Python爬虫(学习笔记)
常见的反爬机制及应对策略
|
名称 |
描述 |
解决方案/反反爬措施 |
|
1.Headers
|
从用户的headers进行反爬是最常见的反爬策略,Headers是一种最常见的反爬机制Headers是一种区分浏览器行为和机器行为中最简单的方法,还有一些网站会对Referer (上级链接)进行检测 从而实现爬虫。 |
相应的解决措施:通过审查元素或者开发者工具获取相应的headers 然后把相应的headers 传输给python 的requests,这样就能很好地绕过。 |
|
2.IP 限制
|
一些网站会根据你的IP 地址访问的频率,次数进行反爬。也就是说如果你用单一的IP 地址访问频率过高,那么服务器会在短时间内禁止这个IP 访问。 |
解决措施:构造自己的IP 代理池,然后每次访问时随机选择代理(但一些IP 地址不是非常稳定,需要经常检查更新)。 |
|
3. UA 限制
|
UA 是用户访问网站时候的浏览器标识,其反爬机制与ip 限制类似。 |
解决措施:构造自己的UA 池,每次python 做requests 访问时随机挂上UA 标识,更好地模拟浏览器行为。当然如果反爬对时间还有限制的话,可以在requests 设置timeout(最好是随机休眠,这样会更安全稳定,time.sleep())。
|
|
4.验证码反爬虫或者模拟登陆
|
验证码:这个办法也是相当古老并且相当的有效果,如果一个爬虫要解释一个验证码中的内容,这在以前通过简单的图像识别是可以完成的,但是就现在来讲,验证码的干扰线,噪点都很多,甚至还出现了人类都难以认识的验证码 |
解决措施:验证码识别的基本方法:截图,二值化、中值滤波去噪、分割、紧缩重排(让高矮统一)、字库特征匹配识别。(python 的PIL 库或者其他)模拟登陆(例如知乎等):用好python requests 中的session |
|
5.Ajax 动态加载
|
网页的不希望被爬虫拿到的数据使用Ajax 动态加载,这样就为爬虫造成了绝大的麻烦,如果一个爬虫不具备js 引擎,或者具备js 引擎,但是没有处理js 返回的方案,或者是具备了js 引擎,但是没办法让站点显示启用脚本设置。基于这些情况,ajax 动态加载反制爬虫还是相当有效的。 Ajax 动态加载的工作原理是:从网页的url 加载网页的源代码之后,会在浏览器里执行JavaScript程序。这些程序会加载出更多的内容,并把这些内容传输到网页中。
|
解决策略:若使用审查元素分析”请求“对应的链接(方法:右键→审查元素→Network→清空,点
击”加载更多“,出现对应的GET 链接寻找Type 为text/html 的,点击,查看get 参数或者复制Request URL),循环过程。如果“请求”之前有页面,依据上一步的网址进行分析推导第1 页。以此类推,抓取Ajax 地址的数据。对返回的json 使用requests 中的json 进行解析,使用eval()转成字典处理fiddler 可以格式化输出json 数据。
|
|
6.cookie 限制
|
一次打开网页会生成一个随机cookie,如果再次打开网页这个cookie 不存在,那么再次设置,第三次打开仍然不存在,这就非常有可能是爬虫在工作了。 |
解决措施:在headers 挂上相应的cookie 或者根据其方法进行构造(例如从中选取几个字母进行构造)。如果过于复杂,可以考虑使用selenium 模块(可以完全模拟浏览器行为) |
代理IP:一种反反爬机制
|
作用 |
突破封IP的反爬机制 |
|
什么是代理 |
代理服务器 先将请求发送至代理服务器,再由代理服务器发送至目标服务器 |
|
代理的作用 |
突破自身IP的访问限制 隐藏真实IP |
|
代理相关网站 |
快代理 西祠代理 |
|
代理IP的种类 |
http:适用于http协议的URL访问中 https:应用到https协议的URL访问中 |
|
代理IP的匿名度 |
透明:服务器直到该次请求使用了代理,也知道请求对应的真实IP 匿名:知道使用了代理,但是不知道真实的IP 高匿名:不知道使用了代理,也不知道真实IP |
模拟登录session
|
模拟登录 |
爬取基于某些用户的用户信息 |
|
没有请求到数据的原因 |
发起的第二次基于个人主页的页面请求的时候,服务器端并不知道该次请求是基于登录状态下的请求; |
|
http、https协议特性 |
无状态 |
|
cookie |
用来让服务器端记录客户端的相关状态 |
|
手动处理 |
通过抓包工具F12,获取cookie值,将该值手动粘贴到代码中,封装到headers数据中 |
|
自动处理 |
|
|
cookie值来源于哪里? |
模拟登录post请求后,由服务端创建; |
|
session会话的作用 |
1可以进行请求的发送; 2如果请求过程中产生了cookie,则该cookie会被自动存储/携带在该session对象中 |
|
session实例化 |
创建一个session对象,session=requests.Session() 使用session对象进行模拟登录post请求的发送(服务端生成的cookie就会存储在session中); session对象对个人主页对应的get请求进行发送(session携带了cookie) |
|
使用 |
session.post() session.get() |
|
|
|
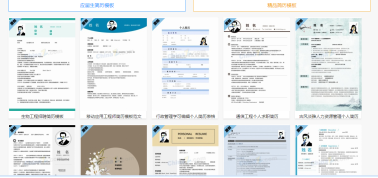

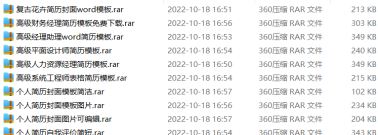
通过xpath下载简历模板
|
import os.path
#导入包 from lxml import etree import requests #定义函数-爬取单个页面 def OnePage( page_number=1): #根据页数生成对应的URL url='' if page_number==1: url = 'https://sc.chinaz.com/jianli/free.html' elif(page_number in range(2,1192)):
url='https://sc.chinaz.com/jianli/free_'+str(page_number)+'.html'
#UA伪装 headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36 SE 2.X MetaSr 1.0'} #请求整页数据 #page_text=requests.get(url=url,headers=headers).text response=requests.get(url=url,headers=headers) #处理中文乱码问题 response.encoding='utf-8' page_text=response.text #初始化etree对象 tree=etree.HTML(page_text) #解析对象列表 page_list=tree.xpath('//div[@class="sc_warp mt20"]/div/div/div/a') #创建文件夹存储下载数据 folder='./jianli/' if not os.path.exists(folder): os.mkdir(folder) #遍历对象列表 for page in page_list: #解析文件名 name=page.xpath('./img/@alt')[0] #解决中文乱码问题 #name=name.encode('iso-8859-1').decode('gbk') #解析下载页的URL href=page.xpath('./@href')[0] #print(name,href) #处理URL if href[0] == "/": href = 'https:' + href #获取下载页源码 page_text2=requests.get(url=href,headers=headers).text #构造etree对象 tree2=etree.HTML(page_text2) #解析下载地址 href2=tree2.xpath('//div[@class="down_wrap"]/div[2]/ul/li[1]/a/@href')[0] #处理URL if href2[0]=="/": href2='https:'+href2 #print(name,href2) #添加后缀名 name=name+'.rar' #创建文件路径 path=folder+name #读取文件数据 data=requests.get(url=href2,headers=headers).content #数据持久化 with open(path,'wb') as fp: fp.write(data) print(name,'下载成功!!!')
#对不同的页码循环执行 for i in range(50,879): print(f'开始下载第【{i}】页...') try: OnePage(i) except: continue |
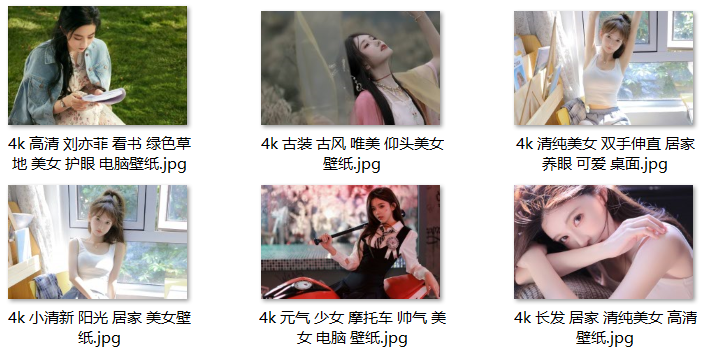
通过xpath解析,获取网页图片
|
import os.path #导入包 import requests from lxml import etree #指定URL url='https://pic.netbian.com/4kmeinv/' #UA伪装 headers= {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36 SE 2.X MetaSr 1.0'} #读取整页文本 page_text=requests.get(url=url,headers=headers).text
#解决中文乱码问题-方法2 #response=requests.get(url=url,headers=headers) #response.encoding='utf-8' #page_text=response.text #初始化etree对象 tree=etree.HTML(page_text) #解析获取所有对象列表 li_list=tree.xpath('//div[@class="slist"]//li') folder='./4kMeinv' if not os.path.exists(folder): os.mkdir(folder) #遍历对象列表 for li in li_list: #从对象解析出图片URL,并补全为完整URL src='https://pic.netbian.com'+li.xpath('./a/img/@src')[0] #读取图片二进制数据 data=requests.get(url=src,headers=headers).content #获取文件名称 name=li.xpath('./a/img/@alt')[0]+'.jpg' #解决中文乱码问题-方法1 name=name.encode('iso-8859-1').decode('gbk') path=folder+'/'+name #数据持久化存储 with open(path,'wb') as fp: fp.write(data) print(name,', 保存成功!!!')
|
导入包
指定URL UA伪装
读取整页文本
etree初始化 xpath解析
xpath二次解析 获取图片URL 下载图片数据(二进制) 获取文件名称
数据持久化 |
HTML常用标签及其全称
|
HTML标签 |
英文全称 |
中文释义 |
|
a |
Anchor |
锚 |
|
abbr |
Abbreviation |
缩写词 |
|
acronym |
Acronym |
取首字母的缩写词 |
|
address |
Address |
地址 |
|
dfn |
Defines a Definition Term |
定义定义条目 |
|
kbd |
Keyboard |
键盘(文本) |
|
samp |
Sample |
示例(文本 |
|
var |
Variable |
变量(文本) |
|
tt |
Teletype |
打印机(文本) |
|
code |
Code |
源代码(文本) |
|
pre |
Preformatted |
预定义格式(文本 ) |
|
blockquote |
Block Quotation |
区块引用语 |
|
cite |
Citation |
引用 |
|
q |
Quotation |
引用语 |
|
strong |
Strong |
加重(文本) |
|
em |
Emphasized |
加重(文本) |
|
b |
Bold |
粗体(文本) |
|
i |
Italic |
斜体(文本) |
|
big |
Big |
变大(文本) |
|
small |
Small |
变小(文本) |
|
sup |
Superscripted |
上标(文本) |
|
sub |
Subscripted |
下标(文本) |
|
bdo |
Direction of Text Display |
文本显示方向 |
|
br |
Break |
换行 |
|
center |
Centered |
居中(文本) |
|
font |
Font |
字体 |
|
u |
Underlined |
下划线(文本) |
|
s/ strike |
Strikethrough |
删除线 |
|
div |
Division |
分隔 |
|
span |
Span |
范围 |
|
ol |
Ordered List |
排序列表 |
|
ul |
Unordered List |
不排序列表 |
|
li |
List Item |
列表项目 |
|
dl |
Definition List |
定义列表 |
|
dt |
Definition Term |
定义术语 |
|
dd |
Definition Description |
定义描述 |
|
del |
Deleted |
删除(的文本) |
|
ins |
Inserted |
插入(的文本) |
|
h1~h6 |
Header 1 to Header 6 |
标题1到标题6 |
|
p |
Paragraph |
段落 |
|
hr |
Horizontal Rule |
水平尺 |
|
href |
hypertext reference |
超文本引用 |
|
alt |
alter |
替用(一般是图片显示不出的提示) |
|
src |
Source |
源文件链接 |
|
cell |
cell |
巢 |
|
cellpadding |
cellpadding |
巢补白 |
|
cellspacing |
cellspacing |
巢空间 |
|
nl |
navigation lists |
导航列表 |
|
tr |
table row |
表格中的一行 |
|
th |
table header cell |
表格中的表头 |
|
td |
table data cell |
表格中的一个单元格 |
|
iframe |
Inline frame |
定义内联框架 |
|
optgroup |
Option group |
定义选项组 |
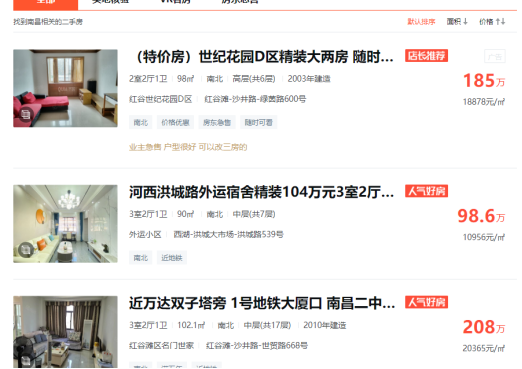
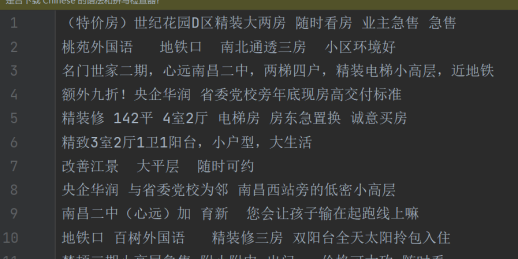
通过etree-xpath获取二手房源标题
|
from lxml import etree import requests #指定URL url='https://nc.58.com/ershoufang/' #UA伪装 headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36 SE 2.X MetaSr 1.0'} #获取整页文本 page_text=requests.get(url=url,headers=headers).text #初始化etree对象 tree=etree.HTML(page_text) #第一次解析,获取对象列表 div_list=tree.xpath('//section[@class="list"]/div') #打开文件 fp=open('./58.txt','w',encoding='utf-8') #遍历对象列表 for div in div_list: #第二次解析,获取二手房源标题 title=div.xpath('./a/div/div/div/h3/text()')[0] #数据持久化,写入本地文件 fp.write(title+'n') #print(title)
|
导入包 指定URL ua伪装 获取页面文本 初始化etree对象 通过xpath表达式 解析获取指定内容 数据持久化存储 |
解析方式总结
|
名称 |
正则表达式 |
BeautifulSoup |
xpath |
|
安装 |
-- |
pip install bs4 pip install lxml |
pip install xpath pip install lxml |
|
导入包 |
import re import requests |
from bs4 import BeautifulSoup import requests |
from lxml import etree import requests |
|
原理 |
获取整页文本 指定re表达式 通过re方法匹配 获取指定内容 持久化数据存储 |
实例化soup对象 将页面文本载入soup对象 soup解析获取指定内容 持久化存储数据 |
1实例化一个etree对象,将需要解析的对象加载到该对象中 2调用etree中的xpaht方法,结合xpath表达式,实现标签定位和内容捕获 |
|
初始化 |
re.findall(ex,text,re.S) |
本地数据初始化 soup=BeautifulSoup(fp,'lxml') 网页文本初始化 soup=BeautifulSoup(page_text,'lxml') |
将本地文档源码加载到etree对象中 etree.parse(filePath) 将互联网的源码数据加载到etree对象中 etree.HTML(page_text) |
|
方法 |
requests.get(url,headers) requests.post(url,param,headers) response.text文本 response.json response.content二进制 |
soup.a/div/p/title/text/string text返回该标签下所有文本内容(各级子标签) string只返回本标签下的文本内容 例子:soup.title.parent.name 例子:soup.div.div.div.a.text soup.find(‘tagName’),soup.find_all() soup.find(‘tagName’,class_=’属性名’) soup.select('.bookcont > ul > span > a') selecet多级访问,返回所有匹配项 .bookcont表示属性名ul表示标签名 find_all()方法没有找到目标是返回空列表,find()方法找不到目标时,返回None 通过CSS的类名查找:soup.select(".sister") 通过tag标签逐层查找:(可跨级) soup.select("body a") 找到某个tag标签下的直接子标签: soup.select("head > title")(不可跨级) soup.a[‘href’] |
xpath(‘xpath表达式’) ./表示当前目录 /(最左侧)表示根目录 /(不在最左侧)表示一个层级,相当于bs4的> //(最左侧)表示多个层级相当于bs4的空格 //(不在最左侧)表示从任意层级开始定位 属性定位://tag[@attrName=’attrVal’] 索引定位:索引下标从1开始而不是从0开始,tag[@attrName=’attrVal’]/p[3] ‘//div[@class=’tang’]//li[5]/a/text()’[0] /text()本层级内容 //text()所有层级内容 /@attrName取属性值 |
|
其他 |
中文文档 |
中文文档 https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html#find |
中文文档 |
通过bs4解析三国
|
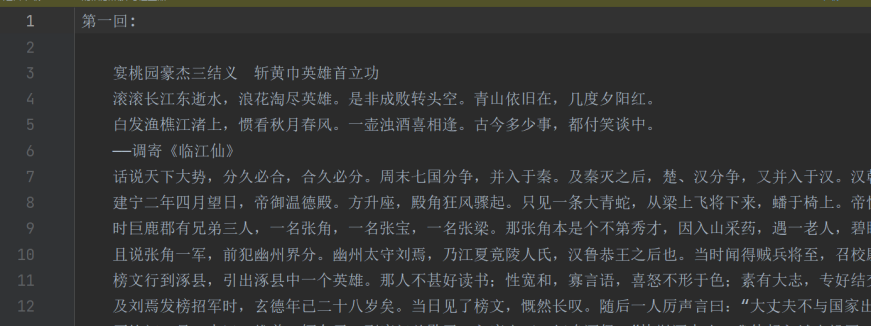
from bs4 import BeautifulSoup import lxml import requests url='https://so.gushiwen.cn/guwen/book_46653FD803893E4F7F702BCF1F7CCE17.aspx' headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36 SE 2.X MetaSr 1.0'} page_text=requests.get(url=url,headers=headers).text soup=BeautifulSoup(page_text,'lxml') #print(soup.div.div.div.a.text)#古诗文网 #print(soup.div.div.string)#None #print(soup.div.div.div.a['href']) chapters=soup.select('.bookcont > ul > span > a') print(chapters) with open('sanguo.txt','w',encoding='utf-8') as fp: for a in chapters: title=a.string link=a['href'] page_content=requests.get(url=link,headers=headers).text soup2=BeautifulSoup(page_content,'lxml') content=soup2.find('div',class_='contson') content_text=content.text fp.write(title+':n'+content_text+'n') print(title ,' 写入成功!!!')
|
导入 指定URL UA伪装
读取起始页
创建soup对象,解析标题和内容URL 读取章节内容
创建soup2,解析章节内容 数据持久化,写入本地TXT文件 |
正则解析--爬取网页中的美女图片
|
import os.path import requests import re #导入包 #UA伪装 headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36 SE 2.X MetaSr 1.0'} #存储图片的文件夹 folder='./meinv/' if not os.path.exists(folder): os.mkdir(folder) #指定URL url='https://m.woyaogexing.com/tupian/z/meinv/' #解析正则表达式 ex='" data-src="(.*?)" />' #src="//img.woyaogexing.com/images/grey.gif" data-src="//img2.woyaogexing.com/2022/07/03/ecb599c9ffa42f2f!400x400.jpg" /> #解析获取图片url列表 text=requests.get(url=url,headers=headers).text image_list=re.findall(ex,text,re.S)
print(image_list) #遍历图片URL for src in image_list: src='https:'+src #生成完整路径 img_data=requests.get(url=src,headers=headers).content #读取图片的二进制数据content name=src.split('/')[-1] #从路径获取图片名称 path=folder+name #写入文件路径 with open(path,'wb') as fp:#打开文件 fp.write(img_data) #写入数据 print(name,'保存成功')#打印日志 |
n 导入包 n UA伪装 n 创建文件夹存储图片
n 指定URL n 读取页面所有内容
n 根据页面格式,编制正则表达式 n 通过正则表达式,解析页面内容获取图片url
n 遍历所有图片url n 读取图片二进制数据
n 图片数据持久化存储 |
聚焦爬虫,爬取页面中指定的页面内容,例如豆瓣中评分>9的电影;
数据解析:从整个页面中获取所需的部分信息;
数据解析分类:
- 正则
- bs4-beautiful Soup
- xpath-通用性强
数据解析原理:
解析的局部的文本内容都会在标签之间或者标签对应的属性中进行存储;
1 进行指定标签的定位
2 标签或者标签对应的属性中存储的数据值进行提取(解析)
爬取肯德基餐厅数据
|
import json#导入包 import requests #指定URL url='http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword' add='南昌'#指定参数 params={ 'cname': '', 'pid': '', 'keyword': add, 'pageIndex': 1, 'pageSize': 10, }#UA伪装 headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36 SE 2.X MetaSr 1.0'} #发起请求 response=requests.post(url=url,headers=headers,params=params) json_obj=response.json()#获取数据 print(json_obj) with open('kfc_'+add+'.json','w') as fp: json.dump(json_obj,fp=fp) #数据持久化保存 print('成功保存') |
requests爬虫流程
1导入包
2 指定url(通过F12调试查看)
3指定参数(通过F12调试查看)
4指定UA(UA伪装)
5发起请求get/post
6获取数据
7数据持久化保存 |
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:Python爬虫(学习笔记) - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 