#QQ:502440275@qq.com
#本截图适合安康码截图,如需其他地区截图统计,可与我QQ或QQ邮箱联系
#1、在当前文件夹下创建imgs文件夹用于存放图片,图片格式.jpg
#2、在当前文件夹下创建“shuju.xlsx”的Excel用于存放统计结果
文件夹目录样式

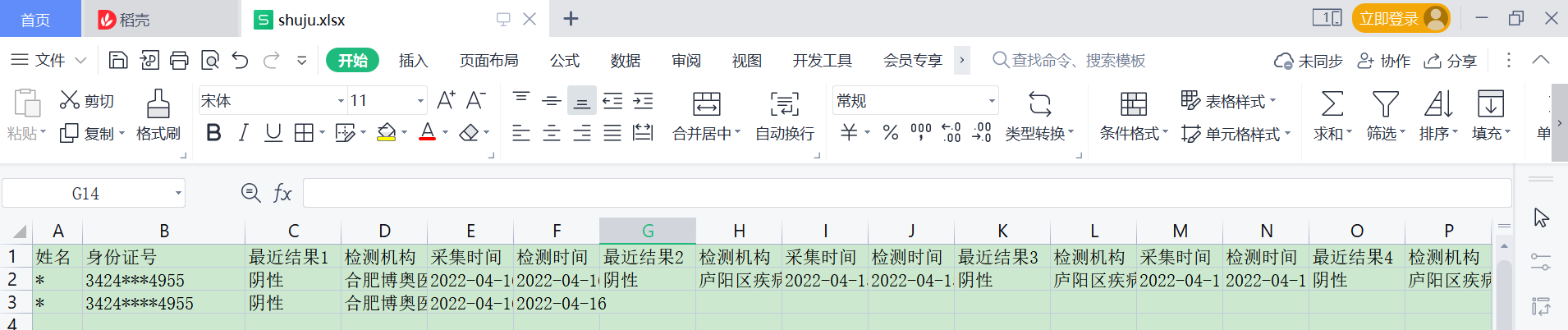
统计结果Excel样式
具体代码如下:
# @Time : 2022/4/19 22:00 # @Author : CFang # @File : hesuan_results.py # @Software: PyCharm #QQ:502440275@qq.com #本截图适合安康码截图,如需其他地区截图统计,可与我QQ或QQ邮箱联系 #1、在当前文件夹下创建imgs文件夹用于存放图片,图片格式.jpg #2、在当前文件夹下创建“shuju.xlsx”的Excel用于存放统计结果 #获得截图结果 def get_hesuan_res(path): #获得API的access_token import requests AK = '*******'#输入自己的百度智能云的AK和SK SK = '*******' # client_id 为官网获取的AK, client_secret 为官网获取的SK host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id='+AK+'&client_secret='+SK response = requests.get(host) if response: print(response.json()) print(response.json()['access_token']) # encoding:utf-8 #文字识别接口,可自己调整不同接口获得不同精度要求 import requests import base64 ''' 通用文字识别 ''' request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic" # 二进制方式打开图片文件 f = open(path, 'rb') img = base64.b64encode(f.read()) params = {"image":img} access_token = response.json()['access_token'] request_url = request_url + "?access_token=" + access_token headers = {'content-type': 'application/x-www-form-urlencoded'} response = requests.post(request_url, data=params, headers=headers) if response: # print (response.json()) # print(response.json()['words_result']) all_res = response.json()['words_result'] return all_res # for i in range(len(all_res)): # print(i,all_res[i]) # 对图片识别结果的数据清洗 all_lists_deals = [] def deal_datas(all_lists): all_lists_deal = [] if all_lists[5]['words'].split(":")[0] == "姓名": for i in range(5, len(all_lists)): print(i, all_lists[i]['words']) # ,all_lists_display[i]['words'] if all_lists[i]['words'] != '>' and all_lists[i]['words'] != '身份证件号码:': all_lists_deal.append(all_lists[i]['words']) all_lists_deal[0] = all_lists_deal[0].split(":")[1][:-1] # print(all_lists_deal) else: for i in range(6, len(all_lists)): print(i, all_lists[i]['words']) # ,all_lists_display[i]['words'] if all_lists[i]['words'] != '>': all_lists_deal.append(all_lists[i]['words']) all_lists_deal[0] = all_lists_deal[0].split(":")[1] all_lists_deal[1] = all_lists_deal[1].split(":")[1] # print(all_lists_deal) print(all_lists_deal) all_lists_deals.append(all_lists_deal) #获取文件夹imgs内的所有图片 import os def get_imlist(path): return [os.path.join(path,f) for f in os.listdir(path) if f.endswith('.jpg')] img_path = get_imlist("imgs") print(img_path) for path in img_path: all_lists = get_hesuan_res(path) deal_datas(all_lists) #保存识别清洗后的数据结果到“shuju.xlsx”表中 # -*- coding: UTF-8 -*- from openpyxl import load_workbook wb = load_workbook('shuju.xlsx') ws = wb['Sheet1'] row = ws.max_row+1 for j in range(len(all_lists_deals)): for i in range(len(all_lists_deals[j])): if len(all_lists_deals[j][i].split(":")) == 1: ws.cell(row+j,i+1).value = all_lists_deals[j][i] elif all_lists_deals[j][i].split(":")[0] == "检测机构" or all_lists_deals[j][i].split(":")[0] == "身份证件号码": ws.cell(row+j, i + 1).value = all_lists_deals[j][i].split(":")[1] else: ws.cell(row+j, i + 1).value = all_lists_deals[j][i].split(":")[1][:10] wb.save('shuju.xlsx')
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:python代码统计核酸检测结果截图 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 