检查网页源代码
首先让我们来检查豆瓣top250的源代码,一切网页爬虫都需要从这里开始。F12打开开发者模式,在元素(element)页面通过Ctrl+F直接搜索你想要爬取的内容,然后就可以开始编写正则表达式了。
如下是我们将要爬取内容的html局部区域:
<div class="item">
<div class="pic">
<em class="">1</em>
<a href="https://movie.douban.com/subject/1292052/">
<img width="100" alt="肖申克的救赎" src="https://img2.doubanio.com/view/photo/s_ratio_poster/public/p480747492.webp" class="">
</a>
</div>
<div class="info">
<div class="hd">
<a href="https://movie.douban.com/subject/1292052/" class="">
<span class="title">肖申克的救赎</span>
<span class="title"> / The Shawshank Redemption</span>
<span class="other"> / 月黑高飞(港) / 刺激1995(台)</span>
</a>
<span class="playable">[可播放]</span>
</div>
<div class="bd">
<p class="">
导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...<br>
1994 / 美国 / 犯罪 剧情
</p>
<div class="star">
<span class="rating5-t"></span>
<span class="rating_num" property="v:average">9.7</span>
<span property="v:best" content="10.0"></span>
<span>2668670人评价</span>
</div>
<p class="quote">
<span class="inq">希望让人自由。</span>
</p>
</div>
</div>
</div>
当然,在Chrome中页面是这样的:


匹配正则表达式
<em class="">1</em>这显然是‘’索引‘’可以用于匹配序号
相应正则表达式为:
<em class="">(\d+)</em>
其中\d+的含义是匹配1个及以上的数字
正则表达式详解请看:正则表达式完整入门教程,含在线练习
正则表达式速查表请看:正则表达式速查表
<a href="https://movie.douban.com/subject/1292052/">这个表示的是标题对应的超链接,也就是对应电影的详情页,如果我们要做进一步的内容爬取,这个链接也是值得保存的。
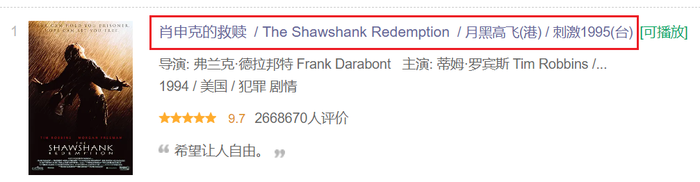
这里介绍一下re.S参数,它可以让我们跨行匹配正则表达式。而且我们知道,正则表达式越详细,匹配的精确度就越高,于是我们可以将上下两行一起匹配。
<em class="">1</em>
<a href="https://movie.douban.com/subject/1292052/">
相应的正则表达式为:
'<em class="">(\d+)</em>.*?<a href="(.*?)">.*?'
然后我来解释下为什么我们要加括号(),这是因为,有的时候我们想要的不是每一个存在变化的变量,它们仅仅需要作为通配符来使用,于是我们将需要返回的匹配值加上括号作为返回值,未加括号的正则表达式匹配的值不会被返回。上面的.*?就是不会被返回的正则表达式。
接下来看看我们的完整正则表达式吧:
pattern = re.compile(
'<em class="">(\d+)</em>.*?<a href="(.*?)">.*?' +
'<img width="100" alt=".*?" src="(.*?)" class=""' +
'>.*?<span class="title">(.*?)</span>.*?<span ' +
'class="other"> / (.*?)</span>.*?<div ' +
'class="bd">.*?<p class="">.*?导演: (.*?) .*?<br>' +
'.*?(\d{4}) / (.*?) / (.*?)\n' +
'.*?</p>.*?<span class="rating_num" property="v:' +
'average">(.*?)</span>',
re.S)
正则表达式中.表示任意字符;*表示前置字符任意次数;?表示前置字符可有可无。
这个+号,即是常用的连接字符串的用法。我们可以发现,上述表达式一共有10个括号(),也就是说最终会在一个item中返回10个值,以列表(数组)形式。
- 正则中没有括号时,返回的是 list,list的元素是 str ;
- 正则中有括号时,返回的是 list,list的元素是
tuple,tuple 中的各项对应的是括号中的匹配结果;
下面我们来认识一下re的几个库函数:
-
re.compile是预编译正则表达式函数,是用来优化正则的,它将正则表达式转化为对象 -
re.compile函数用于编译正则表达式,生成一个 Pattern 对象,pattern 是一个字符串形式的正则表达式 -
pattern是一个匹配对象(Regular Expression),它单独使用就没有任何意义,需要和findall(),search(),match()搭配使用。 -
使用
re.S参数以后,正则表达式会将这个字符串作为一个整体,将“\n”当做一个普通的字符加入到这个字符串中,在整体中进行匹配,而不是在一行内进行匹配。 -
re.findall返回string中所有与pattern相匹配的全部字串,返回形式为数组
完整代码
导入包
# json包
import json
#正则表达式包
import re
import requests
from requests import RequestException
定义获取html函数
#函数:获取一页html
def get_one_page(url):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
# Response对象返回包含了整个服务器的资源
# Response对象的属性,有以下几种
# r.status_code: HTTP请求的返回状态,200表示连接成功,404表示失败
# 2.r.text: HTTP响应内容的字符串形式,即,url对应的页面内容
# 3.r.encoding:从HTTP header中猜测的响应内容编码方式
# 4.r.apparent_encoding:从内容中分析出的响应内容编码方式(备选编码方式)
# 5.r.content: HTTP响应内容的二进制形式
response = requests.get(url, headers=headers, timeout=1000)
if response.status_code == 200:
return response.text
except requests.exceptions.RequestException as e:
print(e)
定义解析html函数【正则】
#函数:解析一页html
def parse_one_page(html):
pattern = re.compile(
'<em class="">(\d+)</em>.*?<a href="(.*?)">.*?' +
'<img width="100" alt=".*?" src="(.*?)" class=""' +
'>.*?<span class="title">(.*?)</span>.*?<span ' +
'class="other"> / (.*?)</span>.*?<div ' +
'class="bd">.*?<p class="">.*?导演: (.*?) .*?<br>' +
'.*?(\d{4}) / (.*?) / (.*?)\n' +
'.*?</p>.*?<span class="rating_num" property="v:' +
'average">(.*?)</span>',
re.S)
#使用re.S参数以后,正则表达式会将这个字符串作为一个整体,将“\n”当做一个普通的字符加入到这个字符串中,在整体中进行匹配,而不是在一行内进行匹配。
#re.findall返回string中所有与pattern相匹配的全部字串,返回形式为数组
#上述pattern正好有10个括号
items = re.findall(pattern, html)
for item in items:
yield {
'index': item[0],
'page_src': item[1],
'img_src': item[2],
'title': item[3],
'other_title': item[4],
'director': item[5],
'release_date': item[6],
'country': item[7],
'type': item[8],
'rate': item[9],
}
定义保存内容函数
#函数:将内容写入文件
def write_to_file(content):
with open('douban_movie_rankings.txt', 'a', encoding='utf-8') as f:
f.write(json.dumps(content, ensure_ascii=False) + '\n')
定义主函数
#主控函数
def main():
#用于翻页
for offset in range(10):
#获取网址
url = f'https://movie.douban.com/top250?start={offset * 25}&filter='
#获取html文件
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item)
定义魔法函数
if __name__ == '__main__':
main()
原创作者:孤飞-博客园
原文链接:https://www.cnblogs.com/ranxi169/p/16565717.html
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:正则表达式实战:最新豆瓣top250爬虫超详细教程 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 