局部搜索策略用于定位一个潜在的解决方案,该解决方案优化了具有挑战性的优化问题的标准。爬山算法是一种局部搜索算法,不断向增加高度或值的方向前进,以找到山顶或问题的最佳解。当它达到一个峰值时,它的邻居都没有更高的值,它就结束了。
使用数学优化解决问题的技术是爬山算法。爬山算法最流行的例子之一是旅行推销员。问题:我们需要减少推销员的行进距离。
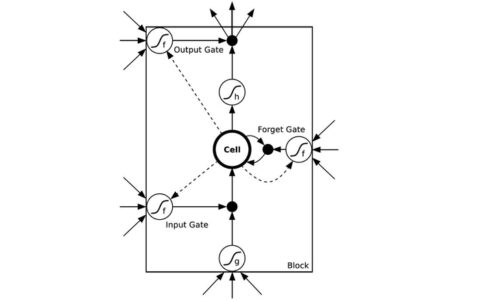
它也被称为贪婪的局部搜索,因为它只在其宜人的近邻状态内部寻找,而不会看得更远。爬山算法节点的两个部分是状态和值。
什么是爬山算法?
一种称为“爬山算法”的局部搜索方法不断向上移动(增长),直到找到最佳答案。一旦达到峰值,算法就完成了。
该算法中的节点有两个组成部分:状态和值。山脚是起点,不是最优的,会不断改进,直到满足某种需要。这个先决条件的基础是启发式函数。
攀登是一个概念,可以用来描述不断改进迭代现状的过程。现在,为什么该方法被称为“爬山算法”是有道理的。
爬山算法的目标是达到当前状态的最佳升级版本。一旦当前状态得到改善,该方法将对更好的状态进行额外的增量修改。此过程将继续进行,直到找到最佳可能选项。在高峰条件下不可能进一步进步。
爬山算法可用于高效处理大型计算任务。它同时考虑了本地状态和当前有效的状态。当我们想要根据输入来改进或减少某个功能时,人工智能中的爬山问题非常有用。
爬山算法最著名的 AI 示例是“旅行推销员”问题,其中我们必须最小化推销员的移动距离。尽管爬山算法擅长快速发现局部最小值/最大值,但它可能无法找到全局最优(最佳可行)解决方案。
换句话说,爬山是一种启发式策略。它是一种搜索策略或知情搜索方法,根据实数为路径上的不同节点、分支和目的地赋予不同的权重。这些统计数据和为 AI 模型中的爬山搜索开发的启发式算法现在可用于增强搜索。爬山算法出色的输入效率和改进的启发式分配是其显着特征。
深度优先搜索质量评估的爬山结果(生成和测试策略的一种变体)。这是属于本地搜索引擎系列的优化策略。
这是一个相当简单的实现方法,因为研究了一个受欢迎的初始选择。爬山在某些情况下可能很有用,即使更复杂的算法可能会提供更好的结果。
可以解决的问题有多种答案,但有些方法比其他方法更可取。爬山可以解决旅行商的困境。找到前往每个城市的服务很简单,但这项服务可能不如理想的服务好。
如果有一种方法可以组织选择以便首先调查最有希望的节点,则搜索效率可能会提高。Hill Climbing 以深度优先的顺序在路径网络上前进,但可能性是根据一些启发式值(即从当前状态到目标状态的剩余成本的度量)排序的。
推荐阅读:什么是爬山算法?
爬山算法在人工智能中的重要性
对于优化问题,爬山算法作为局部搜索方法。它的功能是从一个随机位置开始,转移到下一个最优设置,并重复这个过程,直到它达到局部或全局最优,以先发生者为准。
考虑我们需要在陡峭区域定位最高点的情况。爬山算法可以按如下方式应用:选择地图上的任意一个随机位置作为起点;确定哪个方向去上坡;朝那个方向前进;然后从第二步继续,直到到达地图上的最高点(即附近山顶)。
爬山法可用于解决必须发现理想解但起始位置未知的问题。例如,一个涉及出差员工的场景请求在返回起点之前在每个位置恰好停一次的最快路线。没有确定的最佳路径,但是可以使用爬山算法来识别理想路径。
通过决定最有利可图的商品或服务组合,找到两个站点之间的最快路线和在商业情况下最大化利润是另外两个可以通过爬山来解决的优化问题。
您可以使用爬山来完成诸如解谜或国际象棋或西洋跳棋竞技游戏之类的活动。在这些情况下,该方法用于通过评估所有可能的移动并选择最大化得分或最小化移动后剩余棋子数的移动来确定下一个最佳移动。
找到一条既优化行程时间又优化燃料使用的路线是如何使用爬山技术解决具有多个目标的问题的一个例子。
人工智能使用“爬山”来改进所提供问题的数学解释。因此,在大量强制输入和启发式函数的情况下,算法会尝试在相当长的时间内找到给定问题的潜在解决方案。当没有足够的时间分配并且问题可能有也可能没有明确的解决方案时,爬山很有效。根据这个概念,从输入中选取值允许爬山法来解决需要减少或最大化实函数(也给定)的问题。
旅行推销员的问题,我们可能需要减少或最大化推销员行进的距离,可以是爬山算法的一个例子。
爬山只会发现非凸问题的局部最优解(无法通过任何附近配置改进的解决方案),这些问题并不总是所有潜在解决方案(搜索空间)中的最佳解决方案(全局最优解)。二进制搜索和线性规划的单纯形算法是通过爬山解决凸问题的算法的两个例子。
可以使用重新启动(即重复局部搜索)或更复杂的迭代或基于记忆的方法(即反应式搜索优化和禁忌搜索)来尝试防止陷入局部最优。也可以使用无记忆随机修改(如模拟退火)。
由于该方法相对简单,因此是优化算法中常见的初始选择。它经常用于人工智能中,以从起始节点过渡到所需状态。在相关算法中,开始节点和下一个节点的选择很多。
爬山有时与模拟退火或禁忌搜索等更复杂的算法一样有效,即使它们可能提供更好的结果。当可用于执行搜索的时间有限时,例如使用实时系统,爬山算法通常可以产生比其他算法更好的结果,前提是少量的增量通常会收敛到合适的答案(最佳答案)解决方案或近似值)。
在相反的极端,冒泡排序可能被认为是一种爬山算法(每次附近的元素交换都会减少无序元素对的数量),但即使对于低 N,这种策略也是低效的,因为所需的交换数量呈二次方增长。
爬山算法的问题
爬山有几个缺点。经过多次搜索可能找不到答案,但也无能为力。如果发生这种情况,则将达到局部最大值、平台或波峰。
局部最大值:
这个状态比它的所有邻居表现得更好,但不如某些更远的状态(前面可能有更好的解决方案,这个解决方案被称为全局最大值。)从这个位置来看,所有的行动似乎都更糟。如果发生这种情况,请回到以前的状态并尝试从不同的角度解决问题。
高原:
搜索空间的一个区域,它是水平的并且所有附近的状态都具有相同的值。最好的课程不能提前选择。在这种情况下,执行急转弯并尝试到达搜索区域的不同区域。Flat maximum 是它的另一个名字。
岭:
这是一个搜索空间的区域,它高于附近的地形,但无法通过在单一方向上进行单一移动来到达。这个特定的局部最大值是唯一的。在这里,您应该在参加考试之前使用两个或多个指南,这需要一次在多个方向上旅行。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:AI中的爬山算法详解 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫