程的时候录入数据太过麻烦,下篇介绍直接读取文件数据并进行处理。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:python数据可视化-matplotlib入门(5)-饼图和堆叠图 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 