循环神经网络(二)-极其详细的推导BPTT
首先明确一下,本文需要对RNN有一定的了解,而且本文只针对标准的网络结构,旨在彻底搞清楚反向传播和BPTT。
反向传播形象描述
什么是反向传播?传播的是什么?传播的是误差,根据误差进行调整。
举个例子:你去买苹果,你说,老板,来20块钱苹果(目标,真实值),老板开始往袋子里装苹果,感觉差不多了(预测),放称上一称,还差点(误差),又装了一个,还差点(调整一次之后的误差),又装了一个...迭代,直到20块钱。
注意每次都是根据误差来进行调整,这点谨记。
BPTT 剖析
RNN网络结构比较复杂,BPTT在梯度计算时也不同于常规。
不同1:权重共享,多个误差
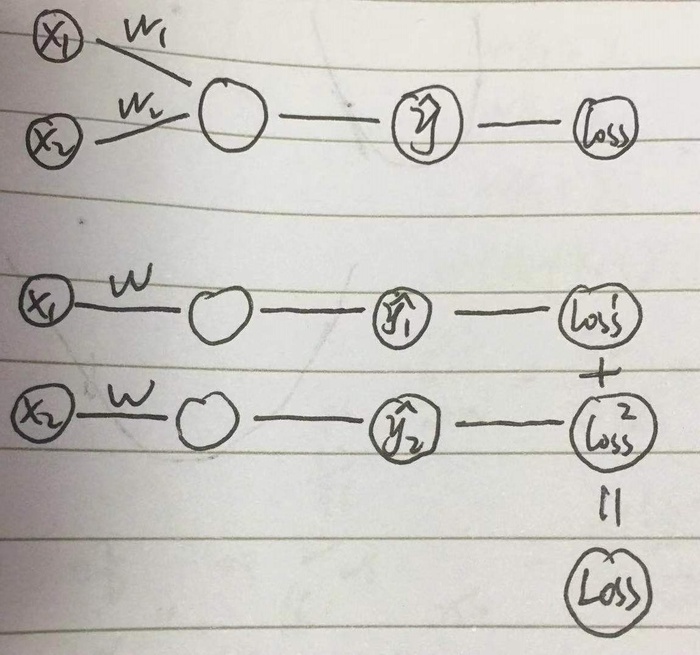

常规是误差分两条路传递,然后每条路分别算w,很容易理解
而权重共享时,一个权重,生成了2个误差,还有个总误差,到底用哪个?怎么反向?假设能反向回去,2个w,怎么处理?咋一想,好乱,
其实是这样的
1. 总误差,分误差,其实是一样的
2. 2个w,需要求和。
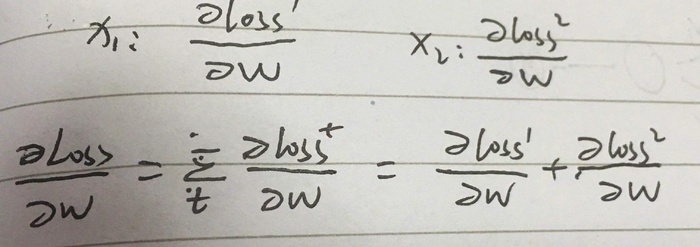
一个权重,多个误差,求和
不同2:权重共享,链式传递
![]()
![]()
也是2个w,咋一看,不知道咋算。
其实是这样的
链式法则
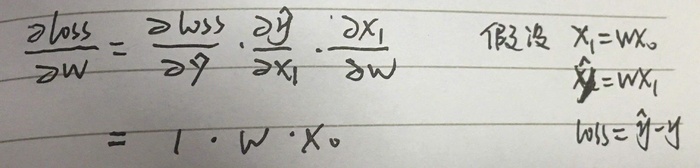
一个权重,多次传递,其梯度中含有w,且容易看出,传递次数越多,w的指数越大
其实rnn比这些不同点更复杂
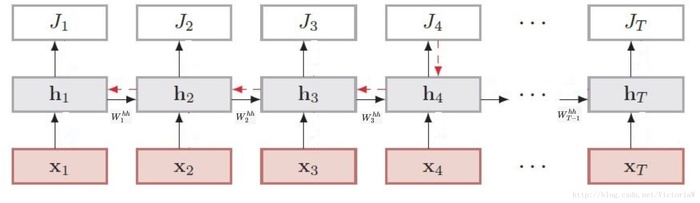
图不解释了,直接上干货。
首先对网上各种坑爹教程进行补充和完善,总结,当然虽然坑爹,但是对我们理解也是有帮助的。
教程1:教程描述ly1的误差来自ly2 和 next_ly1两个方向(下图),其实说法不错,只是不完整。
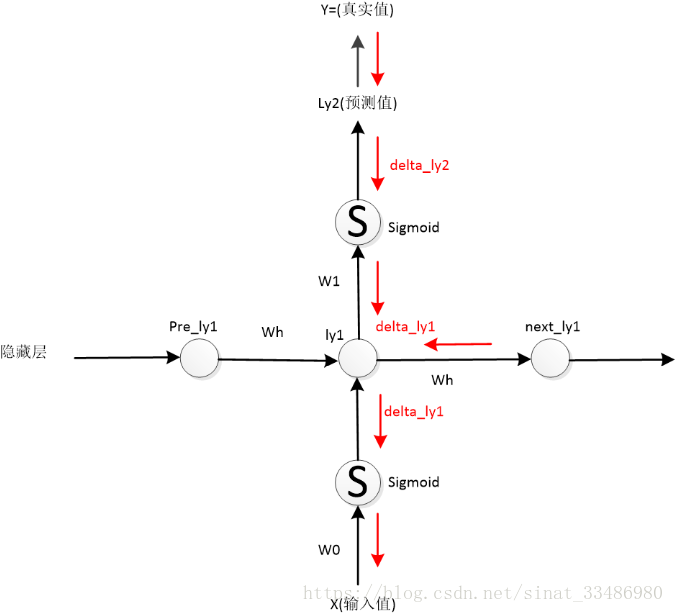
补充:
1. ly1的误差来自两个方向,ly2和next_ly1,这两条路都要从各自的误差开始算起。(这里体现了我上面例子里提醒谨记的话)
2. 这里计算的是“单层”的梯度,即单个w的梯度,实际计算BPTT梯度时并不是这样。
这里的公式应该是这样子

教程2:教程定义了中间变量,并用中间变量来表示梯度

各种δ,完全搞不清,公式也没有推导过程。
补充:这里针对单个节点自定义了变量,然后把每个节点直接相加得到总梯度。
总结:这里定义了中间变量δ,之所以定义这个,是因为这个计算比较麻烦,而且要经常用到,这样会很好地简化运算。
这里的公式应该是这样子

这些教程加上我的补充,其实已经可以算出梯度了。
下面我再系统的讲一遍BPTT
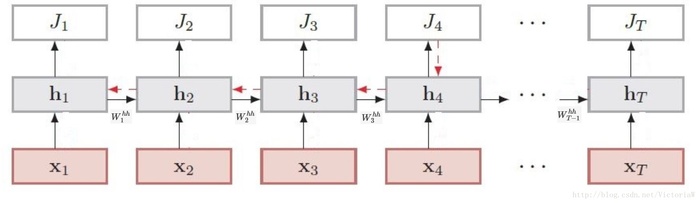
还是用这张图,这张图在整个网络架构上比较完整,但是缺乏完整的cell,我在前向传播中标记一下。
前向传播
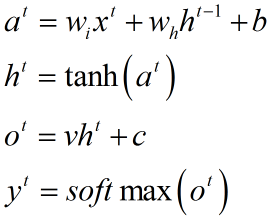
wi 表示输入权重,wh表示隐层权重
反向传播
首先理解如下公式
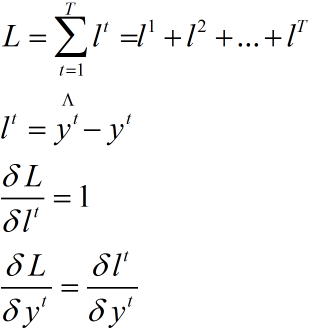
1. v 和 c并没有多路传递误差,和普通的梯度计算无差别
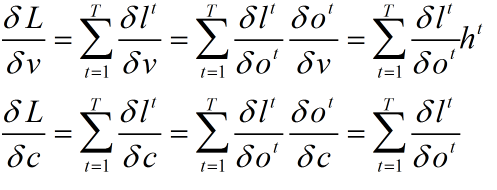
2. wi wh b都有多路传播
同样设定中间变量,注意这个变量最好是个递推公式,能够大大简化运算,且容易得到规律
初步设定
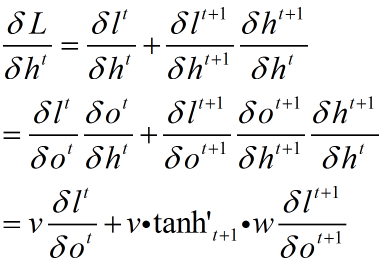
优化
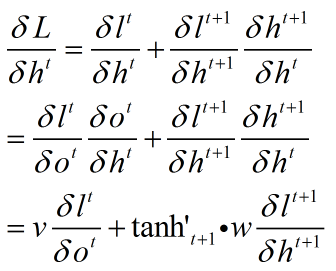
再优化
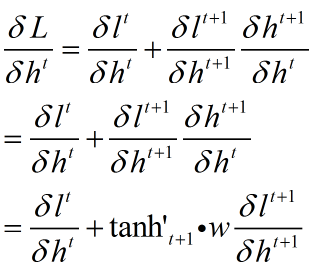
这样貌似好多了,递推下去
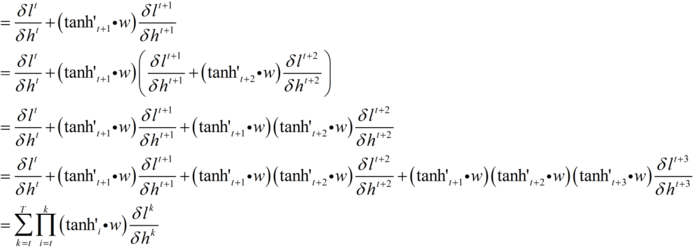
注意到这里还是传递误差,从上式大概可以看出
1. 这是t时刻隐层cell的误差 ,当然要乘以总误差
2. t时刻的误差是t时刻到T的一个和,也就是说是从终点一步一步传过来的
3. 每步传递都是从t时刻到传递时刻的连乘,w指数。
4. 大概是这样 w * losst1 + ww * losst2 + www * losst3 + wwww * losst4 + wwwww * losst5 ,越往前传这个式子越长,损失也越传越小
5. 加上激活函数的搅和,其导数经常小于1
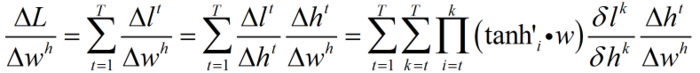
wi同理
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:循环神经网络(二)-极其详细的推导BPTT – 努力的孔子 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 