1,GAN的发展历史
总结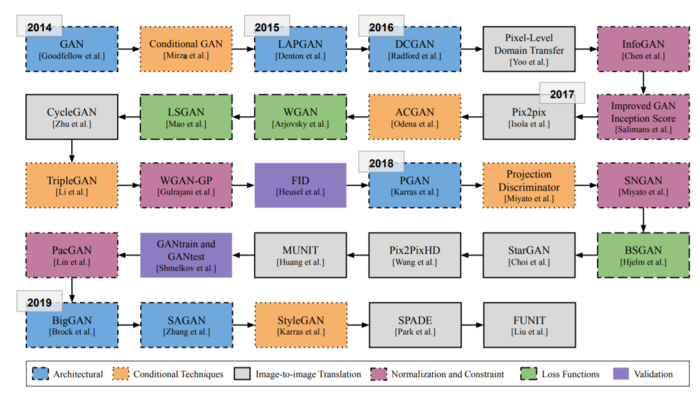

The Six Fronts of the Generative Adversarial Networks
GAN最早是由Ian J. Goodfellow等人于2014年10月提出的,他的《Generative Adversarial Nets》可以说是这个领域的开山之作,论文一经发表,就引起了热议。而随着GAN在理论与模型上的高速发展,它在计算机视觉、自然语言处理、人机交互等领域有着越来越深入的应用,并不断向着其它领域继续延伸。
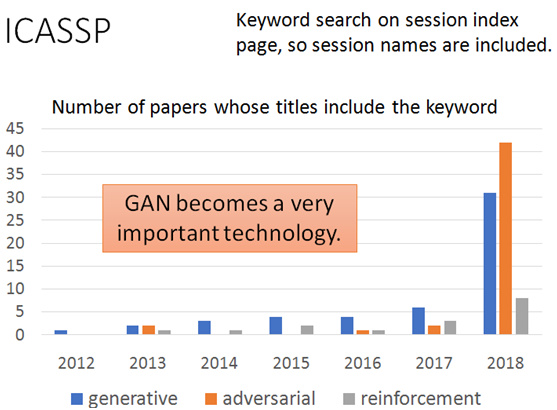
图自李宏毅老师的GAN课程
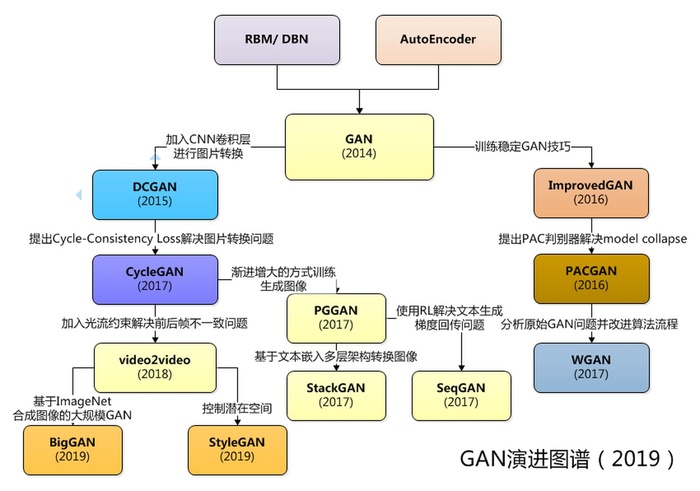
下面将按照时间顺序,简单介绍GAN的演进历史中的代表性网络
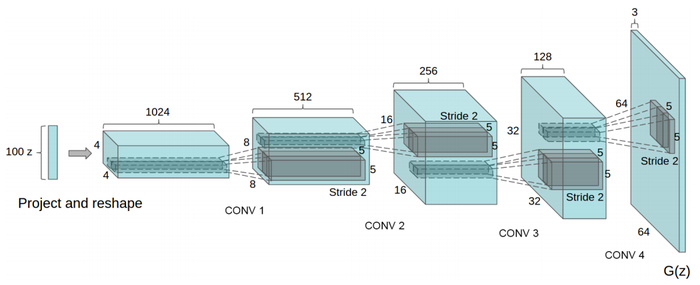
DCGAN
顾名思义,DCGAN[3]主要讨论 CNN 与 GAN 如何结合使用并给出了一系列建议。由于卷积神经网络(Convolutional neural network, CNN)比MLP有更强的拟合与表达能力,并在判别式模型中取得了很大的成果。因此,Alec等人将CNN引入生成器和判别器,称作深度卷积对抗神经网络(Deep Convolutional GAN, DCGAN)。另外还讨论了 GAN 特征的可视化、潜在空间插值等问题。
DCGAN生成的动漫头像:

ImprovedGAN
Ian Goodfellow 等人[4]提供了诸多训练稳定 GAN 的建议,包括特征匹配、mini-batch 识别、历史平均、单边标签平滑以及虚拟批标准化等技巧。讨论了 GAN 不稳定性的最佳假设。
PACGAN
PACGAN[5]讨论的是的如何分析 model collapse,以及提出了 PAC 判别器的方法用于解决 model collapse。思想其实就是将判别器的输入改成多个样本,这样判别器可以同时看到多个样本可以从一定程度上防止 model collapse。
WGAN
WGAN[6]首先从理论上分析了原始 GAN 模型存在的训练不稳定、生成器和判别器的 loss 无法只是训练进程、生成样本缺乏多样性等问题,并通过改进算法流程针对性的给出了改进要点。
CycleGAN
CycleGAN[7]讨论的是 image2image 的转换问题,提出了 Cycle consistency loss 来处理缺乏成对训练样本来做 image2image 的转换问题。Cycle Consistency Loss 背后的主要想法,图片 A 转化得到图片 B,再从图片 B 转换得到图片 A’,那么图片 A 和图片 A’应该是图一张图片。
Vid2Vid
Vid2Vid[8]通过在生成器中加入光流约束,判别器中加入光流信息以及对前景和背景分别建模重点解决了视频转换过程中前后帧图像的不一致性问题。
PGGAN
PGGAN[9]创造性地提出了以一种渐进增大(Progressive growing)的方式训练 GAN,利用逐渐增大的 PGGAN 网络实现了效果令人惊叹的生成图像。“Progressive Growing” 指的是先训练 4x4 的网络,然后训练 8x8,不断增大,最终达到 1024x1024。这既加快了训练速度,又大大稳定了训练速度,并且生成的图像质量非常高。
StackGAN
StackGAN[10]是由文本生成图像,StackGAN 模型与 PGGAN 工作的原理很像,StackGAN 首先输出分辨率为 64×64 的图像,然后将其作为先验信息生成一个 256×256 分辨率的图像。
BigGAN
BigGAN[11]模型是基于 ImageNet 生成图像质量最高的模型之一。该模型很难在本地机器上实现,而且 有许多组件,如 Self-Attention、 Spectral Normalization 和带有投影鉴别器的 cGAN 等。
StyleGAN
StyleGAN[12]应该是截至目前最复杂的 GAN 模型,该模型借鉴了一种称为自适应实例标准化 (AdaIN) 的机制来控制潜在空间向量 z。虽然很难自己实现一个 StyleGAN,但是它提供了很多有趣的想法。
参考文献
[1] Must-Read Papers on GANs/ 必读!生成对抗网络GAN论文TOP 10
[2] Generative Adversarial Networks
[3] Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
[4] Improved Techniques for Training GANs
[5] PacGAN: The power of two samples in generative adversarial networks
[6] Wasserstein GAN
[7] Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
[8] Video-to-Video Synthesis
[9] 深度推荐系统
2,相关模型资料
以下是课程中所涉及到的所有模型简介、代码链接及论文。
*注意:实际代码请参考Config文件进行配置。
Wasserstein GAN
简介:本文从理论上分析了原始 GAN 模型存在的训练不稳定、生成器和判别器的 loss 无法只是训练进程、生成样本缺乏多样性等问题,并通过改进算法流程针对性的给出了改进要点。
代码链接:https://github.com/PaddlePaddle/PaddleGAN/blob/develop/configs/wgan_mnist.yaml
DCGAN
论文:UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS
简介:由于卷积神经网络(Convolutional neural network, CNN)比MLP有更强的拟合与表达能力,并在判别式模型中取得了很大的成果。因此,本文将CNN引入生成器和判别器,称作深度卷积对抗神经网络(Deep Convolutional GAN, DCGAN)。
代码链接:https://github.com/PaddlePaddle/PaddleGAN/blob/develop/configs/dcgan_mnist.yaml
Least Squares GAN
论文:Least Squares Generative Adversarial Networks
简介:本文主要将交叉熵损失函数换做了最小二乘损失函数,改善了传统 GAN 生成的图片质量不高,且训练过程十分不稳定的问题。
Progressive Growing of GAN
论文:PROGRESSIVE GROWING OF GANS FOR IMPROVED QUALITY, STABILITY, AND VARIATION
简介:本文提出了一种用来训练生成对抗网络的新方法:渐进式地增加生成器和判别器的规模,同时,提出了一种提高生成图像多样性的方法以及给出一种新的关于图像生成质量和多样性的评价指标。
StyleGAN
论文:A Style-Based Generator Architecture for Generative Adversarial Networks
简介:本文是NVIDIA继ProGAN之后提出的新的生成网络,其主要通过分别修改每一层级的输入,在不影响其他层级的情况下,来控制该层级所表示的视觉特征。 这些特征可以是粗的特征(如姿势、脸型等),也可以是一些细节特征(如瞳色、发色等)。
StyleGAN2
论文:Analyzing and Improving the Image Quality of StyleGAN
简介:本文主要解决StyleGAN生成图像伪影的同时还能得到细节更好的高质量图像。新的改进方案也不会带来更高的计算成本。不管是在现有的分布质量指标上,还是在人所感知的图像质量上,新提出的模型都实现了无条件图像建模任务上新的 SOTA。
代码链接:https://github.com/PaddlePaddle/PaddleGAN/blob/develop/configs/stylegan_v2_256_ffhq.yaml
Conditional GAN
论文:Conditional Generative Adversarial Nets
简介:本文提出在利用 GAN(对抗网络)的方法时,在生成模型G和判别模型D中都加入条件信息来引导模型的训练,并将这种方法应用于跨模态问题,例如图像自动标注等。
代码链接:https://github.com/PaddlePaddle/PaddleGAN/blob/develop/configs/cond_dcgan_mnist.yaml
CycleGAN
论文:Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
简介:CycleGAN本质上是两个镜像对称的GAN,构成了一个环形网络。 两个GAN共享两个生成器,并各自带一个判别器,即共有两个判别器和两个生成器。 一个单向GAN两个loss,两个即共四个loss。 可以实现无配对的两个图片集的训练是CycleGAN与Pixel2Pixel相比的一个典型优点。
代码链接:https://github.com/PaddlePaddle/PaddleGAN/blob/develop/configs/cyclegan_horse2zebra.yaml
Pix2Pix
论文:Image-to-Image Translation with Conditional Adversarial Networks
简介:本文在GAN的基础上提供一个通用方法,完成成对的图像转换。
代码链接:https://github.com/PaddlePaddle/PaddleGAN/blob/develop/configs/pix2pix_cityscapes_2gpus.yaml
U-GAT-IT
简介:本文主要研究无监督的image-to-image translation。在风格转换中引入了注意力模块,并且提出了一种新的可学习的normalization方法。注意力模块根据辅助分类器获得的attention map,使得模型聚能更好地区分源域和目标域的重要区域。同时,AdaLIN(自适应层实例归一化)帮助注意力指导模型根据所学习的数据集灵活地控制形状和纹理的变化量。
代码链接:https://github.com/PaddlePaddle/PaddleGAN/blob/develop/configs/ugatit_selfie2anime_light.yaml
Super Resolution GAN
论文:Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
简介:本文主要讲解如何利用卷积神经网络实现单影像的超分辨率,其瓶颈仍在于如何恢复图像的细微纹理信息。
Enhanced Super Resolution GAN
论文:ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks
简介:本文在SRGAN的基础上进行了改进,包括改进网络的结构,判决器的判决形式,以及更换了一个用于计算感知域损失的预训练网络。
代码链接:https://github.com/PaddlePaddle/PaddleGAN/blob/develop/configs/esrgan_x4_div2k.yaml
Residual Channel Attention Networks(RCAN)
论文:Image Super-Resolution Using Very Deep Residual Channel Attention Networks
简介:本文提出了一个深度残差通道注意力网络(RCAN)解决过深的网络难以训练、网络的表示能力较弱的问题。
EDVR
论文:EDVR: Video Restoration with Enhanced Deformable Convolutional Networks
简介:本文主要介绍基于可形变卷积的视频恢复、去模糊、超分的网络。
代码链接:https://github.com/PaddlePaddle/PaddleGAN/blob/develop/configs/edvr.yaml
First Order Motion
论文:First Order Motion Model for Image Animation
简介:本文介绍的是image animation,给定一张源图片,给定一个驱动视频,生成一段视频,其中主角是源图片,动作是驱动视频中的动作。如下图所示,源图像通常包含一个主体,驱动视频包含一系列动作。
Wav2lip
论文:A Lip Sync Expert Is All You Need for Speech to Lip Generation In The Wild
简介:本文主要介绍如何将任意说话的面部视频与任意语音进行唇形同步。
代码链接:https://github.com/PaddlePaddle/PaddleGAN/blob/develop/configs/wav2lip.yaml
参考资料
[3] 宋代诗人‘开口’念诗、蒙娜丽莎‘唱’rap-PaddleGAN唇形合成的应用
[6] 老北京城影像修复-PaddleGAN上色、超分、插帧的应用
[7] 一键生成多人版‘脸部动作迁移
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:GAN0-生成对抗网络-GAN的分类 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 