众所周知,某点评是一直有JS加密的,所以关于它的外包一直都很贵,有些公司甚至用来面试,可见他的难度。
但是吧,最近他好像没有加密了,这~
不值钱了啊!
那当时就忍不住了,就得用Python开始整活了!


话不多说,让我们上代码!
今天就没那么多步骤了,直接上代码!
import requests import parsel url = 'https://www.dianping.com/search/keyword/344/0_%E7%81%AB%E9%94%85/p2' headers = { 'Cookie': 'fspop=test; cy=344; cye=changsha; _lxsdk_cuid=181f2b8ceedc8-00c68dfc700b1e-c4c7526-384000-181f2b8ceedc8; _lxsdk=181f2b8ceedc8-00c68dfc700b1e-c4c7526-384000-181f2b8ceedc8; _hc.v=fa46cfdd-99f6-80af-c226-f8777fc1f097.1657634607; s_ViewType=10; _lx_utm=utm_source%3DBaidu%26utm_medium%3Dorganic; Hm_lvt_602b80cf8079ae6591966cc70a3940e7=1657634608,1657690542; lgtoken=0ecd60582-14f9-4437-87ad-7b55881b56df; WEBDFPID=3x389w8ww1vw5vuzy491zvxxu36989x2818u39v38389795895568429-1657776946569-1657690545731QSUUAWGfd79fef3d01d5e9aadc18ccd4d0c95072230; dper=6cfaf0f82f34d241b584d587fc92a7117ba6c082354d350ed861c0a256d00ba3beb93db7dc5485b4e2e4e4085a92126fa2e5f1dbe1b6eaefd1c814167fce943e; ll=7fd06e815b796be3df069dec7836c3df; Hm_lpvt_602b80cf8079ae6591966cc70a3940e7=1657690573; _lxsdk_s=181f60e4e6c-cad-fea-c91%7C%7C40', 'Host': 'www.dianping.com', 'Referer': 'https://www.dianping.com/search/keyword/344/0_%E7%81%AB%E9%94%85', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36', } response = requests.get(url=url, headers=headers) selector = parsel.Selector(response.text) href = selector.css('.shop-list ul li .pic a::attr(href)').getall() print(href) for index in href: html_data = requests.get(url=index, headers=headers).text selector_1 = parsel.Selector(html_data) title = selector_1.css('.shop-name::text').get() # 店名 count = selector_1.css('#reviewCount::text').get() # 评论 Price = selector_1.css('#avgPriceTitle::text').get() # 人均消费 item_list = selector_1.css('#comment_score .item::text').getall() # 评价 taste = item_list[0].split(': ')[-1] # 口味评分 environment = item_list[1].split(': ')[-1] # 环境评分 service = item_list[-1].split(': ')[-1] # 服务评分 address = selector_1.css('#address::text').get() # 地址 tel = selector_1.css('.tel ::text').getall()[-1] # 电话 dit = { '店名': title, '评论': count, '人均消费': Price, '口味': taste, '环境': environment, '服务': service, '地址': address, '电话': tel, '详情页': index, } print(dit)
注释我就不注释了,有点赶时间,女朋友喊我去吃饭呢!


不过没关系,还好我有先见之明,已经录了视频,都发在这里了,代码不明白的话,可以看视频有一步步的讲解。
视频地址: Python爬取大众点评
# 我给大家准备了这些资料:Python视频教程、100本Python电子书、基础、爬虫、数据分析、web开发、机器学习、人工智能、面试题、Python学习路线图、问题解答! # 都放在这个扣群啦 : 279199867
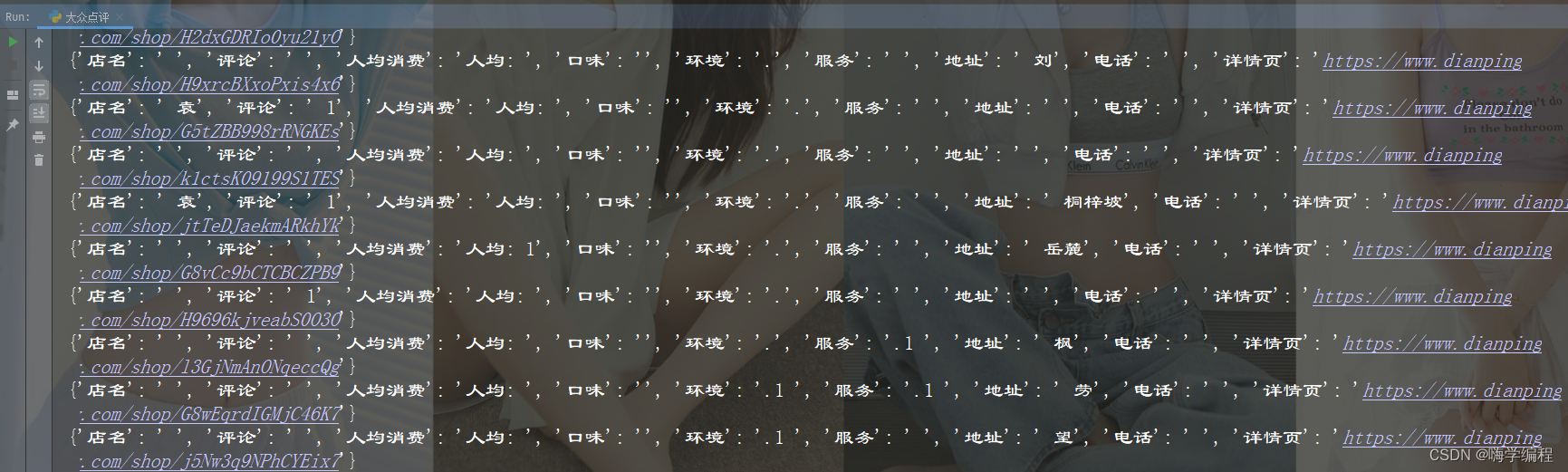
本文代码只是爬取了部分内容,视频中还讲解了让数据更好看,多页爬取,保存Excel表格等等。
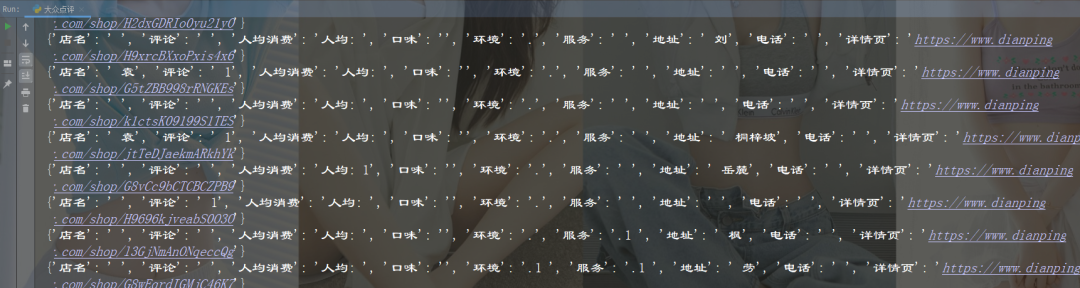
给大家展示一下效果
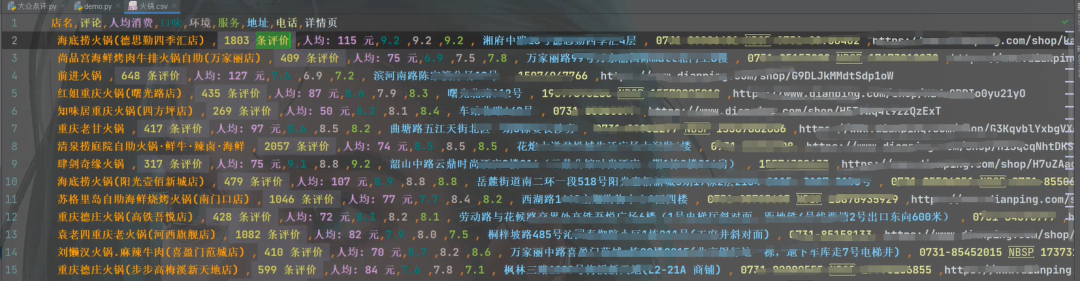
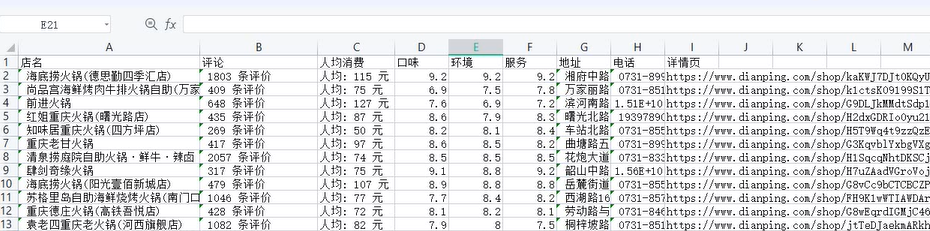
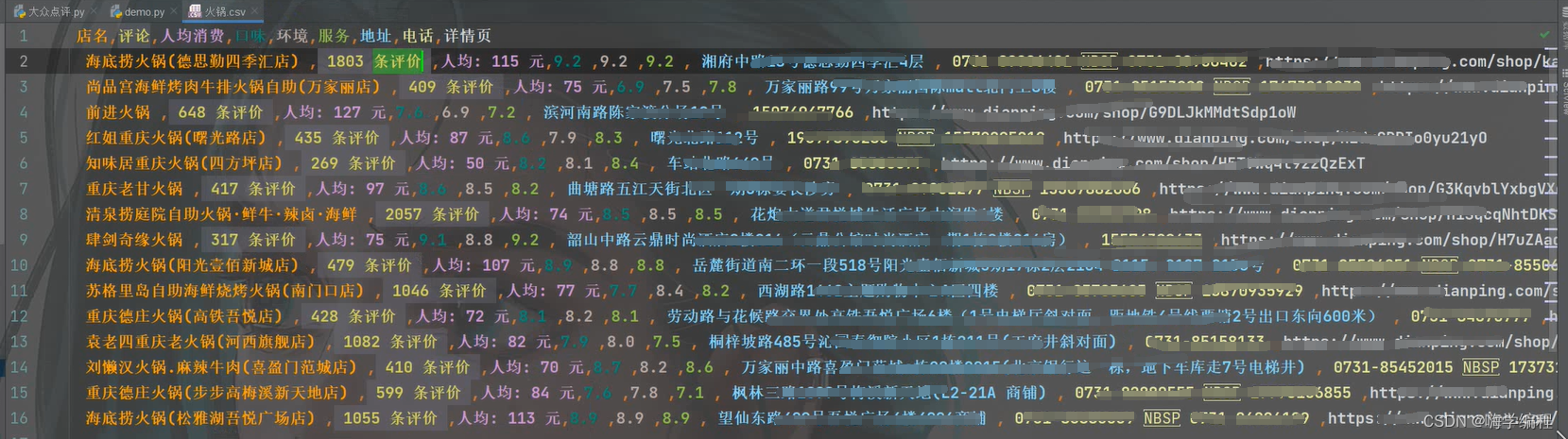
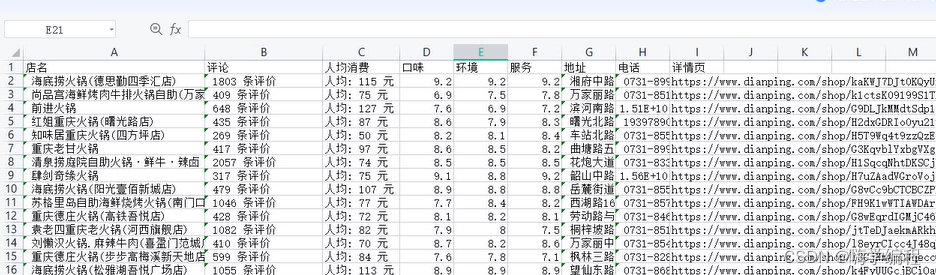
好了,今天的分享就到这,下次再见!
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:Python批量爬取大众点评数据 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 