这几天想搞到一个三阶魔方排行榜的数据,官网居然不能导出Excel文件,刚好这几天学了个爬虫,于是爬着玩玩(应该不会进去)。
1 目标网站:
https://www.worldcubeassociation.org/results/rankings/333/average
2 准备库
## 准备的库
import pandas as pd # 数据分析库
import requests # 用于发送 HTTP 请求
from lxml import etree # 可以将xml格式的文件转为树状结构
3 申请访问
如下图:点击 “网络” => “文档” => “average”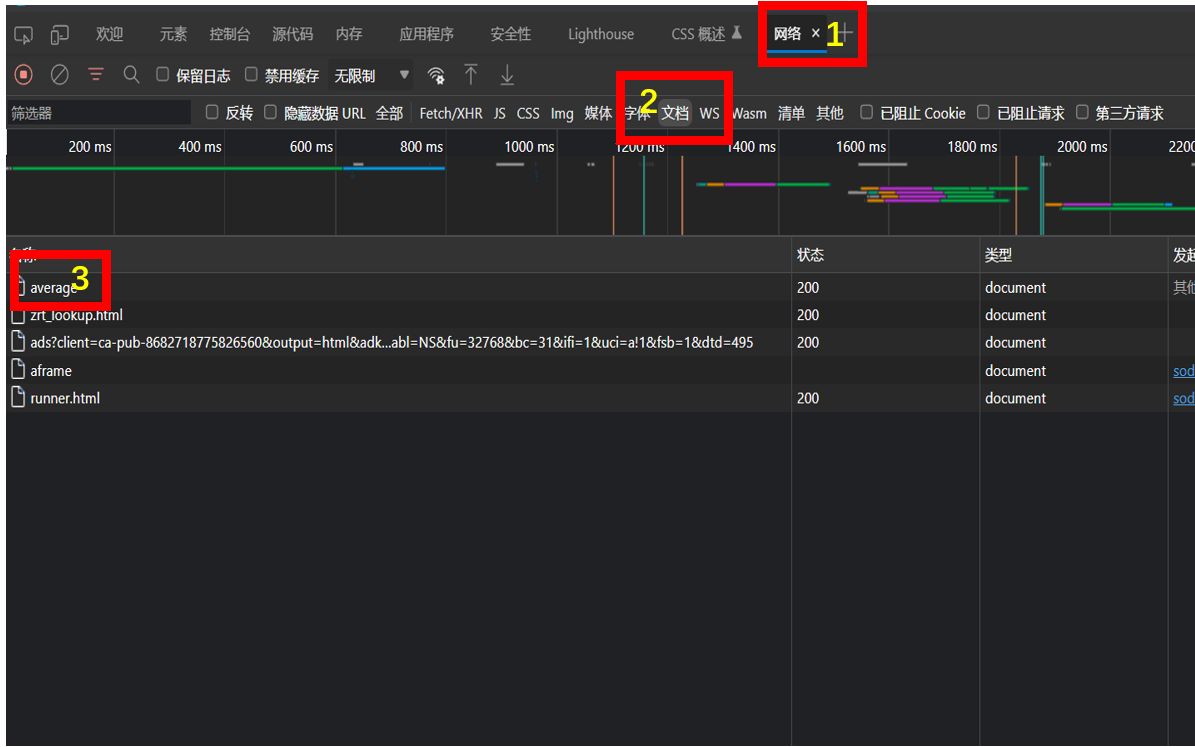

点击预览,就能看到排行榜的数据信息. 我们要爬的数据就在这里
点击“标头”,获取 url 和 标头
## 标头
headers = 'user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)'
## 访问地址
url = 'https://www.worldcubeassociation.org/results/rankings/333/average'
r = requests.get(url,headers)
# r.text xml格式 又臭又长就不展示了
data_ml = etree.HTML(r.text) #转成树状结构
3 寻找规律
接下来就是无聊的寻找环节,点击“元素”
经过不懈的努力,终于看到了 Tymon 的大名,意味着我找到了排行榜的数据。。接下来的工作就轻松了
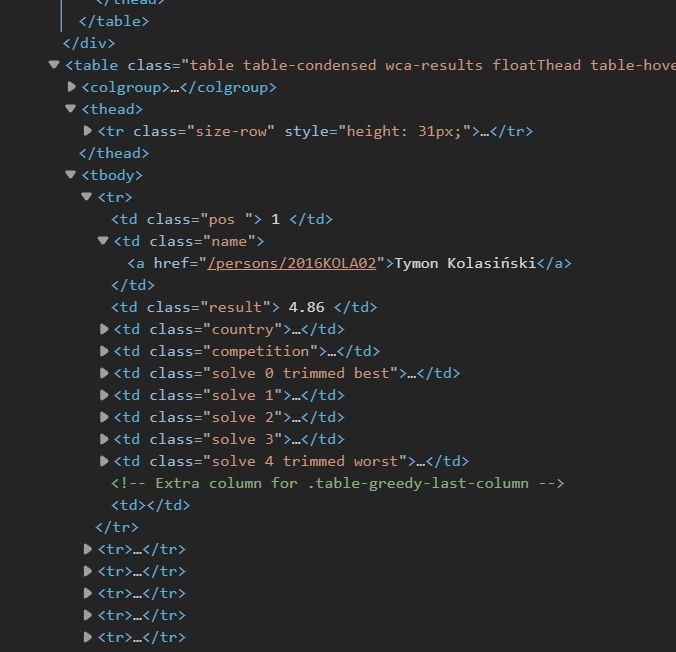
3.1 获取选手排名列表
(话说排行榜的rank不就是1-100的自然数序列么,其实只要 range(1,101) 就行。。)
先看下世界第一 Tymon 的世界排名。。
在目标位置右击,赋值完整的XPath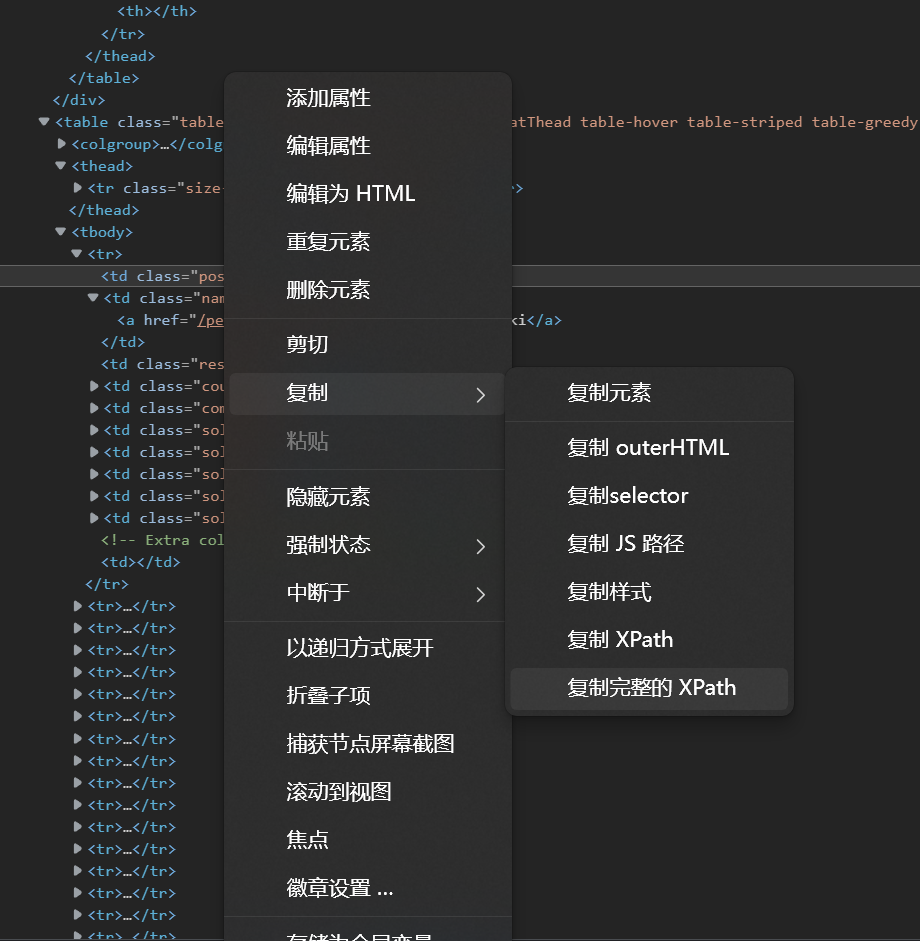
data_ml.xpath('/html/body/main/div[3]/div[2]/div/div/table/tbody/tr[1]/td[1]/text()')[0] #第一位选手的排名
[out]: '1'
这说明世界第一的Tymon的世界排名是1,太棒了完全吻合
再看看世界第二的 MaxPark,同样的赋值 XPath 信息
data_ml.xpath('/html/body/main/div[3]/div[2]/div/div/table/tbody/tr[2]/td[1]/text()')[0] #第二位选手的排名
[out]: '2'
又完美匹配,同时找到规律,tr[k]就是第k名选手的信息。按照这个规律我们可以得到前100名选手的排名序列:
## 爬取前一百名选手的排名序列
rank_cuber = []
for i in range(100):
rank_cuber.append(
int(data_ml.xpath('/html/body/main/div[3]/div[2]/div/div/table/tbody/tr'+'['+str(i+1) + ']'+'/td[1]/text()')[0])
)
# rank_cuber
3.2 获取选手姓名列表
有了上一个试验,下面就得心应手了。同样地,我们先看下世界排名第一Tymon的姓名
data_ml.xpath('/html/body/main/div[3]/div[2]/div/div/table/tbody/tr[1]/td[2]/a/text()') #第一位选手的姓名
[out]: ['Tymon Kolasiński']
完美吻合,下面只需改tr[k]就能知道第k名选手的姓名了。不妨试验一下,中国第一的许瑞航的世界排名是4,我们尝试爬取第4名选手的姓名信息
data_ml.xpath('/html/body/main/div[3]/div[2]/div/div/table/tbody/tr[4]/td[2]/a/text()') #第一位选手的姓名
[out]: ['Ruihang Xu (许瑞航)']
完全正确,下面写个循环爬取前100名选手的姓名
name_cuber = []
for i in range(100):
name_cuber.append(
data_ml.xpath('/html/body/main/div[3]/div[2]/div/div/table/tbody/tr'+'['+str(i+1)+']'+'/td[2]/a/text()')[0]
)
# name_cuber
3.3 爬取选手的国籍
过程和上面完全一样,直接上代码
country_cuber = []
for i in range(100):
country_cuber.append(
data_ml.xpath('/html/body/main/div[3]/div[2]/div/div/table/tbody/tr'+'['+str(i+1)+']'+'/td[4]/text()')[1]
)
# country_cuber
3.4 爬取成绩
WCA赛事中,选手每一轮都会有五次复原,从而会有五个成绩,这五次成绩的去尾平均就是该选手本轮比赛的平均成绩。下面我将爬取排名前100名选手的最佳的五次成绩和平均成绩。
过程也差不多,不多赘述,直接上代码
solve_cuber = [] # 五次成绩
for i in range(100):
l = []
# 取出五次成绩
for j in range(5):
l.append(
data_ml.xpath('/html/body/main/div[3]/div[2]/div/div/table/tbody/tr'+'['+str(i+1)+']'+'/td'+'['+str(6+j)+']'+'/text()')[0]
)
solve_cuber.append(l)
# solve_cuber
solve_average_cuber = [] #平均成绩
for i in range(100):
solve_average_cuber.append(
data_ml.xpath('/html/body/main/div[3]/div[2]/div/div/table/tbody/tr'+'['+str(i+1)+']'+'/td[3]/text()')[0]
)
# solve_average_cuber
注:DNF说明该选手这把成绩因某种原因无效
整合成 excel 文件
# 合成数据框
cuber_data = pd.DataFrame({
'排名' : rank_cuber,
'姓名' : name_cuber,
'国籍' : country_cuber,
'五次成绩' : solve_cuber,
'去尾平均' : solve_average_cuber,
})
cuber_data.head()
| 排名 | 姓名 | 国籍 | 五次成绩 | 去尾平均 | |
|---|---|---|---|---|---|
| 0 | 1 | Tymon Kolasiński | Poland | [4.02, 4.68, 5.33, 4.56, 5.59] | 4.86 |
| 1 | 2 | Max Park | United States | [4.88, 5.70, 5.56, 4.53, 4.80] | 5.08 |
| 2 | 3 | Matty Hiroto Inaba | United States | [5.23, 4.84, 6.48, 5.68, 4.74] | 5.25 |
| 3 | 4 | Ruihang Xu (许瑞航) | China | [5.48, 5.52, 5.45, 4.06, 7.51] | 5.48 |
| 4 | 5 | Feliks Zemdegs | Australia | [7.16, 5.04, 4.67, 6.55, 4.99] | 5.53 |
# 导出为excel文件
cuber_data.to_excel("前100名选手成绩.xlsx")
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:娱乐向:用 Python 爬 WCA(世界魔方协会)三阶魔方排行榜前一百名选手的成绩信息 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 