最近在写一个基于代理池的高并发爬虫,目标是用单机从某网站 API 爬取十亿级别的JSON数据(均为公开非敏感信息)。
代理池
有两种方式能够实现爬虫对代理池的充分利用:
- 搭建一个 Tunnel Proxy 服务器维护代理池
- 在爬虫项目内部自动切换代理
所谓 Tunnel Proxy 实际上是将切换代理的操作交给了代理服务器,很多市面上的代理软件都有此类功能。
如果要自行搭建可参考以下项目:
考虑到高并发,在爬虫项目内部切换代理更加灵活一些。代理池选一个能用的就行:GitHub - jhao104/proxy_pool
记得加上匿名校验:能否设置代理池只获取高匿IP · Issue #169 · jhao104/proxy_pool · GitHub
代理切换策略
如果简单的在多线程中对每个 requests.get() 使用不同的代理,那么一定会遇到内存泄露的问题:
- 内存泄露问题 · Issue #522 · jhao104/proxy_pool · GitHub
- Requests memory leak · Issue #4601 · psf/requests · GitHub
- Memory Leak in Python requests - GeeksforGeeks
即便写成:
session = requests.session()
response = session.get(url, headers=headers, proxies=proxies)
response.close()
session.close()
甚至在加上 gc.collect() 也无济于事。
因此需要控制创建 session 对象的数量,只在请求失败后切换代理和创建新的 session。
工作流程
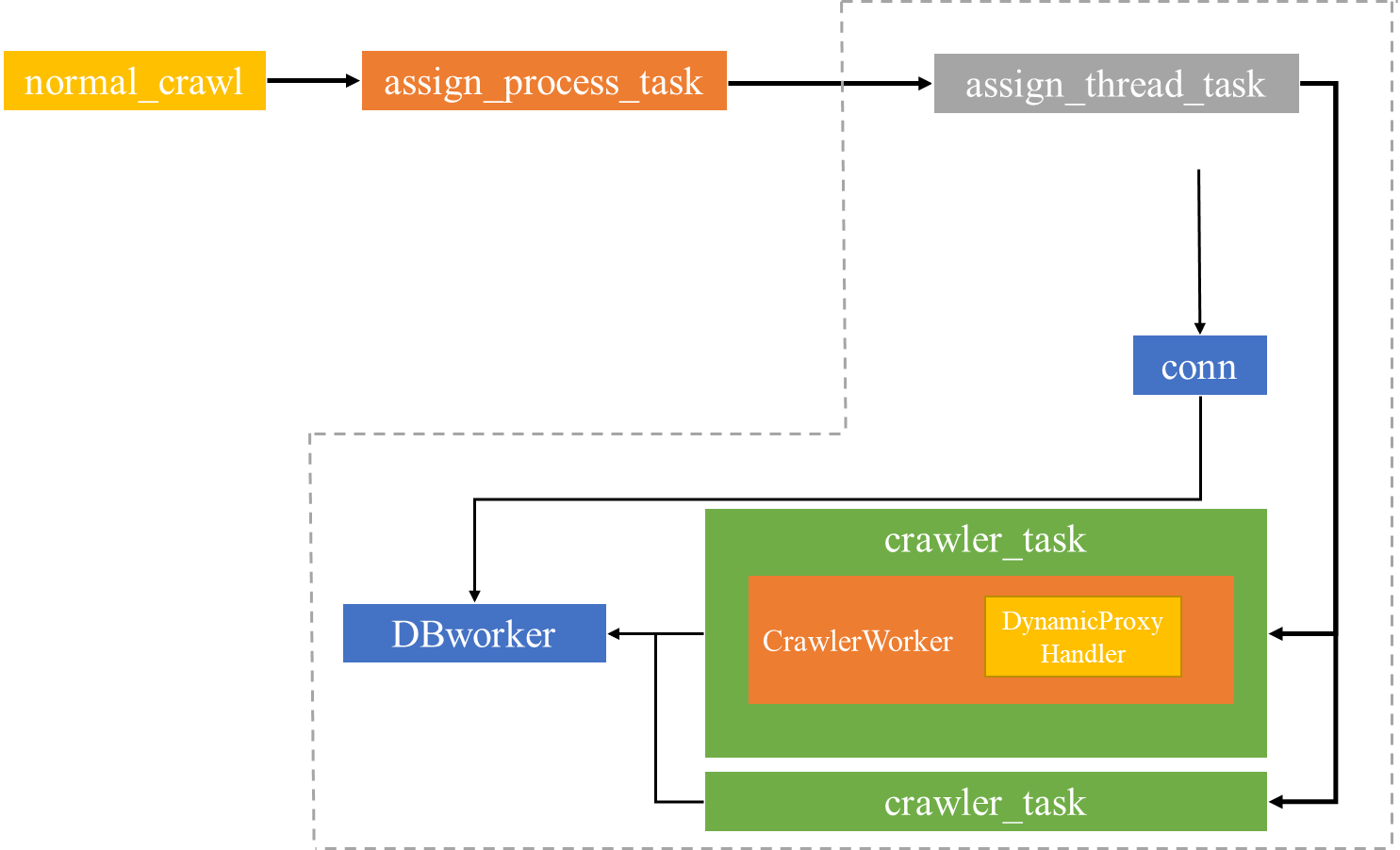

① 主线程根据 URL 数量动态创建子进程,虚线框内为子进程任务
② crawler_task 为线程任务,执行发送请求和解析JSON
插入策略
每个子进程维护一个 url_queue 和 insert_queue。
线程会从 url_queue 取出URL执行爬取任务,由于JSON数据占用的空间不大,所以线程会先将每个 response 经过简单解析后存到列表中。
等到 url_queue 为空时(不要使用不安全的 queue.empty() 判断),get 方法会触发 Timeout 异常,然后线程会将列表插入到 insert_queue 中。
所有线程任务结束后,子进程再执行 executemany 将数据批量插入到 MySQL。
其他
爬取JSON数据产生的流量不大,但需要考虑 PPS(packet per second),如果网络设施不到位的话可能严重影响爬取效率。
网络上获取的免费代理大多是透明代理,如果使用开源项目 Proxy_Pool 作为代理池并加入匿名校验,可能会间歇性导致代理池没有可用代理。(所以最好还是从一些网络空间测绘引擎上通过特征抓取)
代理蜜罐
代理池虽好,但也会遇到不讲武德的蜜罐:
(这项目发布于2019年5月,提前预测了微博的数据泄露?)
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:【Python】爬虫实战-基于代理池的高并发爬虫 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 