一、问题引入
单链表的实现【01】:Student-Management-System 只体现了项目功能实现,未对代码部分做出说明。
故新增随笔进行补充说明代码部分。
重构代码,迭代版本:Student Mangement System(Version 2.0)
二、解决过程
基于单链表实现就离不开链表的几个重要概念:头结点、首元结点、头指针
2-1 链表概念
线性表链式存储结构的特点是:用一组任意的存储单元存储线性表的数据元素(这组存储单元可以是连续的,也可以是不连续的)。
根据链表结点所含指针个数、指针指向和指针连接方式,可将链表分为单链表、循环链表、双向链表、二叉链表、十字链表、邻接表、邻接多重表等
本随笔基于单链表实现,这里重点介绍它。
? 不带附加结点(即头结点)的单链表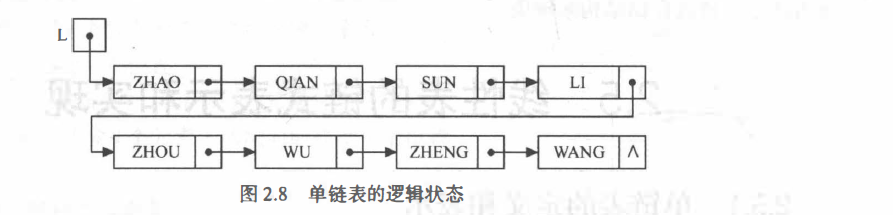

? 带附加结点(即头结点)的单链表
-
首元结点:指链表中存储第一个数据元素a1的结点
-
头结点:在首元结点之前附设的一个结点,其指针域指向首元结点
-
头指针:指向链表中第一个结点的指针
若链表设有头结点,则头指针所指结点为线性表的头结点;
若链表不设头结点,则头指针所指结点为该线性表的首元结点

? 链表增加头结点的作用如下:
(1)便于首元结点的处理增加了头结点后,首元结点的地址保存在头结点(即其“前驱” 结点)的指针域中,则对链表的第一个数据元素的操作与其他数据元素相同,无需进行特殊处理。
(2)便于空表和非空表的统一处理当链表不设头结点时,假设L 为单链表的头指针,它应该指向首元结点,则当单链表为长度n 为0 的空表时, L 指针为空(判定空表的条件可记为:L== NULL)。
? 为了提高程序的可读性,在此对同一结构体指针类型起了两个名称,LinkList 与LNode* , 两者本质上是等价的。通常习惯上用LinkList 定义单链表,强调定义的是某个单链表的头指针;用LNode *定义指向单链表中任意结点的指针变量
2-2 链表实现
- 结构体定义
#define ERROR -1 // 错误
#define OK 0 // 成功
#define OVERFLOW -2 // 溢出
#define TRUE 1 // 真
#define FALSE 0 // 假
typedef struct
{
char stu_name[10]; // 学生姓名
char stu_sex[10]; // 学生性别
int stu_age; // 学生年龄
int stu_id; // 学生学号
}Student_T;
typedef Student_T ElemType;
typedef struct LNode_T
{
ElemType data; // 结点数据域
struct LNode_T *next; // 结点指针域
}LNode_T, *LinkList_T; //LinkList_T 为指向结构体LNode_T的指针类型
- 单链表的初始化
int list_init(LinkList_T *L)
{
// 构造一个空的单链表
// 生成新结点作为头结点,用头指针*L(即单链表L)指向头结点
*L = (LNode_T *)malloc(sizeof(LNode_T));
if (NULL == *L)
exit(OVERFLOW);
memset(*L, 0, sizeof(LNode_T));
(*L)->next = NULL;
return OK;
}
- 单链表的销毁
int list_destory(LinkList_T *L)
{
// 释放所有结点(包括头结点)空间
LNode_T *temp;
while (*L)
{
temp = *L;
*L = (*L)->next;
free(temp);
}
return OK;
}
- 单链表的查找(匹配学号查找结点)
LNode_T * list_locate(LinkList_T L, int stu_id)
{
// p指向首元结点
LNode_T *p = L->next;
LNode_T *q = NULL;
while (p != NULL)
{
if (stu_id == p->data.stu_id)
{
q = p;
break;
}
p = p->next;
}
return q;
}
- 单链表的结点更新
int list_update(LinkList_T L, int stu_id, const char *stu_name)
{
int result = ERROR;
LNode_T *p_node = list_locate(L, stu_id);
if (NULL != p_node)
{
strcpy(p_node->data.stu_name, stu_name);
result = OK;
}
return result;
}
- 单链表的删除(匹配学号删除结点)
int list_delete(LinkList_T *L, int stu_id)
{
// p指向头结点
LNode_T *p;
LNode_T *q;
int is_found = ERROR;
for (q = NULL, p = *L; p != NULL; q = p, p = p->next)
{
if (stu_id == p->data.stu_id)
{
q->next = p->next;
free(p);
is_found = OK;
break;
}
}
return is_found;
}
- 创建单链表(尾插法)
int list_create_r(LinkList_T *L, ElemType elem)
{
// r指向头结点
LNode_T *r = (*L);
while (r->next != NULL)
{
r = r->next;
}
LNode_T *p = (LNode_T *)malloc(sizeof(LNode_T));
p->data = elem;
p->next = NULL;
r->next = p;
return OK;
- 单链表的遍历
int list_traverse(LinkList_T L)
{
// p指向首元结点
LNode_T *p;
for (p = L->next; p != NULL; p = p->next)
{
printf("%d %s %s %d\n", p->data.stu_id, p->data.stu_name,
p->data.stu_sex, p->data.stu_age);
}
return OK;
}
三、反思总结
单链表的实现过程,需要考虑是否附加头结点,有头结点和没有头结点的实现会有所不同
单链表的操作可以独立封装,根据具体的应用场景可以进行二次封装
四、参考引用
数据结构第二版:C语言版 【严蔚敏】 第二章 线性表(链表)
原文链接:https://www.cnblogs.com/caojun97/p/17268928.html
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:单链表的实现【02】:Student-Management-System - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 