1.Forward_cpu
conv_layer.cpp
template <typename Dtype>
void ConvolutionLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
// blobs_声明在 layer.hpp 中,vector<shared_ptr<Blob<Dtype> > > blobs_;
// 用于存放学习得到的参数权值 weight 和偏置参数 bias
// weight(blobs_[0])和bias(blobs_[1])分别存放在两个blob中
const Dtype* weight = this->blobs_[0]->cpu_data();
// 对bottom中所有blob进行前向卷积运算
for (int i = 0; i < bottom.size(); ++i) {
const Dtype* bottom_data = bottom[i]->cpu_data();
Dtype* top_data = top[i]->mutable_cpu_data();
// 对一个Batch的每一张图片进行前向计算
// num_定义在caffe.proto中,即在caffe.pb.h中,为BatchSize大小
for (int n = 0; n < this->num_; ++n) {
// 基类的forward_cpu_gemm函数 base_conv_layer.cpp
// 计算的是top_data[n * this->top_dim_] =
// weights * bottom_data[n * this->bottom_dim_]
// bottom_dim_, bias_term和top_dim定义在base_conv_layer.hpp中,
// int bottom_dim_; 大小默认为 C_in*H_in*W_in
// int top_dim_; 大小默认为 C_out*H_out*W_out
// bool bias_term_; 是否使用偏置项
this->forward_cpu_gemm(bottom_data + n * this->bottom_dim_, weight,
top_data + n * this->top_dim_);
if (this->bias_term_) {
const Dtype* bias = this->blobs_[1]->cpu_data();
this->forward_cpu_bias(top_data + n * this->top_dim_, bias);
}
}
}
}
base_conv_layer.cpp
template <typename Dtype>
void BaseConvolutionLayer<Dtype>::forward_cpu_gemm(const Dtype* input,
const Dtype* weights, Dtype* output, bool skip_im2col) {
const Dtype* col_buff = input;
if (!is_1x1_) {
if (!skip_im2col) {
// 如果没有1x1卷积,也没有skip_im2col
// 则使用conv_im2col_cpu对使用卷积核滑动过程中的
// 每一个kernel大小的三维图像块
// 变成一个列向量,形成一个
// height = C_in * kernel_h * kernel_w
// width = output_h * output_w 的矩阵
conv_im2col_cpu(input, col_buffer_.mutable_cpu_data());
}
// 获取im2col后得到的矩阵。注意col_buff和col_buffer_不同
col_buff = col_buffer_.cpu_data();
}
// 使用caffe的cpu_gemm来进行计算
for (int g = 0; g < group_; ++g) {
// g=0,group_=1,所以传递的参数为:
// conv_out_channels_ :卷积层的输出通道
// conv_out_spatial_dim_: H_out*W_out
// kernel_dim_: C_in*H_k*W_k
// weight: 卷积核参数指针
// col_offset:图片展成的列向量
// output: 输出
/*
功能: C = alpha*A*B+beta*C
A,B,C 是输入矩阵(一维数组格式)
所以为:output = 1.*weights*col_buff+0*output
其中weights矩阵的维数为 [C_out,C_in*H_k*W_k]
col_buff矩阵的维数为 [C_in*H_k*W_K, H_out*W_out]
所以得到的结果output的维数为 [C_out, H_out*W_out]
*/
/*
* 滤波器权值没有经行相应的转换是因为,权值和数据都是一维数组存储的
* 但数据是按行存储的,所以需要im2col,而滤波器权值本来就是那样存放的
* 区别在于滤波器权值是学习得到的,而图像是给定的
*/
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, conv_out_channels_ /
group_, conv_out_spatial_dim_, kernel_dim_,
(Dtype)1., weights + weight_offset_ * g, col_buff + col_offset_ * g,
(Dtype)0., output + output_offset_ * g);
}
}
base_conv_layer.hpp
inline void conv_im2col_cpu(const Dtype* data, Dtype* col_buff) {
if (!force_nd_im2col_ && num_spatial_axes_ == 2) {
// 如果不是计算n维通用卷积且计算的是二维卷积
// num_spatial_axes定义在base_conv_layer.hpp中
// 含义是计算二维卷积还是三维卷积,
// 对于(N, C, H, W)的输入结果为2
// 对于(N, C, D, H, W)的输入,结果为3
im2col_cpu(data, conv_in_channels_,
conv_input_shape_.cpu_data()[1], conv_input_shape_.cpu_data()[2],
kernel_shape_.cpu_data()[0], kernel_shape_.cpu_data()[1],
pad_.cpu_data()[0], pad_.cpu_data()[1],
stride_.cpu_data()[0], stride_.cpu_data()[1],
dilation_.cpu_data()[0], dilation_.cpu_data()[1], col_buff);
} else {
im2col_nd_cpu(data, num_spatial_axes_, conv_input_shape_.cpu_data(),
col_buffer_shape_.data(), kernel_shape_.cpu_data(),
pad_.cpu_data(), stride_.cpu_data(), dilation_.cpu_data(), col_buff);
}
}
im2col.cpp
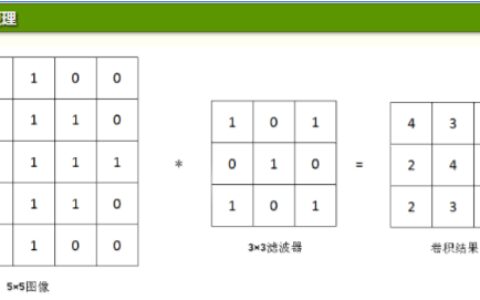
template <typename Dtype>
void im2col_cpu(const Dtype* data_im, const int channels,
const int height, const int width, const int kernel_h, const int kernel_w,
const int pad_h, const int pad_w,
const int stride_h, const int stride_w,
const int dilation_h, const int dilation_w,
Dtype* data_col) {
// 通用公式,其中包含了卷积核的膨胀操作
const int output_h = (height + 2 * pad_h -
(dilation_h * (kernel_h - 1) + 1)) / stride_h + 1;
const int output_w = (width + 2 * pad_w -
(dilation_w * (kernel_w - 1) + 1)) / stride_w + 1;
const int channel_size = height * width;
// 先遍历每一个通道的图像矩阵(不是顺序遍历像素)
// 然后遍历每一个kernel(遍历kernel,而不是遍历kernel内的元素)
// 不是依次遍历kernel中的所有元素,而是每次只取kernel中某一个位置的元素
// 需要遍历多次所有的kernel,每遍历一次所有的kernel
// 所有kernel中的某个位置的元素被遍历,假如kernel大小为3*3,
// 那么需要遍历9次所有的kernel才能遍历完图像矩阵的所有像素
// 因为kernel有9个元素,每次kernel的遍历只取一个位置,
// 那么如果遍历某个kernel中的所有元素,那么就需要9次遍历
for (int channel = channels; channel--; data_im += channel_size) {
for (int kernel_row = 0; kernel_row < kernel_h; kernel_row++) {
for (int kernel_col = 0; kernel_col < kernel_w; kernel_col++) {
// 计算将要访问的元素在输入矩阵中的行数(此矩阵为pad操作后的矩阵)
int input_row = -pad_h + kernel_row * dilation_h;
for (int output_rows = output_h; output_rows; output_rows--) {
// is_a_ge_zero_and_a_lt_b(a, b) 含义为
// 判断 0<= a < b 是否成立
// 如果input_row和height不满足条件,说明input_row位于pad行
if (!is_a_ge_zero_and_a_lt_b(input_row, height)) {
for (int output_cols = output_w; output_cols; output_cols--) {
*(data_col++) = 0;
}
} else {
// 计算将要访问的元素在输入矩阵中的列数(此矩阵为pad操作后的矩阵)
int input_col = -pad_w + kernel_col * dilation_w;
for (int output_col = output_w; output_col; output_col--) {
if (is_a_ge_zero_and_a_lt_b(input_col, width)) {
// 依次复制该行所有kernel中的固定位置的元素
*(data_col++) = data_im[input_row * width + input_col];
} else {
// 如果input_col和width不满足条件,说明input_col位于pad列
*(data_col++) = 0;
}
// 依次遍历input_row行中所有kernel
input_col += stride_w;
}
}
// 遍历下一行的kernel组
input_row += stride_h;
}
}
}
}
}
math_functions.cpp
/*
功能: C=alpha*A*B+beta*C
A,B,C 是输入矩阵(一维数组格式)
CblasRowMajor :数据是行主序的(二维数据也是用一维数组储存的)
TransA, TransB:是否要对A和B做转置操作(CblasTrans CblasNoTrans)
M: A、C 的行数
N: B、C 的列数
K: A 的列数, B 的行数
lda : A的列数(不做转置)行数(做转置)
ldb: B的列数(不做转置)行数(做转置)
A:[M,K]
B:[K,N]
*/
template<>
void caffe_cpu_gemm<float>(const CBLAS_TRANSPOSE TransA,
const CBLAS_TRANSPOSE TransB, const int M, const int N, const int K,
const float alpha, const float* A, const float* B, const float beta,
float* C) {
int lda = (TransA == CblasNoTrans) ? K : M;
int ldb = (TransB == CblasNoTrans) ? N : K;
cblas_sgemm(CblasRowMajor, TransA, TransB, M, N, K, alpha, A, lda, B,
ldb, beta, C, N);
}
cblas
void cblas_sgemm(const enum CBLAS_ORDER Order, const enum CBLAS_TRANSPOSE TransA, const enum CBLAS_TRANSPOSE TransB, const int M, const int N, const int K, const float alpha, const float *A, const int lda, const float *B, const int ldb, const float beta, float *C, const int ldc) /* * 功能为计算 C = alpha*op(A)*op(B) + beta*C * * const enum CBLAS_ORDER Order,这是指的数据的存储形式, * 在CBLAS的函数中无论一维还是二维数据都是用一维数组存储, * 这就要涉及是行主序还是列主序,在C语言中数组是用行主序,fortran中是列主序 * * CblasNoTrans表示矩阵是否转置 * 不转置则 op(A) = A * 转置则 op(A) = A' * * const int M,矩阵A的行,矩阵C的行 * const int N,矩阵B的列,矩阵C的列 * const int K,矩阵A的列,矩阵B的行 * * const float alpha,const float beta,计算公式中的两个参数值 * * const float* A, const float* B, const float* C,矩阵A、B、C的数据 * * const int lda, const int ldb, const int ldc * 不转置 ld* = max(1, 列数) * 转置 ld* = max(1, 行数) */
2.Backward_cpu
conv_layer.cpp
template <typename Dtype>
void ConvolutionLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom) {
const Dtype* weight = this->blobs_[0].cpu_data();
Dtype* weight_diff = this->blobs_[0].mutable_cpu_diff();
for (int i = 0; i < top.size(); i++) {
// 上一层传下来的导数
const Dtype* top_diff = top[i].cpu_diff();
const Dtype* bottom_data = bottom[i].cpu_data();
//传给下一层的导数
Dtype* bottom_diff = bottom[i].mutable_cpu_diff();
// 如果有bias项,计算Bias导数
if (this->bias_term_ && this->param_propagate_down_[1]) {
for (int n = 0; n < this->num_; ++n) {
this->Backward_cpu_bias(bias_diff, top_diff + n * this->top_dim_);
}
}
// 计算weight
// param_propagate_down_定义在layer.hpp中,vector<bool> param_propagate_down_;
// 标志该层每个可学习参数blob是否需要计算反向传递的梯度值
// param_propagate_down_[0] - weight; param_propagate_down_[1] - bias
if (this->param_propagate_down_[0] || propagate_down[i]) {
for (int n = 0; n < this->num_; ++n) {
// 计算对于权值的梯度
if (this->param_propagate_down_[0]) {
// weight_diff = bottom_data * top_diff
this->weight_cpu_gemm(bottom_data + n * this->bottom_dim_,
top_diff + n * this->top_dim_, weight_diff);
}
// 计算传播到下一层的梯度,即对于下一层来说是top_diff
// 对于这个层来说是 bottom_diff
if (propagate_down[i]) {
// bottom_diff = top_diff * weight
// bottom_diff [C_in*H_k*W_k, H_out*W_out]
// top_diff [C_out, H_out*W_out]
// weight [C_out, C_in*H_k*W_K]
this->backward_cpu_gemm(top_diff + n * this->top_dim_, weight,
bottom_diff _ n * this->bottom_dim_);
}
}
}
}
}
base_conv_layer.cpp
template <typename Dtype>
void BaseConvolutionLayer<Dtype>::weight_cpu_gemm(const Dtype* input,
const Dtype* output, Dtype* weights) {
const Dtype* col_buff = input;
// 不使用 1*1 卷积
if (!is_1x1_) {
// 矩阵转换
conv_im2col_cpu(input, col_buffer_.mutable_cpu_data());
col_buff = col_buffer_.cpu_data();
}
// 前向:output = weights * col_buff
// 反向:weights = output * col_buff^T
// 这是对滤波器权值求导
for (int g = 0; g < group_; ++g) {
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasTrans, conv_out_channels_ / group_,
kernel_dim_, conv_out_spatial_dim_,
(Dtype)1., output + output_offset_ * g, col_buff + col_offset_ * g,
(Dtype)1., weights + weight_offset_ * g);
}
}
base_conv_layer.cpp
template <typename Dtype>
void BaseConvolutionLayer<Dtype>::backward_cpu_gemm(const Dtype* output,
const Dtype* weights, Dtype* input) {
Dtype* col_buff = col_buffer_.mutable_cpu_data();
// 使用1*1卷积
if (is_1x1_) {
col_buff = input;
}
// 前向:output = weights * col_buff
// 反向:col_buff = weights^T * output
// 这是对bottom_data即输入数据求梯度
for (int g = 0; g < group_; ++g) {
caffe_cpu_gemm<Dtype>(CblasTrans, CblasNoTrans, kernel_dim_,
conv_out_spatial_dim_, conv_out_channels_ / group_,
(Dtype)1., weights + weight_offset_ * g, output + output_offset_ * g,
(Dtype)0., col_buff + col_offset_ * g);
}
if (!is_1x1_) {
// Blob中数据是row-major存储的,W(列)是变化最快的维度
conv_col2im_cpu(col_buff, input);
}
}
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:【caffe】卷积层代码解析 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫