一、事件背景
大家好,我是马哥python说,一枚10年程序猿。
演员张天爱于2022.8.25号在网上爆出一段音频 "惯犯,希望所以女孩擦亮眼睛。"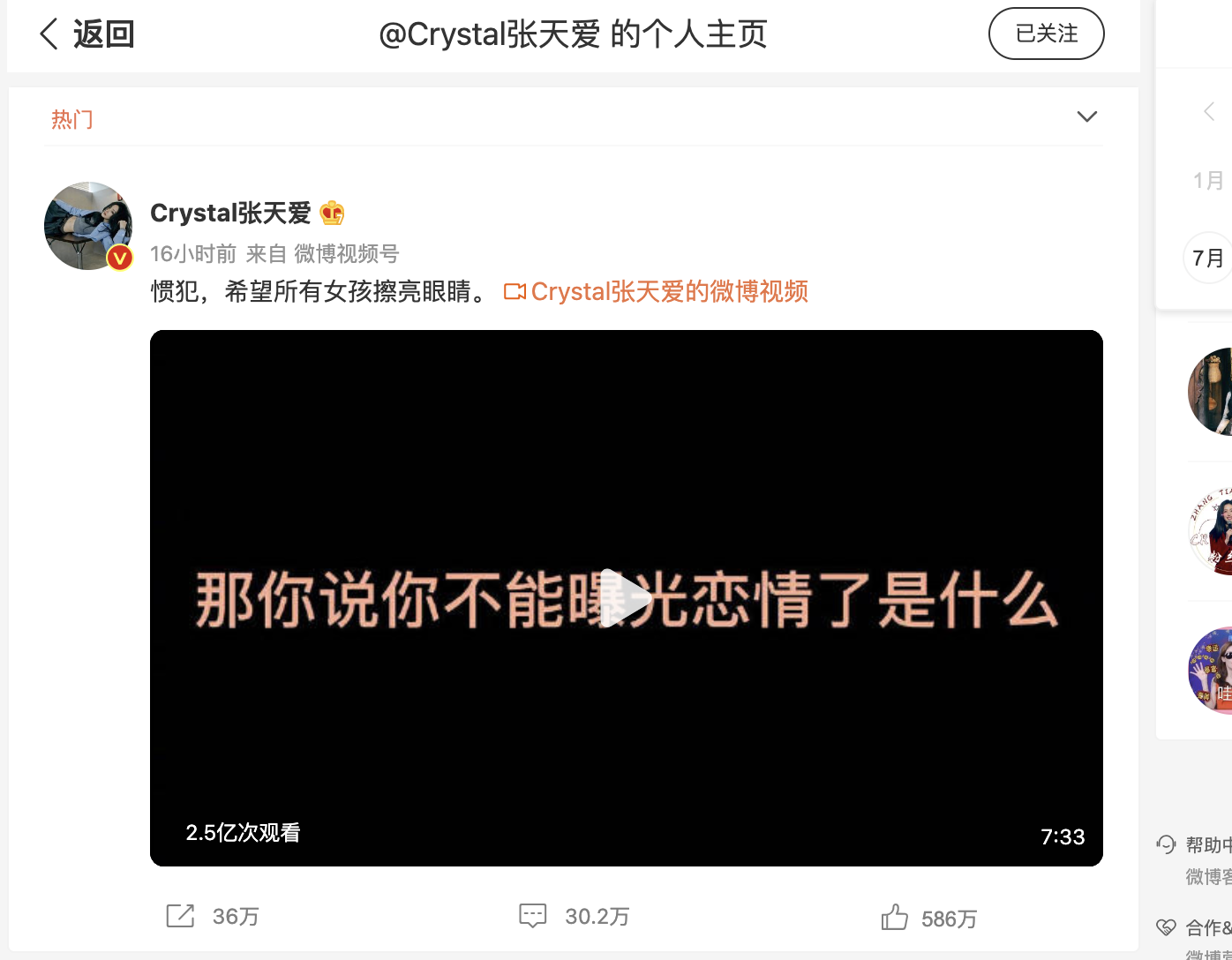

至今已有2.5亿次观看量,瞬间冲上热搜。
二、微热点分析
以下数据来源:微热点
从舆情分析网站上来看,从热度指数的变化趋势来看,"张天爱"的热度在08月25日22时达到了92.56的峰值。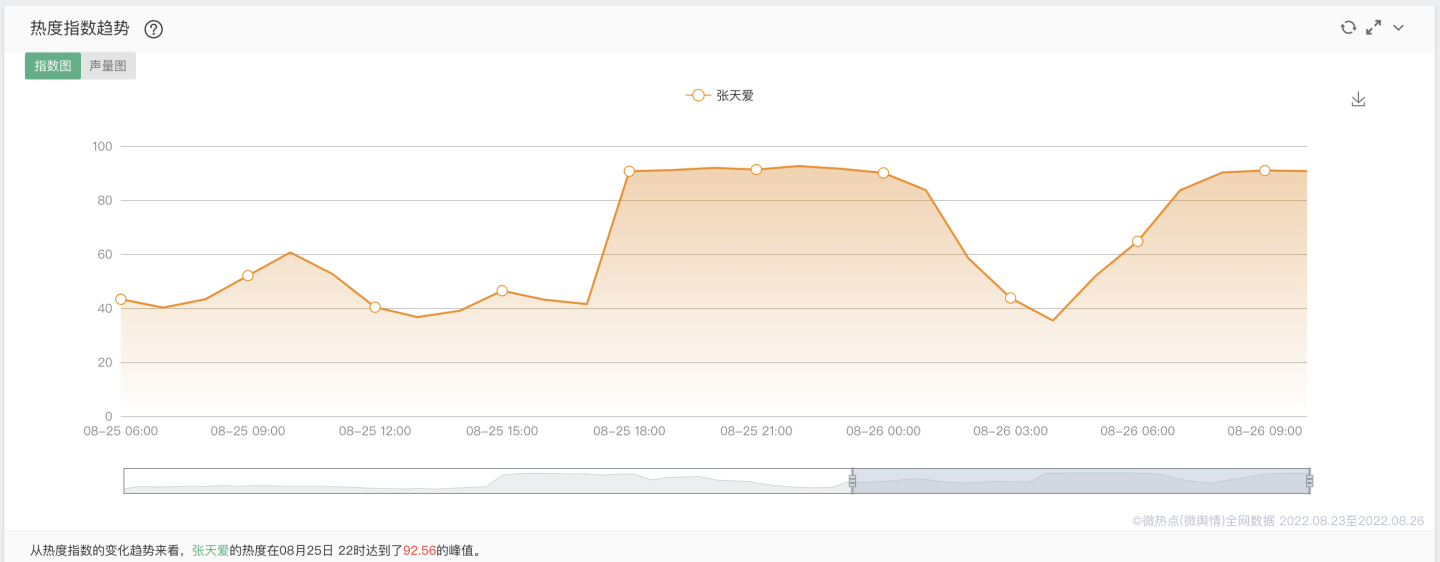
"张天爱"全网热度: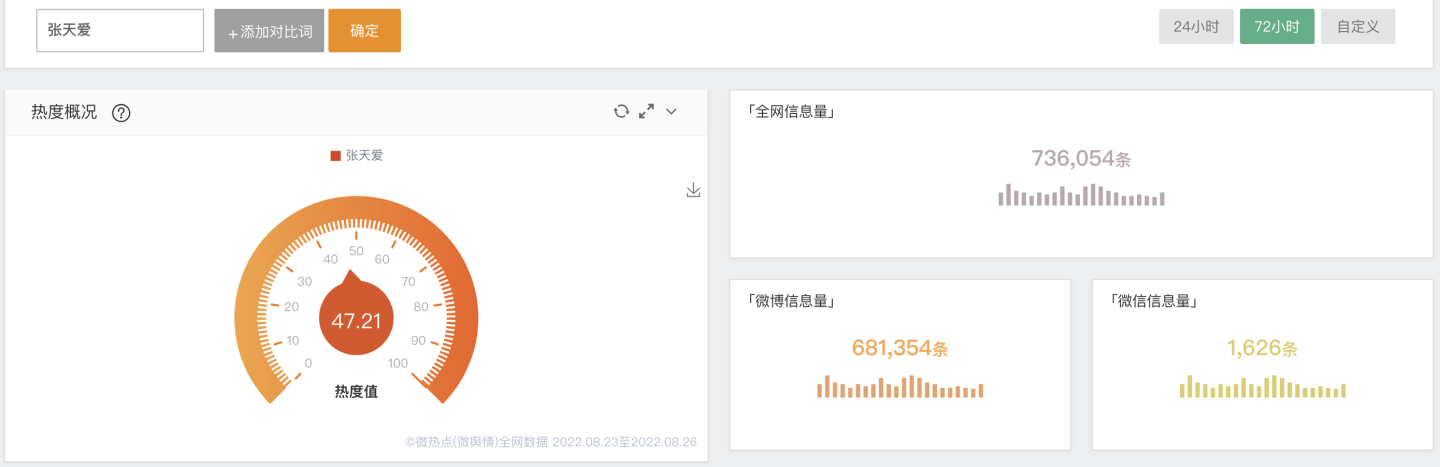
"张天爱"网络媒体的评价指标: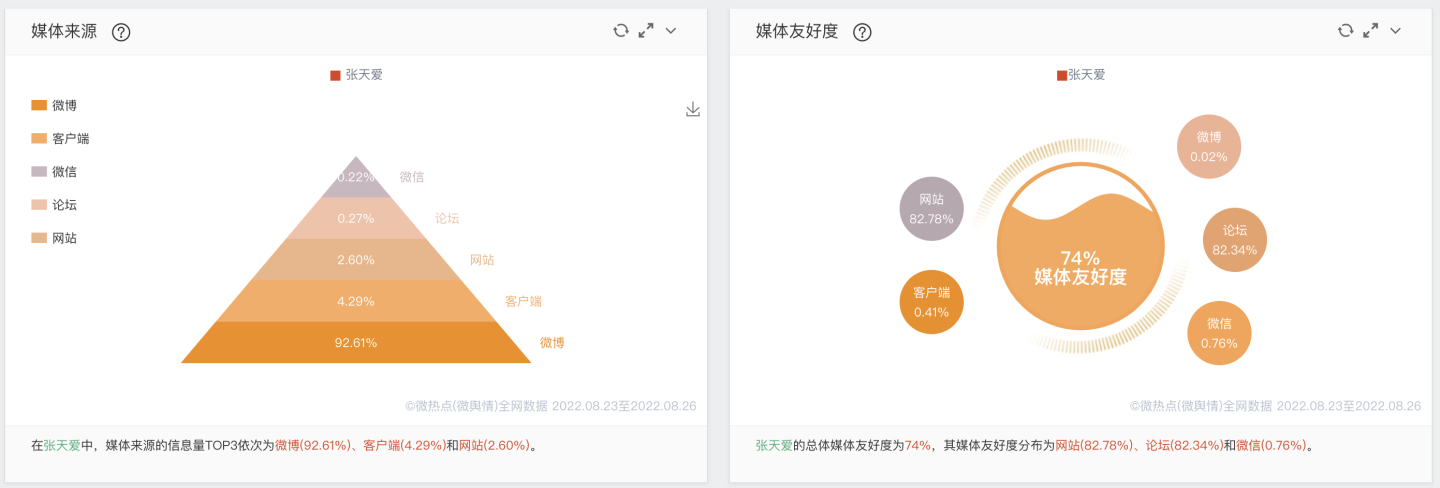
"张天爱"关键词分析: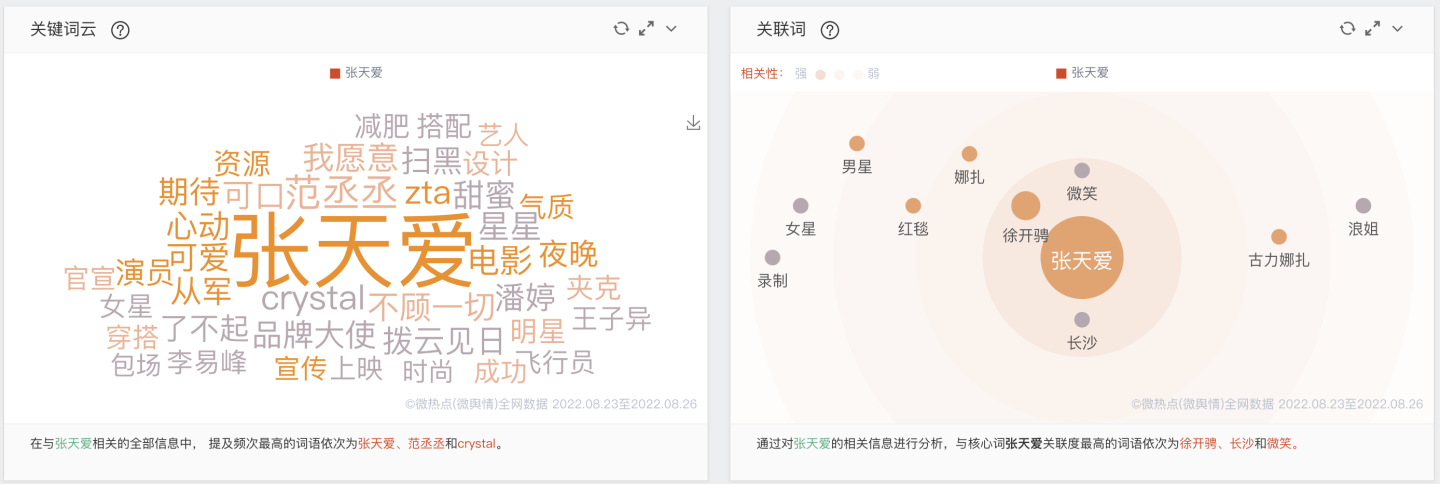
"张天爱"地域分析: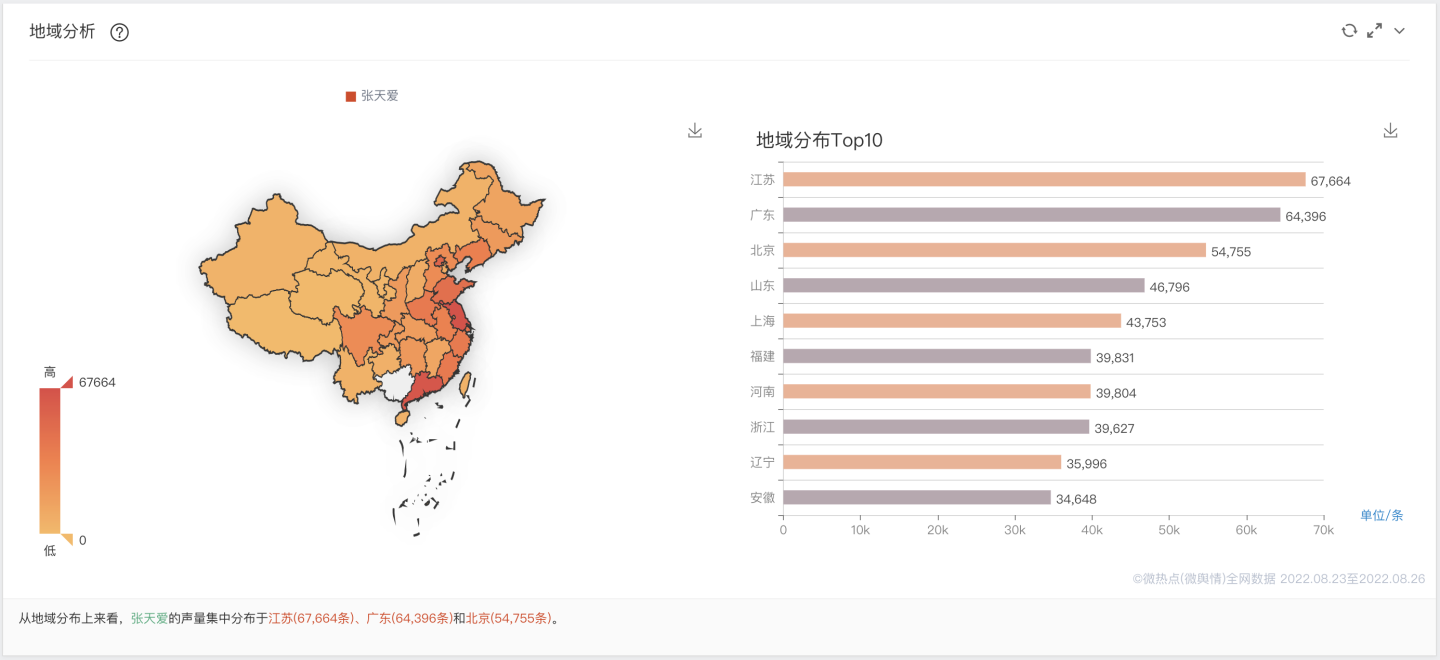
二、自开发Python舆情分析
2.1 Python爬虫
从博文URL地址中找出id。
目标链接地址的id参数值就是id:
原文查看
把id带入到我的Python爬虫代码中,下面展示部分爬虫代码。
关键逻辑,就是max_id的处理:
if page == 1: # 第一页,没有max_id参数
url = 'https://m.weibo.cn/comments/hotflow?id={}&mid={}&max_id_type=0'.format(weibo_id, weibo_id)
else: # 非第一页,需要max_id参数
if max_id == '0': # 如果发现max_id为0,说明没有下一页了,break结束循环
print('max_id is 0, break now')
break
url = 'https://m.weibo.cn/comments/hotflow?id={}&mid={}&max_id_type=0&max_id={}'.format(weibo_id,
weibo_id,
max_id)
如果是第一页,不用传max_id参数。
如果非第一页,需要传max_id参数,它的值来自于上一页的r.json()['data']['max_id']
首先,向页面发送请求:
r = requests.get(url, headers=headers) # 发送请求
print(r.status_code) # 查看响应码
print(r.json()) # 查看响应内容
下面,是解析数据的处理逻辑:
datas = r.json()['data']['data']
for data in datas:
page_list.append(page)
id_list.append(data['id'])
dr = re.compile(r'<[^>]+>', re.S) # 用正则表达式清洗评论数据
text2 = dr.sub('', data['text'])
text_list.append(text2) # 评论内容
time_list.append(trans_time(v_str=data['created_at'])) # 评论时间
like_count_list.append(data['like_count']) # 评论点赞数
source_list.append(data['source']) # 评论者IP归属地
user_name_list.append(data['user']['screen_name']) # 评论者姓名
user_id_list.append(data['user']['id']) # 评论者id
user_gender_list.append(tran_gender(data['user']['gender'])) # 评论者性别
follow_count_list.append(data['user']['follow_count']) # 评论者关注数
followers_count_list.append(data['user']['followers_count']) # 评论者粉丝数
最后,是保存数据的处理逻辑:
df = pd.DataFrame(
{
'id': [weibo_id] * len(time_list),
'评论页码': page_list,
'评论id': id_list,
'评论时间': time_list,
'评论点赞数': like_count_list,
'评论者IP归属地': source_list,
'评论者姓名': user_name_list,
'评论者id': user_id_list,
'评论者性别': user_gender_list,
'评论者关注数': follow_count_list,
'评论者粉丝数': followers_count_list,
'评论内容': text_list,
}
)
if os.path.exists(v_comment_file): # 如果文件存在,不再设置表头
header = False
else: # 否则,设置csv文件表头
header = True
# 保存csv文件
df.to_csv(v_comment_file, mode='a+', index=False, header=header, encoding='utf_8_sig')
print('结果保存成功:{}'.format(v_comment_file))
篇幅有限,请求头、cookie、循环页码、数据清洗等其他细节不再赘述。
看下最终数据: 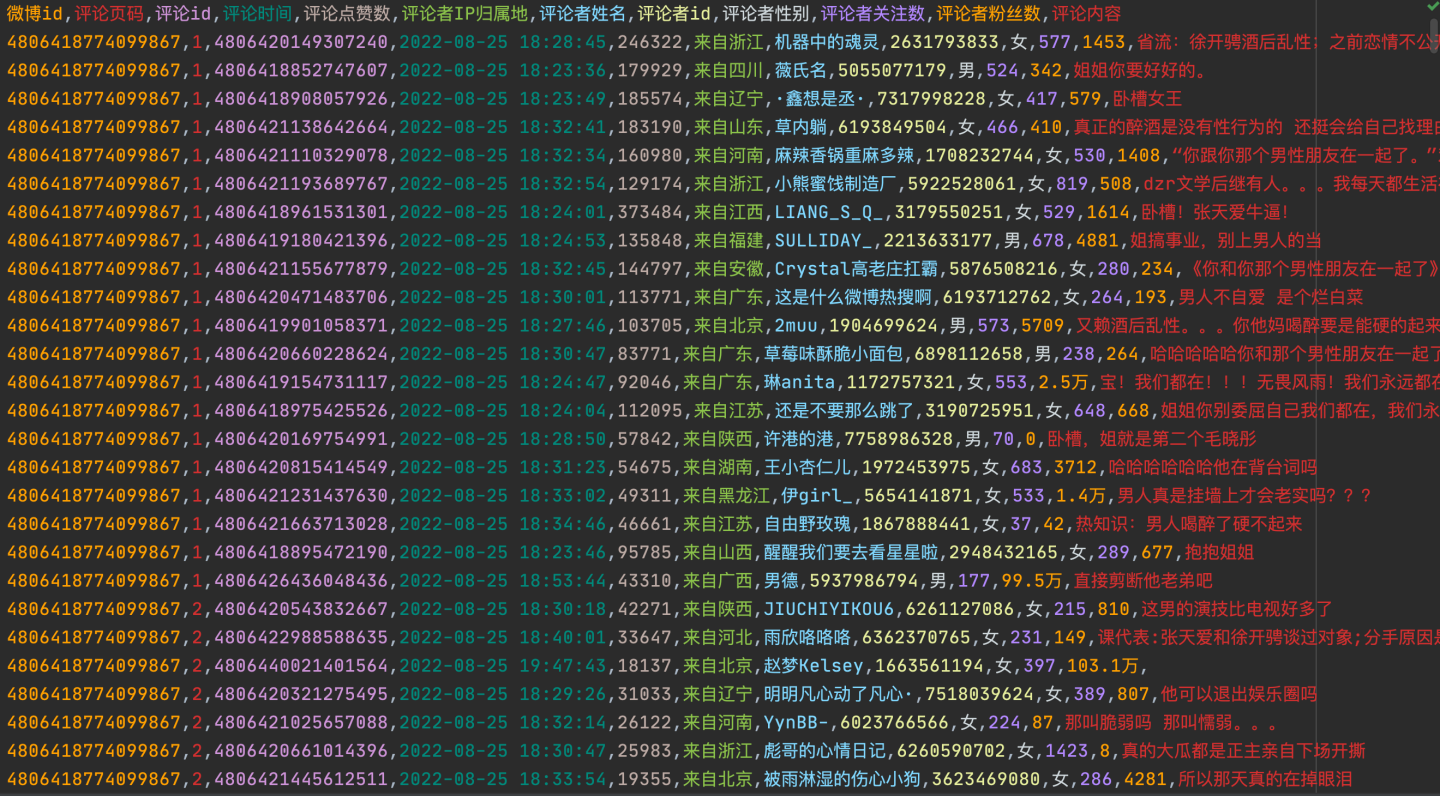
2.2 可视化大屏
首先,看下最终大屏交互效果:
这个大屏,包含了5个图表:
- 大标题-Line
- 词云图-Wordcloud
- 条形图-Bar
- 饼图-Pie
- 地图-Map
下面,依次讲解代码实现。
2.2.1 大标题
由于pyecharts组件没有专门用作标题的图表,我决定灵活运用Line组件实现大标题。
line3 = (
Line(init_opts=opts.InitOpts(width="1000px", # 宽度
height="625px", # 高度
bg_color={"type": "pattern", "image": JsCode("img"),
"repeat": "repeat", })) # 设置背景图片
.add_xaxis([None]) # 插入空数据
.add_yaxis("", [None]) # 插入空数据
.set_global_opts(
title_opts=opts.TitleOpts(title=v_title,
pos_left='center',
title_textstyle_opts=opts.TextStyleOpts(font_size=45,
color='#51c2d5',
align='left'),
pos_top='top'),
yaxis_opts=opts.AxisOpts(is_show=False), # 不显示y轴
xaxis_opts=opts.AxisOpts(is_show=False)) # 不显示x轴
)
# 设置背景图片
line3.add_js_funcs(
"""
var img = new Image(); img.src = '大屏背景.jpg';
"""
)
line3.render('大标题.html')
print('页面渲染完毕:大标题.html')
这里最关键的逻辑,就是背景图片的处理。我找了一个张天爱的图片:
然后用add_js_funcs代码把此图片设置为整个大屏的背景图。
大标题效果:
2.2.2 词云图
首先,把评论数据清洗出来:
cmt_list = df['评论内容'].values.tolist() # 转换成列表
cmt_list = [str(i) for i in cmt_list] # 数据清洗
cmt_str = ' '.join(cmt_list) # 转换成字符串
然后,将清洗后的数据,带入词云图函数,核心代码:
wc = WordCloud(init_opts=opts.InitOpts(width=chart_width, height=chart_height, theme=theme_config, chart_id='wc1'))
wc.add(series_name="词汇",
data_pair=data,
word_gap=1,
word_size_range=[5, 30],
mask_image='张天爱背景图.png',
) # 增加数据
wc.set_global_opts(
title_opts=opts.TitleOpts(pos_left='center',
title="张天爱评论-词云图",
title_textstyle_opts=opts.TextStyleOpts(font_size=20) # 设置标题
),
tooltip_opts=opts.TooltipOpts(is_show=True), # 不显示工具箱
)
wc.render('张天爱词云图.html') # 生成html文件
print('渲染完成:' + '张天爱词云图.html')
看下效果:
2.2.3 条形图
针对评论数据的TOP10高频词,绘制出条形图。
核心代码:
bar = Bar(
init_opts=opts.InitOpts(theme=theme_config, width=chart_width, height=chart_height,
chart_id='bar_cmt')) # 初始化条形图
bar.add_xaxis(x_data) # 增加x轴数据
bar.add_yaxis("数量", y_data) # 增加y轴数据
bar.reversal_axis() # 设置水平方向
bar.set_series_opts(label_opts=opts.LabelOpts(position="right")) # Label出现位置
bar.set_global_opts(
legend_opts=opts.LegendOpts(pos_left='right'),
title_opts=opts.TitleOpts(title=v_title, pos_left='center'), # 标题
toolbox_opts=opts.ToolboxOpts(is_show=False, ), # 不显示工具箱
xaxis_opts=opts.AxisOpts(name="数量", axislabel_opts={"rotate": 0}), # x轴名称
yaxis_opts=opts.AxisOpts(name="关键词",
axislabel_opts=opts.LabelOpts(font_size=9, rotate=0), # y轴名称
))
bar.render(v_title + ".html") # 生成html文件
print('渲染完成:' + v_title + '.html')
看下效果: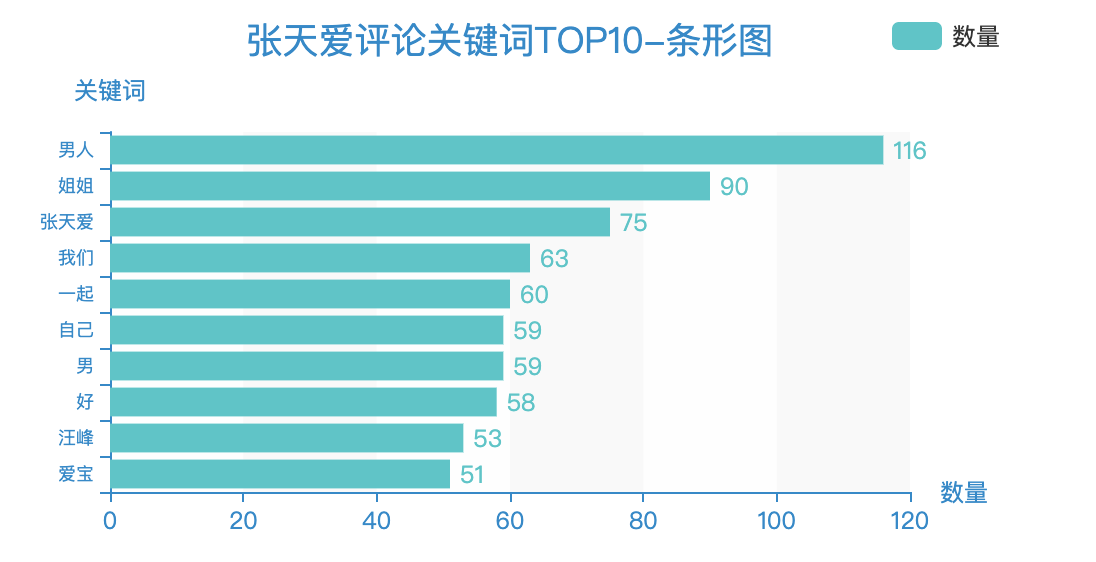
2.2.4 饼图(玫瑰图)
首先,针对评论数据,用snownlp库做情感分析判定。
for comment in v_cmt_list:
tag = ''
sentiments_score = SnowNLP(comment).sentiments
if sentiments_score < 0.4: # 情感分小于0.4判定为消极
tag = '消极'
neg_count += 1
elif 0.4 <= sentiments_score <= 0.6: # 情感分在[0.4,0.6]直接判定为中性
tag = '中性'
mid_count += 1
else: # 情感分大于0.6判定为积极
tag = '积极'
pos_count += 1
score_list.append(sentiments_score) # 得分值
tag_list.append(tag) # 判定结果
df['情感得分'] = score_list
df['分析结果'] = tag_list
然后,将统计数据带入饼图函数,部分核心代码:
# 画饼图
pie = (
Pie(init_opts=opts.InitOpts(theme=theme_config, width=chart_width, height=chart_width, chart_id='pie1'))
.add(series_name="情感分布", # 系列名称
data_pair=[['正能量', pos_count], # 添加数据
['中性', mid_count],
['负能量', neg_count]],
rosetype="radius", # 是否展示成南丁格尔图
radius=["30%", "55%"], # 扇区圆心角展现数据的百分比,半径展现数据的大小
) # 加入数据
.set_global_opts( # 全局设置项
title_opts=opts.TitleOpts(title=v_title, pos_left='center'), # 标题
legend_opts=opts.LegendOpts(pos_left='right', orient='vertical') # 图例设置项,靠右,竖向排列
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))) # 样式设置项
pie.render(v_title + '.html') # 生成html文件
print('渲染完成:' + v_title + '.html')
看下效果: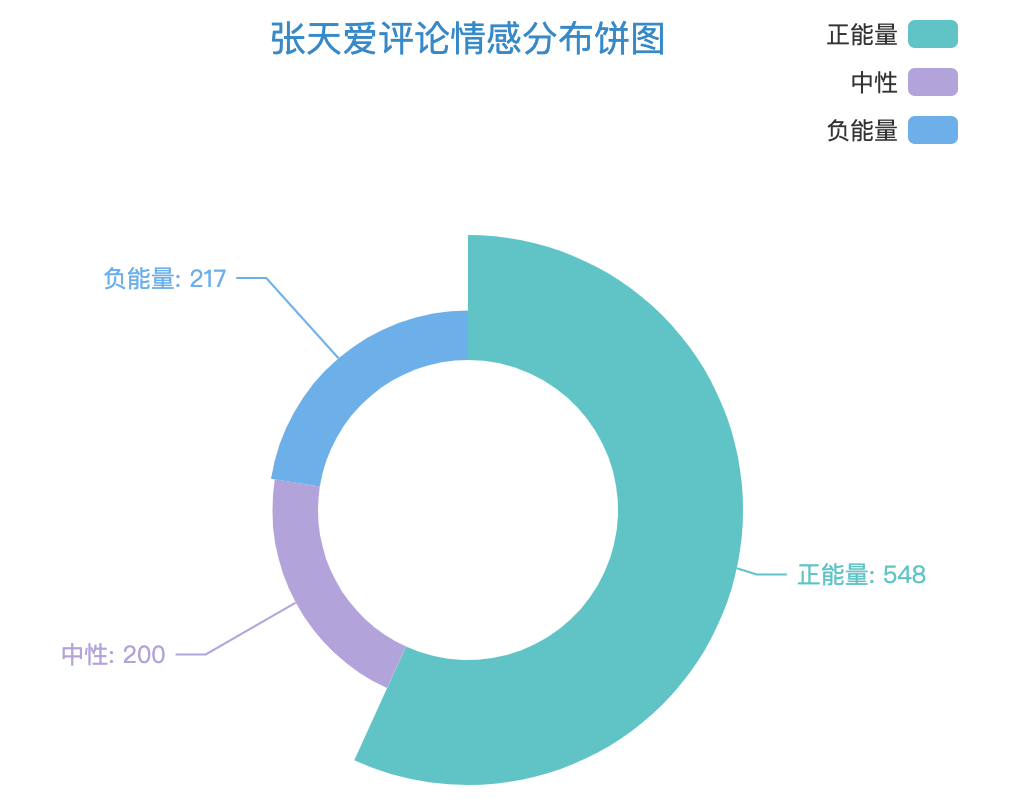
2.2.5 地图
把评论者的IP归属地统计求和,求和后的总数分布在地图上。
df['评论者IP归属地'] = df['评论者IP归属地'].astype(str).str.replace('来自', '') # 数据清洗
loc_grp = df.groupby('评论者IP归属地').count()['评论内容']
data_list = list(zip(loc_grp.index.tolist(), loc_grp.values.tolist()))
数据准备好之后,带入地图函数,部分核心代码:
f_map = (
Map(init_opts=opts.InitOpts(width=chart_width,
height=chart_height,
theme=theme_config,
page_title=v_title,
chart_id='map1',
bg_color=None))
.add(series_name="评论数量",
data_pair=v_data_list,
maptype="china", # 地图类型
is_map_symbol_show=False)
.set_global_opts(
title_opts=opts.TitleOpts(title=v_title,
pos_left="center", ),
legend_opts=opts.LegendOpts( # 设置图例
is_show=True, pos_top="40px", pos_right="30px"),
visualmap_opts=opts.VisualMapOpts( # 设置视觉映射
is_piecewise=True, range_text=['高', '低'], pieces=[ # 分段显示
# {"min": 10000, "color": "#751d0d"},
{"min": 121, "max": 150, "color": "#37561a"},
{"min": 91, "max": 120, "color": "#006400"},
{"min": 61, "max": 90, "color": "#4d9116"},
{"min": 31, "max": 60, "color": "#77bb40"},
{"min": 11, "max": 30, "color": "#b8db9b"},
{"min": 0, "max": 10, "color": "#e5edd6"}
]),
)
.set_series_opts(label_opts=opts.LabelOpts(is_show=True, font_size=8, ),
markpoint_opts=opts.MarkPointOpts(
symbol_size=[90, 90], symbol='circle'),
effect_opts=opts.EffectOpts(is_show='True', )
)
)
f_map.render(v_title + '.html')
print('渲染完成:' + v_title + '.html')
看下效果: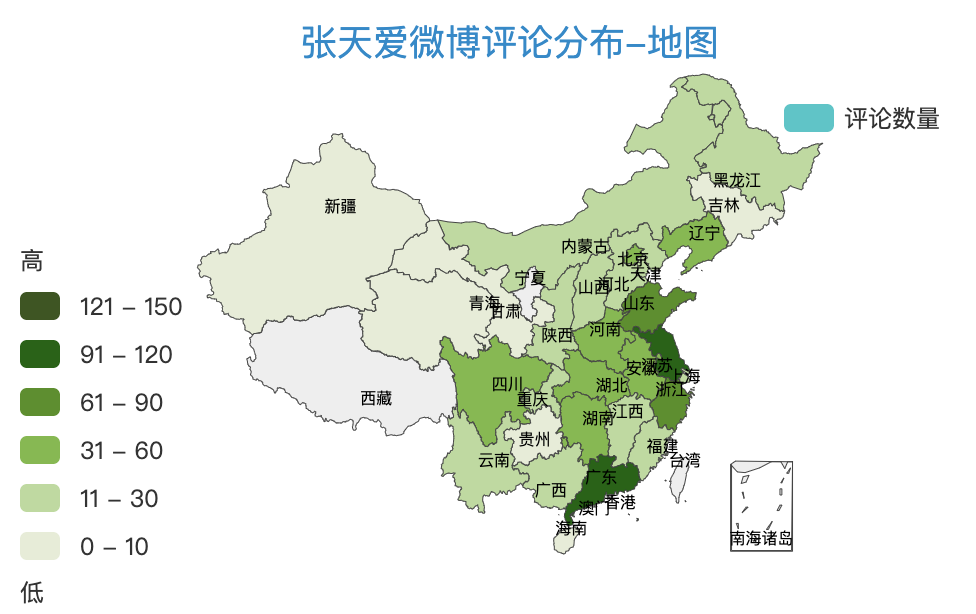
三、演示视频
效果演示:
https://www.zhihu.com/zvideo/1546516025184866304
四、完整源码
附完整源码:点击此处get完整源码!
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:【技术流吃瓜】python可视化大屏舆情分析“张天爱“事件微博评论 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 