Redis 是内存数据库,高效使用内存对 Redis 的实现来说非常重要。
看一下,Redis 中针对字符串结构针对内存使用效率做的设计优化。
一、SDS的结构
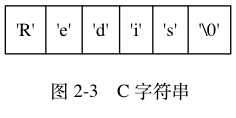
c语言没有string类型,本质是char[]数组;而且c语言数组创建时必须初始化大小,指定类型后就不能改变,并且字符数组的最后一个元素总是空字符 '\0' 。
以下展示了一个值为 "Redis" 的 C 字符串:
Redis没有直接使用C语言的字符串方式,而是构建了一种简单动态字符串(Simple dynamic string, SDS)的类型,Redis中的字符串底层都是使用SDS结构进行存储,比如包含字符串的键值对底层都是使用SDS结构实现的。
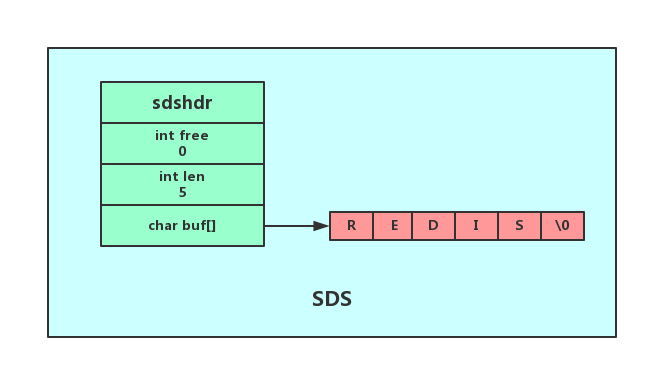
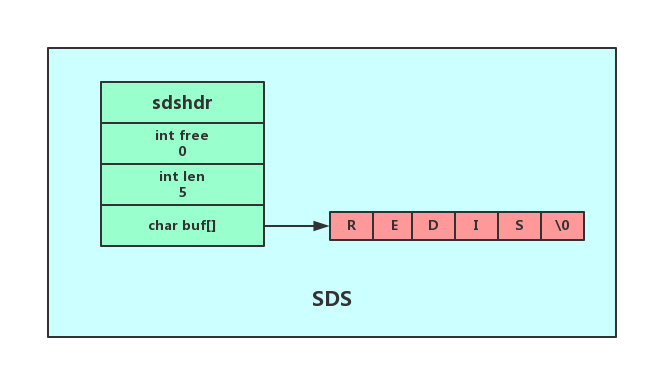
SDS结构定义在sds.h中
struct sdshdr{
int len;//SDS保存的字符串长度
int free;//buf数组中未使用字节数量
char buf[];//字符数组,保存字符串
}
最后一个字节保存了空字符'\0',保留了C字符串的规范,使得SDS结构的字符串,可以重用一部分C函数库的函数。
二、为什么不使用C字符串 主要是因为C字符串有以下缺点:
获取字符串长度时间复杂度为O(N):C字符串获取长度需遍历整个字符串,遇到'\0'空字符为止。 缓冲区溢出:比如在进行字符串追加操作时,如果没有分配足够的内存,就会造成内存溢出。 内存重分配:每次增长或者截短字符串,程序都要对保存C字符串的数组进行内存重分配操作,而内存重分配涉及复杂的算法,并可能需要执行系统调用,所以它通常比较耗时。 空字符问题:C字符串中间不能保存空格,否则程序遍历是会误认为是字符串的末尾。这一限制导致C字符串只能存储文本数据,不能保存像图片、音视频、压缩文件等二进制数据。
三、怎样解决C字符串问题
1、SDS通过len属性记录了SDS长度,所以获取长度的时间复杂度为O(1),即strlen命令的时间复杂度是O(1)。
2、SDS空间分配策略避免了缓冲区溢出:当对SDS进行修改时,会先检查SDS空间是否满足修改,不满足会自动扩展到所需大小,然后才执行修改。
3、较少修改字符串时内存重分配次数:SDS中的free记录buf字节数组中未使用的字节。
redis
空间预分配:当对SDS进行增长操作时,程序不仅会分配修改所必须得空间,还会为SDS分配额外的未使用空间。通过预分配策略,减少了连续执行字符串增长操作时内存重分配次数。 惰性空间释放:当对SDS进行截短操作时,程序并不会立即回收缩短后多出来的字节所占用的内存,而是使用free属性记录多出来的字节数,以供将来使用。如果将来要对这个SDS进行增长操作,未使用空间可能就派上用场,并且增长操作也不一定会执行内存重分配。
SDS结构中的buf字节数组,是二进制安全的,不仅可以保存字符,也可以保存二进制数据。
SDS保留了C字符串的惯例,将数据的末尾设置为空字符'\0',SDS中之所以保留这一规范是可以重用C字符串函数库的一部分函数,例如追加字符串。
四、对字符串的进一步优化 Redis string的三种编码:
int 存储8个字节的长整型(long,2^63-1 ) embstr, embstr格式的SDS (Simple Dynamic String) raw, raw格式的SDS,存储大于44个字节的长字符串
int类型就是指的是数字,那么raw、embstr都代表的是字符串有什么异同吗,下面我们分析下。
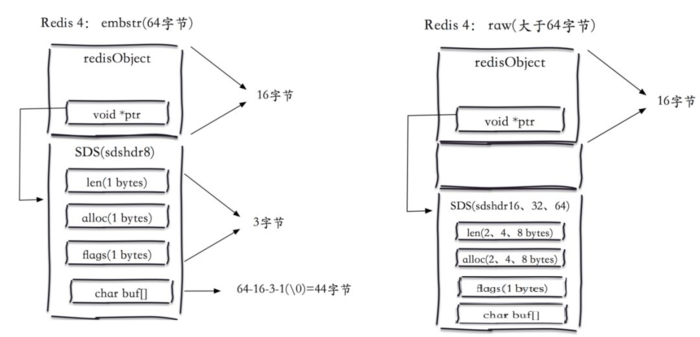
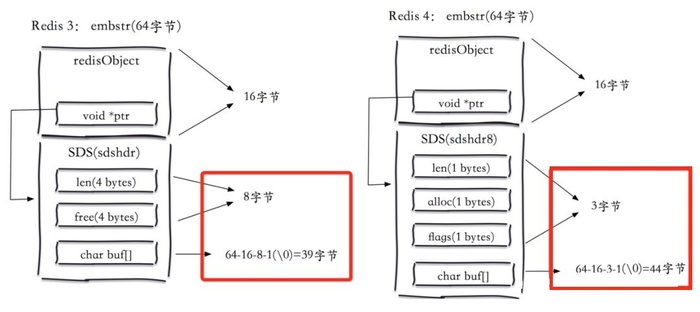
图中展示了两者的区别,可以看到embstr将redisObject和SDS保存在连续的64字节空间内,这样可以只需要一次内存分配,而对于raw来说,SDS和redisObject分离,需要两次内存分配,而且占用更多的内存空间。
可以看到embstr在3.2+中使用了叫sdshdr8的结构,在该结构下,元数据只需要3个字节,而Redis需要8个字节,所以总共64个字节,减去redisObject(16字节),再减去SDS的原信息,最后的实际内容就变成了44字节和39字节。
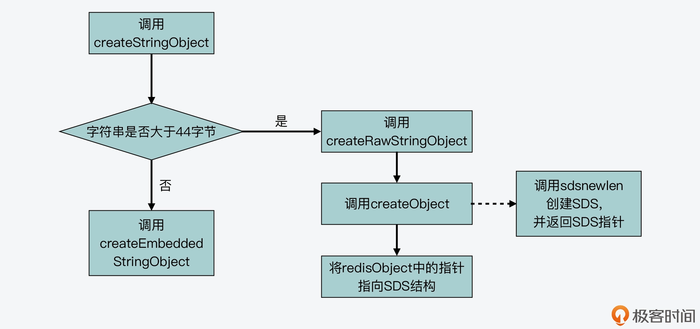
当字符串小于等于 44 字节时,Redis 就使用了嵌入式字符串的创建方法,以此减少内存分配和内存碎片。
下面这张图展示了 createEmbeddedStringObject 创建嵌入式字符串的过程:
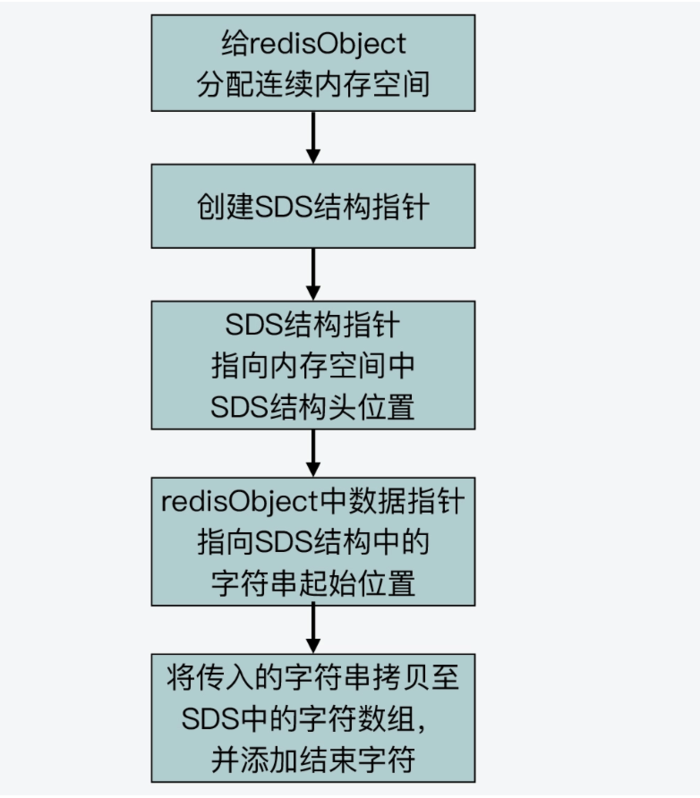
总之,只要记住,Redis 会通过设计实现一块连续的内存空间,把 redisObject 结构体和 SDS 结构体紧凑地放置在一起。
这样一来,对于不超过 44 字节的字符串来说,就可以避免内存碎片和两次内存分配的开销了。


 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫