
1 六度分隔理论
先来看两个有趣的例子。我们建立一个好莱坞演员的网络,如果两个演员在电影中合作或就将他们链接起来。我们定义一个演员的贝肯数(bacon number)是他们与演员凯文·贝肯有多少步的距离,贝肯数越高,演员离凯文·贝肯越远。研究发现,直到2007年12月,最高(有限)的贝肯数仅为\(8\),且大约只有12%的演员没有路径链接到凯文·贝肯。
此外,在学术合作中,埃尔德什数(Erdős number)被用来描述数学论文中一个作者与Pual Erdős的“合作距离”(Pual Erdős就是我们在博客《图数据挖掘:Erdos-Renyi随机图的生成方式及其特性》中提到的那位巨佬)。菲尔茨奖获得者的艾数中位数最低时为3,CS224W讲师Jure Leskovec(也是一位图数据挖掘大佬)的Erdős数为3.

看完这两个例子我们不禁会思考,两个人之间的典型最短路径长度是多少呢?事实上,哈佛大学心理学教授斯坦利·米尔格拉(Stanley Milgram)早在1967年就做过一次连锁实验[1],他将一些信件交给自愿的参加者,要求他们通过自己的熟人将信传到信封上指明的收信人手里。他发现,296封信件中有64封最终送到了目标人物手中。而在成功传递的信件中,平均只需要5次转发,就能够到达目标。也就是说,在社会网络中,任意两个人之间的“距离”是6。这就是所谓的六度分隔理论,也称小世界现象。尽管他的实验有不少缺陷,但这个现象引起了学界的注意。
2 小世界网络模型
六度分隔理论令人吃惊的地方其实还不在于其任意两个人之间的路径可以如此之短,而是在保证路径如此之短的情况下还保证了高的聚集性。
短路径从直觉上可以理解,因为每个人认识了超过\(100\)个能直呼其名的朋友,而你的每个朋友除你之外也至少有\(100\)个朋友,原则上只有两步之遥你就可以接近超过\(100\times 100=10000\)个人。然而问题在于,社会网络呈三角形态,即三个人相互认识,也就是说你的\(100\)个朋友中,许多人也都相互认识。因此,当考虑沿着朋友关系构成的边到达的节点时,很多情况是从一个朋友到另一个朋友,而不是到其它节点。前面的数字\(10000\)是假设你的\(100\)歌朋友连接到\(100\)个新朋友,如果不是这样则经过两步你能达到的朋友数将大大减小。
由此看来,小世界现象从局部角度看社会网络的个体被高度聚集,却还能保证任意两个人之间的路径如此之短,确实令人吃惊。
2.1 权衡聚类系数和图的直径
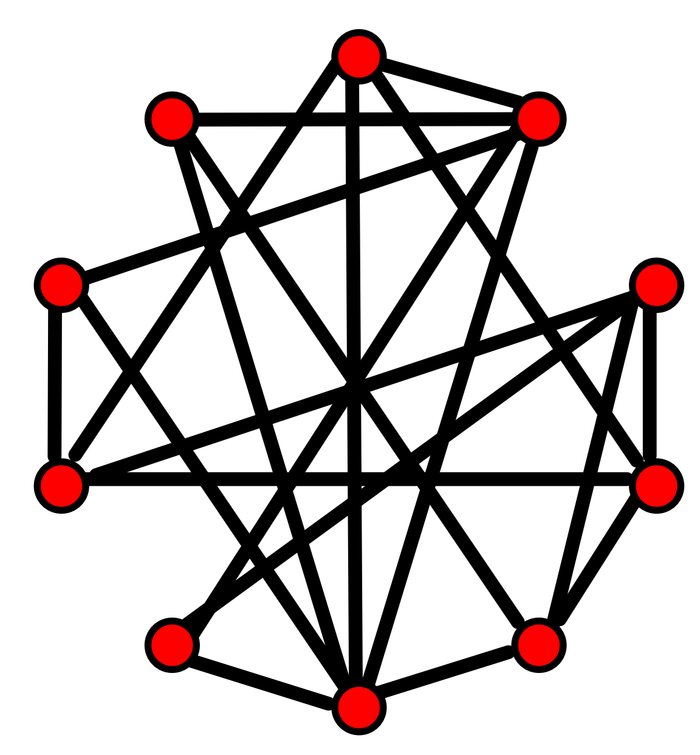
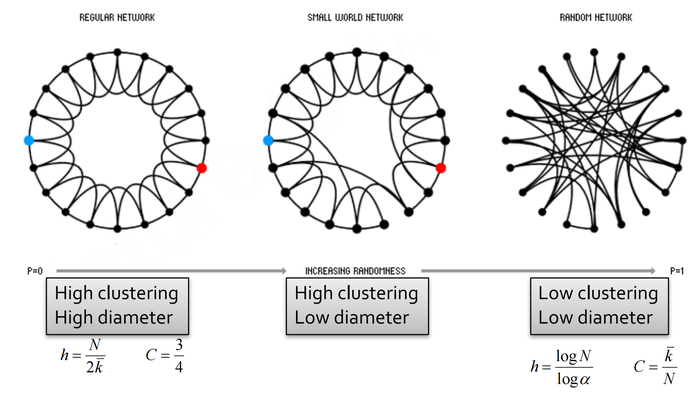
正如我们前面所说,聚类系数与图任意两点间的最短路径(可以通过图的直径来体现)有着矛盾的关系。比如在下面所示的这个网络虽然直径小,但聚类系数低:
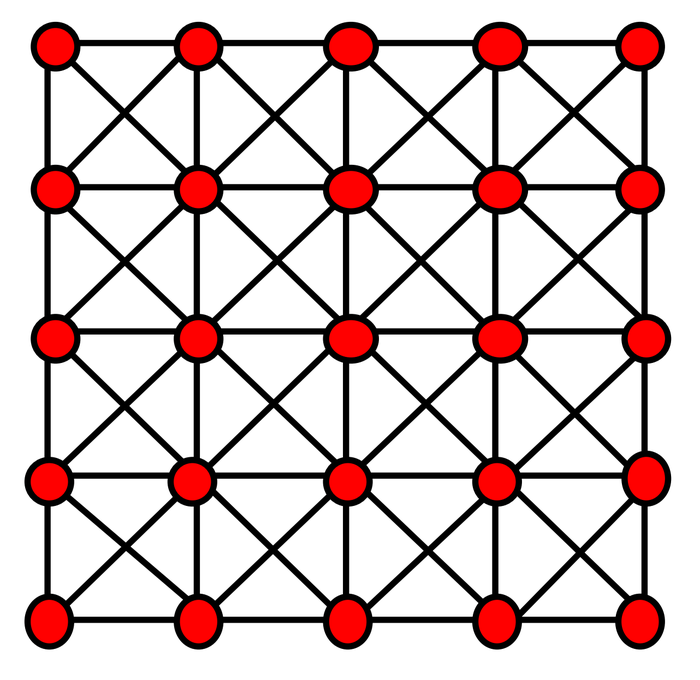
而下图这个具有“局部”结构的网络聚类系数虽高(即满足三元闭包,我朋友的朋友也是我朋友),但其网络直径大:
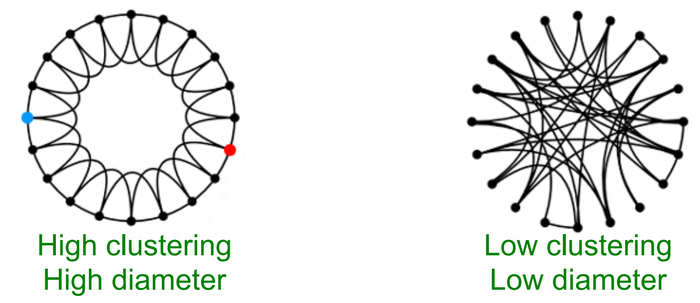
我们是否可以同时拥有高的聚类系数与小的直径呢?直觉上,我们发现聚集性体现着边的局部性(locality),而随机产生的边会产生一些捷径(shortcuts),如下图所示:
这样,我们在保持边聚集性的条件下,随机地添加一些边,那么就能够完成要求了。根据这个思想,人们提出了许多小世界模型,我们接下来介绍Watts-Strogatz模型。
2.2 Watts-Strogatz模型
Watts-Strogatz提成的小世界模型[2]包含两个部分:
(1) 低维的正则网格(lattice)
首先需要一个低维的正则网格模型来满足高的聚类系数。在下面的例子中我们使用一维的环状网络(ring)作为网格。
(2) 重新排布边(rewire)
接着在网格的基础上添加/移除随机边来创造捷径,以连接网格的远程部分。每条边有概率为\(p\)被随机地重新排布(将其一端点连接到一个随机节点)。
如下就是一个小世界网络的例子:
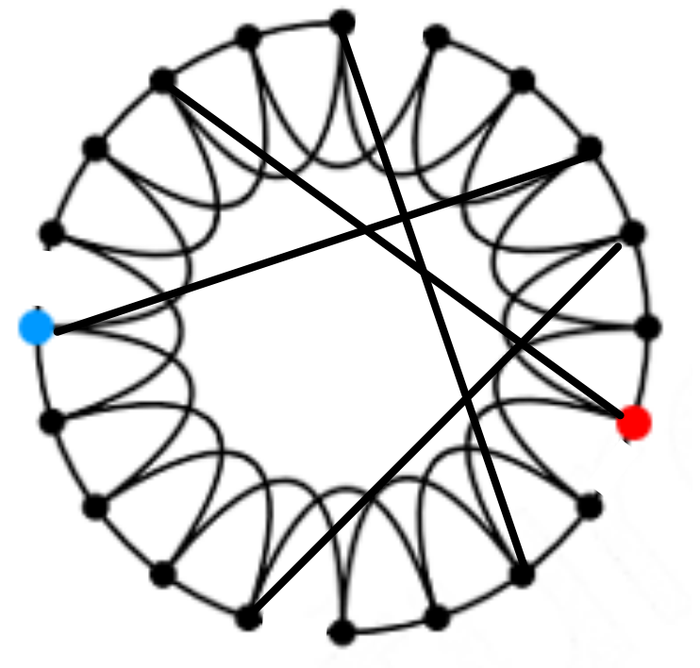
边的重新排布允许我们在正则网格和随机图之间形成一种“插值”:
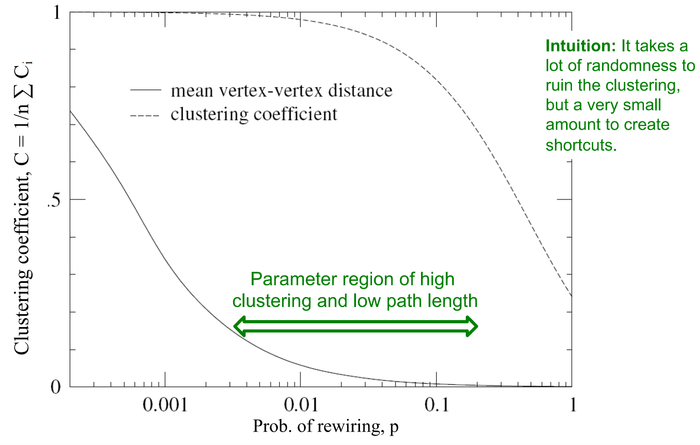
如下图所示,我们直观地发现如果想破坏聚类结构需要大量的随机性注入(即边随机重排的概率大),然而只需要少量的随机性注入就可以产生捷径。
接下来我们来根据一个实例分析其聚类系数和直径。我们基础网格模型选用方格,每个节点有一个随机产生的长距离边(long-range edge),如下图所示:
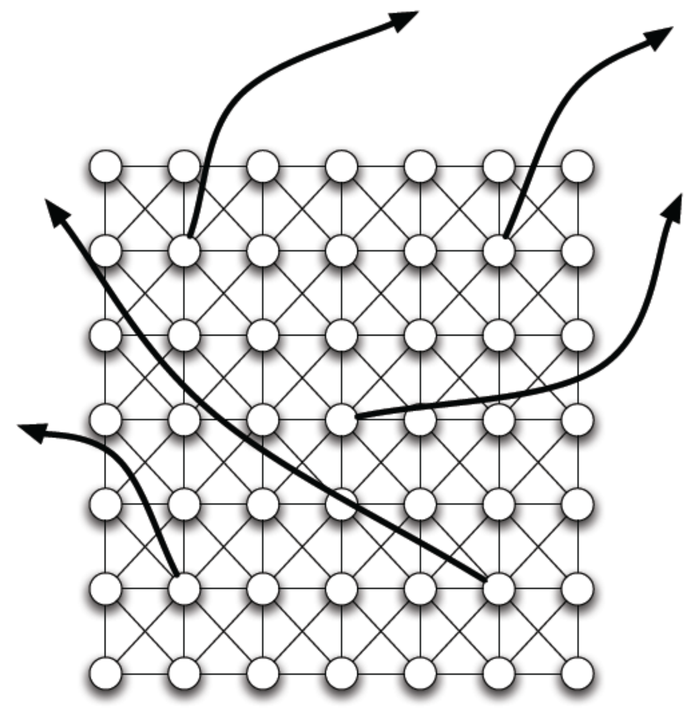
对于正中央的那个节点,我们有其聚类系数
\]
我们接下来来证明其直径是\(O(\log n)\)的。
我们将每个\(2\times2\)都子图合并为一个超节点,以形成一个超图,如下图所示: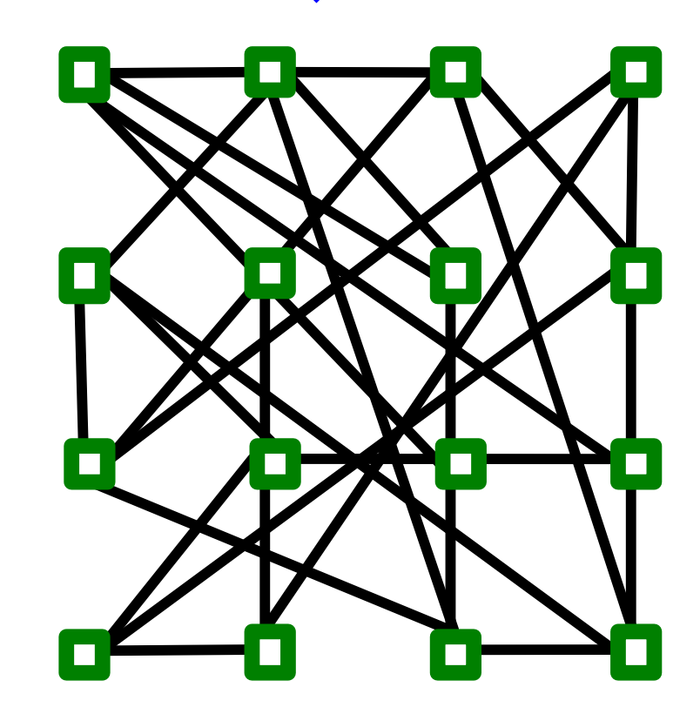
每个超节点有4条边伸出去,这是一个4-正则随机图。我们在每条长距离边上添加最多两步(必须遍历内部节点) 将每个超节点之间的最短路径转变为真实图中的路径。
于是我们得到该模型的直径为\(O(2\log n)\)
3 分散式搜索
接下来我们考虑另外一个问题:即如何找到到指定目标节点的最短路径,即对网络进行导航(navigation)。
3.1 问题定义
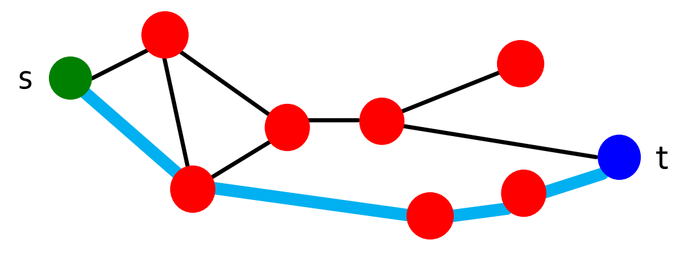
我们设开始节点为\(s\),目标节点为\(t\)。消息要从节点\(s\)开始,沿着网络中的边最终被传递到目标节点\(t\)。的起初节点\(s\)只知道其朋友的位置和目标的位置,且除了自己的链接之外,并不知道其它节点的链接情况。路径上每个中间节点也都仅具有这种局部信息,而且它们必须选择某个邻居转发该消息。这些选择相当于寻找一条从\(s\)到\(t\)的路径。我们将搜索时间(search time)\(T\)定义为消息从\(s\)转发到\(t\)所需要的步数。
3.2 Watts-Stogatz模型中的搜索
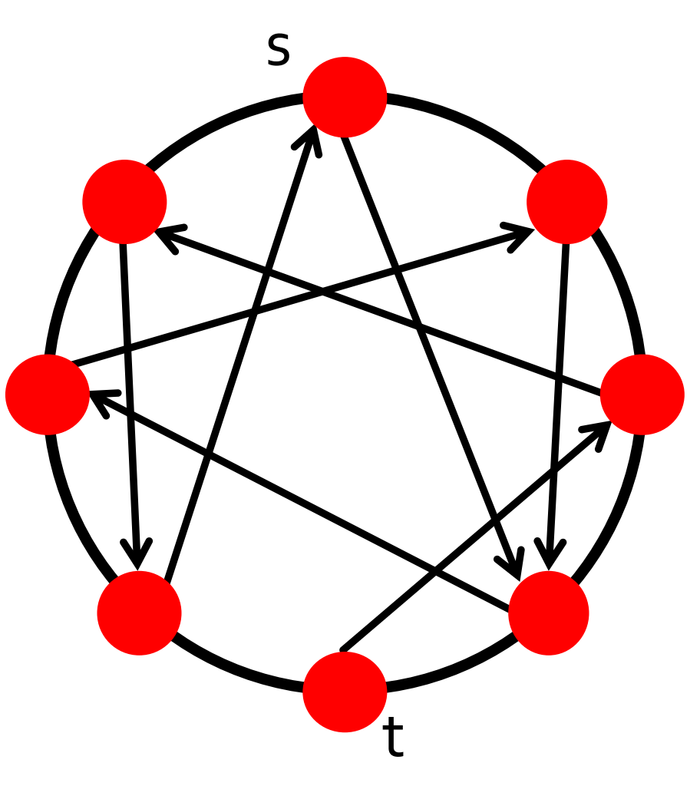
Watts-Stogatz模型即我们前面提到的,每个节点都有一条随机边的二维网格:
由于是小世界网络,其直径为\(O(\log n)\)。
然而令人遗憾的是,尽管存在长度仅为\(O(\log n)\)步的路径,但Watts-Stogatz模型中的去中心化搜索算法在期望上需要\(n^{2/3}\)步来到达目标节点\(t\),这也就意味着Watts-Stogatz模型是不可搜索的(is not searchable)。
证明
我们先来证明一维的情况。我们想要证明Watts-Stogatz是不可搜索的,则需要为其搜索时间证明一个下界(lower bound)。
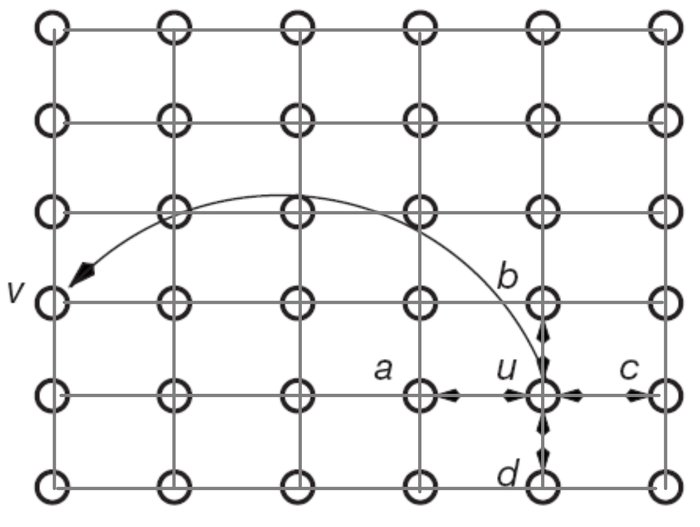
我们设置\(n\)个节点在一个环状网络(ring)上,且每个节点都有一个有向随机边。如下图所示:
我们接下来会证明对环状网络(一维网格),搜索时间\(T \geq O(\sqrt{n})\)。
我们采用的证明策略为延期决定原则(principle of defered decision),即我们假设仅在到达某个节点后才碰到随机长距离链接。
我们设\(E_i\)是一个随机事件,表示从节点\(i\)发出的长距离链接指向某个在\(t\)周围间隔\(I\)中的节点(间隔宽度为\(2\cdot x\)个节点),如下图所示:
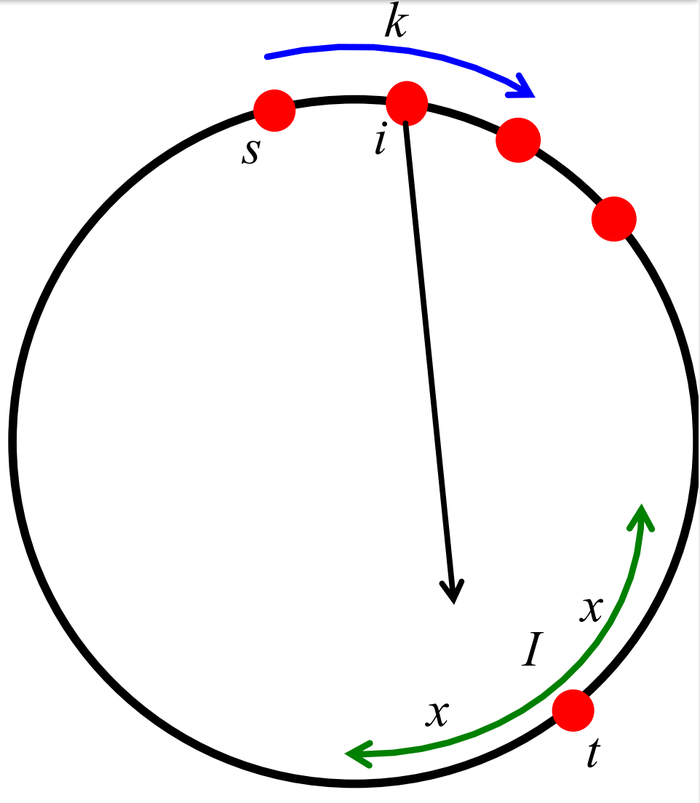
接着我们有
\]
设随机事件\(E\)为算法访问的前\(k\)个节点中,有一个拥有到\(I\)的链接(任意一个节点都行),如下图所示:
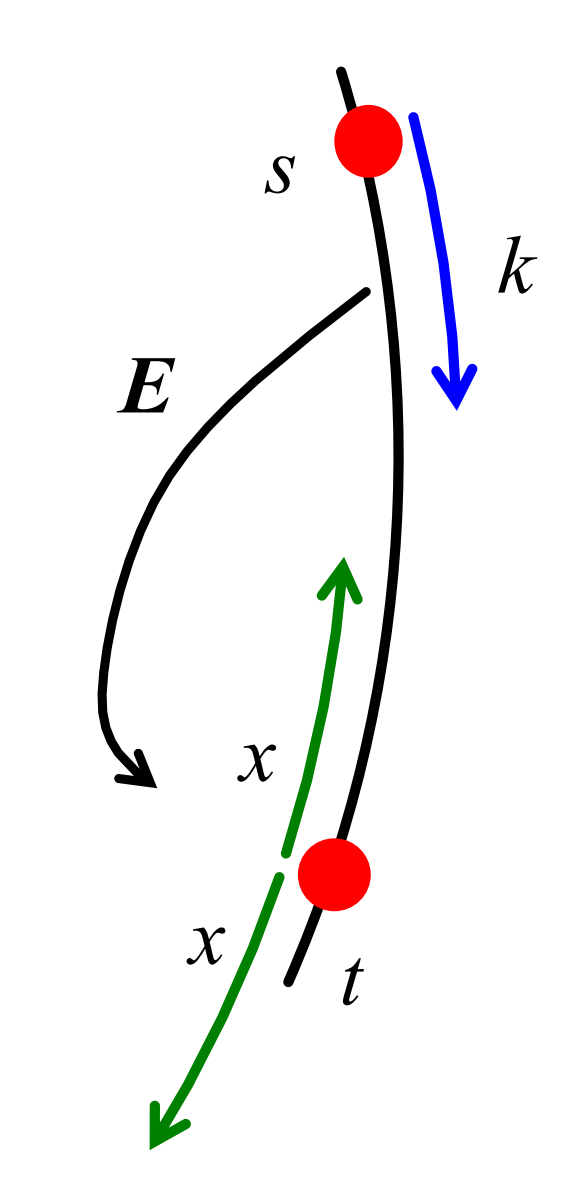
则
\]
我们选择\(k=x=\frac{1}{2} \sqrt{n}\),则:
\]
这实际上也就意味着在\(\frac{1}{2}\sqrt{n}\)步可以跳到\(t\)周围\(\frac{1}{2}\sqrt{n}\)步内的概率 $ \leq \frac{1}{2}$。
假设初始点\(s\)在\(I\)之外,且事件\(E\)没有发生(最先访问的\(k\)个节点都没有链接指向\(I\)),则搜索算法必须要花费\(T \geq \min (k, x)\)步来到达\(t\)。这两个下界分别对应以下两种情况:
Case 1 恰好在我们访问\(k\)个节点后,就碰到了一个很好的远程链接,此时共花费\(k\)步。
Case 2 \(x\)和\(k\)重叠了,由于\(E\)没有发生,我们必须至少要走\(x\)步。
这两种情况分别如下图所示:
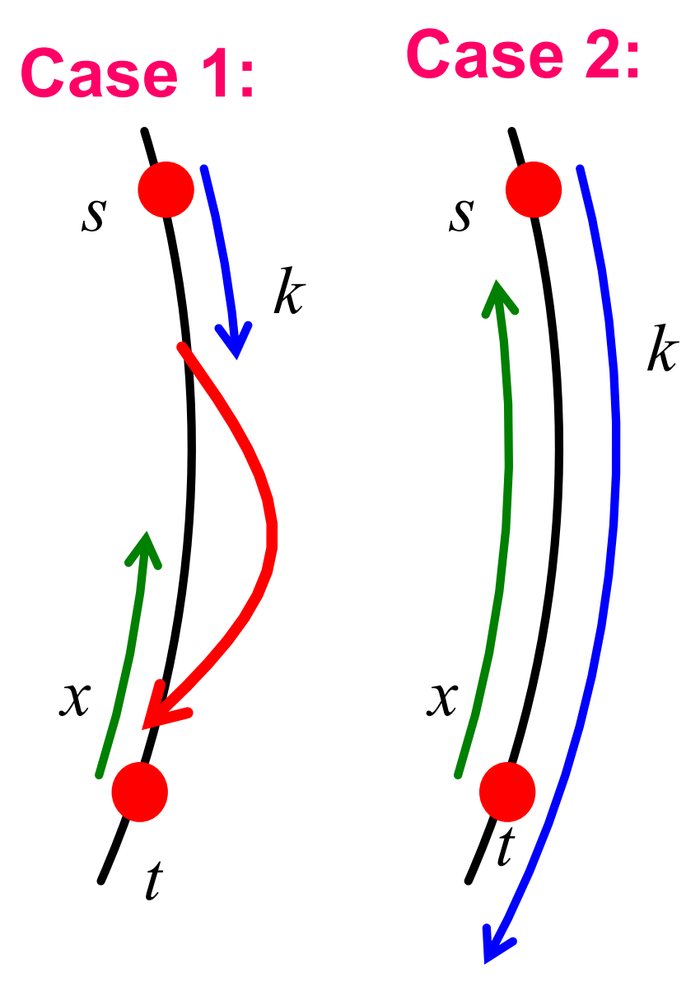
再加上根据前文的推论,我们有
\]
而我们前面已经说明了当\(x=k=\frac{1}{2} \sqrt{n}\)时,\(E\)有\(\frac{1}{2}\)的概率不发生。如果\(E\)不发生,则我们必须再走\(\geq \frac{1}{2} \sqrt{n}\)的步数才能到达\(t\),如下图所示:
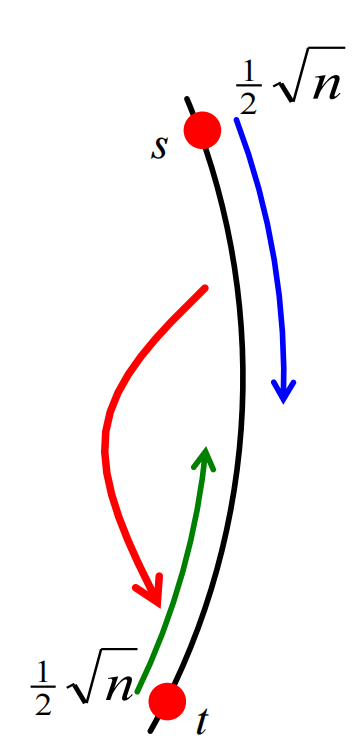
则到达\(t\)的期望时间
\]
得证。
同理我们可以证明对\(d\)维网格,有\(T \geq O\left(n^{d /(d+1)}\right)\)。
既然Watts-Stogatz模型是不可搜索的,我们如何构建一个可搜索的小世界图呢?接下来我们来介绍Watts-Stogatz模型的扩展版——Kleinberg模型。该模型同时具备我们所需要的两种性质:网络包含短路径,且通过分散搜索在可接受时间内发现这些短路径。
3.3 Kleinberg模型中的搜索
Kleinberg模型[3]基于以下直觉:长距离链接(long range links)并不是随机的,它们是根据节点的地理位置分布来的,因此我们可以使每个节点之间的随机边以距离衰减的方式生成。
八卦:Kleinberg也是个大牛,在ICM上做了题为“ Complex networks and decentralized search algorithms”的45分钟报告。
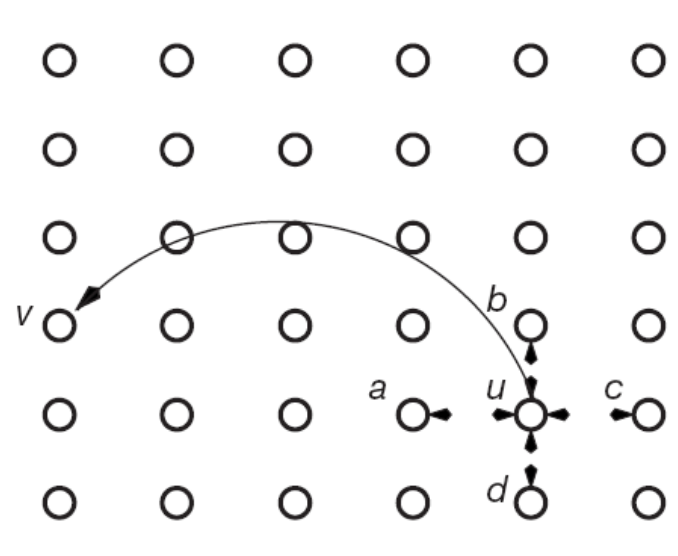
该模型仍然是基于网格的,且每个节点有一个长距离链接,不过该模型创新性地定义了节点\(u\)长距离链接到\(v\)的概率为:
\]
这里\(d(u,v)\)指\(u\)和\(v\)之间的网格距离(即一个节点沿着到相邻节点的边到另一节点的步数),\(\alpha\geqslant0\)。分母\(\sum_{w \neq u} \mathrm{~d}(\mathrm{u}, \mathrm{w})^{-\alpha}\)实际上是一个和\(d\)无关的归一化常数(后面我们会详细讨论),用于表示\(u\)到所有其它节点的距离和,因此我们实际上有:
\]
在不同\(\alpha\)的设置下,\(\text{P}(u\rightarrow v)\)随着\(d\)变化示意图如下:
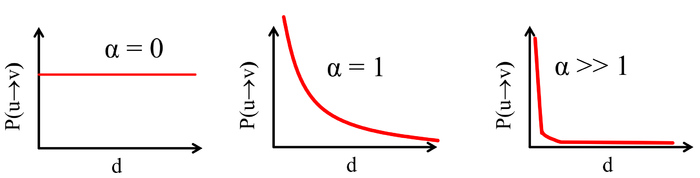
当\(\alpha=0\)时,\(P(u\rightarrow v)\)服从均匀分布,即节点之间的边完全随机产生,此时Kleinberg模型退化到Watts-Stogatz模型。
接下来我们介绍如何在Kleinberg模型中做搜索。我们接下来会证明在一维情况下,当\(\alpha=1\)时,从\(s\)到\(t\)的期望步数为\(O\left(\log (n)^2\right)\)。
我们假设某个节点\(v\)满足\(d(v,t)=d\),并设置间隔\(I=d\):
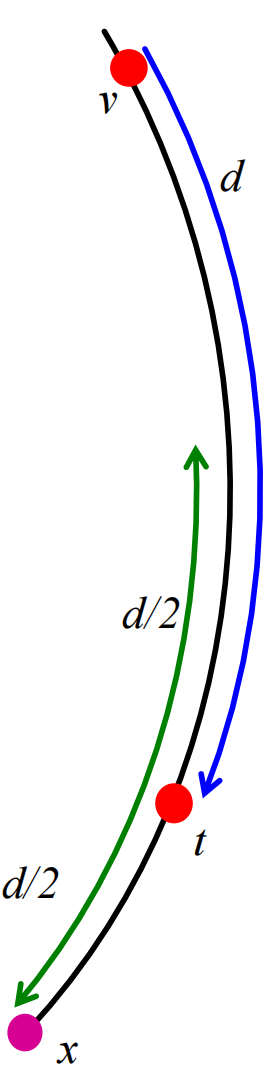
则我们可以证明从\(v\)到\(I\)中的某节点存在长距离链接的概率满足
\text { Long range } \\
\text { link from } v \\
\text { points to a } \\
\text { node in } I
\end{array}\right)=O\left(\frac{1}{\ln n}\right)
\]
这个定理非常酷,这是因为当\(d\)增大时,\(I\)会变得宽,但是该概率却和\(d\)是独立的。
下面我们来看该定理的证明。
首先我们有
\]
这里\(w\)为区间\(I\)中的一个点,归一化常数
\]
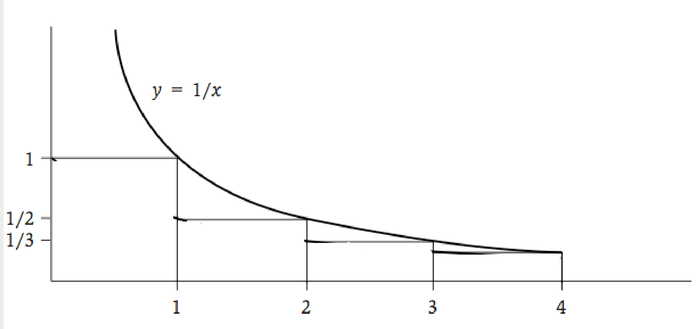
这里第一个等式成立是因为每个可能的距离\(d\)都对应两个节点,而从每个点产生链接的概率都为\(\frac{1}{d}\)。最后一个不等式成立是因为\(\sum_{d=1}^{n / 2} \frac{1}{d} \leq 1+\int_1^{n / 2} \frac{d x}{x}=1+\ln \left(\frac{n}{2}\right)=\ln n\),即用\(y=\frac{1}{x}\) 下方的面积来确定调和级数的上界,如下图所示:
因此,我们从有\(v\)链接到间隔\(I\)的概率
P(v \text { points to } I)&=\sum_{w \in I} \mathrm{P}(\mathrm{v} \rightarrow \mathrm{w}) \geq \sum_{w \in I} \frac{\mathrm{d}(\mathrm{v}, \mathrm{w})^{-1}}{2 \ln n}\\
&=\frac{1}{2 \ln n} \sum_{w \in I} \frac{1}{d(v, w)} \geq \frac{1}{2 \ln n} d \frac{2}{3 d}\\
&=\frac{1}{3 \ln n} = O\left(\frac{1}{\ln n}\right)
\end{aligned}
\]
其中对\(\sum_{w \in I} \frac{1}{d(v, w)}\),我们考虑到所有项都有\(\frac{1}{d(v, w)}\geq \frac{2}{3d}\),故在此基础上进行放缩。
因此,我们有\(v\)链接到\(t\)周围\(I\)间隔(宽度为\(\frac{d}{2}\))内的概率为(这里\(d=d(v,t)\))
\]
得证。
这实际上就意味着在期望上我们只需要步数\(\sharp \text{step}\leqslant \ln(n)\)就能到达间隔\(I\),因此就将到\(t\)的距离削减了一半。而距离被减半最多\(\log_2(n)\)次,故到达\(t\)的期望时间为\(O(\log_2(n)^2)\)。
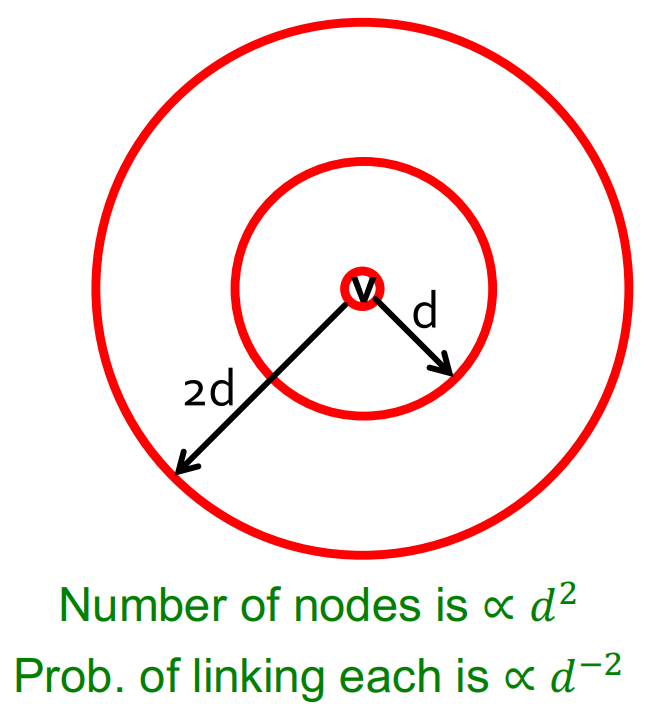
注: 事实上在2D网格的情况下,我们有距离目标距离在\(d/2\)以内的节点数语\(d^2\)成比例,即\(\sharp nodes(I)∝ d^2\)。这表明要获得和一维情况下同样的“抵消”效果,需要\(v\)连接到每个其它节点\(w\)的概率应该与\(d(v,w)^{-2}\)成比例,这样我们也有结论\(\text P(v \text { points to } I)>\ln{n}\)。
3.4 多种模型的搜索时间对比和反思
总结一下,不可搜索的模型对应的搜索时间为\(O(n^{\lambda})\),其代表为Watts-Stogatz网络(\(O(n^{\frac{2}{3}})\))、Erdős-Rényi网络(\(O(n)\));可搜索模型对应的搜索时间为\(O((\log n)^{\gamma})\),其代表为Kleinberg模型(\(O(\log_2(n)^2)\))。
由于小世界图的直径为\(O(\log n)\),故Kleinberg模型的搜索时间关于\(\log n\)是多项式阶增长的,然而Watts-Stogatz模型关于\(\log n\)是指数阶增长的。
前面我们已经证明,在一维情况下当距离节点距离项\(\mathrm{d}(\mathrm{u}, \mathrm{v})^{-\alpha}\)中的\(\alpha=0\)时(也即Watts-Strogatz模型),我们需要\(O(\sqrt{n})\)步,当\(\alpha=1\)时,我们需要\(O(\log(n)^2)\)步。事实上,我们有搜索时间和指数\(\alpha\)的关系如下:
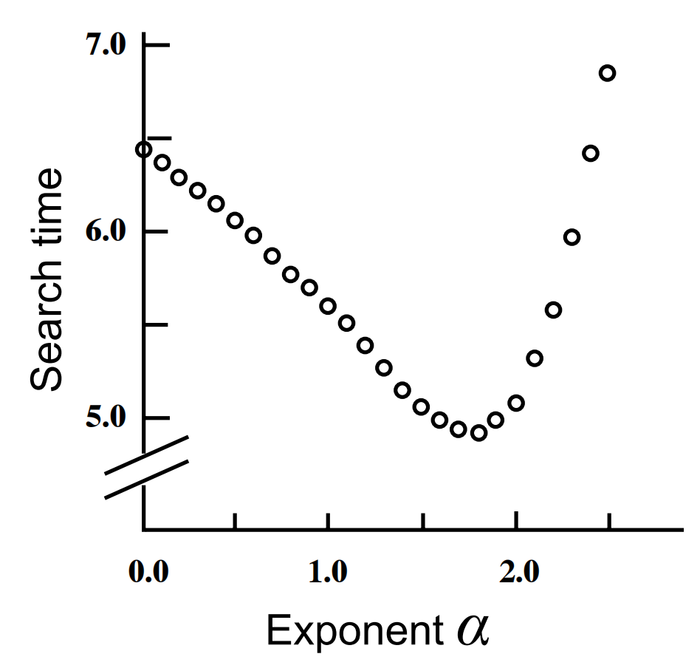
可见当\(\alpha=2\)时分散搜索最有效(此时随机链接遵循反平方分布)。
过小和过大的\(\alpha\)形象化的展示如下图所示:
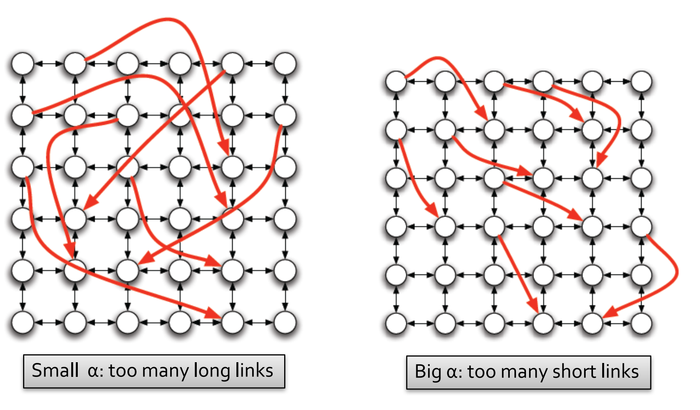
可接过小的\(\alpha\)意味着有太多的长距离链接,过大的\(\alpha\)则意味着又太多的短距离链接。
最后,让我们来思考一下为什么\(P(u \rightarrow v) \sim d(u, v)^{d i m}\)会如此有效呢?因为该分布在所有“分辨率尺度”上都是近似均匀的,和\(u\)之间距离为\(d\)的节点数量会以\(d^{dim}\)倍率增长,而这会产生一种抵消作用,导致每条边产生链接的概率值和\(d\)独立(正如我们前面分析二维情况时所说)。如下图所示:
参考
[1] Milgram S. The small world problem[J]. Psychology today, 1967, 2(1): 60-67.
[2] Watts D J, Strogatz S H. Collective dynamics of ‘small-world’networks[J]. nature, 1998, 393(6684): 440-442.
[3] Kleinberg J. The small-world phenomenon: An algorithmic perspective[C]//Proceedings of the thirty-second annual ACM symposium on Theory of computing. 2000: 163-170.
[4] http://web.stanford.edu/class/cs224w/
[5] Easley D, Kleinberg J. Networks, crowds, and markets: Reasoning about a highly connected world[M]. Cambridge university press, 2010.
[6] Barabási A L. Network science[J]. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 2013, 371(1987): 20120375.
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:图数据挖掘:小世界网络模型和分散式搜索 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 