作者:王雷
etcd是什么
etcd是云原生架构中重要的基础组件,由CNCF孵化托管。ETCD是用于共享配置和服务发现的分布式,一致性的KV存储系统,是CoreOS公司发起的一个开源项目,授权协议为Apache。etcd 基于Go语言实现,主要用于共享配置,服务发现,集群监控,leader选举,分布式锁等场景。在微服务和 Kubernates 集群中不仅可以作为服务注册发现,还可以作为 key-value 存储的中间件。
提到键值存储系统,在大数据领域应用最多的当属ZOOKEEPER,而ETCD可以算得上是后起之秀了。在项目实现,一致性协议易理解性,运维,安全等多个维度上,ETCD相比Zookeeper都占据优势。
ETCD vs ZK
| ETCD | ZK | |
|---|---|---|
| 一致性协议 | Raft协议 | ZAB(类Paxos协议) |
| 运维方面 | 方便运维 | 难以运维 |
| 项目活跃度 | 活跃 | 没有etcd活跃 |
| API | ETCD提供HTTP+JSON, gRPC接口,跨平台跨语言 | ZK需要使用其客户端 |
| 访问安全方面 | ETCD支持HTTPS访问 | ZK在这方面不支持 |
etcd的架构
etcd 是一个分布式的、可靠的 key-value 存储系统,它用于存储分布式系统中的关键数据,这个定义非常重要。
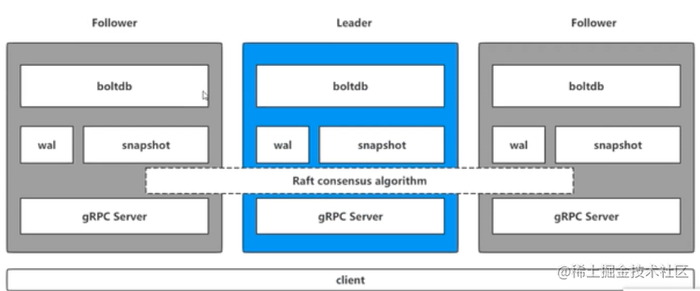

通过下面这个指令,了解一下etcd命令的执行流程,其中etcdctl:是一个客户端,用来操作etcd。
etcdctl put key test
通常etcd都是以集群的方式来提供服务的,etcdctl操作命令的时候,会对应到leader当中的gRPC Server
gRPC Server
用来接收客户端具体的请求进行处理,但是不仅仅是处理客户端的连接,它同时负责处理集群当中节点之间的通讯。
wal: Write Ahead Log(预写式日志)
etcd 的数据存储方式。除了在内存中存有所有数据的状态以及节点的索引以外,etcd 就通过 WAL 进行持久化存储。WAL 中,所有的数据提交前都会事先记录日志。实现事务日志的标准方法;执行写操作前先写日志,跟mysql中redo类似,wal实现的是顺序写。
当执行put操作时,会修改etcd数据的状态,执行具体的修改的操作,wal是一个日志,在修改数据库状态的时候,会先修改日志。put key test会在wal记录日志,然后会进行广播,广播给集群当中其他的节点设置key的日志。其他节点之后会返回leader是否同意数据的修改,当leader收到一半的请求,就会把值刷到磁盘中。
snapshot
etcd 防止 WAL 文件过多而设置的快照,用于存储某一时刻etcd的所有数据。Snapshot 和 WAL 相结合,etcd 可以有效地进行数据存储和节点故障恢复等操作。
boltdb
相当于mysql当中的存储引擎,etcd中的每个key都会创建一个索引,对应一个B+树。
etcd重要的特性
•存储:数据分层存储在文件目录中,类似于我们日常使用的文件系统;
•Watch 机制:Watch 指定的键、前缀目录的更改,并对更改时间进行通知;
•安全通信:支持 SSL 证书验证;
•高性能:etcd 单实例可以支持 2K/s 读操作,官方也有提供基准测试脚本;
•一致可靠:基于 Raft 共识算法,实现分布式系统内部数据存储、服务调用的一致性和高可用性;
•Revision 机制:每个 Key 带有一个 Revision 号,每进行一次事务便加一,因此它是全局唯一的,如初始值为 0,进行一次 Put 操作,Key 的 Revision 变为 1,同样的操作,再进行一次,Revision 变为 2;换成 Key1 进行 Put 操作,Revision 将变为 3。这种机制有一个作用,即通过 Revision 的大小就可知道写操作的顺序,这对于实现公平锁,队列十分有益;
•lease机制:lease 是分布式系统中一个常见的概念,用于代表一个分布式租约。典型情况下,在分布式系统中需要去检测一个节点是否存活的时,就需要租约机制。
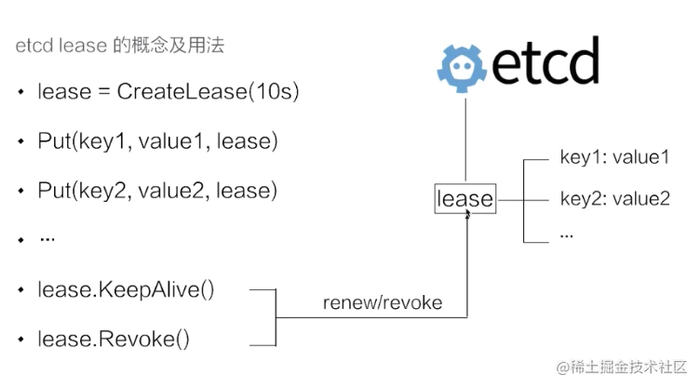
首先创建了一个 10s 的租约,如果创建租约后不做任何的操作,那么 10s 之后,这个租约就会自动过期。接着将 key1 和 key2 两个 key value 绑定到这个租约之上,这样当租约过期时 etcd 就会自动清理掉 key1 和 key2,使得节点 key1 和 key2 具备了超时自动删除的能力。
如果希望这个租约永不过期,需要周期性的调用 KeeyAlive 方法刷新租约。比如说需要检测分布式系统中一个进程是否存活,可以在进程中去创建一个租约,并在该进程中周期性的调用 KeepAlive 的方法。如果一切正常,该节点的租约会一致保持,如果这个进程挂掉了,最终这个租约就会自动过期。
类比redis的expire,redis expore key ttl,如果key过期的话,到了过期时间,redis会删除这个key。etcd的实现:将过期时间相同的key全部绑定一个全局的对象,去管理过期,etcd只需要检测这个对象的过期。通过多个 key 绑定在同一个 lease 的模式,我们可以将超时间相似的 key 聚合在一起,从而大幅减小租约刷新的开销,在不失灵活性同时能够大幅提高 etcd 支持的使用规模。
在引擎中的场景
服务注册发现
etcd基于Raft算法,能够有力的保证分布式场景中的一致性。各个服务启动时注册到etcd上,同时为这些服务配置键的TTL时间。注册到etcd上的各个服务实例通过心跳的方式定期续租,实现服务实例的状态监控。服务提供方在 etcd 指定的目录(前缀机制支持)下注册服务,服务调用方在对应的目录下查询服务。通过 watch 机制,服务调用方还可以监测服务的变化。
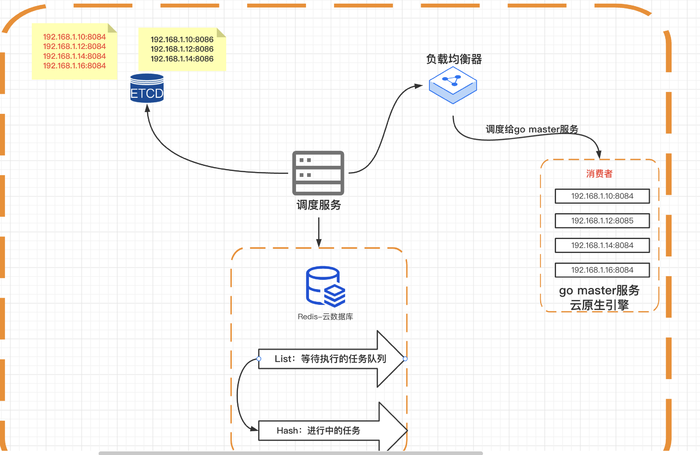
引擎服务包含两大模块,一个是master服务,一个是调度服务。
master服务
master服务启动成功后,向etcd注册服务,并且定时向etcd发送心跳
server, err := NewServiceRegister(key, serviceAddress, 5)
if err != nil {
logging.WebLog.Error(err)
}
定时向etcd发送心跳
//设置续租 定期发送需求请求
leaseRespChan, err := s.cli.KeepAlive(context.Background(), resp.ID)
调度服务
调度服务作为服务的消费者,监听服务目录:key=/publictest/pipeline/
// 从etcd中订阅前缀为 "/pipeline/" 的服务
go etcdv3client.SubscribeService("/publictest/pipeline/", setting.Conf.EtcdConfig)
监听put和delete操作,同时在本地维护serverslist,如果有put或者delete操作,会更新本地的serverslist
客户端发现指客户端直接连接注册中心,获取服务信息,自己实现负载均衡,使用一种负载均衡策略发起请求。优势可以定制化发现策略与负载均衡策略,劣势也很明显,每一个客户端都需要实现对应的服务发现和负载均衡。
watch机制
etcd可以Watch 指定的键、前缀目录的更改,并对更改时间进行通知。BASE引擎中,缓存的清除策略借助etcd来实现。
缓存过期策略:在编译加速的实现中,每个需要缓存的项目都有对应的缓存key,通过etcd监控key,并且设置过期时间,例如7天,如果在7天之内再次命中key,则通过lease进行续约;7天之内key都没有被使用,key就会过期删除,通过监听对应的前缀,在过期删除的时候,调用删除缓存的方法。
storage.Watch("cache/",
func(id string) {
//do nothing
},
func(id string) {
CleanCache(id)
})
除此之外,引擎在流水线取消和人工确认超时的场景中,也使用到了etcd的watch机制,监听某一个前缀的key,如果key发生了变化,进行相应的逻辑处理。
集群监控与****leader选举机制
集群监控:通过 etcd 的 watch 机制,当某个 key 消失或变动时,watcher 会第一时间发现并告知用户。节点可以为 key 设置租约(TTL),比如每隔 30 s 向 etcd 发送一次心跳续约,使代表该节点的 key 保持存活,一旦节点故障,续约停止,对应的 key 将失效删除。如此,通过 watch 机制就可以第一时间检测到各节点的健康状态,以完成集群的监控要求。
Leader 竞选:使用分布式锁,可以很好地实现 Leader 竞选(抢锁成功的成为 Leader)。Leader 应用的经典场景是在搜索系统中建立全量索引。如果每个机器分别进行索引建立,不仅耗时,而且不能保证索引的一致性。通过在 etcd 实现的锁机制竞选 Leader,由 Leader 进行索引计算,再将计算结果分发到其它节点。
类似kafka的controller选举,引擎的调度服务启动,所有的服务都注册到etcd的/leader下面,其中最先注册成功的节点成为leader节点,其他节点自动变成follow。
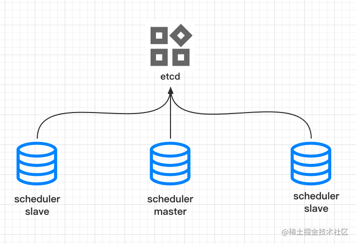
leader节点负责从redis中获取任务,根据负载均衡算法,将任务派发给对应的go master服务。
follow节点监听leader节点的状态,如果leader节点服务不可用,对应节点删除,follow节点会重新抢占,成为新的leader节点。
同时leader设置在etcd中的leader标识设置过期时间为60s,leader每隔30s更新一次。follow每隔30s到etcd中通告自己存活,并检查leader存活。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:分布式注册服务中心etcd在云原生引擎中的实践 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 