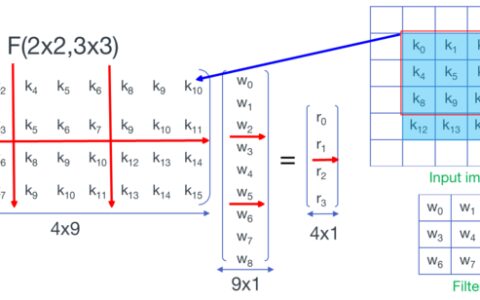
使用multi_gpu_model即可。观察了一下GPU的利用率,非常的低,大部分时候都是0,估计在相互等待,同步更新模型;
当然了,使用多GPU最明显的好处是可以使用更大的batch size
import tensorflow as tf
from keras.applications import Xception
from keras.utils import multi_gpu_model
import numpy as np
num_samples = 1000
height = 224
width = 224
num_classes = 1000
# Instantiate the base model
# (here, we do it on CPU, which is optional).
with tf.device('/cpu:0'):
model = Xception(weights=None,
input_shape=(height, width, 3),
classes=num_classes)
# Replicates the model on 8 GPUs.
# This assumes that your machine has 8 available GPUs.
parallel_model = multi_gpu_model(model, gpus=8)
parallel_model.compile(loss='categorical_crossentropy',
optimizer='rmsprop')
# Generate dummy data.
x = np.random.random((num_samples, height, width, 3))
y = np.random.random((num_samples, num_classes))
# This `fit` call will be distributed on 8 GPUs.
# Since the batch size is 256, each GPU will process 32 samples.
parallel_model.fit(x, y, epochs=20, batch_size=256)
https://www.jianshu.com/p/d57595dac5a9
https://keras.io/utils/#multi_gpu_model
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:keras多gpu训练 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫