循环神经网络
引言
上几节讲了一些时间序列的基本概念, 大家总感觉不那么的'智能', 与现在的人工智能的总那么的... 不太搭边. 先不管以上'感觉'对不对, 今天插队与大家分享一个处理时间序列的'大杀器' — 循环神经网络(Recurrent neural network, RNN), RNN就是为处理序列数据而生的( 时间序列数据是当是序列数据!!!).
首先,对于时间序列,让大家感受一下我随便训练的结果(真的很随便,大约只有100个循环,
+_+!):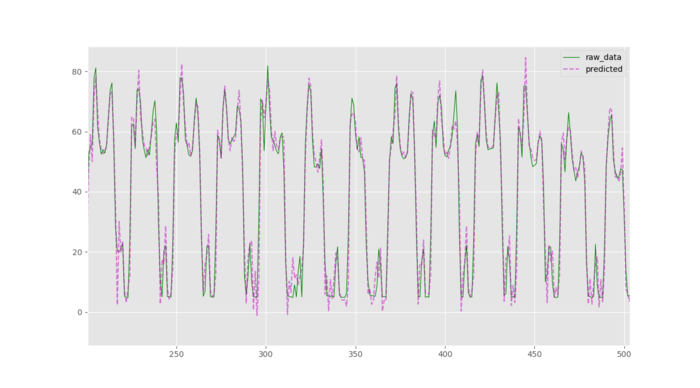

怎么样? 预测效果惊人的好!
RNN在当今的人工智能领域,或者说机器学习领域炙手可热,大放异彩, 特别是在自然语言处理(natural language processing, NLP)方面(比如机器翻译,语音识别,对话机器人等等)可谓独孤求败. 而且已有许多应用被大家开发出来,比如让机器写文章,写古诗,谱曲填词,写代码... 不胜枚举, 这些无论怎么看都比时间序列(特指业务上的时间序列数据,一般有timestamp, value 等类似格式)复杂得多, 所以用RNN处理时间序列,大家是不是已经很有信心啦?
举个例子, '曾经有一份真挚的感情,摆在我面前,我没有去___.'
这句话如果应用传统的语言模型,可选项有:'北京','学校','珍惜','上班',… 有好多选项.传统的语言模型基于统计模型,可以利用横线前面的信息非常有限, 目前最长用的传统语言模型可能利用的前面信息是: '去….', '没有去…','我没有去…',再长就受不了.
显然,就算是可利用的信息是'我没有去…', 你认为选择出''珍惜''的概率会比'北京'大吗? 不过,RNN就会选择''珍惜'',而且概率会比'北京','上班'等等大很多. 这是因为,RNN不但会利用'我没有去…'这样的信息,而且还会利用'摆在我面前',以及'曾经有一份真挚的感情'等信息. 当这些信息利用上以后,就会发现'上班','学校'等等词汇放在横线上意思就对不上了.
不仅如此,RNN 还会告诉你,接下来会说什么:' 等到失去了,才追悔莫及','这让我很后悔','从而伤害了一位可爱的女孩',… 至于哪个,就看你的数据及训练情况了,如果都还行,至尊宝的'谎言'RNN完全可以脸不红心不跳的说出来.
Tip: 本文面向不同需求读者(或为您的最佳阅读体验着想):
- 只想了解一下,或拓宽一下思路的读者, 只需读 **非 *** 部分即可;
- 如果想稍微深入一些,或知道一些细节则需阅读所有小节包括 带 * 部分.
循环神经网络
那什么是神经网络? 别急,先看下RNN擅长做什么? 前面已经说过就是序列数据(sequential data). 序列数据的特点是什么? 就是序列数据前后之间是有很强的关联性的,专业一点的说法是不独立的(nonindependent). 前面出现的数据(比如词汇)对后面的数据有重大影响的, 甚至后面的数据对前的数据也是有重要影响的(双向循环神经网络,稍后介绍).
RNN就是为处理此等问题而生的,即RNN在处理当前信息时,会考虑前面出现的信息,理论上RNN可以包含当前信息前面的所有已知信息的.那循环是什么意思呢? 就是说之前处理过的信息还会一直被利用去帮助后面到来的信息,.
举个例子: 把一串信息比作一群学生去体检, 而RNN可以看成的一家医院, 第一个人进去后, 体检完成后,体检单包含了此人体检相关的所有信息, 作为输出信息上存储在系统中,并打印一份给这位学生,,而此学生出来后却把体检单交给了下一位同学(别问我为什么要给下一位同学,'医院'就是这么规定的,没办法,学生只能按学校的规则来,否则,想不想毕业?).
这个''下一位''同学进去后,把体检单交给医生,医生根据这个同学的体检情况及上交的这份体检单给这个同学重新写一份体检单,储存,并打印一份交给这位同学,此同学拿着这份包含他和之前同学信息的体检单出来后交给下一位同学.如此循环下去.
直到最后一位同学拿着包含他之前所有同学信息的体检单进去并检查完成后,他的体检单(理论上包含所有同学的信息)被储存,并打印一份交给他,这样一队人的'花式'体检就结束了, RNN就是这样的处理数据的.
循环结构*
规范化一点, 正如上面的例子一样,当前的数据依赖于之前的信息, 设有一状态序列数据({s_t})
要表示这一性质,典型的处理方式:
]
其中f() 为映射(在RNN中可以简单的理解激活函数), (theta) 为参数. 从上式可以看出, 1). 映射是与时间不相关的. 2). (theta) 也是与时间无关的,这里体现了循环结构(在RNN中)的很重要性质: 参数(主要为权值参数)共享(parameter sharing).
上式可以用另一种形式(展开式)表示:
\
s_t &=& f(s_{t-1},theta) \
&=& f(f(s_{t-2},theta),theta)\
& = & dots \
& = & f(f(...f(s_1,theta),theta,)...,theta)\
end{array}
]
如果状态序列中的每个数据不只受其前面信息的影响,还受外部信息的影响,那么循环结构可以表示成:
]
其中(x_t)为外部信息序列的第t个元素. 这个就是RNN(简单的)使用的循环结构.
写成带权重的形式:
]
为简洁,可以把偏置省略,可以将其看成是U中的(额外)第一维(元素都为 1),后面的BPTT推导将采用此种方式.
如果考虑输出层:
]
RNN 结构*
一个标准的(简单的)RNN单元包含三层: 输入层,隐藏层和输出层,用图示有两种方式:折叠式(图1左)与展开式(图1右):
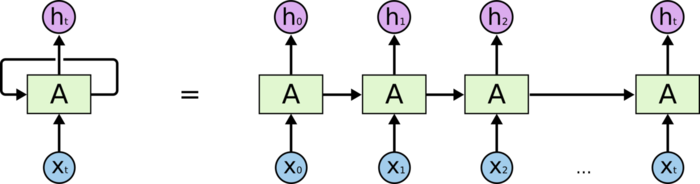
图1 RNN结构的两种呈现方式,折叠式(左),展开式(右),上图中青色(圆)区块为输入层,绿色(方)为隐藏层,而紫色的为输出层.(引自: understanding LSTM Networks, colah'blog 2015 .)
如果理解了上面的循环结构,那对RNN的结构就可以比较明白.当然如果你对着图看了好久也是正常的,因为这个思维还是需要转换的,毕竟不那么直观.
双向循环神经网络
双向循环神经网络(Bi-Directional Recurrent Neural Network,BDRNN) 则不止利用前面的信息,还会利用后面的信息.
比如: 我的家乡是一千五里外的哈尔滨, ___回家,要三个多小时.
这句话, 如果只考虑前面的信息,后面真的有太多可能: ' 那里每年二百多天处于冬季', '不是上海线','回家不方便','吃烧烤','看电影','乘火车','乘飞机'…
但考虑后面的信息(如''回家'')前面大多满足要求了,因为后面有''回家''二字,那么可以想到与交通工具可能有很大关系(但也其他可能),比如'走路','跑步','骑车','不想','很少','妈妈总希望我',…虽然还是有很多种可能性,但范围是极大的缩小了.
如果把后面的'要三个多小时',那这个空白的部分就基本确定了: 乘飞机.(有些小伙伴,可能会说也可能是'坐飞机','打飞的'等等啊.对的,完全正确, 这就需要额外的信息了,比如语境等等, 但多数情况,选择不只一种时,就会选取概率最大的选项了.)
上个图*****:
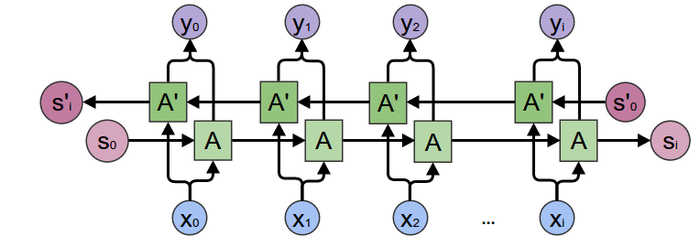
图2 双向RNN (引自: understanding LSTM Networks, colah'blog 2015)
是不是一看到这张图就懵了? 对的,第一次看到类似结构图我也懵,懵得很彻底.不过目前我们只需要知道处理当前信息时,利用了未来信息(穿越,对的, BDRNN就是解决未来信息如何'穿越'回来而设计的~~)就可以了.目前的业务上的时间序列研究方式不倾向于BDRNN的研究方式(但要注意,也是可以应用的:比如某电商大促时间的前一段时间会对业务产生'反向'性抑制就是BDRNN的应用场景.什么,还太懂?'双十一'前的几天,不止商家囤货,买家也会囤单吧,就是这个意思.)
深度循环神经网络
前面提到的其是都只有RNN的一单元或者说RNN单元只有一层隐藏层,可以想象将多个RNN单元堆叠在一起,那就形成了深度循环神经网络(deep RNN),或者说是多层RNN(multi-layers RNN).
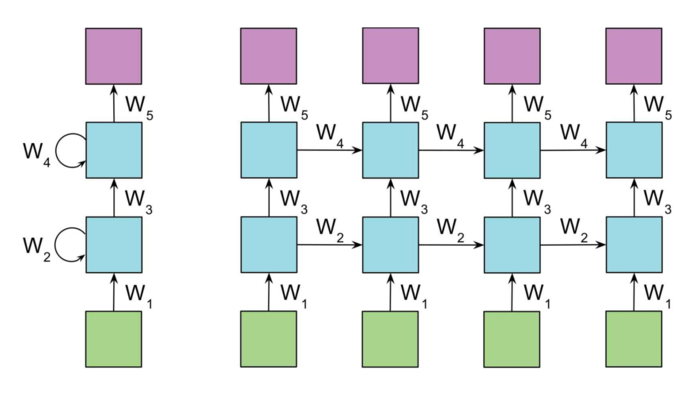
图3 多层RNN (图中呈现的是二层RNN)(引自: Tensorflow for Intelligence, Sam Abrahams et al.)
穿越时间的反向传播算法
建模可分为两个过程,都是无比重要的,其一就是模型的构建,其二就是对模型参数的训练了.模型构建之后, 框架就确定了,但在框架之内,你是搭建出垃圾厂,还是宫殿就要靠参数的训练了. 更加直观的例子: y = ax +b, 这个线性方程,几乎所有人都懂, 可在这个模型确定之后, y = 2x + 3 与 y = -2x +3 可完全不相同啊.
那神经网络用什么训练呢? 用得即是梯度下降算法(gradient descent algorithm),这与一般的机器学习算法没有什么不同, 但我们知道,神经网络是,特别多层神经网络,参数众多,层与层之间的关系复杂,如果每一个都按传统的方式计算梯度,那有太多无意义开销(重复计算).因此在BP随之而生,如许多惊人的贡献一样,最初(1970年)BP被提及时,并没有引起人们的注意,而在十六年后才有人认识到其重要性,但真正(火热地)用起来的当然是二十一世纪之后的事了.
反向传播算法(back propagation algorithm, BP-algorithm)是深度学习的最重要的两大基石(另一个是梯度下降算法),几乎所有的深度学习算法底层都会调用BP算法,其本质就是对链式求导法则的应用而已. 而穿越时间的反向传播算法(back propagation through time algorithm, BPTT-algorithm) 则是BP上的应用,其核心没有改变,只不过在应用时,要注意一些穿越时间的特别之处.
反向传播算法*
BP的目标是计算损失(Loss 或者叫'代价','成本'(cost)等等)函数对参数(主要是权重(weights)及偏置(biasses))求偏导.
在梯度下降法中, 对参数进行更新:
]
其中 w 即为待更新(训练)参数,(eta)为超参数(hyper parameter) 学习率, 而(frac{partial L}{partial w}) 即为损失函数L对w的偏导,也可称为w在梯度, 而反向传播即是对这个梯度的求解.
学习反向传播算法,要记住'一,二,三,四':
一. 一个乘积:
Hadamard 乘积: 是逐元素的(element-wise)乘积, 用符号(odot) 表示.举个例子:
a = [1,2,4], b = [2,3,5], 则(aodot b = [1*2,2* 3,4*5] = [2,6,20]).
二. 二个假设:
- 损失函数可以表示成每个训练样本x上的代价函数的均值.这个假设很基本也很自然,从样本的视角看损失函数,它一要是'一视同仁的'.
- 损失函数可以表示成神经网络输出的函数, 否则如何反向传播?没出门就停下了,怎么往下进行?
三: 三个步骤:
- 前向传播,计算神经网络的输出;
- 根据误差函数(或损失函数) 对所有所需训练的参数求偏导(其间要先计算每个神经元的偏导数);
- 基于2步,计算每个参数的梯度.
四: 四个基本方程**:
设:
L为神经网络的损失函数;
(w_{jk}^l) 表示从(l-1)层的第 k 个神经元到第 l 层的第 j 个神经元(很怪是吧,习惯就好了~哈,其实这样表示有好处,因为公式表述更方便)的权值,请看下图:
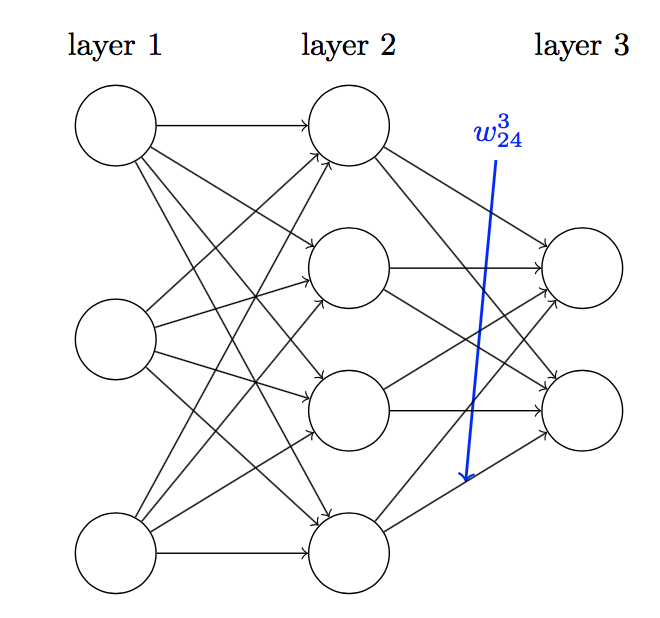
这里的(w_{2,4}^3) 表示从第二层的第四个神经元到第三层的第二个神经元的权值;
(a^l) 表示第 l 层的神经元激活值,(逐个使用sigmoid 函数,即element wise):
]
其中 (sigma) 是激活函数数(activation function);
中间变量: (boldsymbol{z^l = w^l a^{l-1} + b^l}) .
定义 l 层的第 j 个神经元上的误差为(delta_j^l):
]
OK, 准备结束,开始:
-
输出层的误差:
[delta_j^L = frac{partial L}{partial a_j^L} sigma'(z_j^L)
]写成向量(矩阵形式):
[boldsymbol{(delta^L)^T= nabla_a L odot sigma'(z^L)}
]其中(nabla_a L)的每一个分量即是 (frac{partial L}{partial a_j^L}).(注: 其中角标L 为最后一层(L层,不同于损失L)的意思,另, 矩阵微积分这样重要而常用的知识形式竟然没有统,因此这也为矩阵的微积发增加了难度,这里应用'分子式排版',即形式优先考虑分子的形式,具体请看wikipedia)
-
使用下一层的误差来(delta^{l+1})表示当前层的误差(delta^l):
[boldsymbol{(delta^l)^T = (w^{l+1})^Tdelta^{l+1}odotsigma'(z^l)}
]这个一下出结果不像上一个那么直观,咱们来推导一下:
[begin{array}
\
delta_j^l &= &partial L / partial z_j^l \
& = & sum_k frac{partial L}{partial z_k^{l+1}}frac{partial z_{k}^{l+1}}{partial z_j^l}\
&=& sum_k frac{partial L}{partial z_j^{l+1}}delta_k^{l+1}\
& =& sum_k w_{k,j}^{l+1}delta_k^{l+1}sigma'(z_j^l)
end{array}
]K 是(l+1)层的神经元的个数.这里用到了(8)式及下面的式子(13):
[begin{array}
\
frac{partial z_k^{l+1}}{partial z_j^l} &=& frac{partial (sum_j w_{k,j}^{l+1}sigma(z_j^l)+b_k^{l+1})}{partial z_j^l} \
&=& w_{k,j}^{l+1}sigma'(z_j^l)
end{array}
] -
对任一偏置的梯度:
[frac{partial L}{partial b_j^l } = frac{partial L}{partial z_j^l}frac{partial z_j^l}{partial b_j^l} = delta_j^l
]即:
[boldsymbol{(frac{partial L}{partial b^l})^T = (delta^l)^T}
] -
对任一权重的梯度:
[begin{array}
\
frac{partial L}{partial w_{j,k}^l } &=& frac{partial L}{partial z_j^l}frac{partial z_j^l}{partial w_{j,k}^l} \
&= &delta_j^l frac{partial (w^l a^{l-1} + b^l)}{w_{j,k}^l}\
&=& delta_j^l a^{l-1}_k
end{array}
]即:
[(boldsymbol{frac{partial L}{partial w^l})^T = (delta^l)^T (a^{l-1})^T}
]
式(10),(11),(15)(17)即为BP的四个方程,有了这四个方程,任一可训练参数的梯度就可以计算了,进而可以更新,达到学习的目的.
BPTT**
有了上面的铺垫, BPTT就简单多了, BPTT 的误差项沿两个方向传播,一个是从当前层传上向一层,另一个是从当前时刻传到上一时刻(在处理时域反向传播时,最好把这个循环展开(unfold)这样,结构就像一个层的全连接网络了,只不过权值共享):
(PS: 下面均为矩阵运算)
根据上面:
]
即:
]
先考虑:
frac{partial z_t}{partial z_{t-1}} &=& frac{partial z_t}{partial s_{t-1}}frac{partial s_{t-1}}{partial z_{t-1}}\
&=& boldsymbol{W odot (f'(z_{t-1}))^T}\
end{array}
]
其中:
]
]
注意,(20,21)式本来均是Jacobian矩阵,但因其中(22)式是一对角阵((diag(f'(z_{t-1}))),简化,写成向量式(如(20)式中),可以应用hardamad 乘积,形式上更统一,简洁.
最后T时刻的误差(delta_k):
delta_{k}^T &= &frac{partial L}{partial z_k^{T}} \
& =& frac{partial L}{partial f}f'(z_k^{T})
end{array}
]
写成矩阵形式:
]
则第t 时刻的误差(角标 l 代表层,这里的角标有些乱,因为时间,层际,元素三个在一起不好排列, 故注意描述./_!) (delta_t^l):
delta_t & =& (frac{partial L}{partial z_t})^T\
&=& (frac{partial L}{partial z_T}frac{partial z_T}{partial z_t})^T\
& =& (frac{partial L}{partial z_T}frac{partial z_T}{partial z_{T-1}}frac{partial z_{T-1}}{partial z_{T-2}}...frac{partial z_{t+1}}{partial z_{t}})^T\
& =& delta_T Pi_{i = t}^{T-1} Wodot f'(z_i)^T\
& = & boldsymbol{ W^Tdelta_{t+1}odot f'(z_t)}
end{array}
]
第 l-1层的误差:
delta_t^{l-1}& =& frac{partial L}{partial z_t^{l-1}}\
&=& frac{partial L}{partial z_t^l}frac{partial z_t^l}{partial z_t^{l-1}}\
&= &delta_t frac{partial (Uf^{l-1}(z_t^{l-1}) + Ws_{t-1})}{partial z_t^{l-1}} \
&=& boldsymbol{U^Todot f'^{l-1}(z_t^{l-1})}
end{array}
]
对w_t 的梯度:
nabla_{W_t}L &=& frac{partial L}{partial W_t} \
&=& frac{partial L}{partial z_t}frac{partial z_t}{partial W_t}\
& =& boldsymbol{delta_t ^T s_{t-1}^T}
end{array}
]
而对于w 的梯度则是上式在时间轴上的相加:
]
对u_t的梯度:
nabla_{U_t}L &=& frac{partial L}{partial U_t} \
&=& frac{partial L}{partial z_t}frac{partial z_t}{partial U_t}\
& =& boldsymbol{delta_t^Tx_{t}^T}
end{array}
]
则对U的梯度:
]
上式(22)(23)(25)(27)即为BPTT的四个方程了.
总结
以上就是RNN的基本内容, 尽管RNN很强大,但其实也有些现实的问题,这里先不展开了(比如梯度消失,爆炸等等), 因为这些问题,出现了许多变种, 其中门限变种比LSTM,GRU 可谓如日中天.
参考方献:
- Deep learning, 2015,Ian Goodfellow et al.
- Neural network and deep learning, 2016 Micheal Nielsen.
- Tensorflow for intelligence 2016, Sam Abrahams et al.
- Understanding LSTM Networks —colah's blog
- A critical Review of Recurrent Neural Network for sequence learning, 2015, Zachary C. Lipton
- Hands on Machine learning with scikit-learn and Tensorflow: Concept, Tools, and, Techniques for Building Intelligent Systems.
- The Unreasonable Effectiveness of Recurrent Neural Network, 2015, Andrej Karpathy blog.
- 零基础入门深度学习(5)- 循环神经网络,2017, hanbingtao.
- Matrix calculus,2017, Wikipedia.
- Matrix Differential Calculus with Applications in Statistics and Econometrics,2007, Jan R. Magnus, et al.
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:时间序列(五): 大杀器: 循环神经网络 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 