文本文件可存储的数据量多、每当需要分析或修改存储在文件中的信息时,读取文件都很有用,对数据分析应用程序
处理文件,让程序能够快速地分析大量的数据
处理文件和保存数据可让你的程序使用起来更容易
一、从文件中读取数据
1)读取整个文件:
先创建一个任意的文本文件,设置任意行,任意个数据,命名为data.txt,如下所示:
415926535897 932384626433 832795028841 9716939 937510 234 321
打开data.txt,并读取到程序中
with open('data.txt') as file_object: #方法open() 打开文件 ,并且接受一个参数,即要打开的文件的名称 contents = file_object.read() #方法 read() 读取这个文件的全部内容,并将其作为字符串存储在变量 contents 中 print(contents) #打印字符串contents
执行结果如下:
415926535897 932384626433 832795028841 9716939 937510 234 321
2)文件路径
上述 open('data.txt') 其中data.txt文件必须和.py模块(文件)放在同一个文件夹中,为方便打开其他文件,可以使用相对文件路径和 绝对文件路径。
#使用绝对路径打开文件 file_path = 'E:WorkSpacepythoncodingdata.txt' #使用绝对路径,可读取系统任何地方的文件 with open(file_path) as file_object: contents = file_object.read() print(contents)
3)逐行读取
上述都是一次读取data.txt中的内容,读取文件时,可能需要检查其中的每一行或者查找特定的信息,或者要以某种方式修改文件中的文本,可使用 for 循环以每次一行的方式检查文件。
filename = 'E:WorkSpacepythoncodingdata.txt' with open(filename) as file_object: for line in file_object: print(line.rstrip()) #消除多余的空白
4)使用列表来存取读入的行,其中每一行相当于列表的一个元素。(重新创建了一个pi.txt的文本,里面有若干行数字。)
pi.txt文件内容如下:注意,前后有空格
3.14159265358979323846264338
32795028841971693993751058
20974944592307816406286208
99862803482534211706791201
611596
程序如下:
#创建一个包含文件各行内容的列表 filename = 'pi.txt' with open(filename) as file_object: lines = file_object.readlines() #方法 readlines() 从文件中读取每一行,并将其存储在一个列表中 for line in lines: # for 循环来打印 lines 中的各行 print(line.strip()) #方法strip()去除每行首尾的空格。
5)使用文件的内容,将文件读取到内存中后,就可以以任何方式使用这些数据。
filename = 'pi.txt' with open(filename) as file_object: lines = file_object.readlines() #方法 readlines() 从文件中读取每一行,并将其存储在一个列表中 #上述代码完成后,结果应该为:lines=['3.141592****','32795028841971','20974944592',]形式 pi_string = '' #定义一个空字符串 for line in lines: # for 循环来将lines中的各元素连接起来 pi_string += line.strip() #strip()用来消除每个元素(txt文件中的每行)首尾的空白行 print(line.strip() ) print(pi_string) #打印连接好的字符串 print(len(pi_string)) #求字符串的长度
运行结果:(注意每行前后的空格已经消除,strip()方法的作用)
3.14159265358979323846264338 32795028841971693993751058 20974944592307816406286208 99862803482534211706791201 611596 3.14159265358979323846264338327950288419716939937510582097494459230781640628620899862803482534211706791201611596 112
可处理的数据量,Python中没有任何限制;只要系统的内存足够,如在科学计算或数据处理的时候,多达百万位的小数。
示例程序:在给定的百万位圆周率数据中,查找看是否有你的生日
filename = 'pi_million_digits.txt' #百万位圆周率数据 with open(filename) as file_object: lines = file_object.readlines() #读取每一行数据,作为一个元素存入列表lines中 pi_string = '' for line in lines: pi_string += line.rstrip() #消除空格,并将所有行连接起来 birthday = input("Enter your birthday, in the form mmddyy: ") #输入生日:月日年 if birthday in pi_string: #在连接好的百万位圆周率中对输入的生日匹配,如存在打印下列语句 print("Your birthday appears in the first million digits of pi!") else: #如没有匹配的字符串,打印下列语句 print("Your birthday does not appear in the first million digits of pi.")
运行结果:
Enter your birthday, in the form mmddyy: 02211994 Your birthday does not appear in the first million digits of pi.
二、写入文件
之前都是直接调用 print()将相关信息打印在console中,现在将文件保存到.txt文件中:要将文本写入文件,在调用 open() 时需要提供另一个实参。
filename = 'programming.txt'#打开或创建一个文件 with open(filename, 'w') as file_object: # 调用 open() 时提供了两个实参。第一个实参也是要打开的文件的名称(如果不存在programming文件,会自动创建); 第二个实参( 'w' )告诉Python,要以写入模式打开这个文件 file_object.write("I love python.") #即在文件中写入字符串"I love programming."
程序运行结果,是创建了一个 programming.txt的文件 ,并在文件写入了 I love programming.
filename = 'programming.txt'#打开或创建一个文件 with open(filename, 'w') as file_object: # 调用 open() 时提供了两个实参(见Ø)。第一个实参也是要打开的文件的名称; # 第二个实参( 'w' )告诉Python,要以写入模式打开这个文件 file_object.write("I love python.") file_object.write("Lucy love java.") file_object.write("I love creating new project.n") file_object.write("Lucy love creating project.")
注意:python中写入到txt文件中,如果没有n ,程序可能会直接连接成一行字符串,如果要分行需要在每一行后面加上n,才能分成多行,如上述代码最后两行所示。
给文件添加内容,而不覆盖原有内容,可以附加模式打开文件。
以附加模式打开文件时,Python不会在返回文件对象前清空文件,而写入到文件的行都将添加到文件末尾。
如果指定的文件不存在,Python将为你创建一个空文件。
接上述代码 :
with open(filename, 'a') as file_object: file_object.write("I also love finding meaning in large datasets.n") file_object.write("I love creating apps that can run in a browser.n")
运行结果:
I love python.Lucy love java.I love creating new project. #写入文件,没有带n,直接连成一行 Lucy love creating project. I also love finding meaning in large datasets.#在原有文件中,附加新内容 I love creating apps that can run in a browser.
三、存储数据
一种简单的方式是使用模块 json 来存储数据。
模块 json 能够将简单的Python数据结构转储到文件中,并在程序再次运行时加载该文件中的数据。
还可以使用 json 在Python程序之间分享数据。
更重要的是,JSON数据格式是一种非常通用的数据格式,能够将以JSON格式存储的数据与使用其他编程语言的人分享。
1、使用 json.dump() 和 json.load()
编写一个存储一组数字的简短程序,再编写一个将这些数字读取到内存中的程序。第一个程序将使用 json.dump() 来存储这组数字,而第二个程序将使用 json.load() 。
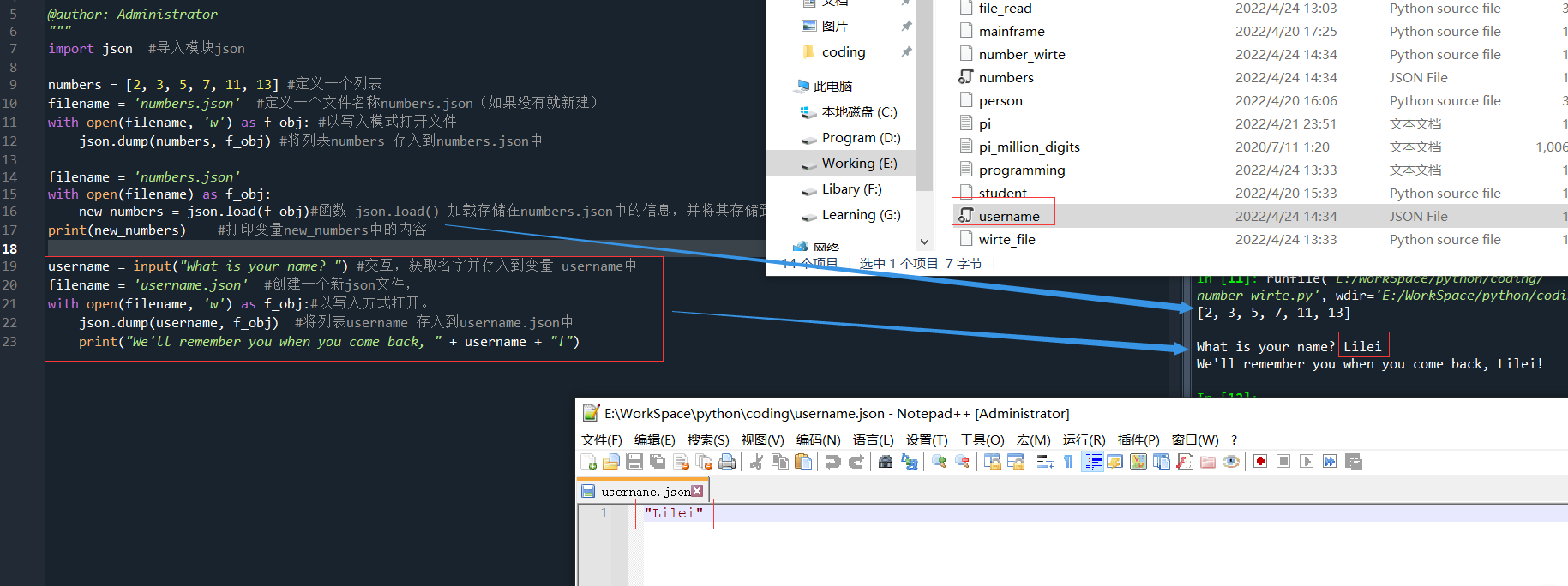
import json #导入模块json numbers = [2, 3, 5, 7, 11, 13] #定义一个列表 filename = 'numbers.json' #定义一个文件名称numbers.json(如果没有就新建) with open(filename, 'w') as f_obj: #以写入模式打开文件 json.dump(numbers, f_obj) #将列表numbers 存入到numbers.json中 filename = 'numbers.json' with open(filename) as f_obj: new_numbers = json.load(f_obj)#函数 json.load() 加载存储在numbers.json中的信息,并将其存储到变量new_numbers 中 print(new_numbers) #打印变量new_numbers中的内容
2、保存、读取用户生成的数据
程序运行过程中,会生成的数据,停止运行时,这些信息将丢失,可使用 json 保存。
import json username = input("What is your name? ") #交互,获取名字并存入到变量 username中 filename = 'username.json' #创建一个新json文件, with open(filename, 'w') as f_obj:#以写入方式打开。 json.dump(username, f_obj) #将列表username 存入到username.json中 print("We'll remember you when you come back, " + username + "!")
运行结果是在console中需要输入一个名字,系统将保存后存入到一个username.json的文件中,再在console打印输入最后一句。

测试一下
f = open("demo.txt","w")#打开文件以便写入 print('日照香炉生紫烟',file=f) print('遥看瀑布挂前川',file=f) print('飞流直下三千尺',file=f) print('疑是银河落九天',file=f) f.close()
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:python入门基础(12)–文件的读写操作 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 