作者
朱建平,TEG/云架构平台部/块与表格存储中心副总监。08年加入腾讯后,承担过对象存储、键值存储,先后负责过KV存储-TSSD、对象存储-TFS等多个存储平台。
NoSQL 技术和行业背景
NoSQL 是对不同于传统关系型数据库的一个统称,提出 NoSQL 的初衷是针对某些场景简化关系型数据库的设计,更容易水平扩展存储和计算,更侧重于实现高并发、高可用和高伸缩性。
NoSQL vs 关系型数据库
其实早几年大家看两者的区别是清晰的,关系型数据库就是用 SQL 语句操作,具有行列结构和预定义 scheme 的二维表;NoSQL 是 Key-Value 存储,它是一个分布式的 Hash Map 的存储。但最近几年却有些不清晰了?主要是出现 NoSQL 的部分产品也开始增强在SQL的接口和事务等方面的能力,比如 Cassandra 支持 CQL,DynamoDB 支持 PartiQL,InfluxDB 也支持 InfuxQL 等。这里我的看法是,NoSQL vs 关系型数据库的关键差异:关系型数据库具有强大的 ACID 事务、复杂 SQL 检索、数据完整性约束等能力,这给它带来很好的易用性,但同时也是它实现高并发、高可用和高伸缩性的束缚;NoSQL 在工程实现上做了个取舍平衡,弱化甚至舍弃了在跨分区事务、分布式JOIN等维度的能力,增强其在高并发、高可用和高伸缩性方面的能力。
多模型 NoSQL 的数据模型
多模型 NoSQL 中的多模型是指这里包括多个数据模型:键值模型 Key-Value、宽表模型 Wide-column、文档模型 Document、时序模型 Time-series、图模型 Graph 和内存模型 in-memory 等。我们可以简单理解,Key-Value 是个哈希表,Wide-column 是个多维的哈希表即 Key-Key-Value 结构,文档 Document 是类似于 Json 结构的一个嵌套树结构,Graph 是以顶点和边组成的复杂图结构,Time-series 是按时间有序的一个检索表。
数据模型使用和发展可以从受欢迎程度和增长速度两个指标来看。受欢迎程度反映着应用推广的累积效应,排名前三的依次为 文档>键值>宽表;增长速度代表着未来需求的反应,排名前三依次 时序>键值>图,其中时序和图得益于物联网LoT以及实时计算等方面需求目前增长较为迅速,国外 NoSQL 的一些创业公司,近期较多集中在时序和图存储相关领域。
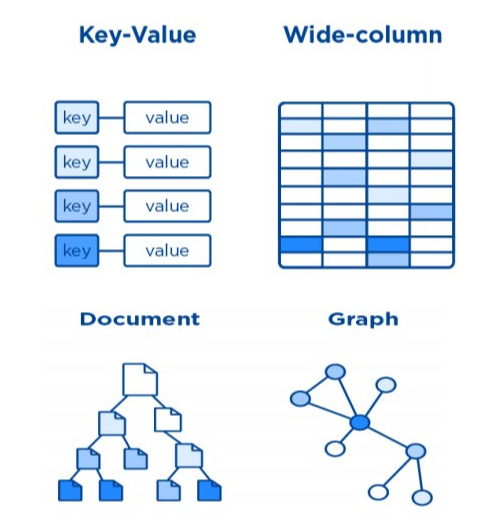

NoSQL 存储领域的业界玩家
主要分为三类:垂直领域的开源社区、多模型 NoSQL 公司 和公有云厂商。
垂直领域的开源社区,包括键值存储领域的 Redis,文档存储的 MongoDB,时序存储领域的 InfluxDB、图存储的 Neo4j 等,这些公司都是从垂直开源社区多年的竞争中突围出来的赢家,掌握了垂直领域的生态和接口的标准,基于公有云开展支持多云的企业服务。
多模型NoSQL公司,如YugabyteDB、Aerospike等,虽然也是开源,也是基于公有云开展支持多云的企业服务,但并不掌握垂直领域生态和接口标准,更多地兼容Redis、Cassandra、PG(PostgreSQL)等接口标准去融入已有的生态。
公有云厂商,如微软 Azure CosmosDB、亚马逊 AWS DynamoDB 等,提供了云原生的托管存储服务,在接口上采用自定义或者直接兼容开源社区的 Redis 和 Cassandra 等垂直领域的接口。
而我们的 NoSQL 属于这里的第三类玩家。
据市场公开数据显示,最近几年这三类厂商都有比较好的市场增速,但也存在着垂直领域、开源社区和公有云厂商的一些矛盾和竞争。

NoSQL 存储的发展方向与趋势
公司内部自研的 NoSQL,源于早些年结合业务场景的定制开发。比如我们 oTeam 中的 CKV+、TSSD、PCG 的 BDB 、Grocery 等。但是面向云原生的场景下、新的软硬件基础设施升级以及新场景的扩展支持也面临着新的挑战,以及无法同时兼顾内部自用与云上外部客户的一些诉求。
首先,云原生场景下客户对自研提出了更高的要求。例如要求解除云厂商的绑定,就是采用业界 API 的接口标准,支持多可用区和地域的分布,弹性伸缩,按需付费容器化和分布式云等方式部署。
其次,持续提升的基础设施能力对底层存储提出更高要求。过去几年,公司机房、网络环境、微服务框架、系统、软件等基础设施方面的能力都得到极大的提升,如 SSD 单盘容量,以及单台存储服务器配置的磁盘数量都有了较显著的增长,新 TRPC 框架、新网络和新的磁盘 IO 通道,如 RDMA/DPDK、SPDK/IO_URING 等能力的推出,均要求底层的存储架构进行不断地适配,以获取更高的性价比。
最后,个性化内容推荐和物联网监控等新生场景出现。相较于以往我们在社交网络中的键值存储场景,近年来也出现了诸如个性化内容推荐中的特征存储、物联网/监控中的时序存储等新生场景,而它们在 API 接口、功能、存储引擎等方面跟以往的键值存储使用是有所差异,需要能复用平台的大部分能力,同时也需要能定制部分组件。
为了应对新的机遇和挑战,我们联合了 PCG、CSIG、WXG 和 IEG 相关团队,在2021年组建了多模型 NoSQL 的 Oteam,支持新的业务场景。经过 oTeam 各方的一起努力,从零研发出多模型 NoSQL 平台(X-Stor),目前已完成了平台技术能力和规模化运营能力的初步建设。
重新再造--多模型 NoSQL 系统架构
多模型 NoSQL 架构和目标
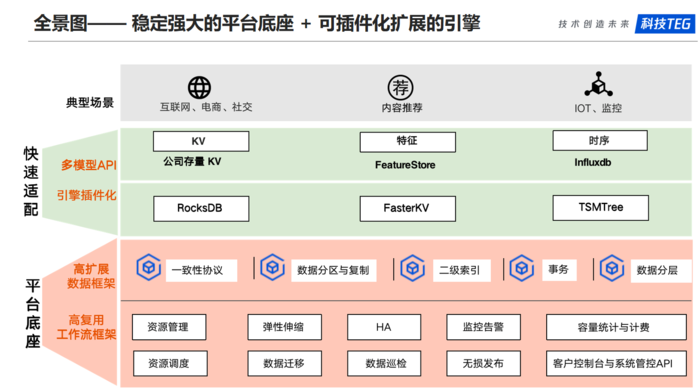
多模型 NoSQL 两个核心目标:一是要提供稳定强大的平台底座,供不同的扩展实现复用;二是提供快速适配的能力,供业务定制化开发或者是新的场景的扩展。
平台底座,包括在线访问相关和管控相关。一 在线访问相关部分,提供高度可扩展的数据处理框架,具体包括支持多种数据一致性,数据分区与多 AZ/Region 的数据副本复制、数据分层以及索引和事务等方面的能力。二 管控相关的部分,提供工作流引擎 WorkFlow,并基于这个工作流引擎实现了资源管理、数据迁移、数据备份和定点回档、数据巡检等运营管控能力。
快速适配,包括可扩展多模型API和存储引擎框架。可扩展多模型 API,方便协同方根据业务场景需求定制访问协议。目前的 API 接口已支持TSSD/BDB/Grocery 等存量键值存储平台的接口和功能,同时也支持了部分 Redis 的接口。存储引擎的框架,方便根据业务场景定制自己的存储引擎,在内存占用和磁盘 IO 资源方面进行取舍和平衡。目前已经支持的 LSM-Tree 的 RocksDB 存储引擎,基于Hash的 FasterKV 引擎和基于 TSM-Tree 的时序 TSDB 存储引擎。
多模型 NoSQL 资源概念
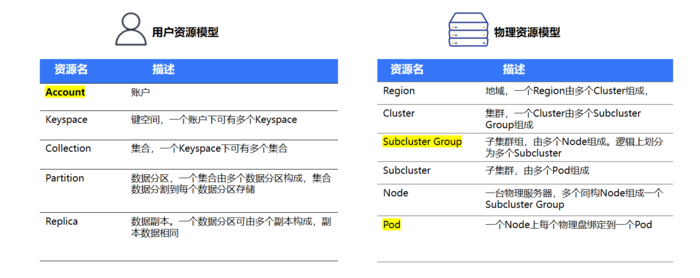
多模型 NoSQL 资源概念,我们分为用户资源和物理资源。
用户资源是用户创建的逻辑资源,主要有 Account、Keyspace、Collection、Partition、Replica。这里大家比较陌生的可能是 Account 这个概念。多模型 NoSQL 的 Account 主要不是为了计费设计的,它跟腾讯云的账户或者公司内计费的 OBS 系统的账户不一样,主要目的是方便客户配置 Collection 的公共属性,以及底层根据 Collection 的相关性做资源的共享,比如接入机关联的北极星的入口,甚至同账户下的 Replica 副本将他们调度到一起,方便在资源层面进行多租户隔离和复用。
物理资源是管理的服务器资源,目前我们申请的存储服务器和接入/逻辑类的TKE容器。对于存储服务器进行容器化,比如对一个配置了12块SSD 的存储服务器,我们创建了12个 TKE 的容器,让每个容器关联到一块 SSD 盘,我们称之为一个 Pod,相应地这台存储服务器我们称之为一个 Node。根据硬件的物理分布,我们给每个 PoD 的关联地域属性 Region,集群属性 Cluster,子集群的属性Subcluster Group,我们称为 SCG,子集群属性Subcluster Region、Subcluster Group 和 Subcluster 之间是逐层包含的一个关系。SCG将指定数量的Node组成一个节点组,而 Subcluster 的是加 SCG 的部分盘组成的一个盘组。通过将一个Partition多个副本分布在这些Group的内部,方便有效地管理同时多个节点或者磁盘故障带来的风险,同时也能控制我们在故障发生时的爆炸半径,影响半径。有兴趣的同学可以在网上 google 下 CopySet 的论文,对其原理做进一步的了解。
多模型 NoSQL 模块结构
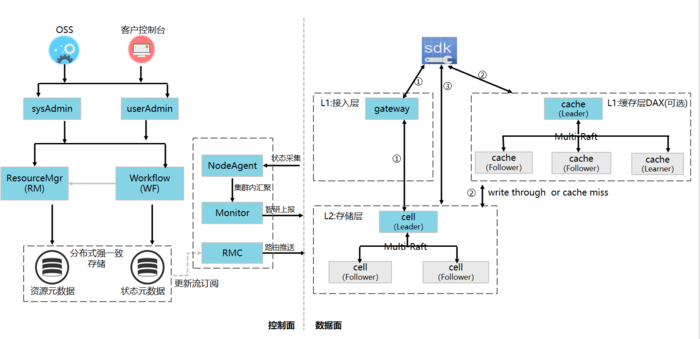
多模型 NoSQL 的模块架构中,我们分为数据面和控制面。数据面主要是指业务在线增/删/改/查请求路径上的模块;控制面是业务的控制台、运维系统,或者内部的定时任务维护处理所涉及的模块。
数据面模块架构,为方便长尾延时的管控和成本的控制,采用两层设计,服务一个请求后端最多经过两跳,业务场景需求设计三类请求处理。
常规路径(标①),请求到达接入层 gateway,其查询本地缓存的元信息,并将请求转发给底层的存储模块cell,独立gateway部署方便于收敛前端网络连接数,以及业务前端不支持定制SDK的场景。
缓存路径(标②),请求到达接入层 cache,其查询本地的内存缓存,如果命中就直接返回,如果不命中,访问底层存储模块 cell 查询获取并通知 cache 主节点,由 cache 主节点根据预配置的缓存策略更新缓存并基于一致性协议同步更新给所有 cache 从节点。便于降低有明显热点效应的业务请求,降低访问成本。
定制路径(标③),通过定制的 sdk 允许客户端直连存储节点,实现一跳访问,同时也可以将部分计算功能卸载到客户端上执行,有利于降低访问延时,减少计算成本。
控制面模块结构,控制面对外的访问入口有两个访问网关和三个内部部分。访问网关为 userAdmin 和 sysAdmin,userAdmin 是供客户控制台API访问的网关,sysAdmin 是供运维系统访问的网关。内部三个部分分别是元数据的存储和分发、工作流 Workflow 和监控。
元数据存储和分发,主要是资源管理服务,包含资源管理服务(RM)和资源管理缓存服务(RMC)。元数据采用分布式的强一致存储,目前是五副本存储在 CMongo 中,未来会考虑闭环存储于自身系统里面。RMC是为了方便于元数据分发而设计的,数据面的 gateway 和 cache 服务启动后会注册到RMC,方便 RMC 做元数据的增量、推送、分发和一次性校验,通过 userAdmin 和 sysAdmin 网关访问 RM,实现元数据的更新,RMC 通过更新流感知到这个数据的变动,并推知元数据的更新给注册到自己的 gateway 和 cache 容器。
工作流 Workflow,以往存储管控的实践中,通常是基于微服务架构设计数据迁移服务、数据巡检服务、数据调度服务、容量采集服务、数据冷备服务、资源上下架服务等众多的独立模块上来实现存储管控。虽然实现了较好的伸缩性,但模块多会增加开发、维护、运营、管理方面的成本。在 X-Stor 中,我们设计的是 Workflow 框架,搭积木的方式配置组装处理流程,实现可重入的执行。通过 Workflow 框架,结合容器化部署,共用一个 Workflow 服务来实现上述的所有功能,同时自动伸缩和容错,对所有的 Workflow 执行、日志存档和审计等能力也非常容易实现。
监控,通过在每个服务器 Node 的上面本地部署 NodeAgent,实时汇集本 Node 上的各个容器的状态信息,并且推送给集群的 Monitor 服务。 Monitor 服务对接到 Prometheus 的存储、集群调度服务、监控报警组件如 TEG 智研监控宝等,可以方便地按集群实现实时调度和基于 Grafana 定制一个自己的可视化 Dashboard。
云原生能力设计与思考
可扩展和云原生是我们设计多模型 NoSQL 时考虑的两个目标。前面介绍了实现扩展性的相关的架构内容,系统助于扩展性,支持多种数据访问、API 和存储引擎来实现多模型存储。接下来我想分享下在云原生上的设计思考。
云原生这个词是最近几年大家经常听到的概念,但当你百度这个概念时却发现很难比较清晰的理解。我个人的理解,云原生核心有两个概念,云原生产品和云原生技术。云原生产品是在公有云普及的大背景下,站在客户的视角,对云端提供服务的产品提出的能力和要求,比如弹性伸缩、可观测性等。云原生技术是帮助实现云原生产品的技术手段,如容器、服务网格、微服务、不可变的基础设施和声明式 api 等。多模型 NoSQL 从设计之初,我们就与相关的原生技术进行紧密结合,考虑了基于云原生的能力。我们云原生的特性重点体现在开放性、弹性伸缩、按需付费、多 AZ 和 Region 数据分布四个方面。
01 开放性
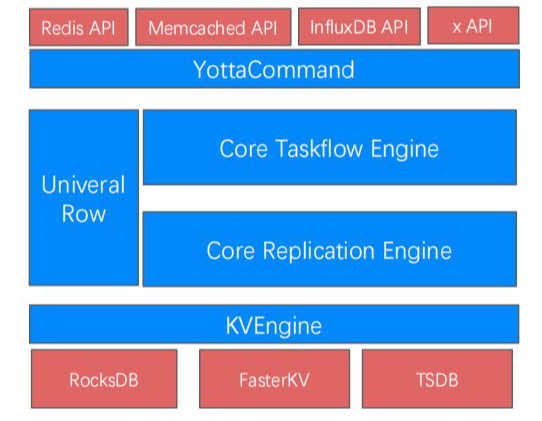
多模型 NoSQL 的开放性主要在下面三个维度进行体现。
首先,接口和功能的开放。客户出于成本、容错等方面的考虑提出了多云的诉求,要求对云端产品打破厂商绑定(Vendor Lockin),需要产品可以实现在不同的云厂商间迁移。云原生产品需要尊重这个考虑,我们放弃了锁定自定义私有协议和接口,转向全面兼容垂直社区软件接口和功能,如 Redis、InfluxDB 等,未来还会在数据迁移 DTS 能力方面进一步补齐。
其次,支持扩展、开放互联的连接器(Connector)。不断丰富跟公有云上的其他的云原生产品实现互联互通,如目前我们已经支持的数据镜像、备份和更新流水存放于对象存储产品 COS 或者其他兼容 S3 接口的产品,更新流可以导入到我们 Kafka 队列中,未来可能会推出更多的连接器,能连接到相关的云端产品。
最后,在资源层面,部署产品时不锁定特定的硬件资源。我们率先在公司内实现了从接入到存储完全架构在 K8S 的容器化化环境中,从能力上可以支持多云和分布式云的部署。
02 弹性伸缩
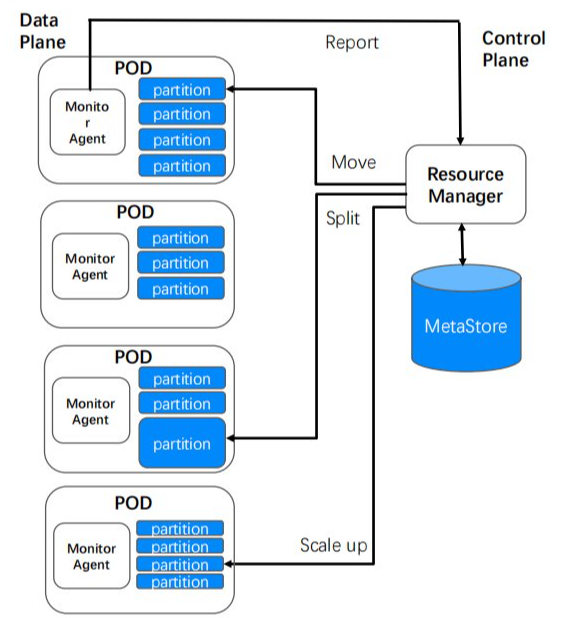
弹性伸缩,是云原生产品非常重要的能力,解决以往自行开发在软件架构层面或者在资源层面上面临的一些瓶颈。多模型 NoSQL 从客户资源、服务器或者容器资源方面实现了弹性伸缩。
首先,通过分布式强一致存储和分发的架构,提供强大的元数据存储和访问能力,支持用户的库表数量和单个库表容量的伸缩能力;通过水平伸缩的架构和底层的调度能力,支持单个表在存储和访问容量上无限横向伸缩。
其次,通过对资源的容器化和标准化,实现了从公司大的资源池中实时申请和释放容器资源,便于我们快速地满足业务在资源规格、资源数量和资源在机房分布等方面的要求。
最后,在伸缩的速度和效率方面,借助前面提到的数据副本的分布策略和数据的实时采集调度,实现了极速地扩容和自动化伸缩,垂直伸缩小于10秒,4TB 水平伸缩小于5分钟。
03 按需付费
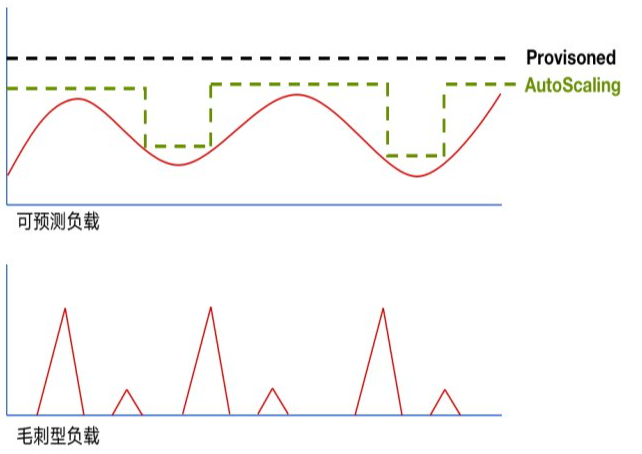
按需付费,是云原生产品帮助客户实现低成本运营的关键能力。在这方面我们主要实现了两个方面的能力。
一是存储和计算的分开计费。不需要客户从几个预定规格的容器中去做选择,客户仅需要关注于存储容量和计算容量,底层通过集约化管理给各个库表预留的 Buffer Pool,通过多租户技术和装箱调度,提升资源的整体利用率,通过我们的资源池管理和资源利用率提升达到帮助客户去节省运营成本。
其次,灵活选择。通过在客户控制台/API 中方便灵活选择,而不是刚性地捆绑/锚定,实现贴合业务场景需求来实现最高的性价比。如我们在于数据的一致性,数据的副本数,多 Region 的分布,数据生命周期,甚至存储介质方面灵活地配置。在资源独享方面,平衡成本和性能,在存储机和接入机方面独享和混用,可以独立配置。
04 多 AZ 和 Region 分布
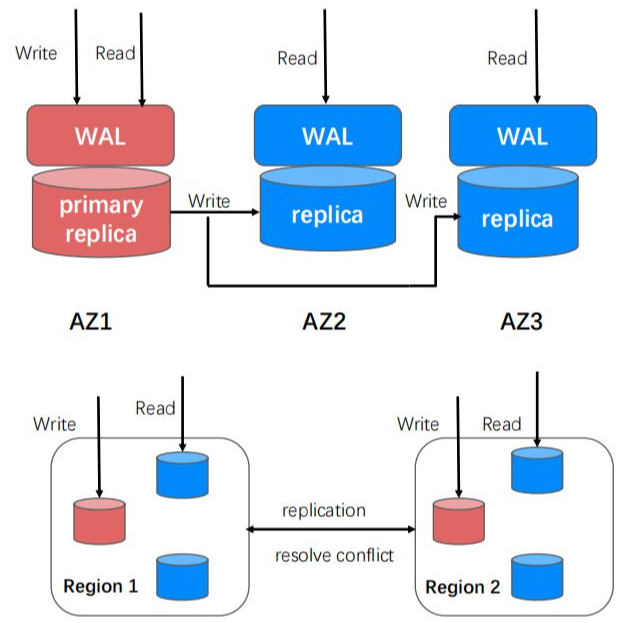
多 AZ 和 Region 分布,是云原生产品实现高可用性、数据高可靠性方面的基础要求。
公有云中的 AZ 和 Region 跟我们常见的机房和城市的概念不完全一样。如同 Region 下的多个 AZ 要求相距30到100千米,RTT 一般在0.5到2毫秒以内。不同 Region 间的物理距离一般在100千米以上。X-Stor 通过对资源构建 AZ 和 Region 的属性,并结合集群调度、数据同步等方面的支持,实现了多 AZ 和 Region 数据分布的能力,可结合业务自身对于数据的一致性需求实现就近访问;同时也计划在多 Region 分布的基础上,支持异地多活(Multi-Master)。对于多 Region 分布的 Collection,可以在任意的 Region 中就近写入,内部我们对于 Region 间的数据进行复制,并解决并发冲突的问题,进一步优化写延时的体验。
关于我们
更多关于云原生的案例和知识,可关注同名【腾讯云原生】公众号~
福利:
①公众号后台回复【手册】,可获得《腾讯云原生路线图手册》&《腾讯云原生最佳实践》~
②公众号后台回复【系列】,可获得《15个系列100+篇超实用云原生原创干货合集》,包含Kubernetes 降本增效、K8s 性能优化实践、最佳实践等系列。
③公众号后台回复【白皮书】,可获得《腾讯云容器安全白皮书》&《降本之源-云原生成本管理白皮书v1.0》
④公众号后台回复【光速入门】,可获得腾讯云专家5万字精华教程,光速入门Prometheus和Grafana。
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!

本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:技术分享 | 云原生多模型 NoSQL 概述 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 