一、函数
函数:是组织好的,可重复使用的,用来实现特定功能的代码段。
优点:
- 可供重复利用的代码段
- 提高程序的复用性
- 减少重复性代码
- 提高开发效率
1.定义
def func1():
print("函数")
return 1
注意
参数、返回值可以省略
返回值可以有多个(后续说)
2.参数
- 可以不传参;可以传入多个参数:使用逗号分隔开
- 函数定义中的参数,称之为形式参数
- 函数调用中的参数,称之为实际参数
- 传入参数的时候,要和形式参数一一对应,逗号隔开;也可以以key-value形式传入
3.返回值
返回值可以有多个,也可以返回None
4.说明
def func2():
print("我是一个函数")
return 1
使用时,当鼠标悬浮函数时出现提示
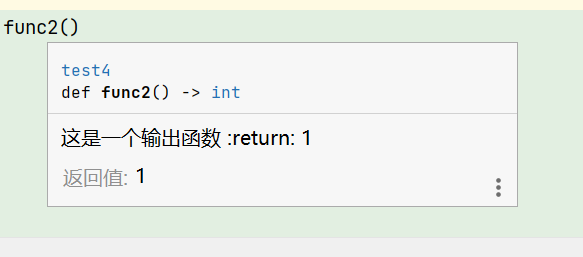

5.嵌套执行
如果函数A中,调用了另外一个函数B,那么先把函数B中的任务都执行完毕之后才会回到上次 函数A执行的位置

6.作用域
变量作用域指的是变量的作用范围
下图num变量为testA()函数的局部变量

使用 global关键字 可以在函数内部声明变量为全局变量

二、数据容器
Python中的数据容器:
一种可以容纳多份数据的数据类型,容纳的每一份数据称之为1个元素
每一个元素,可以是任意类型的数据,如字符串、数字、布尔等。
分为5类,分别是:
列表(list)、元组(tuple)、字符串(str)、集合(set)、字典(dict)
1.列表序列
基本语法
# 定义变量,内部数据类型可以不同;支持嵌套
list = [1,2,3,"gyb"]
# 空列表
list = []
list = list()
下标索引
1.正常顺序

name_list = ["郜宇博","123", "456"]
# 使用下标索引取出列表内元素
name1 = name_list[0]
print(name1)
2.反向索引,也就是从后向前:从-1开始,依次递减(-1、-2、-3......)

3.嵌套列表(二维)
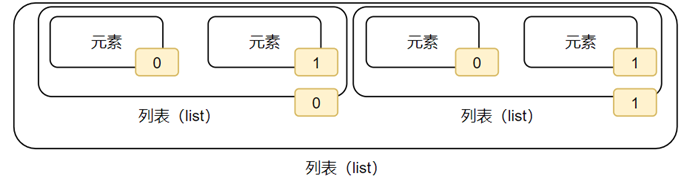
# 2维嵌套列表
my_list = [[1,2,3],[4,5,6]]
# 获取其中的一个元素
num = my_list[0][0]
常用方法
| 编号 | 使用方式 | 作用 |
|---|---|---|
| 1 | 列表.append(元素) | 向列表中追加一个元素 |
| 2 | 列表.extend(容器) | 将数据容器的内容依次取出,追加到列表尾部 |
| 3 | 列表.insert(下标, 元素) | 在指定下标处,插入指定的元素 |
| 4 | del 列表[下标] | 删除列表指定下标元素 |
| 5 | 列表.pop(下标) | 删除列表指定下标元素 |
| 6 | 列表.remove(元素) | 从前向后,删除此元素第一个匹配项 |
| 7 | 列表.clear() | 清空列表 |
| 8 | 列表.count(元素) | 统计此元素在列表中出现的次数 |
| 9 | 列表.index(元素) | 查找指定元素在列表的下标 找不到报错ValueError |
| 10 | len(列表) | 统计容器内有多少元素 |
# 举例
# 插入元素:
# 语法:列表.insert(下标, 元素),在指定的下标位置,插入指定的元素
my_list = [1, 2, 3]
# 在第1个索引位,插入0元素
my_list.insert(1,0)
print(my_list)

特点
- 可以容纳多个元素(上限为2**63-1个)
- 可以容纳不同类型的元素(混装)
- 数据是有序存储的(有下标序号)
- 允许重复数据存在
- 可以修改(增加或删除元素等)
2.元组序列
列表是可以修改的。
元组一旦定义完成,就不可修改
基本语法
# 定义元组使用小括号
my_tuple = (1, 2, 3, 4)
# 不同元素类型
my_tuple = (1, "gy")
# 嵌套
my_tuple = ((1,2,3),(4,5,6))
索引方式与列表相同
常用方法
因为不能修改,所以操作少
| 编号 | 方法 | 作用 |
|---|---|---|
| 1 | index() | 查找某个数据,如果数据存在返回对应的下标,否则报错 |
| 2 | count() | 统计某个数据在当前元组出现的次数 |
| 3 | len(元组) | 统计元组内的元素个数 |
注意
不可以修改元组的内容,但是可以修改元组内列表中的元素,如下
# 可以修改列表中元素
my_t = (1, 2, ["gg","cc"])
# 修改
my_t[2][1] = "aa"
print(my_t)

3.字符串序列
同元组一样,字符串是一个:无法修改的数据容器。不可变
因此当修改字符串中字符时,会获得一个新字符串
常用方法
| 编号 | 操作 | 说明 |
|---|---|---|
| 1 | 字符串[下标] | 根据下标索引取出特定位置字符 |
| 2 | 字符串.index(字符串) | 查找给定字符的第一个匹配项的下标 |
| 3 | 字符串.replace(字符串1, 字符串2) | 将字符串内的全部字符串1,替换为字符串2 不会修改原字符串,而是得到一个新的 |
| 4 | 字符串.split(字符串) | 按照给定字符串,对字符串进行分隔 不会修改原字符串,而是得到一个新的列表 |
| 5 | 字符串.strip() 字符串.strip(字符串) | 移除首尾的空格和换行符或指定字符串 |
| 6 | 字符串.count(字符串) | 统计字符串内某字符串的出现次数 |
| 7 | len(字符串) | 统计字符串的字符个数 |
4.序列的切片
序列是指:内容连续、有序,可使用下标索引的一类数据容器
序列支持切片
切片:从一个序列中,取出一个子序列
语法:序列[起始下标:结束下标:步长] -----》 左闭右开区间
- 起始下标表示从何处开始,可以留空,留空视作从头开始
- 结束下标(不含)表示何处结束,可以留空,留空视作截取到结尾
- 步长表示,依次取元素的间隔
my_list = [1, 2, 3, 4, 5]
new_list = my_list[1:4] # 下标1开始,下标4(不含)结束,步长1
print(new_list) # 结果:[2, 3, 4]
my_tuple = (1, 2, 3, 4, 5)
new_tuple = my_tuple[:] # 从头开始,到最后结束,步长1
print(new_tuple) # 结果:(1, 2, 3, 4, 5)
my_list = [1, 2, 3, 4, 5]
new_list = my_list[::2] # 从头开始,到最后结束,步长2
print(new_list) # 结果:[1, 3, 5]
my_str = "12345"
new_str = my_str[::-1] # 从头(最后)开始,到尾结束,步长-1(倒序)
print(new_str) # 结果:"54321"
5.set集合
列表和元组都支持重复元素,因此需要不支持的容器---》set
最主要的特点就是:不支持元素的重复(自带去重功能)、并且内容无序
定义语法
# 定义
nums = {1,2,3,5,5,2}
print(nums)

常用方法
| 编号 | 操作 | 说明 |
|---|---|---|
| 1 | 集合.add(元素) | 集合内添加一个元素 |
| 2 | 集合.remove(元素) | 移除集合内指定的元素 |
| 3 | 集合.pop() | 从集合中随机取出一个元素 |
| 4 | 集合.clear() | 将集合清空 |
| 5 | 集合1.difference(集合2) | 得到一个新集合,内含2个集合的差集 原有的2个集合内容不变 |
| 6 | 集合1.difference_update(集合2) | 在集合1中,删除集合2中存在的元素 集合1被修改,集合2不变 |
| 7 | 集合1.union(集合2) | 得到1个新集合,内含2个集合的全部元素 原有的2个集合内容不变 |
| 8 | len(集合) | 得到一个整数,记录了集合的元素数量 |
6.字典集合
类似于Java的map集合
以键值对的形式存储数据:key:value
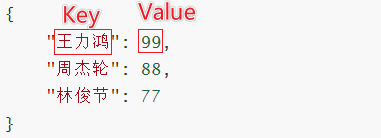
基本定义
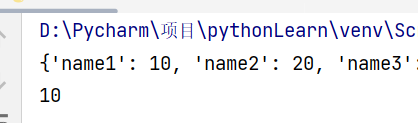
# 定义,支持嵌套
my_dictionary = {"name1":10,"name2":20,"name3":30}
print(my_dictionary)
# 字典值的获取,通过key获取
print(my_dictionary["name1"])
常用方法
| 编号 | 操作 | 说明 |
|---|---|---|
| 1 | 字典[Key] | 获取指定Key对应的Value值 |
| 2 | 字典[Key] = Value | 添加或更新键值对 |
| 3 | 字典.pop(Key) | 取出Key对应的Value并在字典内删除此Key的键值对 |
| 4 | 字典.clear() | 清空字典 |
| 5 | 字典.keys() | 获取字典的全部Key,可用于for循环遍历字典 |
| 6 | len(字典) | 计算字典内的元素数量 |
7.容器的通用操作
| 功能 | 描述 |
|---|---|
| 通用for循环 | 遍历容器(字典是遍历key) |
| max() | 容器内最大元素 |
| min() | 容器内最小元素 |
| len() | 容器元素个数 |
| list() | 转换为列表 |
| tuple() | 转换为元组 |
| str() | 转换为字符串 |
| set() | 转换为集合 |
| sorted(序列, [reverse=True]) | 排序,reverse=True表示降序 得到一个排好序的列表 |
三、函数进阶
1.返回值
如果一个函数要有多个返回值,该如何书写,如下
def func1():
return 1,2
x, y = func1()
# 使用x,y接受返回值
print(x)
print(y)

2.参数
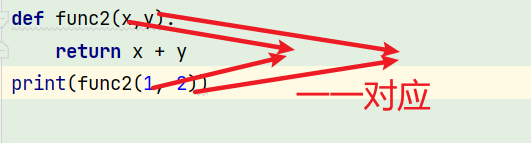
位置参数
x与1对应,y与2对应,根据位置对应
关键字参数
在实参传入时,将形参的关键字填写
注意:
函数调用时,如果有位置参数时,位置参数必须在关键字参数的前面,但关键字参数之间不存在先后顺序
def func2(name, age):
print(f"name={name},age={age}")
func2(name="gyb",age=21)

缺省参数
缺省参数也叫默认参数,用于定义函数,为参数提供默认值,调用函数时可不传该默认参数的值
(注意:所有位置参数必须出现在默认参数前,包括函数定义和调用)
def func2(name, age=19):
print(f"name={name},age={age}")
func2(name="gyb")
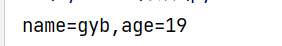
不定长参数
不定长参数也叫可变参数. 用于不确定调用的时候会传递多少个参数(不传参也可以)的场景.
# 定义 *args放入形参中 代表 不定长参数
def func2(*args):
print(args)
func2("gyb",2)

此时将多个参数加入到了 元组序列 中,转为元组了(相当于*arg就是元组类型的形参)
# 定义 **args放入形参中 代表 不定长参数为字典集合
def func2(**args):
print(args)
func2(name="gyb",age=11,g="m")

此时将多个参数传入转为字典集合了(相当于**arg就是字典类型的形参)
函数作为参数
这是一种,计算逻辑的传递,而非数据的传递。

匿名函数
函数的定义中
- def关键字,可以定义带有名称的函数
- lambda关键字,可以定义匿名函数(无名称)
def func(compute):
return compute(1,2)
#在调用func时,传入的实参为;lambda x, y: x + y ------》代表一个匿名函数
print(func(lambda x, y: x + y))
四、文件操作
0.基本介绍
语法
open(name, mode, encoding)
- name:是要打开的目标文件名的字符串(可以包含文件所在的具体路径)。
- mode:设置打开文件的模式(访问模式):只读、写入、追加等。
- encoding:编码格式(推荐使用UTF-8)
mode常用的三种基础访问模式
| 模式 | 描述 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,原有内容会被删除。 如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,新的内容将会被写入到已有内容之后。 如果该文件不存在,创建新文件进行写入。 |
1.文件的读取
# 打开文件(f为文件对象,后续学)
f = open('python.txt', 'r', encoding=”UTF-8)
content = f.readline()
print(f'第一行:{content}')
# 用完后关闭
f.close()
方法操作
| 操作 | 功能 |
|---|---|
| 文件对象 = open(file, mode, encoding) | 打开文件获得文件对象 |
| 文件对象.read(num) | 读取指定长度字节 不指定num读取文件全部 |
| 文件对象.readline() | 读取一行 |
| 文件对象.readlines() | 读取全部行,得到列表 |
| for line in 文件对象 | for循环文件行,一次循环得到一行数据 |
| 文件对象.close() | 关闭文件对象 |
| with open() as f | 通过with open语法打开文件,可以自动关闭 |
2.文件的写入
# 1. 打开文件
f = open('python.txt', 'w')
# 2.文件写入
f.write('hello world')
# 3. 内容刷新
f.flush()
注意:
直接调用write,内容并未真正写入文件,而是会积攒在程序的内存中,称之为缓冲区
当调用flush的时候,内容会真正写入文件
这样做是避免频繁的操作硬盘,导致效率下降(攒一堆,一次性写磁盘)
文件如果不存在,使用”w”模式,会创建新文件
文件如果存在,使用”w”模式,会将原有内容清空
3.文件的追加
# 1. 打开文件,通过a模式打开即可
f = open('python.txt', 'a')
# 2.文件写入
f.write('hello world')
# 3. 内容刷新
f.flush()
注意:
a模式,文件不存在会创建文件
a模式,文件存在会在最后,追加写入文件
五、异常
当检测到一个错误时,Python解释器就无法继续执行了,反而出现了一些错误的提示,这就是所谓的“异常”, 也就是我们常说的BUG
1.捕获
捕获异常的作用在于:提前假设某处会出现异常,做好提前准备,当真的出现异常的时候,可以有后续手段。
"""
try:
可能发生错误的代码
except:
如果出现异常执行的代码
"""
# 需求:尝试以`r`模式打开文件,如果文件不存在,则以`w`方式打开。
try:
f = open('linux.txt', 'r')
except:
f = open('linux.txt', 'w')
# 需求:未定义捕获
try:
print(name)
except NameError as e:
print('name变量名称未定义错误')
注意:
① 如果尝试执行的代码的异常类型和要捕获的异常类型不一致,则无法捕获异常。
② 一般try下方只放一行尝试执行的代码。
捕获多个异常
try:
print(1/0)
except (NameError, ZeroDivisionError):
print('ZeroDivision错误...')

捕获并输出
try:
print(num)
except (NameError, ZeroDivisionError) as e:
print(e)

捕获所有异常
try:
print(name)
except Exception as e:
print(e)
2.异常else
else表示的是如果没有异常要执行的代码
try:
print(1)
except Exception as e:
print(e)
else:
print('我是else,是没有异常的时候执行的代码')

3.异常的finally
finally表示的是无论是否异常都要执行的代码,例如关闭文件
try:
f = open('test.txt', 'r')
except Exception as e:
f = open('test.txt', 'w')
else:
print('没有异常,真开心')
finally:
f.close()
4.传递性
当函数func01中发生异常, 并且没有捕获处理这个异常的时候, 异常
会传递到函数func02, 当func02也没有捕获处理这个异常的时候
main函数会捕获这个异常, 这就是异常的传递性
注意:
当所有函数都没有捕获异常的时候, 程序就会报错

六、模块
Python 模块(Module),是一个 Python 文件,以 .py 结尾. 模块能定义函数,类和变量,模块里也能包含可执行的代码.
作用:python中有很多各种不同的模块, 每一个模块都可以帮助我们快速的实现一些功能,
1.导入
模块在使用前需要先导入,导入的语法如下:

常用的组合形式如:
- import 模块名
- from 模块名 import 类、变量、方法等
- from 模块名 import *
- import 模块名 as 别名
- from 模块名 import 功能名 as 别名
"""
import 模块名
import 模块名1,模块名2
模块名.功能名()
"""
# 1.import模块名
# 导入时间模块
import time
print("开始")
# 让程序睡眠1秒(阻塞)
time.sleep(1)
print("结束")
# 2.from 模块名 import 功能名
# 导入时间模块中的sleep方法
from time import sleep
print("开始")
# 让程序睡眠1秒(阻塞)
sleep(1)
print("结束")
2.自定义模块
新建一个Python文件,别的模块就可以导入了
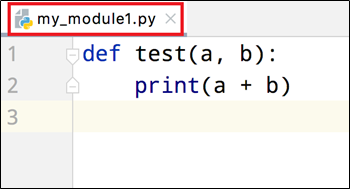
注意
在my_module1.py文件中添加测试代码test(1,1),那么在别的模块导入时,会自动执行test方法
def test(a, b):
print(a + b)
test(1, 1)
如果想不执行test方法,则需要在被导入的模块中加入if name == 'main': 这句话的意思是只有从本程序执行(右键执行、右上角执行)时才调用
def test(a, b):
print(a + b)
# 只在当前文件中调用该函数,其他导入的文件内不符合该条件,则不执行test函数调用
if __name__ == '__main__':
test (1, 1)
当导入多个模块的时候,且模块内有同名功能. 当调用这个同名功能的时候,调用到的是后面导入的模块的功能
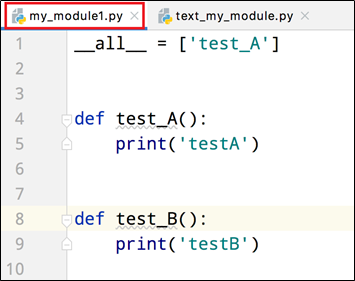
如果一个模块文件中有__all__变量,当使用from xxx import *导入时,只能导入这个列表中的元素
七、包
如果Python的模块太多了,就可能造成一定的混乱,那么使用包管理
- 从物理上看,包就是一个文件夹,在该文件夹下包含了一个 init.py 文件,该文件夹可用于包含多个模块文件
- 从逻辑上看,包的本质依然是模块
创建包:右键新建软件包;或者创建目录,加入__init__.py
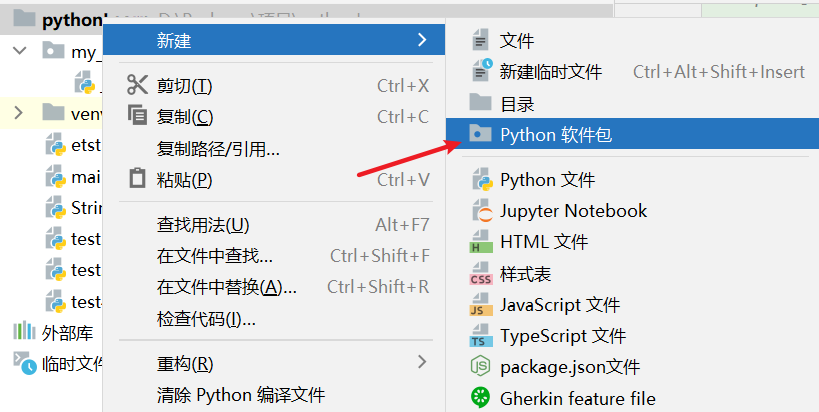
1.导入包
"""
方式一:
import 包名.模块名
调用:包名.模块名.目标
方式二:
from 包名 import 模块名
调用:模块名.目标
"""
2.安装第三方包
一、Pip方式
只需要使用Python内置的pip程序即可
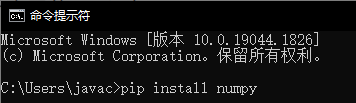
**pip****的网络优化
我们可以通过如下命令,让其连接国内的网站进行包的安装:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 包名称

https://pypi.tuna.tsinghua.edu.cn/simple 是清华大学提供的一个网站,可供pip程序下载第三方包
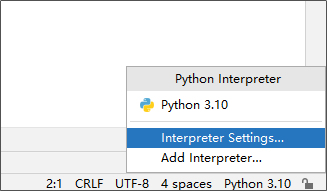
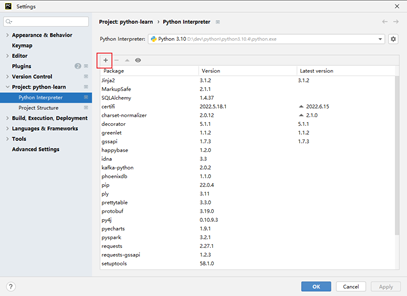
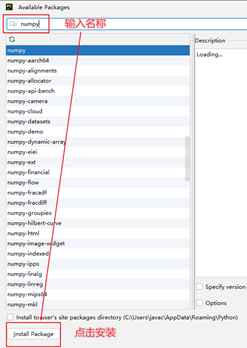
二、PyCharm方式
PyCharm也提供了安装第三方包的功能
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:Python学习三天计划-2 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 