我们之前所学的全连接神经网络(DNN)和卷积神经网络(CNN),他们的前一个输入和后一个输入是没有关系的。但是当我们处理序列信息的时候,某些前面的输入和后面的输入是有关系的,比如:当我们在理解一句话意思时,孤立的理解这句话的每个词是不够的,我们需要处理这些词连接起来的整个序列;这个时候我们就需要使用到循环神经网络(Recurrent Neural Network)。
RNN在自然语言处理领域最先被使用起来,RNN可以为语言模型进行建模:
我没有完成上级布置给我的任务,所以 被开除了
让电脑来填写下划线的词最有可能的是『我』,而不太可能是『小明』,甚至是『吃饭』。
语言模型就是这样的东西:给定一个一句话前面的部分,预测接下来最有可能的一个词是什么。
基本循环神经网络
基本循环神经网络结构:一个输入层、一个隐藏层和一个输出层。
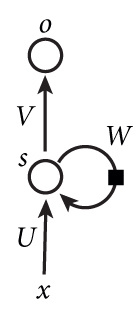
$x$是输入层的值。$s$表示隐藏层的值,$U$是输入层到隐藏层的权重矩阵,$O$是输出层的值。$V$是隐藏层到输出层的权重矩阵。循环神经网络的隐藏层的值s不仅仅取决于当前这次的输入x,还取决于上一次隐藏层的值s。权重矩阵$W$就是隐藏层上一次的值作为这一次的输入的权重。
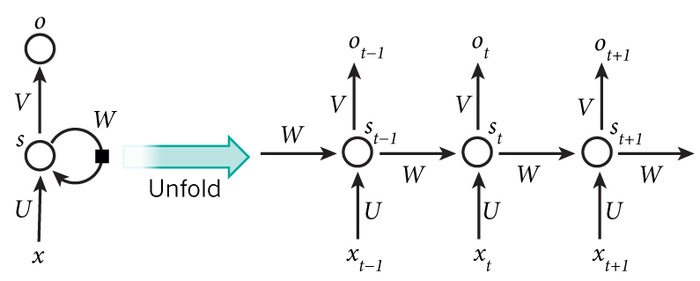
这个网络在t时刻接收到输入$X_t$之后,隐藏层的值是$S_t$,输出值是$O_t$。关键一点是,$S_t$的值不仅仅取决于$X_t$,还取决于$S_{t-1}$。
$$begin{align}
mathrm{o}_t&=g(Vmathrm{s}_t)qquadquad(式1)\
mathrm{s}_t&=f(Umathrm{x}_t+Wmathrm{s}_{t-1})qquad(式2)\
end{align}$$
式1是输出层的计算公式,输出层是一个全连接层,也就是它的每个节点都和隐藏层的每个节点相连。V是输出层的权重矩阵,g是激活函数。
式2是隐藏层的计算公式,它是循环层。U是输入x的权重矩阵,W是上一次的值$S_{t-1}$作为这一次的输入的权重矩阵,f是激活函数。
隐含层有两个输入,第一是$U$与$X_t$向量的乘积,第二是上一隐含层输出的状态$S(t-1)$和$W$的乘积。等于前一次计算输出的$S(t-1)$需要缓存一下,在本次输入$X_t$一起计算,共同输出最后的$O$。
如果反复把式2带入式1,我们将得到:
$$begin{align} mathrm{o}_t&=g(Vmathrm{s}_t)\ &=Vf(Umathrm{x}_t+Wmathrm{s}_{t-1})\ &=Vf(Umathrm{x}_t+Wf(Umathrm{x}_{t-1}+Wmathrm{s}_{t-2}))\ &=Vf(Umathrm{x}_t+Wf(Umathrm{x}_{t-1}+Wf(Umathrm{x}_{t-2}+Wmathrm{s}_{t-3})))\ &=Vf(Umathrm{x}_t+Wf(Umathrm{x}_{t-1}+Wf(Umathrm{x}_{t-2}+Wf(Umathrm{x}_{t-3}+...)))) end{align}$$
从上面可以看出,循环神经网络的输出值$O_t$,是受前面历次输入值$X_t、X_{t-1}、X_{t-2}、X_{t-3}、...$影响的,这就是为什么循环神经网络可以往前看任意多个输入值的原因。这样其实不好,因为如果太前面的值和后面的值已经没有关系了,循环神经网络还考虑前面的值的话,就会影响后面值的判断。
双向循环神经网络
对于语言模型来说,很多时候光看前面的词是不够的,比如下面这句话:
我的手机坏了,我打算 一部新的手机。
我们这个时候就需要双向循环神经网络。
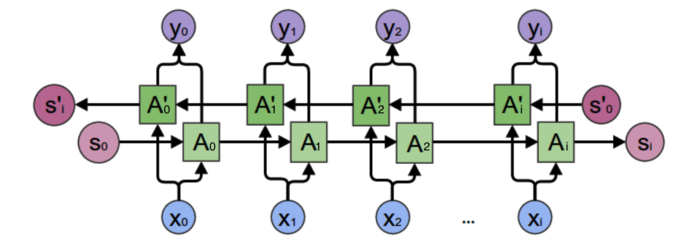
从上图可以看出,双向卷积神经网络的隐藏层要保存两个值,一个A参与正向计算,另一个值A'参与反向计算。最终的输出值$y_2$取决于$A_2$和${A}'_2$。其计算方法为:
$$mathrm{y}_2=g(VA_2+V'A_2')$$
$A_2$和${A}'_2$则分别计算:
$$begin{align}
A_2&=f(WA_1+Umathrm{x}_2)\
A_2'&=f(W'A_3'+U'mathrm{x}_2)\
end{align}$$
现在,我们已经可以看出一般的规律:正向计算时,隐藏层的值$S_t$与$S_{t-1}$有关;反向计算时,隐藏层的值${S}'_t$与${S}'_{t+1}$有关;最终的输出取决于正向和反向计算的加和。现在,我们仿照式1和式2,写出双向循环神经网络的计算方法:
$$begin{align}
mathrm{o}_t&=g(Vmathrm{s}_t+V'mathrm{s}_t')\
mathrm{s}_t&=f(Umathrm{x}_t+Wmathrm{s}_{t-1})\
mathrm{s}_t'&=f(U'mathrm{x}_t+W'mathrm{s}_{t+1}')\
end{align}$$
从上面三个公式我们可以看到,正向计算和反向计算不共享权重,也就是说U和U'、W和W'、V和V'都是不同的权重矩阵。
深度循环神经网络
循环神经网络的训练算法:BPTT
BPTT算法是针对循环层的训练算法,它的基本原理和BP算法是一样的,也包含同样的三个步骤:
1、前向计算每个神经元的输出值;
2、反向计算每个神经元的误差项$delta_j$值,它是误差函数E对神经元j的加权输入$net_j$的偏导数;
3、计算每个权重的梯度。
4、最后用随机梯度下降算法更新权重。
循环层如下图所示:
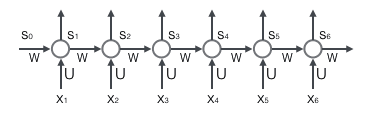
前向计算
使用前面的式2对循环层进行前向计算:
$$mathrm{s}_t=f(Umathrm{x}_t+Wmathrm{s}_{t-1})$$
我们假设输入向量x的维度是m,输出向量s的维度是n,则矩阵U的维度是$n$ x $m$,矩阵W的维度是$n$ x $n$。下面是上式展开矩阵的样子,看起来会直观一些:
$$begin{align}begin{bmatrix}
s_1^t\s_2^t\.\.\s_n^t\
end{bmatrix}=f(begin{bmatrix}
u_{11} u_{12} ... u_{1m}\
u_{21} u_{22} ... u_{2m}\
.\.\u_{n1} u_{n2} ... u_{nm}\
end{bmatrix}begin{bmatrix}
x_1\x_2\.\.\x_m\
end{bmatrix}+begin{bmatrix}
w_{11} w_{12} ... w_{1n}\
w_{21} w_{22} ... w_{2n}\
.\.\w_{n1} w_{n2} ... w_{nn}\
end{bmatrix}begin{bmatrix}
s_1^{t-1}\s_2^{t-1}\.\.\s_n^{t-1}\
end{bmatrix})end{align}$$
误差项的计算
BPTT算法将第I层t时刻的误差项$delta_t^l$值沿两个方向传播,一个方向是其传递到上一层网络,得到$delta_t^{l-1}$,这部分只和权重矩阵U有关;另一个方向是将其沿时间线传递到初始$t_1$时刻,得到$delta_1^l$,这部分只和权重矩阵W有关。
由于推导过程十分复杂,本博客不打算推导。如有兴趣可以查看这篇文章零基础入门深度学习(5)-循环神经网络。
权重梯度的计算
由于推导过程十分复杂,本博客不打算推导。如有兴趣可以查看这篇文章零基础入门深度学习(5)-循环神经网络。
RNN的梯度爆炸和消失问题
实践中前面介绍的几种RNNs并不能很好的处理较长的序列,RNN在训练中很容易发生梯度爆炸和梯度消失,这导致梯度不能在较长序列中一直传递下去,从而使RNN无法捕捉到长距离的影响。
通常来说,梯度爆炸更容易处理一些。因为梯度爆炸的时候,我们的程序会收到NaN错误。我们也可以设置一个梯度阈值,当梯度超过这个阈值的时候可以直接截取。
梯度消失更难检测,而且也更难处理一些。总的来说,我们有三种方法应对梯度消失问题:
1、合理的初始化权重值。初始化权重,使每个神经元尽可能不要取极大或极小值,以躲开梯度消失的区域。
2、使用relu代替sigmoid和tanh作为激活函数。原理请参考上一篇文章零基础入门深度学习(4) - 卷积神经网络的激活函数一节。
3、使用其他结构的RNNs,比如长短时记忆网络(LTSM)和Gated Recurrent Unit(GRU),这是最流行的做法。我们将在以后的文章中介绍这两种网络。
RNN的应用举例——基于RNN的语言模型
我们来介绍一下RNN语言模型,我们首先把词依次输入到循环神经网络中,每输入一个词,循环神经网络就输出截止到目前为止下一个最可能的词。例如,当我们依次输入:
我 昨天 上学 迟到 了
神经网络的输出如下图所示:
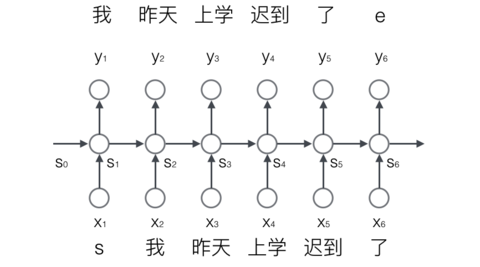
其中,s和e是两个特殊的词,分别表示一个序列的开始和结束。
向量化
为了让语言模型能够被神经网络处理,我们必须把词表达为向量形式,这样神经网络才能处理。所以我们需要把“词”进行向量化。
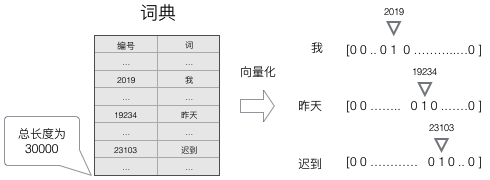
1、建立一个包含所有词的词典,每个词在词典里面有一个唯一的编码。
2、任意一个词都可以用一个N维的one-hot向量来表示(其中N是词典中词的总个数)。假设一个词在词典中的编号是i,v是表示这个词的向量,$V_j$是向量的第j个元素,则:
$$v_j=begin{equation}begin{cases}1qquad j=i\0qquad jne iend{cases}end{equation}$$
上面这个公式的含义,可以用下面的图来直观的表示:
但是处理这种向量会导致我们的神经网络有很多参数,带来庞大的计算量。因此往往需要使用一些降维方法。
语言模型要求输出的是下一个最可能的词,我们可以让循环神经网络计算词典中每个词是下一个词的概率,概率最大的词就是下一个最后的词。输出向量是一个N维向量,向量中的每个元素对应着词典中相应的词是下一个词的概率。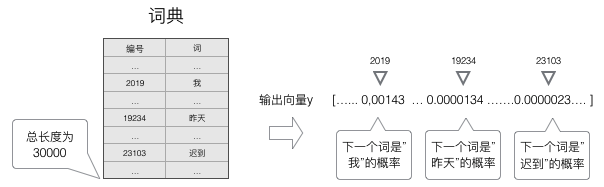
Softmax层
语言模型时对下一个词出现的概率进行建模,让神经网络输出概率的方法就是用Softmax层作为神经网络的输出层。Softmax作为激活函数:1、每一项为取值为0-1之间的正数;2、所有项的总和是1。
$$g(z_i)=frac{e^{z_i}}{sum_{k}e^{z_k}}$$
语言模型的训练
首先我们把语料“我 昨天 上学 迟到 了”转换成语言模型的训练数据集。我们获取输入-标签对:
|
输入 |
标签 |
|---|---|
|
S |
我 |
|
我 |
昨天 |
|
昨天 |
上学 |
|
上学 |
迟到 |
|
迟到 |
了 |
|
了 |
e |
对输入x和标签y进行向量化得到one-hot向量。向量中只有一个元素的值是1,其他元素都是0。
最后我们使用交叉熵误差函数作为优化目标,对模型进行优化。
交叉熵误差
当激活函数是softmax时,对应的误差函数E通常选择交叉熵误差函数,其定义如下:
$$L(y,o)=-frac{1}{N}sum_{nin{N}}{y_nlogo_n}$$
在上式子中,N是训练样本的个数,向量$y_n$是样本的标记,向量$O_n$是网络的输出。标记$y_n$是一个one-hot向量,例如:$y_1=[1,0,0,0]$,如果网络的输出$O=[0.03,0.09,0.24,0.64]$,那么交叉熵是(假设只有一个训练样本,即N=1):
$$begin{align}
L&=-frac{1}{N}sum_{nin{N}}{y_nlogo_n}\
&=-y_1logo_1\
&=-(1*log0.03+0*log0.09+0*log0.24+0*log0.64)\
&=3.51
end{align}$$
RNN的实现
由于用TensorFlow和Keras实现RNN模型篇幅过长,我分成了两篇文章去写:
TensorFlow中实现RNN,彻底弄懂time_step
Keras实现RNN模型
参考文献
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:循环神经网络(RNN)原理 RNN项目 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫