卷积神经网络组成:
input--CONV--ReLU--pooling--FC
输入层--卷积层--激活函数--池化层--全连接层
在这里需要指出的是:--卷积层--激活函数--池化层--全连接层,它的组合不唯一,也可以看一下关于卷积神经网络的概括:


由于它们的组合可以作出相应的改变,所以使得卷积神经网络有很多不同的表达,尤其是在深度上的提高。
卷积层
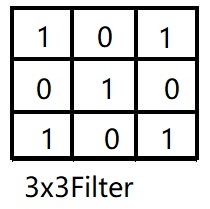
卷积层一般是由3x3或5x5,甚至是11x11的卷积核与传入数据进行卷积得到的,下图是3x3Filter与绿色的图像做卷积的过程,粉红色的图是卷积之后的结果。
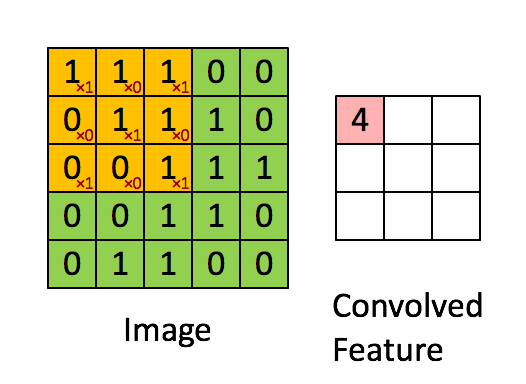
局部感受野:上图中的3x3卷积核,先与图像中的左上角的3x3局部感受野做点积并将所有的结果进行加和才得到粉色图像中的第一个数字4,接着每移动一列进行一次内积并作加和,直到所有的局部感受野处理完毕为止。就得到了第一个卷积特征图。在这里面的移动步长S为1。补充一下:卷积核的行列值一般都是奇数。上图的计算过程中不难发现,输入图的矩阵的四个边只利用到了一次,如果想要充分利用边上的特征就需要扩边。在下图中就是对一个RGB图进行了边的扩充,当然RGB是三维的,所以可以利用三个卷积核对每一维进行卷积,然后将所有的卷积结果进行相加,即图中的绿色输出的第一个图的左上角数字5是由,w0三个卷积核分别对不同维度做卷积后的结果的总和。
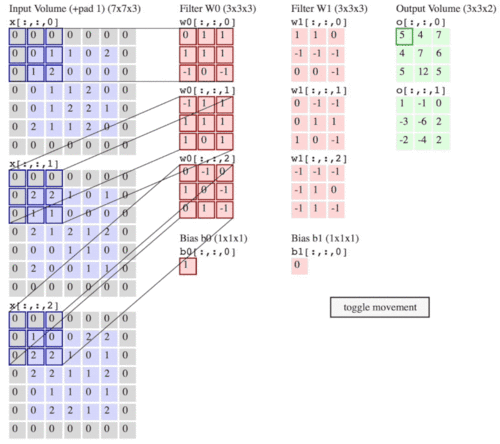
权值共享:在我看来,卷积的过程本身就是权值共享,卷积核的大小决定了权值的数量,卷积核就是权值的组合,所以在卷积过程中每一个总的特征图都只用了同样的卷积核,也就是权值共享。所以为了能更好更充分多角度采集到图像的特征,就对一个图选择多个卷积核做卷积,进行特征提取。
卷积核“矩阵”值:卷积神经网络的参数(权值),卷积核初值随机生成,通过反向传播更新。
卷积核数目:卷积神经网络的“宽度“,常见参数64,128,256,可以使GPU并行更加高效。
与传统神经网络相比(参数/计算量)更多还是更少?答:参数量变少了,计算量变多了。
卷积层输出矩阵的大小:
sizeoutput=[(N+2P−F)/S]+1 其中N为输入图像的行数(通常行列相等),P为扩充边界数量,F为卷积核的行数(通常行列相等),S为卷积滑动步长。
激活函数ReLU (Rectified Linear Units)
为了方便记忆,假设第一次卷积层结束就使用了激活函数,常用的激活函数有sigmoid、tanh、relu等等,前两者sigmoid/tanh比较常见于全连接层,后者ReLU常见于卷积层。
在卷积神经网络中,激活函数一般使用ReLU(The Rectified Linear Unit,修正线性单元),它的特点是收敛快,求梯度简单。计算公式也很简单,max(0,T),即对于输入的负值,输出全为0,对于正值,则原样输出。如下图的从左至右使用激活函数的过程。

池化层
池化层一般是将激活之后的输出特征图进行将采用,可以是均值采样,可以是最大值采样,也可以是中值采样,池化的操作也很简单,通常情况下,池化区域是2*2大小,然后按一定规则转换成相应的值,例如取这个池化区域内的最大值(max-pooling)、平均值(mean-pooling)等,以这个值作为结果的像素值。
下图显示了左上角2*2池化区域的max-pooling结果,取该区域的最大值作为池化后的结果,接着移动两列取2*2池化区域的max-pooling结果,直到第一行结束,接着下移两行从左至右进行上一步的操作,直到将图中的所有数据采集完,如下图:

最大池化(max-pooling)保留了每一小块内的最大值,也就是相当于保留了这一块最佳的匹配结果(因为值越接近1表示匹配越好)。也就是说,它不会具体关注窗口内到底是哪一个地方匹配了,而只关注是不是有某个地方匹配上了。
通过加入池化层,图像缩小了,能很大程度上减少计算量,降低机器负载。
全连接层
全连接层在整个卷积神经网络中起到“分类器”的作用,即通过卷积、激活函数、池化等深度网络后,再经过全连接层对结果进行识别分类。
卷积神经网络的反向传播
以下内容均转自https://blog.csdn.net/weixin_40446651/article/details/81516944
已知池化层的δl推导上一层的δl-1,这个过程一般称为upsample
假设池化的size为2*2,δl:

由于池化size为2*2,首先将size还原:

假设是最大池化,并且之前记录的最大值的位置为左上,右下,右上,左下。那么δl-1:

解释下为什么要这么做,在正向传播的时候,池化之前的四个最大值位置左上,右下,右上,左下,都以比例为1的系数传递到下一层。而其他位置对输出的贡献都为0,也就是说对池化输出没有影响,因此比例系数可以理解为0。所以在正向传播的过程中,最大值所在位置可以理解为通过函数f(x)=x传递到下一层,而其他位置则通过f(x)=0传递到下一层,并且把这些值相加构成下一层的输出,虽然f(x)=0并没有作用,但这样也就不难理解反向传播时,把δl的各个值移到最大值所在位置,而其他位置为0了。因为由f(x)=x,最大值位置的偏导数为1,而f(x)=0的偏导数为0。
如果平均池化,那么δl-1:

平均池化的话,池化操作的四个位置传递到下一层的作用可以等价为f(x)=x/4,所以在方向传播过程中就相当于把δl每一个位置的值乘1/4再还原回去。
所以由δl推导δl-1可以总结为:
![]()
![]()
等式右边第一项表示上采样,第二项是激活函数的导数,在池化中可以理解为常数1(因为池化过程的正向传播过程中没有激活函数)。
已知卷积层的δl推导上一层的δl-1:
![]()
![]()
首先由链式法则:
![]()
![]()
rot180(wl)代表对卷积核进行翻转180°的操作,σ\'(zl-1)为激活函数的导数。这里比较难理解的是为什么要对卷积核进行180°的翻转。
假设我们(l-1)层的输出(al-1)是一个3x3矩阵,第l层的卷积核W是一个2x2矩阵,采用1像素的步幅,则输出zl是一个2x2的矩阵。这里暂时不考虑偏置项b的影响。
那么可得:
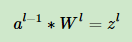
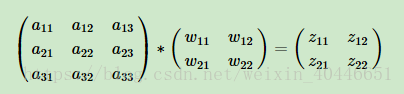
展开:

求al的梯度:

又由展开式:
a11只与z11有关,并且系数为w11,所以:
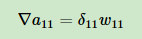
a12只与z11和z12有关,并且系数分别为w11,w12,所以:

同理:
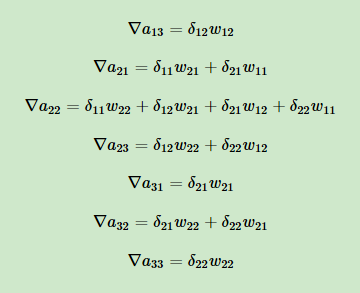
使用矩阵形式表示就是:

这就解释了为什么在反向传播时需要将卷积核进行180°的翻转操作了。
已知卷积层的δl推导w,b的梯度:
全连接层中的w,b的梯度与DNN中的推导一致,池化层没有w,b参数,所以不用进行w,b梯度的推导。
对于卷积层正向传播过程:

所以参数w的梯度:

注意到这里并没有翻转180°的操作:
因为由之前的展开式:
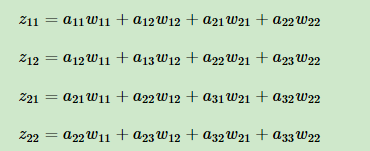

所以w的梯度:

这也就是没有进行翻转的原因。
b的梯度:
这里假设w=0,那么z=b,梯度δl是三维张量,而b只是一个向量,不能像普通网络中那样直接和δl相等。通常的做法是将误差δ的各个子矩阵的项分别求和,得到一个误差向量所以这里b的梯度就是δl的各个通道对应位置求和:

得到的是一个误差向量。
总结一下CNN的反向传播过程:
1 池化层的反向传播:
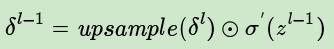
2 卷积层的反向传播
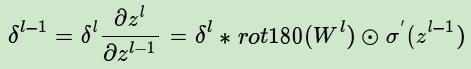
3 参数更新


卷积神经网络需要哪些额外功能?
非线性激励:卷积是线性运算,增加非线性描述能力--ReLU
降维:特征图稀疏,减少数据运算量,保持精度--池化层
归一化:特征的scale保持一致
批量归一化层Batch Normalization(BN)
近邻归一化(Local Response Normalization)
![]()
![]()
BN依据mini batch的数据,近邻归一仅需要自身
BN训练中有学习参数
区域分割:不同区域进行独立学习
在某些应用中,希望独立对某些区域单独学习
好处:学习多套参数更强的特征,描述能力
区域融合:对分开的区域合并,方便信息融合
对独立进行特征学习的分支进行融合,构建高效而精简的特征组合
曾维:增加图片生成或探测任务中空间信息
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:深度学习-卷积神经网络笔记 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 