Python常见面试题001-005
参考资料
https://github.com/taizilongxu/interview_python
https://github.com/hantmac/Python-Interview-Customs-Collection
https://github.com/kenwoodjw/python_interview_question
有些来自上面(但我也做了自己的补充),有些来自网络或书籍
本文不准备写编程题,偏重于理论一些。你要的话去刷leetcode就是了。
倒序描述,限于篇幅,可能要连载
005. 说说你对浅拷贝、深拷贝的理解
- 浅拷贝 shallow copy
- 深拷贝 deep copy
浅拷贝
-
第一次见浅拷贝是在
>>> help(list.copy) Help on method_descriptor: copy(self, /) Return a shallow copy of the list. -
list列表的copy方法,那浅拷贝到底是怎样的行为表现呢?
-
示例代码
list1 = [1,2,3] list2 = list1.copy() list1.append(4) print(list2) # [1,2,3] list1改变了,list2没变 , 浅拷贝是互相不会影响的 -
来看这段
list1 = [1,2,3] list2 = list1 list1.append(4) print(list2) # [1,2,3,4] ,赋值是引用,同时指向了一个内存区域,现在你改变了内存的信息,自然一起改变了 -
在第一个例子中
list1 = [1,2,3] list2 = list1.copy() print(id(list1)) print(id(list2)) # 显然2个id的值是不一样的,所以改变了你,并不会改变我 print(list1 == list2) # True print(list1 is list2) # False
- 来看看其他的浅拷贝方式
切片
-
可变序列的切片创建了一个浅拷贝,不可变序列的切片创建了一个引用
list1 = [1,2,3] list2 = list1[:] list1.append(4) print(list2) # [1,2,3] 跟list1不一样 print(list2 is list1) # False tuple1 = (1,2,3) tuple2 = tuple1[:] print(tuple1 is tuple2) # True
- 浅拷贝,是指重新分配一块内存,创建一个新的对象,里 面的元素是原对象中子对象的引用。因此,如果原对象中的元素不可变,那倒无所谓;但如果元 素可变,浅拷贝通常会带来一些副作用
构造器
-
常见的浅拷贝的方法,是使用数据类型本身的构造器
set1 = {1,2,3} set2 = set(set1) print(set2 is set1) # False
copy.copy()
-
copy.copy则可以用于任意的数据类型的浅拷贝
>>> from copy import copy >>> help(copy) Help on function copy in module copy: copy(x) Shallow copy operation on arbitrary Python objects. See the module's __doc__ string for more info. -
示例代码
dict1 = {"name":"wuxianfeng","age":18} from copy import copy dict2 = copy(dict1) print(dict2 is dict1) dict1['height'] = 180 print(dict2)
特殊情况
-
来看下面的这些例子
l1 = [[1, 2], (30, 40)] l2 = list(l1) l1.append(100) l1[0].append(3) print(l2) # 请问此时l2是什么? -
按照前面的理解,list构造器会产生浅拷贝
print(l2 is l1) # False # 说明这是2个不同的对象 -
按理说l1的变化不会影响到l2
-
但事实是影响了
[[1, 2, 3], (30, 40)] # 第四行代码发生作用了 -
仔细看会发现,line3没有改变,line4改变了
-
再看一个操作
# 承上 l1[1] +=(50,60) print(l2) # 还是[[1, 2, 3], (30, 40)] 但l1肯定是变了的 -
完整的解释
l1 = [[1, 2], (30, 40)] l2 = list(l1) # 对l1执行浅拷贝,赋予l2。 # 因为浅拷贝里的元素是对原对象元素的引用,因此l2中的元素和l1中的元素指向同一个列表和元组对象 l1.append(100) # 这个操作不会对l2产生任何影响,因为l2和l1作为整体是两个不同的对象,并不共享内存地址 l1[0].append(3) # l1[0] 是[1, 2] # 因为l1和l2的[1, 2]是同一个对象,不信? # print(id(l1[0])) # print(id(l2[0])) # print(l1[0] is l2[0]) # True # 所以l1[0].append(3) 这步会对l1和l2的[1,2]都追加一个元素3 l1[1] +=(50,60) # 最麻烦的是这个 # l1[1] 是(30,40) ,是个元组 # l2[1] 的确是同一个对象 # l1[1] +=(50,60) 会创建一个新的,注意是新的!元组 # 但l2不会 -
你可以这样验证
print('l1的元组的id',id(l1[1]),'l1的元组的id',id(l2[1])) l1[1] +=(50,60) print('l1的元组的id',id(l1[1]),'l1的元组的id',id(l2[1])) # 输出参考 l1的元组的id 2411404337920 l1的元组的id 2411404337920 l1的元组的id 2411404749456 l1的元组的id 2411404337920 # 是的,l1中的元组已经变了,l2的没有改变 -
至此你应该发现了浅拷贝的一些副作用
深拷贝
-
深拷贝来自copy模块的deepcopy方法
-
同样看上面的例子
from copy import deepcopy l1 = [[1, 2], (30, 40)] l2 = deepcopy(l1) l1.append(100) l1[0].append(3) l1[1] +=(50,60) print(l2) # [[1, 2], (30, 40)] # 就是你复制的时候的样子 -
好像deepcopy很完美?
-
复制的时候的确不希望互相影响
-
但deepcopy有它的弊端:如果被拷贝对象中存在指向自身的引 用,那么程序很容易陷入无限循环
官方解释
-
Python 的赋值语句不复制对象,而是创建目标和对象的绑定关系
-
对于自身可变,或包含可变项的集合,有时要生成副本用于改变操作,而不必改变原始对象。本模块提供了通用的浅层复制和深层复制操作
- copy.copy(x) 浅层复制
- copy.deepcopy(x) 深层复制
-
浅层与深层复制的区别仅与复合对象(即包含列表或类的实例等其他对象的对象)相关:
- 浅层复制 构造一个新的复合对象,然后(在尽可能的范围内)将原始对象中找到的对象的 引用 插入其中。
- 深层复制 构造一个新的复合对象,然后,递归地将在原始对象里找到的对象的 副本 插入其中。
-
深度复制操作通常存在两个问题, 而浅层复制操作并不存在这些问题:
- 递归对象 (直接或间接包含对自身引用的复合对象) 可能会导致递归循环。
- 由于深层复制会复制所有内容,因此可能会过多复制(例如本应该在副本之间共享的数据)
-
deepcopy() 函数用以下方式避免了这些问题:
- 保留在当前复制过程中已复制的对象的 "备忘录" (
memo) 字典;以及 - 允许用户定义的类重载复制操作或复制的组件集合
- 保留在当前复制过程中已复制的对象的 "备忘录" (
-
下面这个案例说明了一点什么
from copy import deepcopy x = [1] x.append(x) print(x) # [1, [...]] y = deepcopy(x) print(y) # [1, [...]]- 按理说y会无限循环,堆栈溢出,但实际上并没有,还是deepcopy做了一些事情规避的
004. 请说出下面代码的返回结果是什么?
参考了 https://www.liujiangblog.com/course/python/44
如有侵权,联系删除
-
示例代码1
class D: pass class C(D): pass class B(C): def show(self): print("i am B") pass class G: pass class F(G): pass class E(F): def show(self): print("i am E") pass class A(B, E): pass a = A() a.show() -
结果
i am B -
你可以整理出这样的一个继承关系
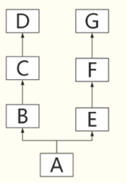

-
从执行结果看先走 是A(B,E)中左侧的B这个分支:可见,在A的定义中,继承参数的书写有先后顺序,写在前面的被优先继承。
-
你可以查看A的__mro__属性
print(A.__mro__) # 你也可以这样print(A.mro()) # 是个元组 (<class '__main__.A'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.D'>, <class '__main__.E'>, <class '__main__.F'>, <class '__main__.G'>, <class 'object'>) -
如果你改成这样
class A(E,B): pass print(A.__mro__) -
顺序自然成了这样
(<class '__main__.A'>, <class '__main__.E'>, <class '__main__.F'>, <class '__main__.G'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.D'>, <class 'object'>) -
继承关系下的搜索顺序
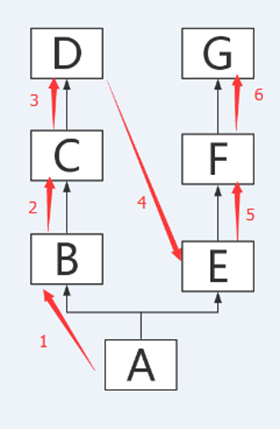
-
所以,把代码改为这样,输出你应该毫无疑问了
class D: def show(self): print("i am D") pass class C(D): pass class B(C): pass class G: pass class F(G): pass class E(F): def show(self): print("i am E") pass class A(B, E): pass a = A() a.show() # i am D -
那么这样呢?
class H: def show(self): print("i am H") pass class D(H): pass class C(D): pass class B(C): pass class G(H): pass class F(G): pass class E(F): def show(self): print("i am E") pass class A(B, E): pass a = A() a.show() -
继承关系是这样的
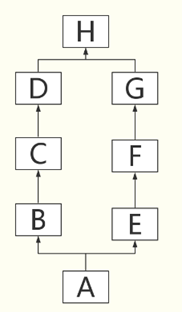
-
答案是
i am E -
看MRO
print(A.__mro__) (<class '__main__.A'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.D'>, <class '__main__.E'>, <class '__main__.F'>, <class '__main__.G'>, <class '__main__.H'>, <class 'object'>) -
所以继承树的搜索顺序是这样的
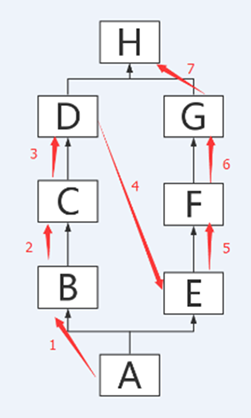
-
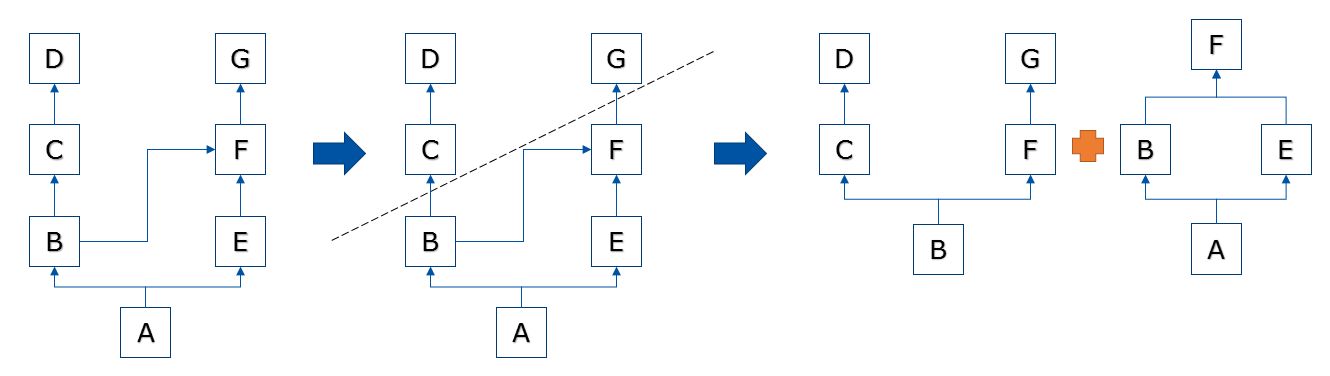
而所有的继承其实都是这2种图形的变化
-
比如这样的代码
class D(): pass class G(): def show(self): print("i am G") pass class F(G): pass class C(D): pass class B(C,F): pass class E(F): def show(self): print("i am E") pass class A(B, E): pass a = A() a.show() -
你先分析下应该输出啥,继承树是怎样的,MRO是如何的?
-
输出
i am E -
继承树
-
MRO
(<class '__main__.A'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.D'>, <class '__main__.E'>, <class '__main__.F'>, <class '__main__.G'>, <class 'object'>)
-
关于类的继承
- 子类在调用某个方法或变量的时候,首先在自己内部查找,如果没有找到,则开始根据继承机制在父类里查找。
- 根据父类定义中的顺序,以深度优先的方式逐一查找父类!
- 子类永远在父类前面,如果有多个父类,会根据它们在列表中的顺序被检查,如果对下一个类存在两个合法的选择,选择第一个父类
-
MRO:即Method Resolution Order(方法解析顺序)
-
从Python 2.3开始计算MRO一直是用的C3算法
https://www.python.org/download/releases/2.3/mro/ -
C3算法的简单解释可以参考码农高天的这个视频:https://www.bilibili.com/video/BV1V5411S7dY
003. 请说出下面的代码返回结果是什么?为何?如何改进?
知识点: 函数参数的类型
-
示例代码
def f(a, L=[]): L.append(a) return L print(f(1)) print(f(1)) -
据说是国内某上市互联网公司Python面试真题(略作改动),而实际在python的官网也有
https://docs.python.org/zh-cn/3.9/tutorial/controlflow.html#default-argument-values -
烂大街了
-
典型的错误答案
[1] [1] -
实际的答案
[1] [1, 2] -
因为Python函数体在被读入内存的时候,默认参数a指向的空列表对象就会被创建,并放在内存里了。因为默认参数a本身也是一个变量,保存了指向对象[]的地址。每次调用该函数,往a指向的列表里添加一个A。a没有变,始终保存的是指向列表的地址,变的是列表内的数据!
-
修改
def f(a, L=None): if L is None: L = [] L.append(a) return L print(f(1)) print(f(1))
-
官网的重要警告: 默认值只计算一次。默认值为列表、字典或类实例等可变对象时,会产生与该规则不同的结果
-
这样的代码
def f(a, L=[]): L.append(a) return L print(f(1)) print(f(2)) # 被我改成了1,具有欺骗性一点 print(f(3)) # 去掉了,3个放一起,你都能猜到有点猫腻了,2个虽然也....总归好一点 -
上面的函数会累积后续调用时传递的参数
-
不想在后续调用之间共享默认值时,建议用None这样的不可变对象来存储
def f(a, L=None): if L is None: L = [] L.append(a) return L
002. 请分别说出下面的代码返回结果是什么?为何?
知识点: 作用域
-
示例代码1
def func(x): print(x) print(y) func(1) -
示例代码2
y = 1 def func(x): print(x) print(y) func(1) -
示例代码3
y = 1 def func(x): print(x) print(y) y = 2 func(1)
-
示例代码1的执行结果
NameError: name 'y' is not defined -
示例代码2的执行结果
1 1 -
示例代码3的执行结果
UnboundLocalError: local variable 'y' referenced before assignment
解释3
- Python 编译函数的定义体时,它判断 b 是局部变量,依据是y=2,你对它进行了赋值。Python 会尝试从本地环境获取 b。
- 后面调用 func(1)时,func的定义体会获取并打印局部变量x 的值,但是尝试获取局部变量 y 的值时,发现 y 没有 绑定值就报错了。
- 这不是缺陷,这是设计如此(做测试是不是经常听到这句话)
- Python 不要求声明变量,但是假定在函数定义体中赋值的变 量,那就认为它是局部变量
对于代码3的处理
-
示例代码3(更改)
y = 1 def func(x): global y print(x) print(y) y = 2 func(1) -
这样解释器就会把 y 当成全局变量,从而找到第一行的y=1并print出来了
从函数的字节码也能看出来这个过程
-
代码1
def func(x): print(x) print(y) y = 2 from dis import dis dis(func) -
字节码
3 0 LOAD_GLOBAL 0 (print) # 加载全局名称print 2 LOAD_FAST 0 (x) # 加载本地名称x 4 CALL_FUNCTION 1 6 POP_TOP 4 8 LOAD_GLOBAL 0 (print) 10 LOAD_FAST 1 (y) # 加载本地名称y 12 CALL_FUNCTION 1 14 POP_TOP 5 16 LOAD_CONST 1 (2) 18 STORE_FAST 1 (y) 20 LOAD_CONST 0 (None) 22 RETURN_VALUE
-
示例代码2
y = 1 def func(x): print(x) print(y) from dis import dis dis(func) -
字节码
3 0 LOAD_GLOBAL 0 (print) 2 LOAD_FAST 0 (x) 4 CALL_FUNCTION 1 6 POP_TOP 4 8 LOAD_GLOBAL 0 (print) 10 LOAD_GLOBAL 1 (y) # 看这里的变化,是全局变量了 12 CALL_FUNCTION 1 14 POP_TOP 16 LOAD_CONST 0 (None) 18 RETURN_VALUE 进程已结束,退出代码为 0
-
示例代码3
y = 1 def func(x): print(x) print(y) y = 2 from dis import dis dis(func) -
字节码
3 0 LOAD_GLOBAL 0 (print) 2 LOAD_FAST 0 (x) 4 CALL_FUNCTION 1 6 POP_TOP 4 8 LOAD_GLOBAL 0 (print) 10 LOAD_FAST 1 (y) # 又变成了本地 12 CALL_FUNCTION 1 14 POP_TOP 5 16 LOAD_CONST 1 (2) 18 STORE_FAST 1 (y) 20 LOAD_CONST 0 (None) 22 RETURN_VALUE -
示例代码3(更改)
y = 1 def func(x): global y print(x) print(y) y = 2 from dis import dis dis(func) -
字节码
4 0 LOAD_GLOBAL 0 (print) 2 LOAD_FAST 0 (x) 4 CALL_FUNCTION 1 6 POP_TOP 5 8 LOAD_GLOBAL 0 (print) 10 LOAD_GLOBAL 1 (y) 12 CALL_FUNCTION 1 14 POP_TOP 6 16 LOAD_CONST 1 (2) 18 STORE_GLOBAL 1 (y) 20 LOAD_CONST 0 (None) 22 RETURN_VALUE
看不懂字节码不要紧的,当然非要,你可以去参考https://docs.python.org/zh-cn/3/library/dis.html
作用域LEGB相关知识单独考虑弄个博文
001. is和==有什么区别
-
==是对象的值的比较,也就是对象保存的数据。
-
is比较的是对象的标识。
-
示例代码1
a = [1,2,3] b = [1,2,3] print(a == b) # True print(a is b) # False -
is的背后是id,is比较为True,说明2个id的返回是一样的
-
在 CPython 中,id() 返回对象的内存地址, 但是在其他 Python 解释器中可能是别的值。关键是,ID 一定是唯一的数值标注,而且在 对象的生命周期中绝不会变。
上面的话引自 <流畅的python> 8.2 标识、相等性、别名
这些知识涉及对象的引用,相关的面试题如浅拷贝/深拷贝、重载运算符(==)等
浅拷贝也考虑单独剥离弄个博文或主题
-
示例代码2
>>> a = 257 >>> b = 257 >>> a is b False >>> a == b True # 但是这个呢? >>> c = d = 256 >>> c is d True -
这是因为出于对性能优化的考虑,Python内部会对-5到256的整型维持一个数组,起到一个缓存 的作用。这样,每次你试图创建一个-5到256范围内的整型数字时,Python都会从这个数组中返回相对应的引用,而不是重新开辟一块新的内存空间。
-
但是,如果整型数字超过了这个范围,比如上述例子中的257,Python则会为两个257开辟两块 内存区域,因此a和b的ID不一样,a is b就会返回False了。
-
比较操作符'is'的速度效率,通常要优于'=='。因为'is'操作符不能被重载,这 样,Python就不需要去寻找,程序中是否有其他地方重载了比较操作符,并去调用。执行比较操作符'is',就仅仅是比较两个变量的ID而已。
-
但是'=='操作符却不同,执行a == b相当于是去执行a.__eq__(b),而Python大部分的数据类型都 会去重载__eq_这个函数,其内部的处理通常会复杂一些。比如,对于列表,__eq_函数会去 遍历列表中的元素,比较它们的顺序和值是否相等。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:Python常见面试题001-005,涉及深浅拷贝、MRO、函数可变参数、作用域、is和==的区别等 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 