前几篇都是手动录入或随机函数产生的数据。实际有许多类型的文件,以及许多方法,用它们从文件中提取数据来图形化。
比如之前python基础(12)介绍打开文件的方式,可直接读取文件中的数据,扩大了我们的数据来源。下面详细介绍从文件中加载数据。
一、使用内置的 csv 模块加载CSV文件
CSV文件是一种特殊的文本文件,文件中的数据以逗号作为分隔符,很适合进行数据的解析。先用excle建立如下表格和数据,另存为csv格式文件,放到代码目录下。
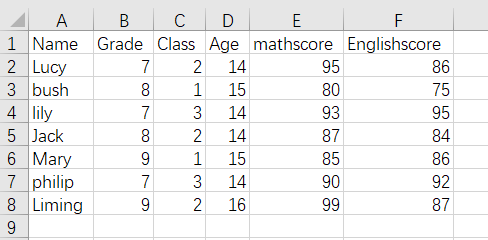

包含在Python标准库中自带CSV 模块,我们只需要import进来就能使用。比如我们需要将上面的CSV文件都打印出来,代码 如下:
import csv #import csv 用来导入csv模块 filename = 'E:WorkSpacepythoncodingscore.csv' #文件保存的绝对路径,如果在代码目录文件下,可以直接用文件名 with open(filename) as file_csv: #是不是忘记了如何打开文件?打开文件,并将结果文件对象存储在file_csv中 reader = csv.reader(file_csv) #直接调读取 用csv.read()读取文件内容 for row in reader: # 用for循环打印每一行 print(row)
运行结果如下:
['Name', 'Grade', 'Class', 'Age', 'mathscore', 'Englishscore'] ['Lucy', '7', '2', '14', '95', '86'] ['bush', '8', '1', '15', '80', '75'] ['lily', '7', '3', '14', '93', '95'] ['Jack', '8', '2', '14', '87', '84'] ['Mary', '9', '1', '15', '85', '86'] ['philip', '7', '3', '14', '90', '92'] ['Liming', '9', '2', '16', '99', '87']
1、打印文件头及其位置
读入文件,是为了获取其中的数据,需要将相关信息进行分离,先看看如何读出头即文件的第一行, next()返回文件中的下一行。
import csv #import csv 用来导入csv模块 filename = 'E:WorkSpacepythoncodingscore.csv' #文件保存的绝对路径 with open(filename) as file_csv: #是不是忘记了如何打开文件?打开文件,并将结果文件对象存储在file_csv中 reader = csv.reader(file_csv) #直接调读取 用csv.read()读取文件内容 header_row = next(reader) #模块csv包含函数 next() ,调用它并将阅读器对象传递给它时,它将返回文件中的下一行。 #调用了next()一次,因此得到的是文件的第一行,其中包含文件头
#for row in reader: # 用for循环打印每一行
# print(row)
for index, column_header in enumerate(header_row): #对列表调用了enumerate()来获取每个元素的索引及其值 print(index, column_header)
运行后的结果如下所示:
0 Name 1 Grade 2 Class 3 Age 4 mathscore 5 Englishscore
提取其中索引,即name的索引为0,Grade的索引为1,知道了索引便可以读取其中的任何数据,比如我们要打印出mathscore,索引为4,于是代码如下:
scores =[] 定义一个空的list for row in reader: scores.append(int(row[4])) #读取的文件,默认为字符串,用int()转换为数字。 print(scores)
运行结果:
[95, 80, 93, 87, 85, 90, 99]
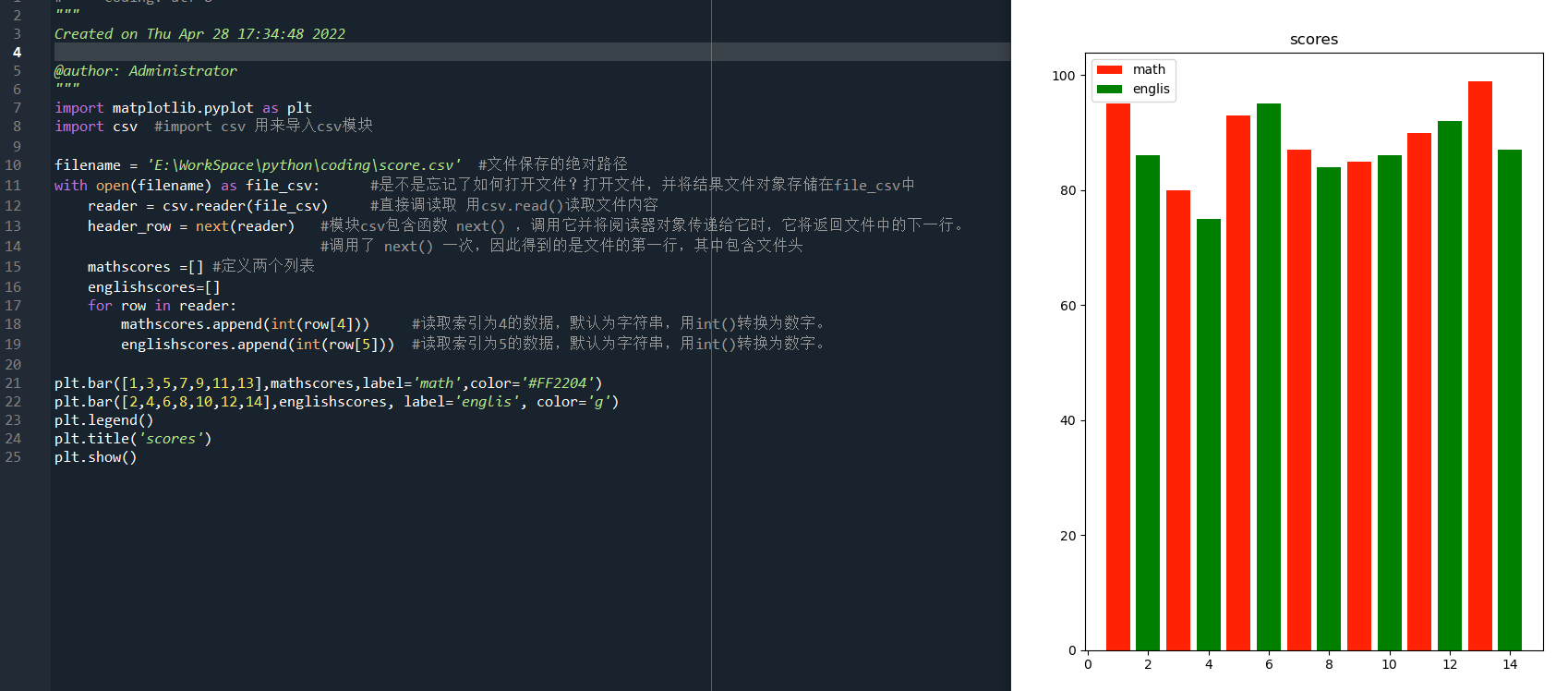
接下来,制作图表展示一下,先把mathscore和englishscore分数做个柱状对比。代码如下:
import matplotlib.pyplot as plt import csv #import csv 用来导入csv模块 filename = 'E:WorkSpacepythoncodingscore.csv' #文件保存的绝对路径 with open(filename) as file_csv: #是不是忘记了如何打开文件?打开文件,并将结果文件对象存储在file_csv中 reader = csv.reader(file_csv) #直接调读取 用csv.read()读取文件内容 header_row = next(reader) #模块csv包含函数 next() ,调用它并将阅读器对象传递给它时,它将返回文件中的下一行。 #调用了 next() 一次,因此得到的是文件的第一行,其中包含文件头 mathscores =[] #定义两个列表 englishscores=[] for row in reader: mathscores.append(int(row[4])) #读取索引为4的数据,默认为字符串,用int()转换为数字。 englishscores.append(int(row[5])) #读取索引为5的数据,用int()转换为数字。 plt.bar([1,3,5,7,9,11,13],mathscores,label='math',color='#FF2204') plt.bar([2,4,6,8,10,12,14],englishscores, label='englis', color='g') plt.legend() plt.title('scores') plt.show()
已将那些打印相关代码删除。看运行结果:
接下来,我们读取文件 ,并根据文件中的时间来绘制图表
新建一个年份的数据(真的是胡编乱造的数据),第一列是年份,第二列每年毕业的人数,第三列是每年申请人数,如图所示:
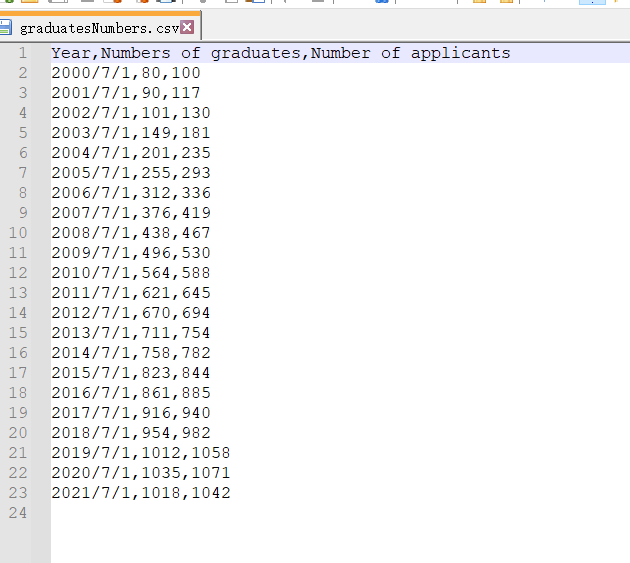
要求:
1,按年份分别显示出每年两者的人数,并用不同的颜色表示;
2、两者间也用其他颜色进行填充。
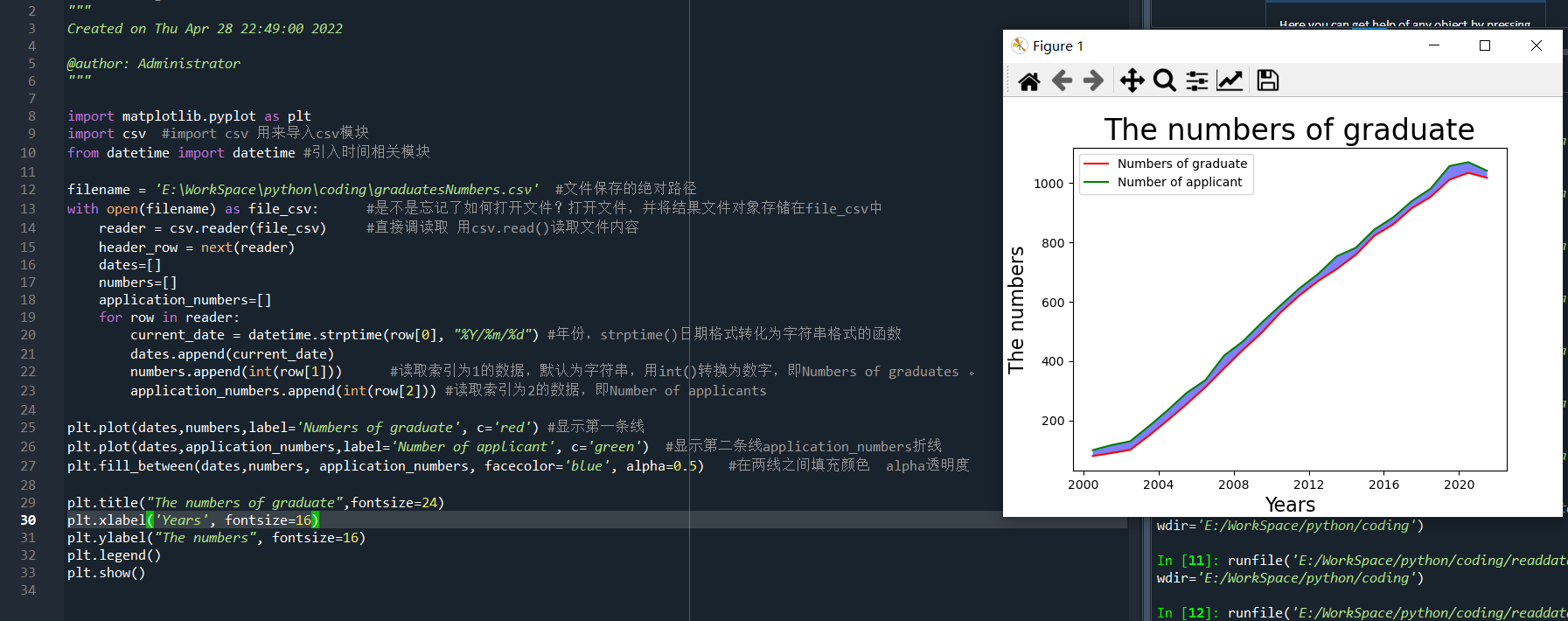
完成代码如下:
import matplotlib.pyplot as plt import csv #import csv 用来导入csv模块 from datetime import datetime #引入时间相关模块 filename = 'E:WorkSpacepythoncodinggraduatesNumbers.csv' #文件保存的绝对路径 with open(filename) as file_csv: #是不是忘记了如何打开文件?打开文件,并将结果文件对象存储在file_csv中 reader = csv.reader(file_csv) #直接调读取 用csv.read()读取文件内容 header_row = next(reader) dates=[] numbers=[] application_numbers=[] for row in reader: current_date = datetime.strptime(row[0], "%Y/%m/%d") #年份,strptime()日期格式转化为字符串格式的函数 dates.append(current_date) numbers.append(int(row[1])) #读取索引为1的数据,默认为字符串,用int()转换为数字,即Numbers of graduates 。 application_numbers.append(int(row[2])) #读取索引为2的数据,即Number of applicants plt.plot(dates,numbers,label='Numbers of graduate', c='red') #显示第一条线 plt.plot(dates,application_numbers,label='Number of applicant', c='green') #显示第二条线application_numbers折线 plt.fill_between(dates,numbers, application_numbers, facecolor='blue', alpha=0.5) #在两线之间填充颜色 alpha透明度 plt.title("The numbers of graduate",fontsize=24) plt.xlabel('Years', fontsize=16) plt.ylabel("The numbers", fontsize=16) plt.legend() plt.show()
实际运行结果如下:
除了直接读取文件外,数据还有众多其他来源,比如后期涉及的爬虫等。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:python数据可视化-matplotlib入门(6)-从文件中加载数据 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 