前言
我们使用深度学习网络实现波士顿房价预测,深度学习的目的就是寻找一个合适的函数输出我们想要的结果。深度学习实际上是机器学习领域中一个研究方向,深度学习的目标是让机器能够像人一样具有分析学习的能力,能够识别文字、图像、声音等数据。我认为深度学习与机器学习最主要的区别就是神经元。
深度学习中重要内容
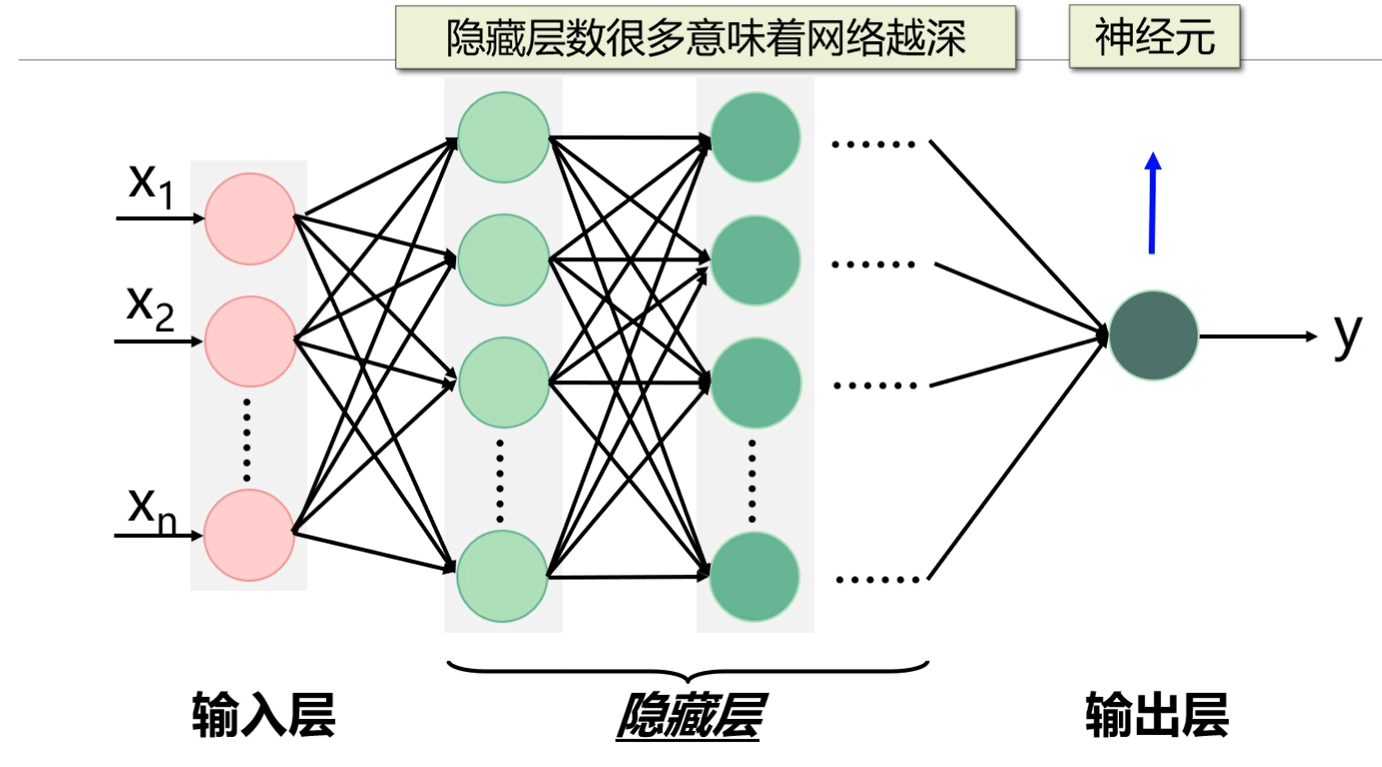
建立模型——神经元
-
基本构造
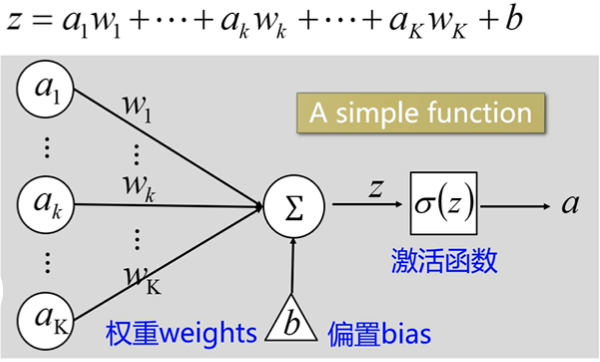

- 一个神经元对应一组权重w,a代表输入,我们把输入与权重相乘再相加,再加上偏置b,最后通过激活函得到对应的输出。
- 我们不看激活函数,只看前面的部分会发现其实就是一个线性函数f=kx+b(k表示斜率,b表示截距)
- w和b就是我们需要在训练中需要寻找的,
- 学习网络就是通过很多个这样的神经元组合而成。
建立模型——激活函数
-
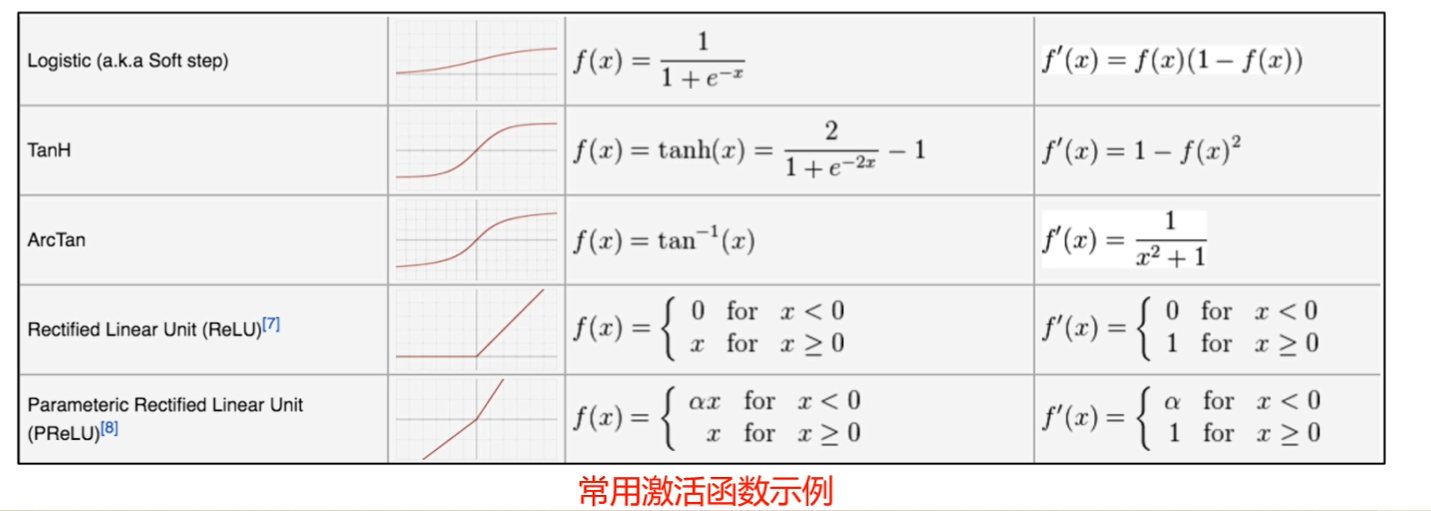
为什么引入激活函数
- 激活函数是为了增强网络的表达能力,我们需要激活函数来将线性函数转变为非线性函数。
- 非线性的激活函数需要有连续性,因为连续非线性激活函数可导的,所以可以用最优化的方法来求解
-
激活函数的种类
建立模型——前馈神经网络
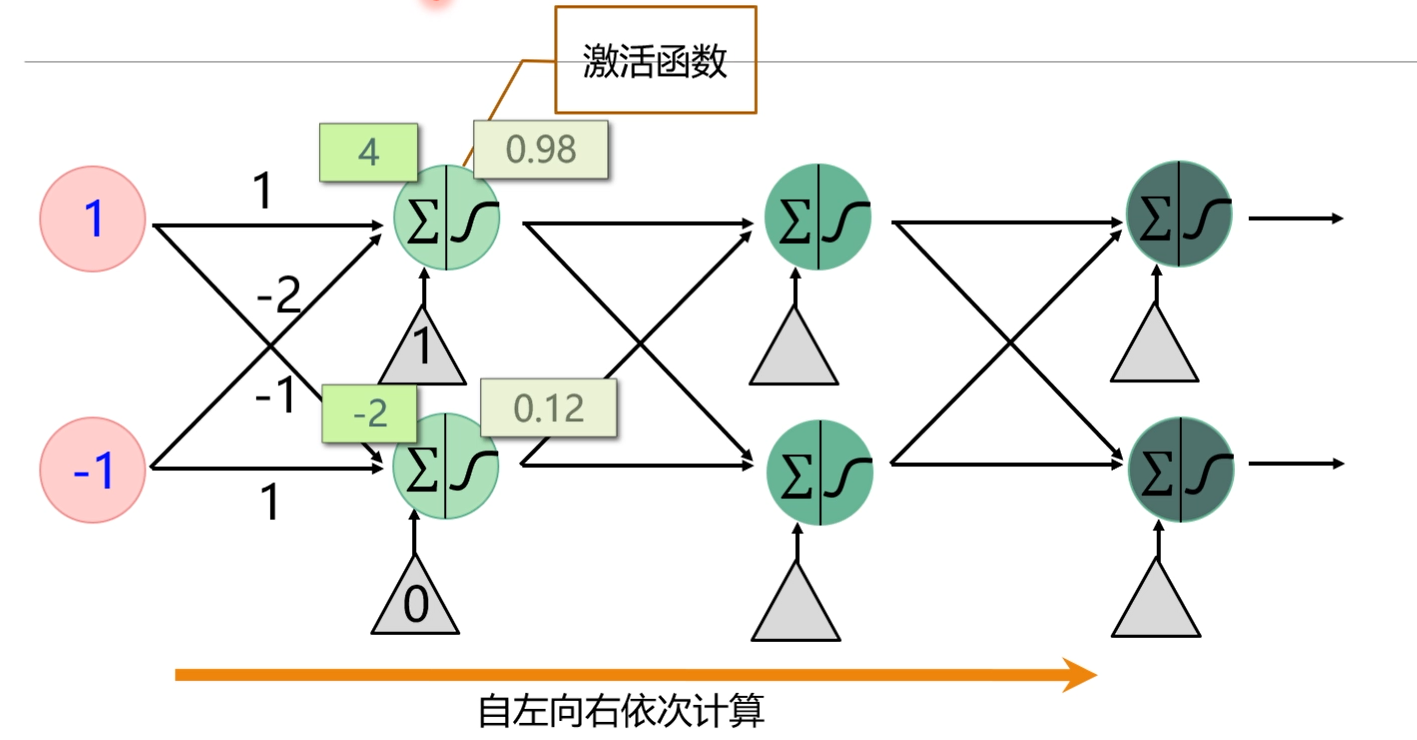
- 我们输入1和-1分别和每一组的权重相乘相加得到4和-2的结果,然后经过激活函数(激活函数实际上也是一个简单函数,但是具有某些特性,可以用来解决问题的目的,例如激活函数是y=x-1,我们输入4,输出结果就是3。)得到0.98和0.12.依次往后计算就是前馈神经网络。
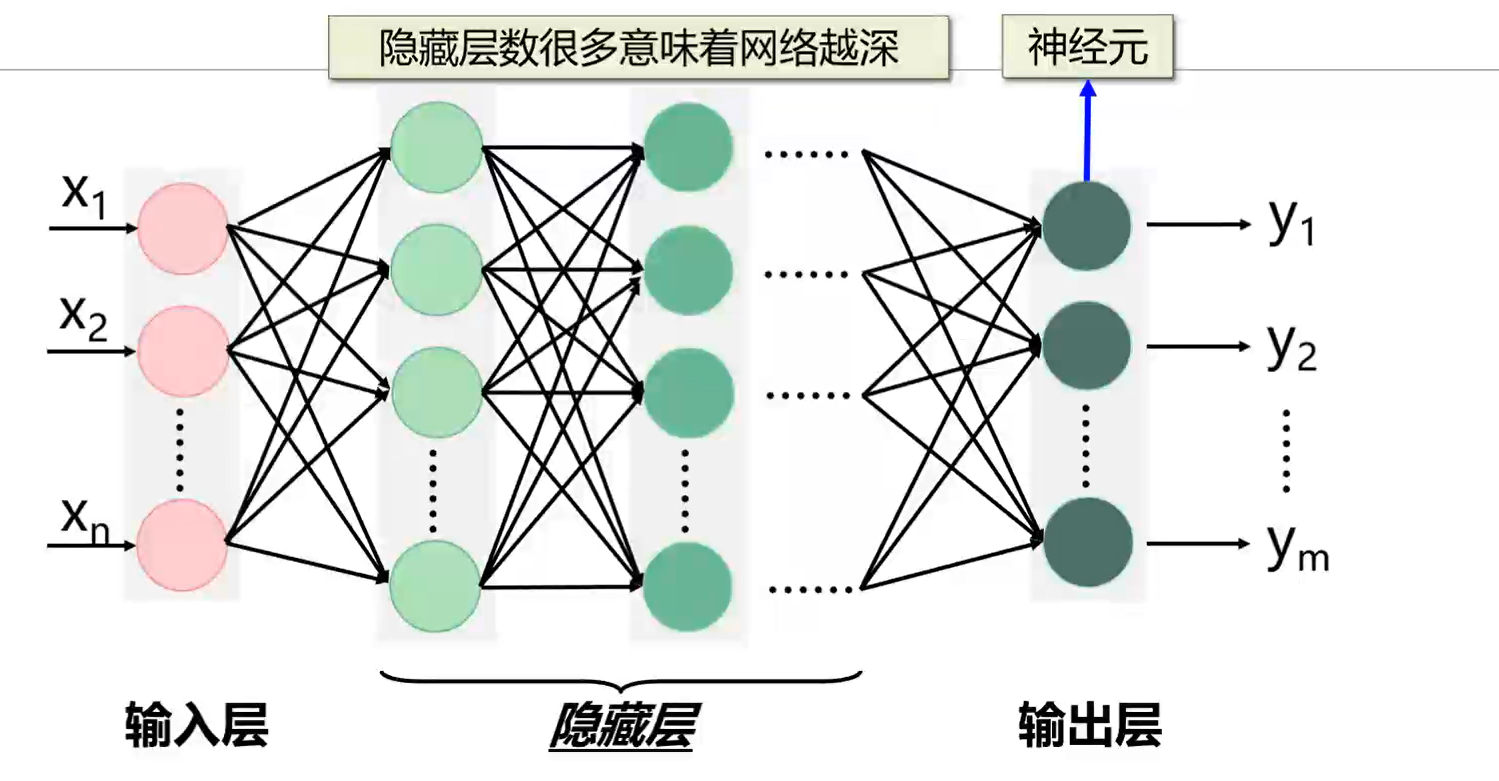
建立模型——深度神经网络
-
神经网络解决的问题有很多,例如分类、预测、回归等。这里我们给出两个解决类型。
-
分类
- 输出层就是输入的数据维度,例如我们要分类图形是正方型还是长方形,那我们可以是3维的输入,一个内角,两条临边。就可以判断。也可以是五维的,一个内角,4条边)
- 输出层y就是结果,就上面举例的图形分类,那结果可以有2个,长方形和正方形,例如y1代表长方形,y2代表正方形,输出的结果那个数值大就是那种类型,也可以增加一个都不是的结果)
-
预测
- 今天的波士顿房价预测就是预测模型,我们通过地段,房屋面积等等,预测房价的多少。
损失函数
- 常用损失函数
平方损失函数、交叉熵损失函数,不同的问题运用不同的损失函数 - 用于衡量我们输入结果和真实结果的差异
- 目的通过损失去修正我们的参数是我们的模型更完美
实践——波士顿房价预测
数据集
使用paddle飞桨波士顿数据集
https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/text/UCIHousing_cn.html
绘图
## 绘图
Batch = 0
Batchs = []
all_train_accs = []
def draw_train_acc(Batchs,train_accs):
title = "training accs"
plt.title(title)
plt.xlabel("batch")
plt.ylabel("acc")
plt.plot(Batchs, train_accs, color = 'green', label = 'training accs')
plt.legend()
plt.grid()
plt.show()
all_train_loss = []
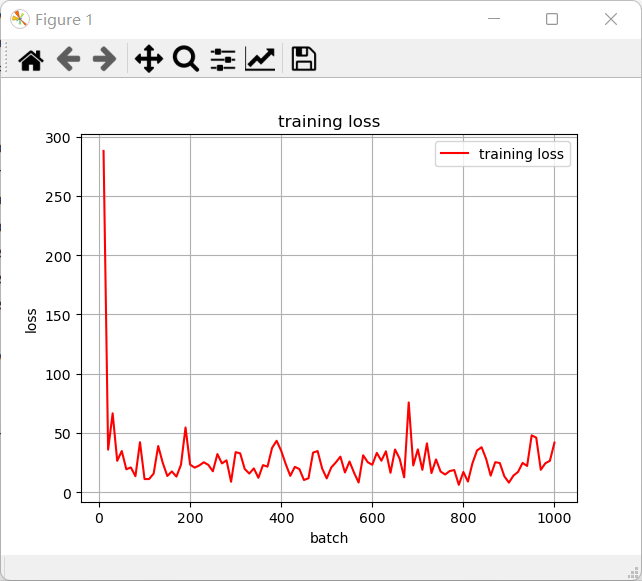
def draw_train_loss(Batchs,train_loss):
title = "training loss"
plt.title(title)
plt.xlabel("batch")
plt.ylabel("loss")
plt.plot(Batchs, train_loss, color = 'red', label = 'training loss')
plt.legend()
plt.grid()
plt.show()
## 绘制真实值与预测值的对比图
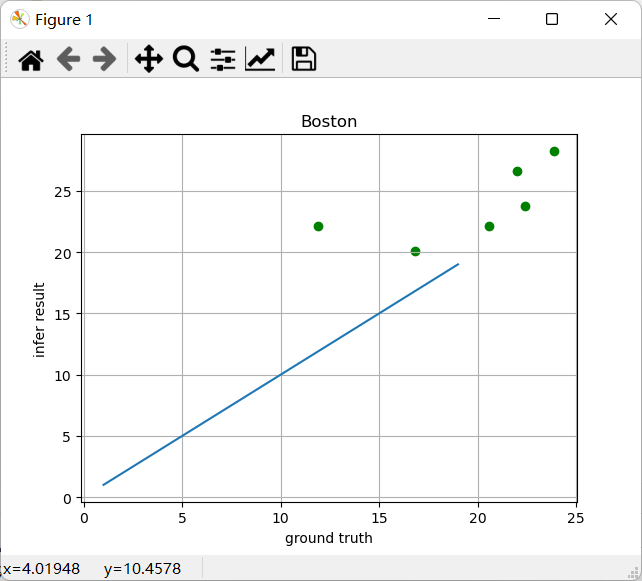
def draw_infer_result(groud_truths, infer_results):
title = 'Boston'
plt.title(title)
x = np.arange(1,20)
y = x
plt.plot(x,y);
plt.xlabel("ground truth")
plt.ylabel("infer result")
plt.scatter(groud_truths,infer_results,color='green',label='training cost')
plt.grid()
plt.show()
网络搭建
'''
核心
网络搭建
'''
class MyDNN(paddle.nn.Layer):
def __init__(self):
super(MyDNN, self).__init__()
#self.linear1 = paddle.nn.Linear(13,1,None) #全连接层,paddle.nn.Linear(in_features,out_features,weight)
self.linear1 = paddle.nn.Linear(13, 32, None)
self.linear2 = paddle.nn.Linear(32, 64, None)
self.linear3 = paddle.nn.Linear(64, 32, None)
self.linear4 = paddle.nn.Linear(32, 1, None)
def forward(self, inputs): ## 传播函数
x = self.linear1(inputs)
x = self.linear2(x)
x = self.linear3(x)
x = self.linear4(x)
return x
模型训练与测试
'''
网络训练与测试
'''
## 实例化
model = MyDNN()
model.train()
mse_loss = paddle.nn.MSELoss()
opt = paddle.optimizer.SGD(learning_rate=0.001, parameters=model.parameters())
epochs_num = 100
for epochs in range(epochs_num):
for batch_id,data in enumerate(train_loader()):
feature = data[0]
label = data[1]
predict = model(feature)
loss = mse_loss(predict, label)
loss.backward()
opt.step()
opt.clear_grad()
if batch_id!=0 and batch_id%10 == 0:
Batch = Batch+10
Batchs.append(Batch)
all_train_loss.append(loss.numpy()[0])
print("epoch{},step:{},train_loss:{}".format(epochs,batch_id,loss.numpy()[0]))
paddle.save(model.state_dict(),"UCIHousingDNN")
draw_train_loss(Batchs,all_train_loss)
para_state = paddle.load("UCIHousingDNN")
model = MyDNN()
model.eval()
model.set_state_dict(para_state)
losses = []
for batch_id,data in enumerate(eval_loader()):
feature = data[0]
label = data[1]
predict = model(feature)
loss = mse_loss(predict,label)
losses.append(loss.numpy()[0])
avg_loss = np.mean(losses)
print(avg_loss)
draw_infer_result(label,predict)
代码
## 深度学习框架
import paddle
import numpy as np
import os
import matplotlib.pyplot as plt
## 绘图
Batch = 0
Batchs = []
all_train_accs = []
def draw_train_acc(Batchs,train_accs):
title = "training accs"
plt.title(title)
plt.xlabel("batch")
plt.ylabel("acc")
plt.plot(Batchs, train_accs, color = 'green', label = 'training accs')
plt.legend()
plt.grid()
plt.show()
all_train_loss = []
def draw_train_loss(Batchs,train_loss):
title = "training loss"
plt.title(title)
plt.xlabel("batch")
plt.ylabel("loss")
plt.plot(Batchs, train_loss, color = 'red', label = 'training loss')
plt.legend()
plt.grid()
plt.show()
## 绘制真实值与预测值的对比图
def draw_infer_result(groud_truths, infer_results):
title = 'Boston'
plt.title(title)
x = np.arange(1,20)
y = x
plt.plot(x,y);
plt.xlabel("ground truth")
plt.ylabel("infer result")
plt.scatter(groud_truths,infer_results,color='green',label='training cost')
plt.grid()
plt.show()
'''
数据集加载
'''
train_dataset = paddle.text.datasets.UCIHousing(mode="train")
eval_dataset = paddle.text.datasets.UCIHousing(mode="test")
train_loader = paddle.io.DataLoader(train_dataset,batch_size=32, shuffle=True)
eval_loader = paddle.io.DataLoader(eval_dataset,batch_size=8,shuffle=False)
print(train_dataset[1])
'''
核心
网络搭建
'''
class MyDNN(paddle.nn.Layer):
def __init__(self):
super(MyDNN, self).__init__()
#self.linear1 = paddle.nn.Linear(13,1,None) #全连接层,paddle.nn.Linear(in_features,out_features,weight)
self.linear1 = paddle.nn.Linear(13, 32, None)
self.linear2 = paddle.nn.Linear(32, 64, None)
self.linear3 = paddle.nn.Linear(64, 32, None)
self.linear4 = paddle.nn.Linear(32, 1, None)
def forward(self, inputs): ## 传播函数
x = self.linear1(inputs)
x = self.linear2(x)
x = self.linear3(x)
x = self.linear4(x)
return x
'''
网络训练与测试
'''
## 实例化
model = MyDNN()
model.train()
mse_loss = paddle.nn.MSELoss()
opt = paddle.optimizer.SGD(learning_rate=0.001, parameters=model.parameters())
epochs_num = 100
for epochs in range(epochs_num):
for batch_id,data in enumerate(train_loader()):
feature = data[0]
label = data[1]
predict = model(feature)
loss = mse_loss(predict, label)
loss.backward()
opt.step()
opt.clear_grad()
if batch_id!=0 and batch_id%10 == 0:
Batch = Batch+10
Batchs.append(Batch)
all_train_loss.append(loss.numpy()[0])
print("epoch{},step:{},train_loss:{}".format(epochs,batch_id,loss.numpy()[0]))
paddle.save(model.state_dict(),"UCIHousingDNN")
draw_train_loss(Batchs,all_train_loss)
para_state = paddle.load("UCIHousingDNN")
model = MyDNN()
model.eval()
model.set_state_dict(para_state)
losses = []
for batch_id,data in enumerate(eval_loader()):
feature = data[0]
label = data[1]
predict = model(feature)
loss = mse_loss(predict,label)
losses.append(loss.numpy()[0])
avg_loss = np.mean(losses)
print(avg_loss)
draw_infer_result(label,predict)
结果展示
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:【深度学习】DNN房价预测 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 