本章主要介绍pytest几种数据驱动的方法,也是我们做接口自动化中经常要使用到的,大致分为以下四种。
一.yaml
二.json
三.csv
四.excel
一.yaml
1.安装插件:pip install pyyaml
2.yaml的两种读写方法load()和dump(),话不多说,直接上代码
load()为读取json流,读取是加上Loader=yaml.FullLoader,防止乱码,self.data为读取的yaml文件
def param_yaml_ready(self): with open(self.data, mode="r", encoding="utf-8") as f1: data = yaml.load(f1, Loader=yaml.FullLoader) return data
dump()为写入dict类型的数据,allow_unicode=True防止写入时乱码,
def param_yaml_write(写入dict类型的数据):
with open("写入的文件名.yaml", mode="w",
encoding="utf-8") as f1:
data = yaml.dump(写入dict类型的数据, f1, allow_unicode=True)
return data
3.yaml文件的写法。
yaml文件中-代码中括号,list的意思,每个层级代表一个{},dict的意思,下面内容读取出来后展示如下
- class: name: 李明 age: 12
读取的内容:[{'class': {'name': '李明', 'age': 12}}]
4.实例。下面我们以一个具体的实例来说下yaml的用法
(1)首先我们先创建一个tokenApproval.yaml文件,具体写法如下。这个yaml文件中只有一条case
- #获取审核token tokenApproval: - request: url: https://qyapi.weixin.qq.com/cgi-bin/gettoken #request-url param: #request-body corpid: ww29957e72e534d2 corpsecret: rVP15c62Ybjl9xTJIbCCXwoDq8eVuTQ-9FOmqjknz methon: get #request-methon response: eq: errcode: 0 #断言判断
(2)然后创建params.py封装yaml读写方法,./params/globalParametersToken.yaml是我写入json数据的yaml文件
def param_yaml_ready(self): with open(self.data, mode="r", encoding="utf-8") as f1: data = yaml.load(f1, Loader=yaml.FullLoader) return data @staticmethod def param_yaml_write(paramYaml): with open("./params/globalParametersToken.yaml", mode="w", encoding="utf-8") as f1: data = yaml.dump(paramYaml, f1, allow_unicode=True) return data
(3) 结合pytest.mark.parametrize实现数据驱动,pytest.mark.parametrize具体写法格式可查考:
https://www.cnblogs.com/lihongtaoya/p/15840026.html
import pytest from params.params import param import requests class Testtoken: @pytest.mark.parametrize("parama", param("./params/tokenApproval.yaml").param_yaml_ready()) def test_tokenApproval(self, parama): url = parama["tokenApproval"][0]["request"]["url"] params = parama["tokenApproval"][0]["request"]["param"] data = requests.get(url, params) assert data.json()["errcode"] == parama["tokenApproval"][0]["response"]["eq"]["errcode"]
若是yaml文件中写入的单接口数据不止一条case,如下代码,那么parama["tokenApproval"][0]这样的
写法就不适用了,这里需要添加一个for循环即可for i in range(0, len(parama["tokenApproval"])):
- #获取审核token tokenApproval: - request: url: https://qyapi.weixin.qq.com/cgi-bin/gettoken param: corpid: ww29957e72e534d2 corpsecret: rVP15c62Ybjl9xTJIbCCXwoDq8eVuTQ-9FOmqjknz methon: get response: eq: errcode: 0 - request: url: https://qyapi.weixin.qq.com/cgi-bin/gettoken param: corpid: ww29957e72e534d2 corpsecret: rVP15c62Ybjl9xTJIbCCXwoDq8eVuTQ-9FOmqjk methon: get response: eq: errcode: 0
若yaml文件中写入的是多接口数据,如下代码写法,这里每个接口我们只要有一个关键字去区分即可:
tokenApproval || tokenContacts,这样我们在获取的时候parama["tokenApproval"],tokenApproval
这个值随机变换即可
-
#获取审核token
tokenApproval:
- request:
url: https://qyapi.weixin.qq.com/cgi-bin/gettoken
param:
corpid: ww29957e72e534d27e
corpsecret: rVP15c62Ybjl9xTJIbCCXwoDq8eVuTQ-9FOmqjknzBc
methon: get
response:
eq:
errcode: 0
- request:
url: https://qyapi.weixin.qq.com/cgi-bin/gettoken
param:
corpid: ww29957e72e534d27e
corpsecret: rVP15c62Ybjl9xTJIbCCXwoDq8eVuTQ-9FOmqjknz
methon: get
response:
eq:
errcode: 0
#获取通讯录token
tokenContacts:
- request:
url: https://qyapi.weixin.qq.com/cgi-bin/gettoken
param:
corpid: ww29957e72e534d27e
corpsecret: hUQCww5PR0o_QHF4HBt7lLQlVf3M5Amssx6OQZxUkPY
methon: get
response:
eq:
errcode: 0
(4)dump()用法,先获取相应的结果,已键值对的格式添加到list中,最后调用封装好的写入方法即可。
datalist = [{"tokenApproval": data.json()["token"]}]
param.param_write_csv(datalist)
二.json
1.json读写的两种方法和yaml一致load()和dump()
with open("读取的json文件", mode="r", encoding="utf-8") as p:
data = json.load(p)
with open("写入数据的json文件", mode="w", encoding="utf-8")as p:
json.dump(写入的数据data, p)
2.剩余部分json的操作方法和yaml的大致相同,唯一不同的区别就是json文件的写法。在实际操作中yaml中写
case会比json方便一点,所以我们可以在yaml写完后,通过第三方工具转换json格式,这样方便的很多:
https://json.im/json2/yaml2json.html。转换过后获取数据和yaml方法相同
三.csv
1.csv两种读写的方法reader()和write()
下图代码,csv.reader(file)返回的是一个可迭代的结果集,最后通过for循环遍历出来添加到list中。writerow()
为写入一个列表,也就是一行数据,如果要写入多条数据的话可使用writerows()方法,写法writes.writerows([list1,list2,list3........])
with open("读取的csv文件", mode="r", encoding="utf-8")as f:
data = csv.reader(f)
dataparam=[]
for lis in data:
dataparam.append(lis)
with open("写入的csv文件", mode="w", encoding="utf-8")as f:
writes = csv.writer(f)
writes.writerow("写入的list")
2.csv文件写法
首先我们在创建csv文件后打开会在右上角看见一个键盘似地图标,点击后选择csv后点击确定,这个时候在改
文件左下角有两个tab,text and data


text写法类似文本,每个元素中间用逗号隔开,而data则是表格的写法。这里需要注意的是如果你写入的是键值
对格式,需要严格按照格式来写,如下02例子
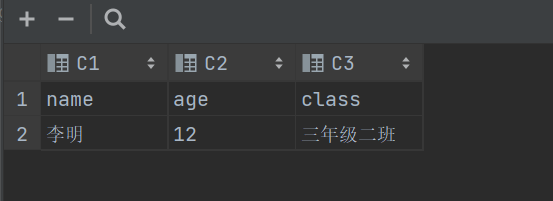
01
name,age,class 李明,12,三年级二班
02
class,name
三年级二班,"{""name"":""小明"",""age"":""12""}"
三.实例。下面我们以一个具体的实例来说下csv的用法
(1)首先我们创建一个tokencsv.csv文件,具体写法如下
tokenApproval,get,https://qyapi.weixin.qq.com/cgi-bin/gettoken,"{""corpid"":""ww29957e72e534d2"",""corpsecret"":""rVP15c62Ybjl9xTJIbCCXwoDq8eVuTQ-9FOmqjknzBc""}",0
(2)来封装我们所需要的读写方法
def param_reader_csv(self):
with open(self.data, mode="r", encoding="utf-8")as f:
data = csv.reader(f)
dataparam=[]
for lis in data:
dataparam.append(lis)
return dataparam
@staticmethod
def param_write_csv(data):
with open("./params/globalParametersToken.csv", mode="w", encoding="utf-8")as f:
writes = csv.writer(f)
writes.writerow(data)
(3)结合pytest.mark.parametrize实现数据驱动,parametrize中添写的变量数量一定要和csv文件中的数
量对齐,否则会报错。另外这里读取csv文件中的内容都是以str 类型输出的,所以当涉及到获取键值
对数据时,即下方parama入参值,需使用json.loads()方法将其转成dict,
@pytest.mark.parametrize("typetoken,methon,url,parama,errcode", param("./params/tokenCsv.csv").param_reader_csv())
def test_tokenApproval(self, typetoken, methon, url, parama, errcode):
data = method(json.loads(parama), url).request_get()
if data.json()["errcode"] == int(errcode):
tokenList = [data.json()["access_token"]]
param.param_write_csv(tokenList)
else:
with open("./log/error.log", mode="a+", encoding="utf-8")as f:
f.write(
f"[{datetime.datetime.now()}]:获取审核token失败,response:{data.json()},request-body:{data.request.body},request-url:{data.request.url}n")
当csv文件中写入单接口多条case时,无需过多处理,按照以上代码即可。当csv文件中写入多接口多条
case时,我们可以在csv文件中写入一个变量来区分这条case是哪条接口的,即上面代码typetoken参数。
cvs文件中首个数据tokenApproval和tokenContacts可代表不同的接口,我们在处理数据时加个if判断即可
(这种方法不太能接受,所以csv做数据驱动时尽量一个接口写 一个csv文件)
tokenApproval,get,https://qyapi.weixin.qq.com/cgi-bin/gettoken,"{""corpid"":""ww29957e72e534d27e"",""corpsecret"":""rVP15c62Ybjl9xTJIbCCXwoDq8eVuTQ-9FOmqjknzBc""}",0
tokenApproval,get,https://qyapi.weixin.qq.com/cgi-bin/gettoken,"{""corpid"":""ww29957e72e534d27"",""corpsecret"":""rVP15c62Ybjl9xTJIbCCXwoDq8eVuTQ-9FOmqjknzBc""}",0
tokenContacts,get,https://qyapi.weixin.qq.com/cgi-bin/gettoken,"{""corpid"":""ww29957e72e534d27e"",""corpsecret"":""hUQCww5PR0o_QHF4HBt7lLQlVf3M5Amssx6OQZxUkPY""}",0
四.excel
表格的操作太过复杂,能不用就不用吧,这里就简单展示的我封装读取excel的方法吧
def param_excel(self):
file = openpyxl.load_workbook(self.data)
file_name = file.active
data = []
for x in range(1, file_name.max_row + 1):
data1 = []
for y in range(1, file_name.max_column + 1):
data1.append(file_name.cell(x, y).value)
data2 = tuple(data1)
data.append(data2)
return data
完.....................
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:详解数据驱动 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 