参考博客:
http://blog.csdn.net/haoji007/article/details/77148374
http://blog.csdn.net/jacke121/article/details/78160398
voc数据集下载地址:
https://pjreddie.com/projects/pascal-voc-dataset-mirror/
我习惯于将所有训练、预测有关的.py .prototxt .caffemodel文件放在一起
将score.py surgery.py voc_layers.py拷贝到voc-fcn32s这个文件夹中。
修改solve.py:
import caffe
import surgery, score
import numpy as np
import os
import sys
try:
import setproctitle
setproctitle.setproctitle(os.path.basename(os.getcwd()))
except:
pass
weights = \'train_iter_100000.caffemodel\' #caffe的预训练模型
deploy_proto = \'deploy_voc_32s.prototxt\' #deploy文件
# init
caffe.set_device(int(0))
caffe.set_mode_gpu()
solver = caffe.SGDSolver(\'solver.prototxt\')
#solver.net.copy_from(weights)
vgg_net=caffe.Net(deploy_proto,weights,caffe.TRAIN)
surgery.transplant(solver.net,vgg_net)
del vgg_net
# surgeries
interp_layers = [k for k in solver.net.params.keys() if \'up\' in k]
surgery.interp(solver.net, interp_layers)
# scoring
#加载训练过程中的测试文件
val = np.loadtxt(\'../data/voc2012/VOCtrainval_11-May-2012/ImageSets/Segmentation/val.txt\', dtype=str)
for _ in range(50):
solver.step(2000)
score.seg_tests(solver, False, val, layer=\'score\')
# N.B. metrics on the semantic labels are off b.c. of missing classes;
# score manually from the histogram instead for proper evaluation
#score.seg_tests(solver, False, test, layer=\'score_sem\', gt=\'sem\')
#score.seg_tests(solver, False, test, layer=\'score_geo\', gt=\'geo\')
在../data/voc2012/VOCtrainval_11-May-2012/ImageSets/Segmentation有train.txt val.txt trainval.txt三个文件,num(trainval)=num(train)+num(val)。
预训练的模型可以去官网下载。
编辑solver.prototxt文件:
train_net: "train.prototxt"
test_net: "val.prototxt"
test_iter: 736
# make test net, but don\'t invoke it from the solver itself
test_interval: 999999999
display: 20
average_loss: 20
lr_policy: "fixed"
# lr for unnormalized softmax
base_lr: 1e-10
# high momentum
momentum: 0.99
# no gradient accumulation
iter_size: 1
max_iter: 100000
weight_decay: 0.0005
snapshot: 20000
snapshot_prefix: "./train"
test_initialization: false
生成deploy.prototxt文件
data层不变,保留
网络层照常理不变
去掉loss层
修改train.prototxt和val.prototxt文件
layer {
name: "data"
type: "Python"
top: "data"
top: "label"
python_param {
module: "voc_layers"
layer: "VOCSegDataLayer"
param_str: "{\\'voc_dir\\': \\'../data/voc2012/VOCtrainval_11-May-2012\\', \\'seed\\': 1337, \\'split\\': \\'val\\', \\'mean\\': (104.00699, 116.66877, 122.67892)}"
}
}
module指的是该文件夹下名为voc_layers.py的python文件,layer是该python文件名称为VOCSegDataLayer的类,该python文件中有两个类,另一个类不管。设置voc_dir为对应的路径。Train.prototxt和val.prototxt文件中作相同的修改。
其中的seed=1337,我也不知道是什么意思。这个mean的参数和siftflow中的值倒是一样的。
修改voc_layers.py:
该文件中主要是修改VOCSegDataLayer类中的一些路径和名称,下面的那个SBDDSegDataLayer不管。
设置voc2012数据集的路径
self.voc_dir = params[\'voc_dir\']
加载txt文件
split_f = \'{}/ImageSets/Segmentation/{}.txt\'.format(self.voc_dir,self.split)
加载图片
im = Image.open(\'{}/JPEGImages/{}.jpg\'.format(self.voc_dir, idx))
加载标签图片
im = Image.open(\'{}/SegmentationClass/{}.png\'.format(self.voc_dir, idx))
voc数据集中的图片尺寸不固定,图片的长宽也不相等。
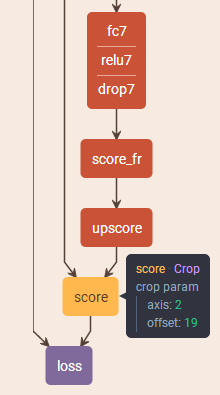

如上图的网络结构可以看到,经过上采样之后,得到一个比原图大的图像,然后做crop操作,生成和原图像一样的尺寸,这就实现了不管输入的图片尺寸是多少,经过全卷积神经网络的结果图片和原图的尺寸都是相同的。

本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:fcn+caffe+voc2012实验记录 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 